

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
关联模型支持下的关联参考服务研究*
引用本文
刘媛媛, 李春旺. 关联模型支持下的关联参考服务研究* . 现代图书情报技术, 2012, 28(12): 15-20
Liu Yuanyuan, Li Chunwang. Study on the Reference Service with Linked Model. 现代图书情报技术, 2012, 28(12): 15-20
Permissions
Liu Yuanyuan, Li Chunwang. Study on the Reference Service with Linked Model. 现代图书情报技术, 2012, 28(12): 15-20
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
关联模型支持下的关联参考服务研究*
关键词:
关联模型; 关联参考服务; 关联数据
中图分类号:G350.7
Study on the Reference Service with Linked Model
Abstract
Based on the introduction of the reference service and main entities related to scholarly information, this article discusses the structure of the linked model and puts forward a modeling proposal. According to the characteristics of the linked model, it analyzes search technologies of linked data, and the building of relevance reference services.
Keyword:
Linked model; Relevance reference service; Linked data
1 引 言
科研人员在阅读学术文献时,经常会遇到科研实体对象(如科学家、研究项目、研究机构、学术会议等)、专业术语、学科主题等信息点,以这些信息点为中心(称作“锚点”)提供语义关联的参考信息,可以帮助读者更好地理解当前文献内容以及扩展获取相关知识,这便是关联参考服务[ 1]。传统的关联参考服务主要是引文链接服务,随着网络化、数字化技术的发展,关联参考服务形式开始变得多样化,相关研究与应用也受到更多的关注。
2 相关研究
在美国国家数字图书馆(National Science Digital Library, NSDL)建设时期,约翰·霍普金斯大学(The Johns Hopkins University)与塔夫斯大学(Tufts University)曾提出一个基于关系数据库资源的关联参考服务方案SCALE[ 2],即通过自动抽取文献中的名词术语并建立参考链接,为用户提供关于这些名词术语的解释说明信息。随着关联数据的发展与应用,数据间关联关系的揭示更深入、更丰富,从而为建设高质量的关联参考服务提供有效支持,因此,基于关联数据的关联参考服务成为当前研究的热点。例如,爱尔兰国立大学数字研究所(Digital Enterprise Research Institute, DERI)利用关联数据构建一个推荐服务,当用户浏览一个音乐家信息时,系统自动推荐相关的其他音乐家信息[ 3];Sonntag等[ 4]利用关联数据中的DrugBank、 Diseasome和DBpedia资源为医学图像提供注释说明服务,帮助医生进行疾病诊断并根据病症给出相关的药物信息;Haslhofer等[ 5]利用关联数据为视频资源添加注释信息,帮助用户理解视频内容。在关联模型研究方面,国内外有多个项目对科研活动中各类实体对象之间的关系界定与描述等都有过深入的研究,有的成果已经得到应用并形成有效服务。其中,文献[6]讨论了基于本体的知识管理机制;斯坦福大学研发了科技信息语义搜索工具VIVO[ 7];奥地利格拉茨科技大学的CAF-SIAL[ 8]则针对关联参考服务提出一个论文作者信息概念模型,支持构建数字期刊关联参考服务。
本文在借鉴前人研究成果基础上,结合关联参考服务需求,抽取研究人员、研究项目、研究机构、学术会议、研究成果等常用实体对象的属性、关系等,构建综合科技信息关联参考模型,并探索基于关联参考模型指导下的关联数据发现、获取以及关联服务构建策略。
3 关联模型分析与设计
3.1 模型结构
为选择确定关联参考服务构建途径,首先需要准确识别锚点实体对象可能存在的关联关系。在构建数字图书馆关联参考模型时,CAF-SIAL的思想值得借鉴。CAF-SIAL模型分三层:顶层是分面推理层(Inferred Aspects Layer),它将期刊论文作者的关联信息分为4个方面,即社会信息(Social)、专业信息(Professional)、个人信息(Personal)、负面信息(Dark Side);底层是资源知识库层(Aggregation Knowledge Bases Layer),汇集相关关联数据资源的类别属性信息;中间是属性映射层(Property Aggregation Layer),建立顶层分面属性信息与底层资源库类别属性之间的映射关系,支持关联数据发现。
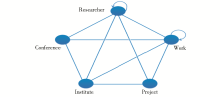
在科技信息服务领域,读者除关心论文作者信息(Researcher)外,还会关心同一作者的其他“科研成果” (Work)、论文作者所属的“研究机构”(Institute)、产出论文所依托的“研究项目”(Project)以及提供论文交流的“学术会议”(Conference)等信息,它们共同构成了科技文献关联参考服务的典型实体对象。对这些实体对象属性的描述以及对实体对象之间关系的揭示,形成了科技文献关联模型,如图1所示:
 | 图1 科技信息关联模型 |
3.2 实体关系描述
关联模型各实体间存在多种关联关系。在图1所示的关联模型框架中,除Conference与Project之间没有直接关联关系外,其他实体两两之间都存在一种或多种关联关系,如Work与Researcher之间存在作者关系(author_of)、成果关系(contribution_of),Project与Institute之间存在资助关系(fundedBy)、管理关系(administratedBy、contributor_of)。另外,同一个实体对象本身也可能存在关联,如两个Researcher实例之间可能是合著者关系(co-author),两个Work之间可能存在引用关系(citeFrom、citedBy、co-citedBy)。实体关系的揭示为以某一实体对象为中心的关联服务构建提供路径指导。科技文献典型实体关联关系如表1所示:
| 表1 典型实体对象关联关系 |
3.3 实体属性描述
实体属性是指描述实体的基本信息项目,可以作为实体间关联关系发现的依据,即通过实体属性相似度计算发现两个实体间的一致性(sameAs)等关系。表2是科技信息关联模型中常见实体的主要属性信息。有些实体也可以先做子类细分,再对不同子类实体定义属性项目,以便提高属性描述的针对性。
| 表2 典型实体对象描述属性 |
3.4 关联实体建模实例
在关联模型建模时,需要综合考虑关联参考服务需求以及关联数据资源特点。其中,参考相关领域常用关联数据源的属性定义,并依据每个属性在数据实例中的使用次数由高到低进行选择,可确保关联实体对象建模的有效性。
以科研人员(Researcher)为例,在确定Researcher实体属性时,本文提出的策略是:以DBpedia本体中Person类的Scientist子类为基础[ 4],同时参考FOAF本体、SWRC本体以及Freebase 的Person类[ 5]。通过查询DBpedia的SPARQL端点[ 6],获取Scientist实体所有描述属性和数据实例中属性使用次数,按照数据实例中属性使用的次数进行排名,并根据排名进行属性项的选择,具体包括:姓名(name)、出生日期(birthDate)、邮箱(mbox)、博客(weblog)、职业(occupation)、研究领域(field)、获奖信息(prizes)等;利用常用实体对象关联分析结果,为处于中心位置的核心实体Researcher建立与关联实体之间的关系,包括:与关联实体Institue之间的雇佣关系(employer_of)、与Project之间的开发关系(developer_of)、与conference之间的参与关系(participateIn)、与Work之间的著作关系(author_of)以及与其他Researcher之间的合作关系(co-author)等。Researcher实体建模实例如图2所示。
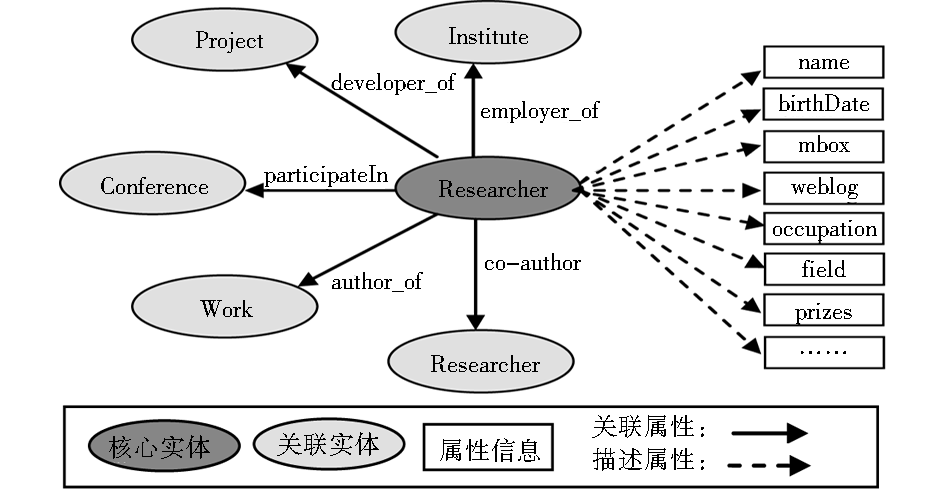 | 图2 Researcher实体关联模型 |
其他实体对象的建模过程与此类似。其中,Institute实体属性可以DBpedia本体中的Organization类的EducationInstitute[ 9]子类为基础,参考Freebase的Organization类确定[ 10];Project实体属性可以DOAP本体为基础,参考DBpedia本体Project类的ResearchProject子类确定[ 11];Work实体属性可以DC为基础,参考SWRC本体及DBpedia本体Work类的Book子类[ 12]确定;Conference实体属性可以DBpedia本体中Event类的Convention子类描述为基础[ 13],参考SWC本体确定。
4 基于关联模型的关联数据搜索策略
4.1 星型搜索
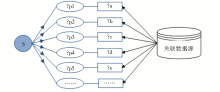
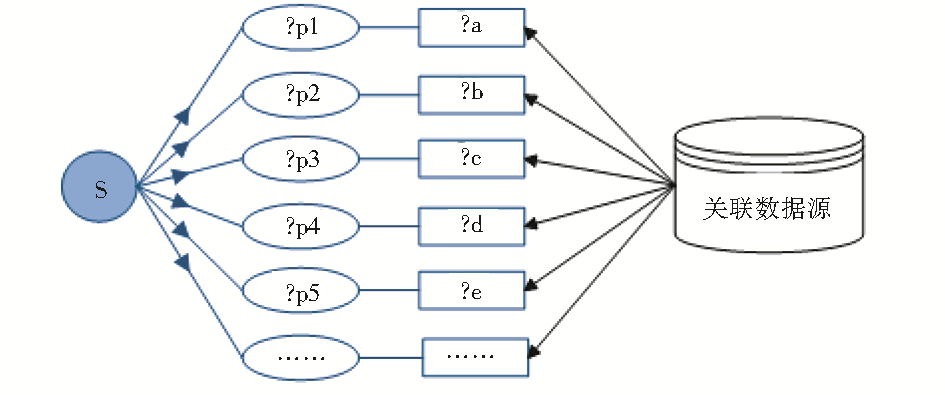
星型搜索是针对核心实体描述属性,发现、获取与每个描述属性项对应的关联数据信息,生成与核心实体对象对应的关联数据实例,如图3所示:
s表示一个核心实体对象,它包含多个描述属性?p1、?p2、?p3 ……,星型搜索过程就是从相关数据源中发现与这些属性对应的关联数据?a、?b、?c ……,并建立“属性-值”映射关系,以便支持科研用户通过实体描述属性渠道获取感兴趣的相关信息。
(1)基本搜索法
根据关联数据源情形不同,关联数据星型搜索的常用方法分为两类:
①在数据源确定的情形下,采用HTTP URI探寻法与SPARQL查询法。HTTP URI探寻法是依据关联模型中的描述属性信息提取主题词,再针对已知目标资源URI构成规则,将抽取的主题词合成URI,最后访问URI探寻是否存在对应资源;SPARQL查询法则利用已知目标资源提供的查询终端,提交SPARQL查询式,搜索并获取相关RDF数据。
②在数据资源不确定的情况下,借助语义搜索引擎从Web空间采集关联数据资源,经索引后支持用户查询,帮助用户发现相关关联数据信息。
HTTP URI法、SPARQL法查准率较高,但查询范围仅限于已知资源空间;搜索引擎法可以搜索未知资源空间,查全率较高,但查准率不理想。
(2)基于知识库搜索法
为解决HTTP URI、SPARQL、搜索引擎等方法的不足,扩大信息搜索范围,改善搜索效果,可以采取基于知识库的关联数据搜索法。具体方法是:从关联资源描述体系中抽取属性信息,建立资源属性数据库(S-base);从关联模型中抽取实体属性信息,建立实体属性数据库(E-base);再建立E-base与S-base之间的映射关系,支持从关联模型实体属性出发搜索发现包含在相关资源中的相关属性数据[ 14]。
抽取资源属性信息前,需要选择与各个实体对象相关的重要关联数据源。具体策略是:选择综合的、被广泛链接的HUB资源(如DBpedia);选择特定实体对象专指资源(如与Work实体对象对应的DBLP资源);选择特定领域的资源;选择属性名称与关联实体属性名重叠率高的数据源等。资源确定后,利用SPARQL法查询指定数据源,获取所有相关实体类型(Type)的属性信息以及每种属性在数据实例中使用频次信息;合并语义相同属性项并将使用频次累加;选择使用频次大于指定阈值的属性项作为知识库入选信息项,必要时可选择全部属性项。
采取自动化与人工相结合的策略建立映射关系。首先直接比较关联模型属性与资源属性的名称字段,建立名称相同属性之间的对应关系;如果属性名称不同,借助WordNet等工具,获取属性名称的同义词,以同义词匹配资源属性名称,建立相同属性之间的映射关系;对于不能自动识别匹配的属性,需要人工建立映射关系。针对一种属性多种描述形式的情况,需要建立一对多的映射关系。
4.2 链型搜索
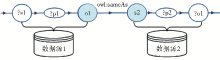
链型搜索是针对核心实体的关联属性,利用关联数据之间的连接关系,发现、获取与之相关的关联实体数据,生成与核心实体对象对应的关联数据实例。在RDF图中,核心实体与关联实体分别作为主语或宾语,中间通过谓词连接,如图4所示:
在数据源1中,核心实体o1作为宾语,与相关实体?s1通过谓词?p1链接;在数据源2中,核心实体s2作为主语通过谓词?p2链接到相关实体?o1;数据源1的核心实体o1与数据源2的核心实体s2存在owl:sameAs关系。利用以上实体之间的关系,借助SPARQL等查询方法实现链型搜索。根据搜索策略的不同,链型搜索可分为关联谓词搜索、共指谓词搜索以及混合搜索。
(1)关联谓词搜索
关联谓词搜索主要用于在一个数据源内部发现相关实体对象。例如,在DBpedia中,使用关联谓词搜索可以找到核心实体对象人(Person)的工作机构实体(Institute),从而建立两实体对象间的数据关联,支持用户在浏览科研人员信息的同时,参考其工作机构信息。与描述属性不同,一个数据源内所包含的核心实体之外的关联实体类型是有限的,因此,关联谓词搜索最好根据数据源所包含的实体类型情况制定具有针对性的搜索策略。
(2)共指谓词搜索
共指谓词搜索是利用owl:sameAs关系在不同数据源之间发现相同实体对象的过程。在相关性排名最高的数据源中,通过关联谓词搜索找到核心实体的关联实体;通过共指谓词搜索找到与该数据源具有owl:sameAs连接的其他数据源中的核心实体;对每个新找到的相关数据源进行关联谓词搜索,获取关联实体的描述属性信息。例如,在DBpedia中发现核心实体对象人(Person)的信息后,利用owl:sameAs共指谓词搜索,在数据源DBLP中发现这个人的相同实体信息,再利用关联谓词dc:creator搜索DBLP,获取到这个人的作品信息,从而建立科研人员实体(Person)与成果实体(Work)之间的链接,支持用户在浏览一名科学家信息的同时,扩展浏览其学术成果信息。
(3)混合搜索
由于关联实体的类型较多,从一个数据源同时获取多种类型关联实体信息的可能性较低。为支持不同类型关联实体的搜索,需要选择多种不同的数据源,数据源选择可以借助星型搜索知识库或者借助语义搜索引擎。针对同一类型关联实体,也可以从多个不同数据源中搜索,从而获得同一实体对象的不同方面信息,其中通过对描述属性信息的合并,可以弥补星型搜索只局限于一个数据源的不足。混合搜索就是综合利用关联谓词搜索与共指谓词搜索,从而达到提高搜索结果精度和广度的目标,因而,在实际开发中被广泛采用。混合搜索具体策略如下:
①确定目标数据源集合;
②针对指定核心实体对象q,依次选择目标数据源集合中的每个资源R,对其实施星型搜索,发现获取相关数据信息,同时,发现核心实体对象q在数据源R中存在的所有owl:sameAs连接信息;
③按照步骤②,递归搜索以上发现的所有owl:sameAs连接数据源;
④全部初选目标数据源及owl:sameAs连接数据源搜索完毕,或达到指定遍历深度,搜索结束。遍历深度可根据实际情况由人工确定。
5 关联参考服务实现
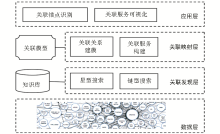
基于以上模型方法和搜索策略,本文实现了一个关联参考服务原型系统,由4层组成,如图5所示:
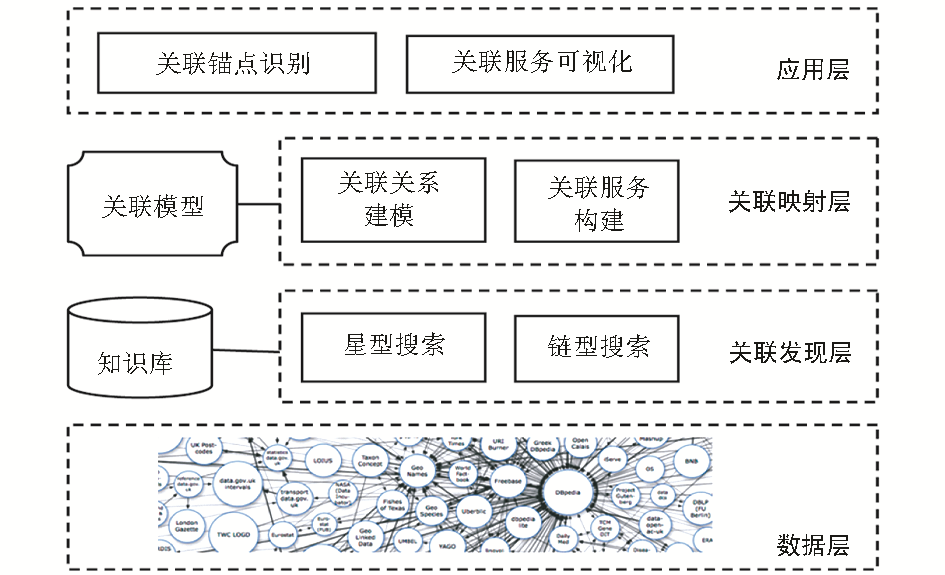 | 图5 关联参考服务系统层次结构 |
应用层包括关联锚点识别、关联服务可视化两部分,前者负责从用户当前阅读文献中识别用户感兴趣的关联信息对象,作为构建关联参考服务的锚点,后者将系统最终构建的综合信息对象以可视化方式呈现给用户;关联映射层借助关联模型方法,分析关联锚点对象的关联关系,指导相关信息发现以及将发现的关联信息融合为综合信息对象;关联发现层则借助知识库,采取星型、链型搜索策略实现对相关信息的发现、获取;最底层是数据层。原型系统借助GATE工具实现关联锚点识别,借助开源工具Jena[ 15]实现对RDF文档的解析并支持SPARQL查询,利用Sindice4j[ 16]支持在未知数据源情况下发现、获取相关描述属性数据和关联实体数据,借助MySQL实现对实体属性与谓词映射知识库信息的保存。
 | 图6 关联参考服务截图 |
为有效支持多种关联实体对象信息的发现,笔者选择了语义网研究领域作为实验环境,主要的关联数据资源是Semantic Web Dog Food(SWDF)[ 17]以及DBpedia、DBLP。其中,SWDF包含人物、机构、会议、会议论文等实体信息;DBpedia包含人物、组织、项目、会议等信息;而从DBLP则可获取学术论文、作者、会议等信息。图6是一个基于论文作者的关联参考服务截图,它以用户当前阅读论文作者(Tim Berners-Lee)为核心实体构建关联参考模型,经星型搜索、链型搜索,获取关于该作者的基本属性信息,同时提供该作者的其他科研成果信息以及与该作者相关的其他科研人员信息、学术会议信息、组织机构信息等,支持用户扩展获取多种关联信息以及关联线索。
6 结语
本文在分析科技信息对象的属性结构与关联关系基础上,提出一个包含科研人员、研究项目、研究机构、学术会议、研究成果等实体的关联参考模型,讨论了基于关联模型指导下的关联参考服务建设技术与策略,这些研究对数字图书馆信息服务系统建设具有一定的借鉴性。然而,本文中讨论的关联参考模型只包含常用科技信息实体对象,尚不能满足复杂的关联参考应用需求。同时,关联参考服务质量受多方面因素影响,包括关联数据发布质量、关联关系语义识别能力、关联信息过滤效果以及可视化呈现策略等,这些方面需要在今后的研究中进一步加强。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|