
{kind=link}
{kind=link}
{kind=link}
网络舆情主题信息采集研究*
引用本文
黄炜, 金雅博, 胡昌龙. 网络舆情主题信息采集研究* . 现代图书情报技术, 2012, 28(11): 65-71
Huang Wei, Jin Yabo, Hu Changlong. Focused Crawling for Network Public Opinion’s Topic Information. 现代图书情报技术, 2012, 28(11): 65-71
Permissions
Huang Wei, Jin Yabo, Hu Changlong. Focused Crawling for Network Public Opinion’s Topic Information. 现代图书情报技术, 2012, 28(11): 65-71
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
网络舆情主题信息采集研究*
摘要
网络舆情的主题不确定性问题在网络治理中越来越突出,通过研究网络舆情的相关特征及其演化机制,在基于内容的主题选择策略上,引入时间维和空间维的主题因子,设计并实现网络舆情的主题信息爬虫。实验结果表明,该主题信息爬虫不仅执行的效率较高,而且主题约束性稳定,为后期网络群体性事件的舆情处理提供主题样本。
关键词:
网络群体性事件; 网络舆情; 主题爬虫; 领域本体; 主题因子
中图分类号:G353.1
Focused Crawling for Network Public Opinion’s Topic Information
Abstract
The unfocused problem of network public opinion becomes more and more serious. This article proposes a focused crawler for network public opinion based on content topic selection strategy with time and spatial dimension factor by analyzing feature and evolution of network group events. The results of experiments prove that this focused crawler has higher execution efficiency, and also achives good focused ability. That provides the focused resources of processing network public opinion group events.
Keyword:
Network group events; Network public opinion; Focused crawler; Domain Ontology; Focused factor
1 引言
CNNIC发布的《第30次中国互联网络发展状况调查统计报告》中显示,截至2012年6月底,我国网民规模已经达到5.38亿[ 1]。由个人以及各种社会群体构成的公众,在一定的社会空间内,通过网络对自己关心或与自身利益紧密相关的各种公共事务所持有的多种情绪、态度和意见交错的总和,形成了各种网络舆情事件[ 2]。而随着事件的不断升级,在缺乏正确引导和管制的情况下,会产生具有极大恶劣影响的网络群体性事件,给经济稳定、社会和谐造成很大的负面影响。 国际上最具影响力的网络舆情监测研究课题是美国TDT(Topic Detection and Tracking)[ 3]系统,用于发现并跟踪网络信息的热点。国内较为成熟的舆情分析与监测系统有北大方正技术研究院推出的方正智思舆情预警辅助决策支持系统[ 4]。由于舆情的不确定性和复杂性以及相关主题的广泛性,这些系统通过网络爬虫广泛地获取网页信息,然后对其进行各种维度的分析处理。而海量的网络信息给处理带来了很大的难度,使系统产生了性能瓶颈。本文提出的基于网络舆情领域本体的主题采集框架,对目标网络信息进行主题分类和舆情筛选,极大地减轻了后期海量数据处理的压力,使网络舆情监控系统的性能得以提高。
2 主题爬虫概述
实现主题爬虫需要完成对抓取目标进行描述或定义、网页主题相关度分析和网页爬行策略,最核心的是网页主题相关度分析算法[ 5]。其中PageRank[ 6]算法和HITS[ 7]算法,两者都是通过对网页间链接度的递归和规范化计算,得到每个网页的重要度定量评价。基于网页内容的分析算法是通过对Web网页文本内容、URL字符串、锚文本、锚文本的上下文、父文本的文本特征等文字内容信息进行主题相关度分析,进而决定爬虫的爬行策略,典型的算法有Best First Search[ 8]、Fish Search[ 9]、Shark Search[ 10]等。基于用户访问行为的分析算法则主要通过对用户访问日志的分析,来制定爬虫的爬行策略。另外还有基于统计模型[ 11]、遗传算法和Context Graph等爬行策略。文献[12]利用P2P分布式架构解决大规模主题爬虫的效率问题。领域本体的语义参照物也在主题爬虫中得到应用[ 13, 14]。为了得到更加准确的主题信息,文献[15]设计优化了“二次爬行”策略。
各类网页分析算法都各有利弊,基于网络拓扑结构的算法在爬行过程中,会忽略与主题内容的相关性,因此容易出现“主题漂移”的现象,造成主题约束率较低;基于网页内容无法有效地预测链接的主题价值;基于用户访问日志的算法还不够成熟,只能使用在某些特殊的领域。网络舆情是一个更为复杂、多元的信息主题,国内的网络舆情主题信息采集尚不成熟,是主题爬虫研究的新难点问题。
3 网络舆情主题爬虫的设计与实现
3.1 主题描述与定义
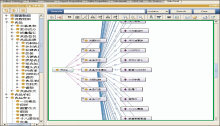
网络舆情是公众对各种公共事务在网络介质上的反应,而这些公共事务是公众关心或是与公众利益相联系的,这就决定了网络舆情主题的泛在性,即没有一个十分明确的主题,也没有明确的边界。任何一件普通的舆情事件,在特定的时间和空间下,都有可能演化为网络群体性事件。所以对网络舆情的主题描述具有相对抽样性,在不同具体领域中进行分类指导。例如将舆情事件可分为如下几类:政治事件类、军事类、教育类、司法类、文化类、自然灾害类、娱乐类、食品安全类、国家安全类等。这些分类基本覆盖民众生活中的各个方面,但由于网络舆情的多重归属性,所以分类的重复覆盖对舆情的处理没有很大的影响。每一个分类就构成了一个网络舆情的领域分主题。然后,针对不同的领域主题构建相应的特征词库,特征词库主要包括领域特征词及其对应的权重。为了保证主题相关度分析的准确性,可以在领域专家的参与下共同完成领域主题特征词库的构建,也可以通过相应的训练语料库,基于机器学习统计的方法进行领域自动分类和构建主题特征词库[ 16]。本文主要以食品安全作为领域主题,构建食品安全领域本体,通过2005年至今252件食品安全事件的语料信息进行语义解析,形成食品安全的特征词库,再采用Protégé本体工具构建食品安全领域本体,如图1所示:
 | 图1 食品安全领域本体 |
本体的开发和完善是一个反反复复不断补充的迭代过程,由于实验的需要,本文对本体做了适当的简化处理。利用Jena开源工具对食品领域的本体进行初步的解析,可以得到构成本体的所有类(Class)、属性(Property)、实例(Individual)。由于这三类概念对本体的主题贡献各不相同,从而在特征词的权值处理中给予不同的权值。其中实例代表的是最具体的对象,在食品安全领域本体中“苏丹红”、“三聚氰胺”、“瘦肉精”就是其中的实例。类相对于实例来说就要抽象一些,并且类与类之间基本关系是SuperClassof(父类)和SubClassof(子类),如果用OWL Functional Syntax语言描述“防腐剂”和“添加剂”之间的父子关系就是[ 17]:
Declaration(Class(:添加剂))
SubClassOf(:添加剂:防腐剂)
属性是对本体进行细致描述的重要部分,在语义推理的时候显得尤为重要,但是对于本体的主题贡献度可能较小。因此本文在处理的过程中对解析出来的特征词的层次权值Wc赋值方式为:
Wc(t)=
 | (1) |
因此食品安全的领域本体就可以成为解析食品安全主题的一个分类器,然后利用向量空间模型构建分类器。分类器特征词库用n维向量表示为T=(t1,t2,t3,…ti,…tn),其中i=1,2…n(n为整数)。根据词的对应的层次权值,分类器对应的向量空间的权值模型为Wc=(wc1,wc2,wc3,…wci,…wcn),其中i=1,2…n(n为整数)。
3.2 相关度算法设计
(1)文本相似度分析
目前,进行文本主题相似度分析的两种主要方式是基于集合的布尔模型和基于向量的向量空间模型[ 18]。布尔模型的最大优点是简单、直观,文档和索引之间就是有或没有的一元关系,同样检索结果也只是相关或不相关。检索过程只进行简单的布尔运算,系统的运算开销非常小。但是该模型检索性能较差,对检索结果无法做排序处理,准确度也不高。基于向量空间模型的最大优点是在知识表示方法上的巨大优势。在该模型中,将文档内容简化为特征项及其权重的向量表示,即文本内容被形式化为多维空间中的一个点,通过向量的形式给出,把对文本内容的处理简化为向量空间中的向量运算,使问题的复杂性大为降低。因此在文本处理领域,向量空间模型是最佳的选择。
爬虫程序在获取了网页信息后,首先进行网页的预处理,获得网页的文本信息。网页的文本信息再经过去标点,运用中国科学院计算技术研究所的分词系统进行中文分词、去停用词之后,合并数字和人名等词汇,就构成了文本的n维词条向量Dj=(tj1,tj2,tj3,…tji,…tjn),其中i=1,2…n(n为整数)。
采用IF-TDF(文本频率-逆文本频率)计算特征词的统计权重Wj(wj1,wj2,wj3,…wji,…wjn),其中i=1,2…n(n为整数)。
wjt表示集合中单词t对某一主题的统计重要程度,wjt用TF×IDF的公式计算获得:
wjt=TFjt×IDFjt= 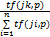
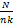
其中,tf(jt, p)是特征词t在p中出现的频率,N为文档集中的所有文档数,nk为t出现的文档数。综合特征词的领域本体层次权值Wc和历史统计权值Wj,加权计算总权值W=Wc×Wj,再使用余弦夹角的相似度算法计算当前文档与主题的相似度,公式如下所示:
Sim(T,Dj)=cos(T,Dj)
=
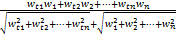 | (3) |
Sim(T,D)将作为主题相关度参考因素,同时也作为爬行策略选择的一个重要因子。
(2)链接相关度分析
对链接进行有效的相关度分析与预测,引导网络爬虫的爬行方向,是防止“主题漂移”、获取精确主题信息的关键,也是主题爬行策略的基础。本文根据舆情分析的特征,为采集有效的舆情信息,在链接相关度分析上主要从锚文本和URL两个层面上进行分析。
①锚文本相关度
链接锚文本一般是文本信息的概括,是文本信息发布者对于文本主题简明而具有高度概括性的短文本,具有较强的主题特征。直接采用基于关键字分析的量度指标过于粗糙,会丢弃一些相关页面。本文采用分词后构建短文本的特征向量,与主题分类器的主题向量进行相关度分析,求得链接锚文本的相似度sim(anchor)。
②URL相关度
URL相关度的分析主要是基于URL字符串的分析,因为舆情信息并不具有特定字符串的标识,所以本文对于URL相关度的分析主要是对URL所在站点的一个权重的分析,对不同站点的URL给予不同的舆情权重,引导爬虫获得权威网站的舆情信息,其权重方法类似于文本信息的空间权重的设置,URL相关度用sim(url)来表示[ 19]。
3.3 主题爬虫的爬行策略
基于大量历史网络群体性事件的演化机制分析,网络舆情演化为网络群体性事件,具有两个方面的共同特征:舆情信息经过影响力强的网站传播与转发;网络群体性事件的源信息表现出明显的实时性和地源性。
因此在舆情信息的获取中,本文引入了时间因子Ot和空间因子Os,指导爬虫的爬行策略,使主题爬虫得以从海量的舆情信息中抓取到真正有效的舆情信息,大大简化了舆情后期的信息分析与处理。本文对网络舆情的主要来源网站进行统计分析,结合各网站的Alexa排名的结果如表1所示:
| 表1 网络舆情主要来源网站 |
将网页文本的空间因子权重表示为:
Os= 
经过统计分析,可以得出网络舆情演化为网络群体性事件的网页更新数目与时间的关系呈倒U形的分布,这一结论与谢科范等[ 20]提出的网络舆情突发事件的热度与时间的关系模型图相一致。
本文将网页文本的时间因子权重表示为:
Ot=
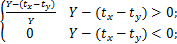 | (4) |
其中,tx为系统当前时间,ty为文本发表时间,Y为常量,代表一定的时间间隔。
Ot因子为网页文本的时间序列权重,表示文本网页的发表时间如果超过一定的期限,则可以近似认为该网页已经丧失舆情的活性,可以不予采集,而是采集文本发表时间在一定期限内的文章。为了提高处理的效率,本文对算法进行了简化处理,认为文本的舆情活性随着时间呈线性递减,即设置当天的文本新闻的时间权重最高为1。
在引入了时间因子和空间因子后,对当前页面链接选择的方法进行链接相关度的计算,包含当前链接的文本相似度的取值为Sim(t,d),时间权重为Ot,空间权重为Os。当前链接的锚文本相似度为sim(anchor),URL的相似度为sim(url)。
3.4 主题爬虫的系统构建
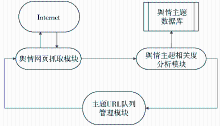
本文构建的主题爬虫的核心模块主要有三个:爬行模块,在队列管理模块的指导下,获取链接文本信息;相关度分析模块,对获取的链接文本信息进行主题相关度分析,判断是否为主题相关网页,同时对网页的链接进行主题相关分析,判断是否加入URL队列;URL队列管理模块,根据主题相关度分析模块提供的链接相关度,对URL队列进行排序优化,确定待抓取URL的优先级。
这三个模块的基本关系如图2所示:
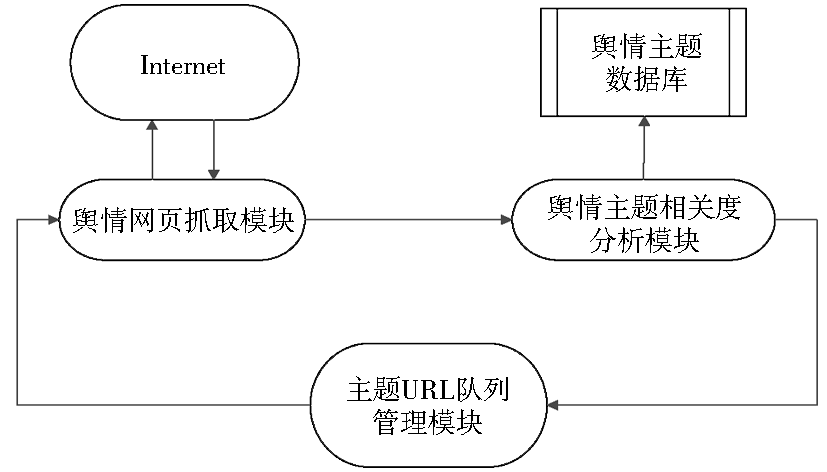 | 图2 网络舆情主题爬虫的基本框架 |
(1)爬行模块
为了有效地提高抓取效率,在主题爬行模块的设计中使用了多线程技术,并将抓取的线程设置为100。爬行模块的种子站点主要是国内知名的门户新闻网站,如新浪、腾讯、网易等。
(2)相关度分析模块
相关度分析模块是主题爬虫的核心。本文根据舆情信息分析的需要,在对文本信息相关度处理的基础上,同时做了时间维和空间维的处理。首先,对网页文本的发布时间进行分析,如果文本的时间权重Ot大于α,则对文本进行相关度分析;如果文本相关度大于β,则将文本存入数据库,并同时提取文本URL;如果URL的相关度大于γ,则将URL放入主题URL队列管理模块。
改进的文本相关度判断算法Sim(t,d)=sim(T,Dj)×60%+Ot×20%+Os×20%;改进的URL相关度决断算法sim(u)=sim(d)×20%+sim(anchor)×60%+sim(url)×20%。网页主题相关度分析流程如图3所示:
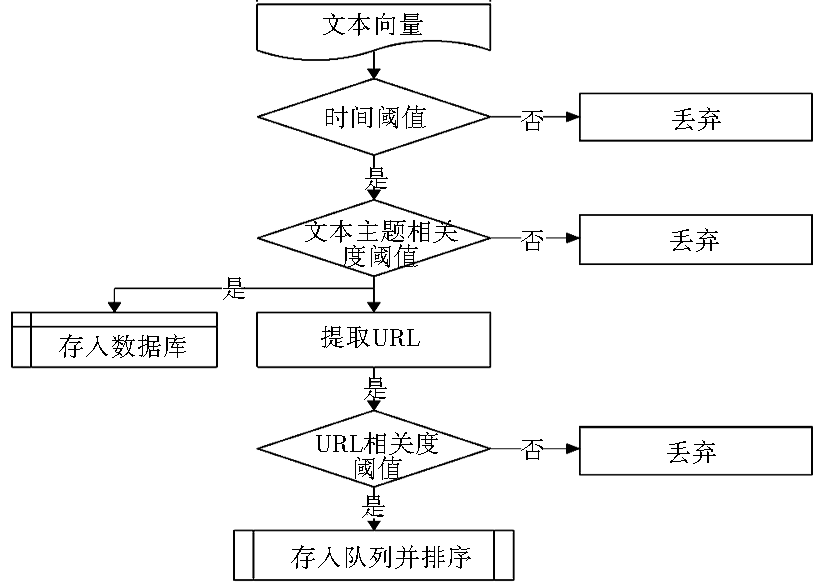 | 图3 网页主题相关度分析模块流程 |
(3)URL队列管理模块
为了完成主题爬虫的网页抓取任务,需要使用5个URL队列,每个队列保存着同一状态的URL。
①等待队列:在这个队列中,URL等待被爬虫处理,新的URL被加入到该队列。
②处理队列:爬虫开始处理URL时,被传送到这一队列,为了保证同一URL不能多次被处理,当一个URL被处理过后,被移送到错误队列、抛弃队列或者完成队列。
③错误队列:如果在下载或解析网页时出错,它的URL将被加入到错误队列,一旦移入错误队列,爬虫不会对它做进一步处理。
④抛弃队列:如果下载且解析网页时没有发生错误,但相关度分析模块将其判定为主题无关的网页,则将对应的URL放入该队列,爬虫不会对它做进一步处理。
⑤完成队列:如果下载且解析网页时没有发生错误,并且相关度分析模块将其判定为主题相关的URL,则将相关URL加入该队列。
同一时间一个URL只能在一个队列中,在实验中将其标示为不同的状态。
4 实验结果分析
4.1 实验环境
运行环境参数:CPU,Intel双核1.5GMHz;内存2GB;硬盘320GB;操作系统Windows Xp-Profession sp2。编程语言Java;数据库MySQL;集成开发平台Eclipse;本体工具Protégé;开源工具ICTCLAS分词系统;本体Jena解析包,网页HTMLParser解析包。
4.2 实验数据分析
为了更好地验证本文提出主题爬虫算法的可行性,将新浪、腾讯和网易作为种子站点,使用该主题爬虫,设定爬行时间为一个小时,对食品安全领域主题进行抓取,获得的实验数据如表2所示:
| 表2 食品安全领域主题爬行数据 |
实验中将α的值统一设为0.5,表示具有舆情价值的时间期限为半年。通过实验的结果发现,爬虫的查准率随着β和γ值的增加而增加,且受γ值变化影响更大。虽然实验6的查准率要优于实验1的查准率,但是实验6可能抛弃了很多的相关网页。由于实验环境的网络文本数量很大,无法准确地获得不同实验下爬虫的查全率,但是通过对相关网页文本的分析,发现实验1中的相关网页中存在有大量实验6中抓取遗漏的网页,而显然实验6单位时间的抓取范围更广。通过综合分析,可知实验3较好地平衡了查准率和查全率两个量度指标。
通过实验得出α=0.5、β=0.5、γ=0.2时主题爬虫的性能达到最佳。在此基础上,设置同样的种子站点和抓取时间,将该取值下的主题爬虫和没有加入时间因子和空间因子两个决策因子的主题爬虫进行实验对比分析,由于数据分析量偏大,故采用分组人工分析的方法,结果如表3所示:
| 表3 时间、空间因子对主题爬行效果对比 |
其中,A为加入了时间因子和空间因子的主题爬虫,B则为没有加入时间因子和空间因子的主题爬虫。实验结果显示,爬虫A获取的具有舆情价值网页的数目为4 212,有效抓取率为68%,比普通爬虫的有效抓取率要高出将近20个百分点,有效地保证了抓取信息的准确度,减少了无价值舆情网页对后期舆情数据分析的干扰,为网络舆情的分析预警打下了坚实的基础。
5 结语
本文结合主题爬虫实现了主题相关度算法,并根据网络舆情主题分析的需要与相关特征,引入了时间因子和空间因子,并以此对网页的相关度与链接的相关度分析算法进行了改进与优化。在实验的基础上,通过对相关度算法中设立不同的阈值进行实验分析,发现在时间因子α=0.5、β=0.5、γ=0.2的情况下,主题爬虫系统的准确率达到最优。并且相比普通的爬虫,本系统在爬行效率和准确度方面都有很大的优势。
本文所设计的主题爬虫也有一些不足之处,其中对于网站空间权重的设置不够完善,实验数据抽样、对比分析还不够精确;特别是面对社会化网络新兴媒体,如微博等社会化关系型自内容网络的主题采集,还是一个难点。另外,对于所建立的食品安全领域的本体,并没有完全实现本体的推理,同时对本体模型的建立也需要进一步优化,这些都是今后研究工作的重点。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|