{kind=link}
{kind=link}
{kind=link}
CSSCI语料中短语结构标注与自动识别*
引用本文
谢靖, 苏新宁, 沈思. CSSCI语料中短语结构标注与自动识别* . 现代图书情报技术, 2012, 28(12): 32-38
Xie Jing, Su Xinning, Shen Si. Chinese Phrase Tagging and Automated Annotation Based on CSSCI Corpus. 现代图书情报技术, 2012, 28(12): 32-38
Permissions
Xie Jing, Su Xinning, Shen Si. Chinese Phrase Tagging and Automated Annotation Based on CSSCI Corpus. 现代图书情报技术, 2012, 28(12): 32-38
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
CSSCI语料中短语结构标注与自动识别*
摘要
将短语结构标注引入CSSCI期刊论文题录信息分析,在关键词、术语构成上从语法角度深度探讨各组成词汇之间的语法关系,力图通过语法功能分析揭示其所蕴含的语义知识。在进行一定规模语料标注基础上,通过短语词汇、词性统计及短语语法功能分析获取学术文献中短语结构构成特征,并将这部分特征与清华树库语料短语特征混合,提高短语结构在科技文献中的识别率。
关键词:
短语结构标记; CSSCI语料; 混合特征; 自动识别
中图分类号:TP391
Chinese Phrase Tagging and Automated Annotation Based on CSSCI Corpus
Abstract
The paper introduces a new syntax method as the solution of term phrase identification on CSSCI corpus, and obtains the inter-relationship among terms in academic literature from the linguistic aspect based on phrase components, such as words, part-of-speech, grammar functions, etc. These linguistic features are mixed with phrase features which are extracted from Tsinghua Treebank so as to leverage the accuracy of phrase auto-identification in academic corpus.
Keyword:
Phrase annotation; CSSCI corpus; Multi-feature; Auto-identification
1 引 言
目前的科技文献检索在内容检索方面主要是通过关键词检索完成,其中涉及到词面相似度计算、关键词概念层次计算等方面。在专家的帮助下,可以通过主题法、分类法、概念描述体系、主题分类一体化等传统检索语言方式实现对检索的扩充与优化,如可以通过对检索词的分析,寻找其中的上下位类关系,对关系最为密切的词汇概念进行二次检索。通过关键词的共现也可以寻找这些词汇之间的潜在关系,并对共现较多的词汇进行联合查询。但无论主题法、分类法、概念描述,还是词汇共现都有一定的缺陷,即对于主题法、分类法、概念描述,需要领域专家和语言学家的介入,需要消耗大量的人工与精力,同时主题法、分类法、概念描述体系具有一定的滞后性,不能反映出当前学科关键词及知识的创新,在使用时用户也需要对分类法进行学习后才能正确标注与查询。 在计算语言学取得重大进展的前提下,可以通过将语言学知识引入信息检索领域,借助短语知识反映关键词、术语内部成分间的语法关系,也可以通过对标题、摘要甚至正文中小句的短语分析获取关键词、术语之间的语法联系,这种联系可以作为语义信息的组成部分。
本文在清华树库标注体系基础上,将其应用于CSSCI语料短语标注,选取“知识组织”、“知识服务”为检索词,将相关文献中的标题、关键词进行短语识别与标注。在此基础上,考察在学术语料中汉语短语组成及其分布情况,这主要从组成词汇、词性序列及短语语法功能等方面进行考察。这些特征在随后被加入以清华树库短语知识为基础的训练语料,提高短语标注在领域科技文献中的识别率。在人工标注过程中,标题、关键词短语中定中结构出现频次最高,本实验即选取定中结构为研究对象,并以最短定中结构(无嵌套定中结构)设定相关语言学特征。实验结果精确率达86.79%,召回率82.51%,F值为84.60%,表明这种混合标注策略具有一定实用价值。
2 国内外研究现状
在计算语言学方面,Chomsky[ 1]在1957年提出了转换生成语法,将语言学由经验主义引入理性主义,通过转化生成理论可以对句子进行机器规则识别。Abney[ 2]在1991年提出句子可以被划分为更小的组成即Chunk,这种基于组块的句法与基于转换规则的句法有很大不同,通过Chunk可以将句子划分为若干更小的结构,对这些小的结构可以进行进一步的观测。基于组块的语料库使得计算语言学得到飞速发展,通过统计的方法可以完成对语言规则的抽取,同时也避免了基于规则研究的局限性。美国宾夕法尼亚大学在1989年启动了“The Penn Treebank Project”,并于20世纪90年代推出英文U-Penn树库,其语料来源为华尔街语料(WSJ)、布朗语料(BROWN)以及两个口语语料SWBD和ATIS[ 3]。周强[ 4]通过多层标注设计并标注了清华大学中文树库(Tsinghua Chinese Treebank, TCT),该树库是国内比较成熟的中文短语树库,也是国内第一个基于平衡语料的短语树库。
树库的出现为计算语言学提供了学习素材和实验平台,尤其是其中短语的语法功能可以作为研究词汇间语义关系的基础。通过对中文短语树库的统计与观测,可以对其中短语结构进行自动识别,通过对短语的语言特征统计,基于统计的模型可以对短语进行序列标注,进而实现机器学习,最后在语料库上对标注和训练情况进行对比分析。陈静等[ 5]在大规模语料的基础上,通过对兼语结构语言学特征统计,使用条件随机场进行短语自动识别。朱丹浩等[ 6]通过对清华树库中介宾结构内外部语言特征的统计,使用条件随机场模型对介宾结构进行自动识别。
近年来,在术语相关的研究中,开始引进自然语言的计算机处理方法和技术,出现了“计算术语学”(Computational Terminology)学科。冯志伟[ 7]在1988 年就注意到术语的自动处理问题,他在德国夫琅禾费研究院(Fraunhofer Institute)使用计算机对汉语的词组型术语进行了自动结构分析,他也是较早将计算术语学引入我国的学者,介绍了国外学者对术语的发现、术语的充实、术语的受控标引、术语的自由标引等问题的研究[ 8]。在词汇及词组的概念上,冯志伟[ 9, 10]对中文单词型术语及短语型术语均进行了结构分析,并从语言学的经济原则角度探讨了单词型术语和短语型术语在术语库中的分布,提出了术语形成的经济律(FEL公式),从数学公式上完成了对术语系统的经济指数、单词的术语构成频率F 和术语的平均长度L的公式表达[ 11]。这些研究将语言学知识引入术语短语研究,通过这种研究可以在语义上获取更多关于术语概念、成分等信息。
3 CSSCI标注语料
在清华树库标注体系基础上,通过对CSSCI关键词、标题的简单分词及词性标注,借助清华树库短语知识进行辅助标注。标注语料为以“知识组织”、“知识服务”为关键词对所有标题进行检索,将相关文献关键词及标题通过ICTCLAS进行初步分词及词性标注,共涉及文献369篇。在分词及词性标注基础上,通过清华树库相关词汇及短语前后词汇、词性知识进行人工辅助标注,具体标题标注样例如下:
[np-DZ [np-DZ [sp-FW [np-DZ 新/a 环境/n ] 下/f ] 的/u [np-DZ 图书馆/n [np-DZ 知识/n 服务/vN ] ] ] 探讨/vN ]
对应文献关键词标注为:
[np-DZ 网络/n 环境/n];[np-DZ 知识/n 服务/vN];[np-DZ 信息/n 资源/n];
| 表1 CSSCI语料辅助标注结果—以“知识组织”、“知识服务”为例 |
需要说明的是,在辅助标注的同时,本文对其中分词及词性标注错误进行了修正,主要包括几个方面:
(1)分词错误,如“[定量分析/l]->[定量/b 分析/vN]”,这类错误较少,可在今后标注中通过导入领域词典减少切分错误;
(2)后缀词汇切分及标注错误,如“[学科/n 化/v]->[学科/n 化/k]”,这类问题在分词上存在争议,有学者认为应当将其视为一个词汇,但在本研究中,仍将这类词汇以后缀形式进行分词及词性标注,以便对此种构成的短语术语概念进行语言学分析;
(3)词性标记错误,例如“[协同/v]->[协同/vN]”,在关键词及标题中,对于研究对象涉及动词,科技语料与通用语料有很大不同,动词名词化并与研究对象构成术语现象较多,大部分词性标记错误均与此相关。
表1为部分标题及对应关键词短语标注结果,同时也附上相关错误校正记录。在标注基础上,通过对标注语料解析获取相关标题、关键词中的短语知识,这些知识将在今后研究中用于统计及机器训练。
4 CSSCI标注语料分析
4.1 关键词短语分析
在这部分标注语料中,可以通过关键词短语标注获取与“知识组织”、“知识服务”相关的术语词汇、短语,并分析其语言学构成,进而进行语义分析。表2为相关关键词单词型、词组型分布情况,表3为关键词短语层次分布情况。
| 表2 标注CSSCI语料关键词类型及所占比例 |
| 表3 标注CSSCI语料关键词短语层次分布情况 |
从表2可知,在“知识服务”、“知识组织”相关文献中,短语型关键词占绝大多数,所占比例为84.36%,经过去重后,所占比例为84.82%。在科技文献中,短语型术语占绝大多数,因而可以通过短语标注研究其构成。从表3可知,在词组型关键词中,一层短语占大多数,二层短语次之,三层短语及以上较少。这个数据表明,在短语型关键词中,学者较多使用一层短语,从短语结构及词性序列中,可以看出这与科学研究本身有密切联系。
| 表4 标注CSSCI语料关键词短语结构分布情况 |
| 表5 标注CSSCI语料关键词短语内部词性序列前10位 |
从表4和表5可知,在短语型关键词中,定中结构占绝大多数,其词性序列主要有“n+n”、“n+vN”、“vN+n”、“a+n”等。在结构上,定中结构更能反映科学研究对象以及相关概念词汇间的组合关系。例如,词性序列为“n+n”的定中结构中,两个名词词汇往往是研究对象,如“[np-DZ 高校/n 图书馆/n ]”;词性序列为“n+vN”的定中结构中,名词为研究对象,通过与名词化的动词结合,形成特定概念术语,如“[np-DZ 知识/n 组织/vN ]”,这类术语中,动名词与名词间往往可以通过转化形成述宾结构,即“[vp-PO 组织/v 知识/n ]”。但是,并非所有“n+vN”定中结构都可以转化为述宾结构,例如“[np-DZ 知识/n 服务/vN ]”,这里就名词与涉及动词的支配关系有关,这里只能理解为“提供知识的服务”或是“基于知识的服务”。
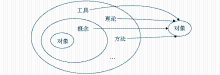
在以“知识组织”、“知识服务”为检索词的文献关键词中,“知识”是研究对象,通过与动词“组织”、“服务”的名词化相结合,形成独立的概念,在此基础上又可以继续与“工具”、“系统”等词汇继续结合形成新的概念。在进一步结合的过程中,由于关注点不同,学者对于其中词汇的倾向也不同,在短语词汇结合上会产生差异。其中由研究对象词汇与其他词汇结合为新的概念,并继续构建相关概念理论、方法、工具的过程如图1所示,示例如图2所示:
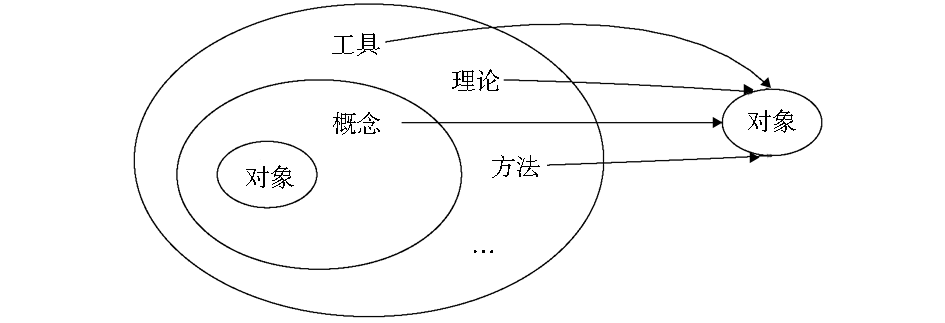 | 图1 标注CSSCI语料关键词短语构造过程 |
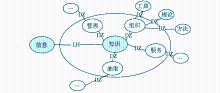
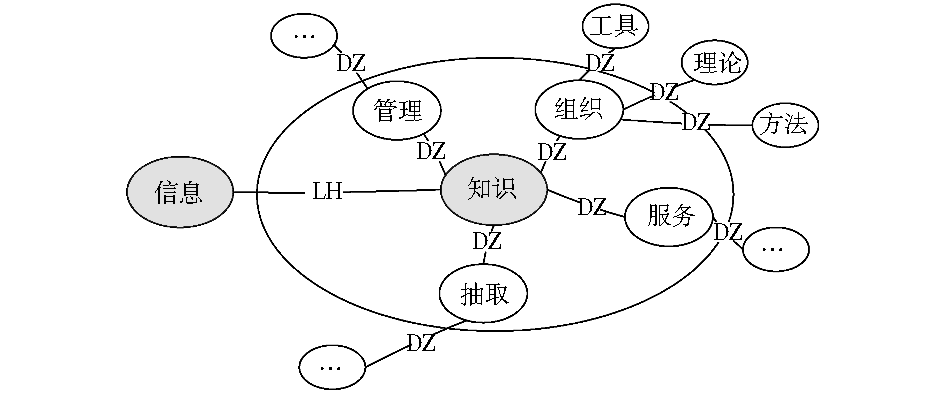 | 图2 标注CSSCI语料关键词短语构造示例 |
4.2 标题短语分析
在研究标题中这些词汇无关的概念之间的短语关系之前,首先对其进行基本情况统计,主要包括短语结构统计、短语功能统计、层次分布情况、词性序列统计等。表6为标题中短语层次统计,表7为主要短语结构统计。
| 表6 标注CSSCI语料标题中短语层次分布情况 |
| 表7 标注CSSCI语料关键词短语结构分布情况 |
从表6可以看出,在以“知识组织”、“知识服务”为检索词的文献标题中,随着短语层深的增加,其分布数呈不均匀下降趋势。结合表7以及关键词短语标注情况,在关键词共现短语间若不存在共现词汇时,通过定中、介宾、方位、补充等短语结构,可以将这些词组型术语短语进行语法连接,不同的短语结构具有不同的语义特征。例如,定中结构可以表现研究对象概念的扩展,如“知识”通过定中结构扩展为“知识管理”、“知识抽取”、“知识组织”、“知识服务”,进而扩展到“知识组织工具”、“知识组织方法”等。相关涉及概念可以通过介宾与定中结合,完成两个及以上术语概念的语法联系,如“[np-DZ [pp-JB 基于/p [np-DZ 网格/n 技术/n ] ] 的/u [np-DZ [np-DZ 数字/n 图书馆/n ] [np-DZ 知识/n 服务/vN ] ] ]”,“网格技术”通过介宾短语,与“数字图书馆”、“知识服务”这两个概念词组联系起来。介宾结构在标题级短语标注中,通常可以表现概念间的方法、工具、理论等语义,方位结构则可以表现概念间的条件及上下位概念关系,补充结构通常为论文标题副标题,即对论文主标题的进一步语义解释等。通过结构组成分析,可以获取相关词汇、概念短语之间的语法联系,进一步分析其语义联系。
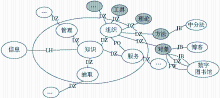
需要说明的是,对标题中的短语标注时以相应关键词短语为参考标准,不同学者对相同文本的理解存在差异,其关注点也会随之变化,对于相同序列的词汇短语标注也应随其认知而改变。在图2基础上,图3对内容相关的术语短语间通过更高层次短语知识进行关联的展示。通过高层次的定中、介宾、方位、补充等,可以实现多个术语概念短语的共现分析,这种分析可以获取概念短语间的语法关系,从而获取其修饰关系。如在定中结构中,充当定语部分的概念短语修饰充当中心语部分的概念短语,介宾结构中作为宾语部分的概念短语通过更高层次的定中结构,充当高层中心语短语的修饰部分,语义上可以进一步分析为工具、理论、方法等。
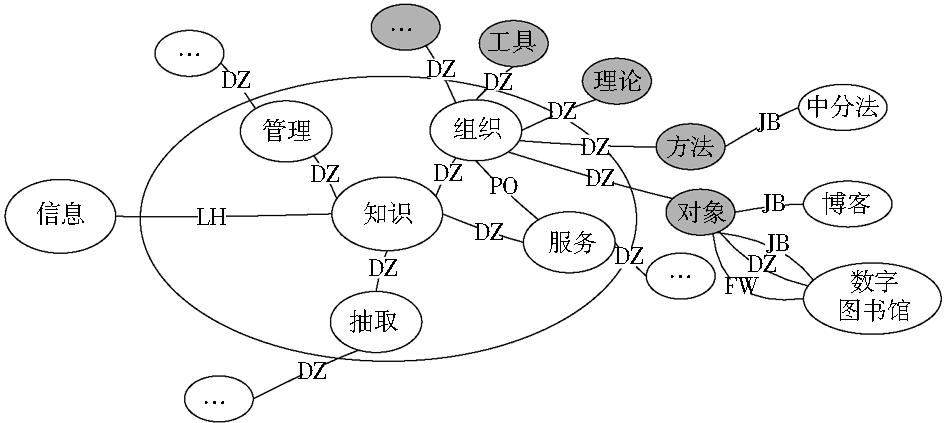 | 图3 标注CSSCI语料标题中术语短语间语法关联 |
5 基于CSSCI短语自动识别
在以上标注语料统计中,通过“知识组织”、“知识服务”对标题进行检索的结果中,关键词短语大部分为一层短语,且定中结构为多数。本实验以一层定中结构为识别对象,以清华树库中无嵌套定中结构为训练样本,同时将关键词短语中定中结构短语作为辅助,进行混合样本训练,用于识别标题中最短定中结构。由于人工标注工作量较大,而只是用通用语料特征进行训练会缺失专业领域知识。通过少量关键词短语标注,辅以通用语料短语内外部特征,进行CSSCI标题中最短定中结构识别。选择CRFs为训练模型[ 12],训练模板设置如表8所示,识别情况如表9所示,结果统计如表10所示。
从表10可知,在标注语料标题中,共有最短定中短语848个,识别结果为892个。其中,前后边界一致、前界一致后界错误的短语均为736个,其精确率为86.79%,召回率为82.51%,F值为84.60%。通过对最小定中结构的识别,可以获取标题中与关键词短语
| 表8 条件随机场特征选择 |
| 表9 标注语料标题中最短定中结构识别情况 |
| 表10 标注语料标题中最短定中结构自动识别结果统计 |
最为相关的一层定中结构,其中绝大多数被作者标记为关键词。这些短语可以作为作者及用户关注焦点,通过更高层次的短语知识进行组合,从而通过语言网络进行语义扩充。
6 结语
本文提出面向CSSCI的短语自动识别方法,并通过CSSCI语料标注及机器训练验证了这些思想在应用中的现实依据。在研究中,通过对语言学知识的引入,将CSSCI中关键词、术语短语之间建立语法功能关系,同时又通过对CSSCI数据的计量验证了短语语法功能等语言学思想,最后通过条件随机场对CSSCI中的最短定中结构完成基于混合训练语料的自动识别,取得很好的效果,其精确率为86.79%,召回率为82.51%,F值为84.60%。该数据表明,可以通过少量人工标注领域文本,辅以通用语料库知识进行领域语料中相应术语短语结构的识别,从而通过语法研究其构成词汇隐藏的语义知识。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|