


{kind=link}
{kind=link}
{kind=link}
一种基于生命周期理论的文献热点发现方法——以肿瘤领域为例
引用本文
赵迎光, 安新颖, 李勇, 贾晓峰. 一种基于生命周期理论的文献热点发现方法——以肿瘤领域为例. 现代图书情报技术, 2012, 28(11): 86-91
Zhao Yingguang, An Xinying, Li Yong, Jia Xiaofeng. A Method for Detecting the Hot Topic of Literature Based on Lifecycle——A Case Study of Neoplasm Field. 现代图书情报技术, 2012, 28(11): 86-91
Permissions
Zhao Yingguang, An Xinying, Li Yong, Jia Xiaofeng. A Method for Detecting the Hot Topic of Literature Based on Lifecycle——A Case Study of Neoplasm Field. 现代图书情报技术, 2012, 28(11): 86-91
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
一种基于生命周期理论的文献热点发现方法——以肿瘤领域为例
摘要
针对文献热点发现方法存在的指标单一、高频常用词过滤效果不明显等问题,将TDT领域的生命周期理论和TF*PDF方法应用到文献热点发现中,通过跟踪词在时间上的变化率来发现热点词,并确定热点出现的具体时间。实验结果表明,该方法能够有效过滤掉高频常用词,对各时间窗内的研究热点有较高的识别率。
关键词:
生命周期理论; 热点发现; 文本挖掘
中图分类号:G250
A Method for Detecting the Hot Topic of Literature Based on Lifecycle——A Case Study of Neoplasm Field
Abstract
There are some shortcomings of hot topic detection in literature,such as single index and the inefficient filtering of high-frequency common words. The paper applies lifecycle theory and TF*PDF algorithm to literature detection, which finds the hot words by tracking the variation of words over time, then locates the time hot words appeared. The results of the empirical tests show that this approach is effective in filtering high frequently used terms and identifying hot research topics in time windows.
Keyword:
Lifecycle theory ; Hot topic detection ; Text mining
1 背景
科研领域中数字资源的急剧增加以及跨学科研究的快速发展,为科研人员及时、准确地获取其研究领域的热点和动向提出了更高的要求。同时,随着TDT(Topic Detection and Tracking)技术的发展,越来越多的新闻和社会网络热点挖掘方法和工具被研究和应用,为用户从海量网络信息环境中获取有用信息提供了更加便捷的工具,但是在文献监测领域中热点发现方法则发展较为缓慢。目前国内的文献热点发现技术大都是通过词频、引文以及聚类等传统方法识别热点研究领域[ 1],存在指标单一和聚类结果模糊等问题。国外关于学科趋势的研究中,基于词频、文档频的方法也较多,例如BioJournalMonitor[ 2]文献趋势发现系统中采用了词频变化率来进行趋势的计算,Swan等[ 3]从研究主题所包含的文档数角度构建了TimeMines系统;Guo等[ 4]综合构建了多指标的学科趋势发现系统,其核心仍然集中于词频、共词及聚类,需要建立完善的停用词表来过滤高频停用词,否则热点信息容易被大量高频常用词的噪音所淹没。
生命周期理论已经在TDT领域得到了广泛应用并表现出了较好的效果,本文将TDT领域的生命周期理论应用到文献监测领域,构建文献领域的热点发现方法,从而为科研和决策提供支持。
2 相关理论研究
2.1 关于热点的界定
Bun等[ 5]在新闻热点话题监测方面做了较多的工作,认为新闻中的热点话题是指在一段时间内出现频率相对较高的话题,话题热度通过两个指标来衡量:话题在一篇新闻报道中出现的次数和包含该话题的新闻报道的数量。同时, Bun等认为每个热点话题都不可能无限“热”下去,它们都要经历一个产生、增长、成熟和消亡的生命周期过程。Chen等[ 6]在Bun等的基础上对热点话题进行了更详细的描述。
科技文献中的研究热点不同于新闻热点,新闻热点通常以新闻话题的形式出现,而在科研过程中,例如肿瘤研究中的新药物、基因以及治疗方法常常能够成为研究热点,因此本文将热点界定为独立的词,如果某个词在某一个时间段内的热度值相对较高,就将其作为该时间范围内的研究热点。借鉴Chen等对新闻热点话题的定义,本文认为文献领域的研究热点需同时满足以下条件:
(1)在一个期刊中,包含该研究的文献数量相对较多;
(2)关于该研究的文献分布在多个期刊中;
(3)与该研究主题相关的其他研究在同时间段内出现较多;
(4)该研究的热度随时间变化明显。
2.2 词权重计算
词的权重计算是热点发现过程中的重要阶段,通过计算每个词在文章或者期刊中的重要程度,就可以用这些词来表示文章或者期刊。文献[7-9]分别使用了TF*IDF、词在文档中的分布与整个语料库中分布的差异、共现偏移量等方法来计算权重。在目前的词权重计算方法中,最常用的是TF*IDF方法[ 10],将词频和逆文档频次的乘积作为词在集合中的权重,这种方法认为在一定文档中出现而不在另外文档中出现的词权重较大,而对在所有文档中都出现的词则赋予较低的权重。在带有时间信息的新闻报道流中,使用TF*IDF算法有一定的局限性,例如在大量报道开始报道该事件之前或者在事件发展前期,TF*IDF算法可以起到较好的识别作用;当大量媒体和新闻都开始报道或者在事件发展中后期,出现该事件中一些关键词的文档越多,其IDF值就越小,所以使用TF*IDF算法将不能完整识别和跟踪一个热点事件或热点主题,在科研领域也是如此。
Bun等[ 11]在2001年提出了TF*PDF算法,对TF*IDF算法进行了改进,避免了在TF*IDF算法中当一个重要的词在多个文档中出现时其权重减小的问题。
基于上述原因,本文中的模型采用TF*PDF算法作为词频权重计算方法,TF*PDF算法对于在大量文档中出现频次较高的词赋予较高的权重,而对于出现次数很少的词赋予较低的权重。
2.3 生命周期理论
词权重根据词在文档中的分布情况反映其权重,属于空间上的属性;而词的生命周期反映的是它在时间上的变化趋势。2003年,Chen等[ 12]首先提出了新闻事件的生命周期模型,将新闻事件按照生命周期分为产生、增长、衰退和消亡4个阶段,并提出了能量函数的概念来跟踪事件的生命周期,通过新闻报道频次和衰退因子分别建模新闻事件在生命周期中的增长和衰退过程,之后在TDT领域得到了广泛的应用。文献[13-16]将生命周期理论应用于新闻、SNS (Social Networking Services)、博客等领域的热点发现,并取得了较好的效果。文献[6]在生命周期理论中引入了能量值和生命值两个指标,并将新闻站点数量也作为一个变量引入模型,在实验中取得了理想的结果。
本文基于这样一个前提:文献中的热点一定具备生命周期特征。如果一个研究主题在时间上的变化率越大,则其生命周期属性越强,成为热点的可能性就越大。对于高频常用词,例如肿瘤领域的Human、Patients、Malignant Neoplasm(恶性肿瘤)等,虽然其出现频率很高,但是由于不具有生命周期特征,因此不能成为热点。同时,考虑到科研领域热点生命周期较长,因此文献覆盖的时间越长,生命周期值的计算就越准确。
3 模型构建
本文借鉴了Chen等[ 6]在新闻领域的热点监测算法,将其用于文献监测领域。
3.1 使用TF*PDF计算词的权重
|Ft,c|exp 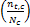
将Bun等[ 11]算法中的媒体用期刊来代替。则给定一个文献集合C,对于词t,其在期刊集合c中的TF*PDF值的计算方法为:
TF*PDF=
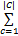 | (1) |
|Ft,c|=
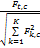 | (2) |
其中,Ft,c是词t在期刊c中出现的频次,|Ft,c|则是对Ft,c的标准化处理,|C|是文献集合中期刊数量,nt,c是期刊c中出现词t的文档数量,Nc是期刊c中的所有文档数量, K是c中所有词的个数。因此如果一个词的词频越大,并且包含该词的期刊越多,TF*PDF值就越大。
3.2 使用生命周期理论计算词的变化率
= 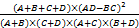
由于文献中的科学研究领域的主题生命周期一般较长,而且各种类型的期刊出版周期(月刊、季刊)不同,因此以年为单位进行热点词的识别,算法如下:
(1)计算词t在一个时间窗s内得到的能量,用Et,s表示:
Et,s=nf×
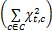 | (3) |
其中,nf是能量转换因子(Nutrition Transfer),是主观设定的常量。C是所有期刊,c∈C,使用卡方检验的统计量 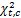
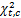 | (4) |
其中,A、B、C、D均表示词在时间窗及集合中出现的个数,具体算法如表1所示:
| 表1 公式(4)参数说明 |
(2)计算词t在时间窗s内的生命值:
lifesupportt,s=ln(Engt,s) (5)
其中,lifesupportt,s是词t在时间窗s中的生命值;Engt,s是在时间窗s上词t获取的能量值。
(3)使用标准差计算词t的生命值变化率Vt:
Vt=
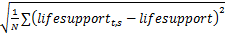 | (6) |
其中,N是在给定的时间段内时间窗个数,lifesupportt,s是t在时间窗s内的生命值,lifesupport是t在所有时间窗内的生命值的平均值。
3.3 选取具有生命特征的热点词
根据公式(1)和公式(6)分别计算出TF*PDF和Vt后,计算每个词的热点值:
(1)按照TF*PDF值对词进行降序排列,得到其权重顺序值Weight Order (WO),TP*PDF值最大的词其WO=1。
(2)按照变化率Vt顺序值Variance Order (VO)进行降序排列,变化率最大的词其VO=1。变化率越大,生命周期特征越明显,而常用词则不会表现出生命周期特征。
(3)使用WO和VO的差值计算Bonus Point (BP),BP用于增加或减少词的最终权重,当VO小于WO时,BP为正数,意味着使用该词的变化率较大:
BP=WO-VO (7)
(4)计算权重修正系数:
WeightModifier=
 | (8) |
其中,TermNum为所有词的总个数,WeightModifier介于-1和1之间。
(5)最终权重为:
NewWeight=TF*PDFt+Vart×(1+WeightModifier) (9)
其中,TF*PDFt是t的TF*PDF值,Vart是t生命值的变化率。
经过上面的步骤,每个词都被赋予新的权重,然后通过新的权重对所有词进行排序,选取前n个词作为整个时间段内的热点词。
3.4 各时间窗中热点词的确定
在新闻热点话题识别中,通常以天为单位识别出短期内的热点事件;而以年为单位识别出的则是长时间段内的热点,因此还需确定各个热点在生命周期中出现的时间,具体算法如下:
热点词t在时间窗s内的生命值指数(Lifesupport Index)为:
lifesupportIndext,s=
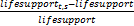 | (10) |
生命值指数是对生命值的标准化处理,从而可以实现不同词在同一时间窗内的比较。lifesupportIndext,s是热点词t在时间窗s内的生命值指数,将每个时间窗内的热点词按照Lifesupport Index降序排序,选取前m个热点词作为该时间窗内的热点词。
4 实验与分析
为了验证热点发现算法的可行性,笔者使用Java语言实现了热点识别程序,对热点发现过程中的TF*PDF值、生命值、生命周期变化率进行了计算,识别出每年的热点词。
4.1 数据源
实验数据来自于PubMed数据库,根据2011年SCI影响因子排名,选取肿瘤领域的前10个肿瘤期刊,时间范围为2001-2010年,最终得到36 229条Medline格式的数据作为实验数据源。
4.2 数据预处理
为了提高热点识别率,在数据预处理过程中,使用概念映射工具MetaMap[ 17]将每篇文章的标题映射为NCI主题词,NCI词表覆盖了肿瘤领域的临床治疗、基础研究等领域的概念和术语。同时保留映射过程中的语义类型,获取NCI主题词11 123个,并建立文档-词矩阵。
为了减少计算时间,提高计算效率和准确度,在计算中只选取了频次大于等于10的词进行计算,共3 136个。
4.3 词权重与生命周期计算实验
使用TF*PDF算法计算概念的词频权重,使用生命周期算法计算Variation,并计算出最终热点值,表2为根据公式(1)TF*PDF选出的前5个词与根据公式(9)NewWeight选出的前5个词。
| 表2 TF*PDF与 NewWeight分别选出的前5个词 |
其中,Patients、Clinical Trials、New等不具备明显热点特征的词TF*PDF值较大,这与TF*PDF算法对在越多的期刊中出现的词赋予越大的权重有关。为了更清晰地对比两种算法的差别,它们的生命周期曲线如图1所示:
 | 图1 TF*PDF与TF*PDF+Lifecycle Variation比较 |
从图1可以看出,尽管TF*PDF值最高的几个词都是肿瘤领域的常用词,出现频次和文档频次都较高,但却不具备生命周期特征,也不能反映出研究热点;而使用TF*PDF和生命周期相结合的算法综合考虑了词频、文档频次和生命周期变化率的影响因素,结果中的MicroRAN为近年来肿瘤领域的研究热点[ 18],Cancer Stem Cell(肿瘤干细胞)为刚刚兴起的研究领域,有良好的发展前景[ 19]。 因此使用生命周期能够有效过滤掉高频常用词,同时生命周期曲线准确反映了其随时间的变化趋势。
4.4 热点计算结果分析
根据公式(10)计算热点词在每个时间窗内的生命值指数,获取每年热点词;同时使用UMLS提供的语义类型将热点词分为不同的类,得到每个细分领域的研究热点,2009年与2010年肿瘤领域热点药物如表3所示:
| 表3 2009年与2010年肿瘤领域热点药物 |
表3中的药物基本上都是肿瘤分子靶向药物,分子靶向药物也是近年来的研究热点,利用肿瘤细胞与正常细胞之间分子生物学的差异,抑制肿瘤细胞的生长增殖,最后使其死亡。近年来,肿瘤分子靶向治疗因具有疗效高、不良反应少且轻等特点而备受瞩目,各种新型分子靶向治疗药物成为近年来的研究热点,并逐步成为临床肿瘤治疗的重要部分。2009年肿瘤领域热点研究药物生命周期如图2所示:
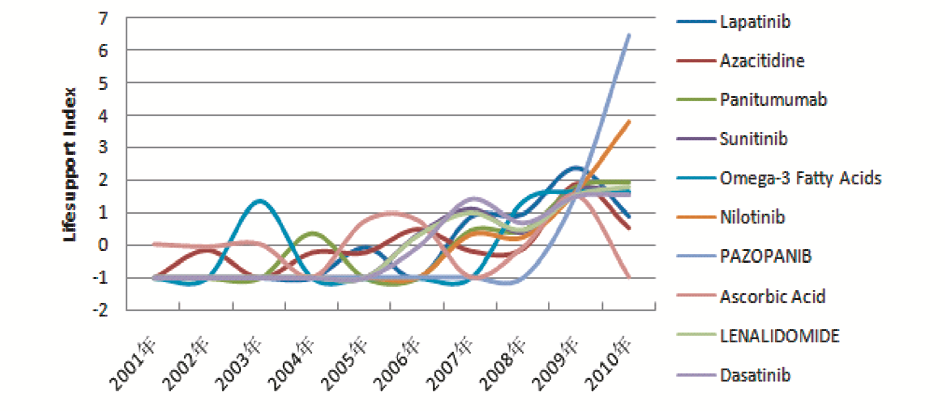 | 图2 2009年肿瘤领域热点研究药物生命周期 |
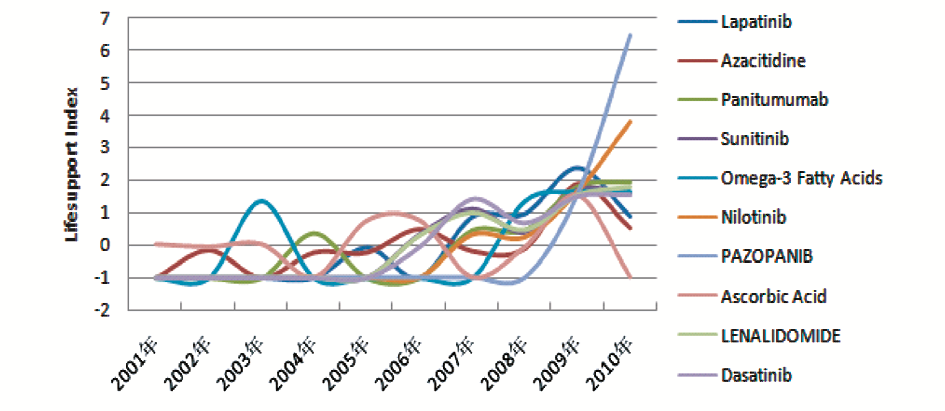
为了验证算法在时间维度上的准确性,将结果和Google Trends进行了对比。Google Trends通过分析Google 网络搜索以计算用户输入的词被搜索的次数,并将其与 Google 上随时间推移的搜索总量相比较,用图表向用户显示结果。以2009年的10个热点药物为关键词,从Google Trends中下载完整数据(2004年-2010年,Google目前只提供2004年之后的数据),并对其进行标准化处理,如图3所示:
 | 图3 Google Trends中用户对2009年科研热点药物的关注度 |
从图3可以看出,在10个所关注的热点词中,7个热点词和图2的生命周期一致,均在2006年与2007年得到了用户关注度的峰值,而其余的三个词在这几年间则一直是平缓的下降趋势,分别是Omega-3 Fatty Acids、Ascorbic Acid、Azacitidine。而图2中的Omega-3 Fatty Acids在2003年、Ascorbic Acid在2005年都有一些峰值的出现。通过对语义类型的分析,发现是由于MetaMap中的语义类型将临床药物、有机化学物质和药理物质归为一类,因此造成了不属于药物的Omega-3 Fatty Acids、Ascorbic Acid等并没有被过滤掉,这是算法需要改进的地方。
此外,图3和图2中的峰值相差了2-3年的时间,以Panitumumab(帕尼单抗)为例进行分析。Panitumumab是结直肠癌治疗的分子靶向药物,2005年7月,Panitumumab获得FDA (Food and Drug Administration)快速通道审批资格。2005年底,安进公司及其合作伙伴Abgenix公司共同向FDA提交了该品生物制剂许可申请,用于治疗化疗失败后转移性结直肠癌。通过对Google Trends的搜索发现,2006年的用户关注度大都与该事件有关,相关新闻报道量增多,而此时对该药物的研究大都处于保密状态,研究文献较少。该药物投入市场后,在基础研究和临床中的研究逐渐增多,因此在科研领域,该药物研究的生命周期峰值出现在2009年。其他的几种药物均有类似的情况。
5 结语
本文在生命周期理论的基础上,设计并实现了基于生命周期的文献热点发现方法,并在肿瘤领域进行了初步的实验,实验结果表明该算法能够有效地过滤高频常用词以及识别时间窗内的研究热点,但仍存在一些问题需要在下一步的工作中继续深入研究:
(1)算法中的阈值设置:算法中涉及多次根据阈值选取热点词的过程。在大规模、不同类别的数据处理中,依靠人工设置来选取存在可靠性和效率较低等问题,因此在未来研究中需要解决各个阶段阈值的设置问题。
(2)热点主题的范围:本文通过算法较为准确地识别出部分热点词,但是并没有发现和这些词相关的其他词,例如对于热点药物Panitumumab,如果能够找出和它相关的疾病以及治疗方法,将会为科研人员提供更大的帮助,这也是下一阶段的研究方向。
(3)算法在其他领域的可扩展性:由于该算法目前只在肿瘤领域进行了测试,在其他学科的通用性还需继续试验。同时,本文使用了医学领域的概念映射工具对词进行降维并识别其语义类型,最后实现了热点药物的提取。在其他学科中如果没有类似工具的支持,则算法还需改进。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|