

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
锐化高斯模板在文本特征项权重调整方法中的应用*
引用本文
路永和, 何新宇. 锐化高斯模板在文本特征项权重调整方法中的应用* . 现代图书情报技术, 2012, 28(12): 39-44
Lu Yonghe, He Xinyu. An Application of Sharpen Gaussian Template in a Text Feature Weight Adjustment Methodology. 现代图书情报技术, 2012, 28(12): 39-44
Permissions
Lu Yonghe, He Xinyu. An Application of Sharpen Gaussian Template in a Text Feature Weight Adjustment Methodology. 现代图书情报技术, 2012, 28(12): 39-44
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
锐化高斯模板在文本特征项权重调整方法中的应用*
摘要
阐述二维高斯模板和锐化高斯模板的构建过程及其对图像的锐化处理技术,提出文本特征项权重调整方法的主要思想,并以此为依据,论述基于锐化高斯模板的文本特征项权重调整方法。以搜狗自然语言实验室的文本分类语料库中的新闻文档作为实验对象,采用宏平均F测度值作为分类效果评价标准,采用中心点法和K-最近邻方法(KNN)作为分类器的分类算法进行实验。实验结果表明:在KNN分类法下,基于锐化高斯模板的文本向量模型权重调整方法起到提升分类效果的作用,但对中心点法的影响并不大。
关键词:
文本分类; 锐化高斯模板; 向量空间模型; 文本特征
中图分类号:TP391
An Application of Sharpen Gaussian Template in a Text Feature Weight Adjustment Methodology
Abstract
This paper introduces Gaussian Template and Sharpen Gaussian Template in computer image processing technology and summarizes main ideas of text feature weight adjustment,then proposes a text feature weight adjustment methodology based on Sharpen Gaussian Template. With corpus of Sogou Lab Data, KNN classifier and Class-center classifier, this methodology is experimented by Macro-averaging F-measures. The experimental result shows that the KNN classifier with this methodology performs better than the traditional method. However,Class-center classifier with this methodology has no significant improvement.
Keyword:
Text categorization; Sharpen Gaussian template; Vector space model; Text feature
1 引言
随着信息技术的飞速发展,人类已经进入信息极大丰富的时代,信息数量的迅猛增长使得“信息爆炸”成为人们当前不得不面对的一个现实问题。尽管信息的形式多种多样,但文本信息仍然占有主要地位。文本分类技术作为处理和组织大量文本数据的关键技术,可以在较大程度上解决信息杂乱的问题,方便用户准确定位所需的信息和分流信息,对于信息的高效管理和有效利用都具有现实的意义。在文本分类技术中,文本一般采用向量空间模型(Vector Space Model, VSM)来表示,文本向量的维度通常达到成千上万维。传统分类方法在进行分类时都会面对两个问题,即过度拟合和过度泛化。本文将图像处理中的高斯模板处理技术应用在文本分类器中,以改善上述两个问题,进一步提高文本分类效果。
2 相关研究
2.1 文本特征项权重
由于计算机无法直接识别无结构化的文本,所以在进行分类之前需要将文本转化为计算机可以操作的形式化结构。根据研究方法分类,目前关于文本表示的研究大致可以分为两类:基于统计的方法,例如布尔模型、概率模型和向量空间模型;基于语言学的方法,这类方法尝试通过语言学中的知识来弥补基于统计方法的不足(忽略文本的语言学特征),但是实验证明这类方法在分类性能上并没有明显的提高,反而复杂性有所增长。统计方法由于具备可理解性好、效率高、效果好等优点,是目前最为流行的文本表示方法,其中的VSM 模型在文本分类中应用非常广泛。
决定文本表示方法后,便可以通过分类器对文本集进行分类。在基于相似度计算的分类方法中(如KNN、类中心、支持向量机、部分集群智能分类法等),判断文本之间相似度的标准一般定义成文本向量之间对实数域的一个映射。在属性值都是标量的情况下,这种映射通常表示为两元素间归一化后的欧氏距离、曼哈顿距离、闵可夫距离、余弦度量等。故文本向量在文本空间内的分布形式对文本向量之间关系的判定有决定性影响。
影响文本向量空间分布的因素主要是特征项权重的计算方式。传统的特征权重计算方法主要有布尔权重、词频权重(Term Frequency, TF)、反文档频率(Inverse Document Frequency, IDF)、结合两者的TF-IDF(Term Frequency- Inverse Document Frequency)权重等。TF-IDF将文档集作为整体来考虑,其中IDF的计算并没有考虑到特征项在类间和类内的分布情况。针对这一缺点,国内外许多学者提出了不同的改进方法。How等[ 1]提出Category Term Descriptor(CTD)算子来解决IDF因子受数据集偏斜影响的问题。Deng等[ 2]提出Category Relevance Factors(CRF)来代替IDF,以体现特征词所在文档所属类与其他类的区分能力。张保富等[ 3]提出的基于类内信息分布熵的权重计算方法,将特征项在类间和类内的分布情况纳入TF-IDF的计算过程中。李原[ 4]同样也将信息熵引入TF-IDF计算公式中,由此计算特征项在语料集中分布的不确定性度量。张瑜等[ 5]的WA-DI-SI特征权重改进算法引入了类间偏斜度(SI)、类内离散度(DI)和权重调整因子(WA)来表达特征项在类间分布的差异性。罗欣等[ 6]根据对文章中出现次数较少的词所含信息量的分析,提出基于词频差异的特征选取,并且在其基础上提出了改进的MTF-IDF权重计算公式,该公式同时考虑了特征项在类间和类内的分布。吕佳[ 7]在TF-IDF中引入特征项在类内出现次数的方差项,以此来体现特征项在类间和类内的分布情况。同样,苏力华等[ 8]认为,对于两个出现相同频率的特征项,在类间分布越不均衡的反而更为重要,故在其改进TF-IDF公式中,引入归一化的类间标准差来体现这种思想。上述各项研究都是围绕特征项在类间或者类内分布开展的,本文提出一种在特征项权重公式计算完成以后,在文档向量空间内根据文档向量之间的相似性对特征项权重实施进一步调整的方法。
2.2 锐化高斯模板
在计算机图像处理领域中,高斯模板是指用高斯函数生成的权值不为零的元素组成的系数矩阵。高斯模板主要作为低通滤波器在图像平滑领域中广泛应用[ 9, 10],利用高斯模板对图像中每个像素进行变换,以减小图像噪声以及降低细节层次,增强图像在不同尺寸下的图像效果。从数学的角度看,对图像应用高斯模板的过程就是图像与正态分布做卷积。在实际应用中,常采用二维高斯模板对图像进行平滑处理。对高斯模板做进一步的处理可得到锐化高斯模板[ 11],具体算法过程如下:
(1)设二维空间中的高斯函数为:
g(x,y)=
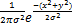 | (1) |
其中,x,y表示二维空间中两个维度上的权值,σ是正态分布标准差。
设生成的系数矩阵为G,高斯模板的平滑半径为r (r2=x2+y2, r=3,5,7…),则用高斯函数生成r×r的高斯模板为:
G=
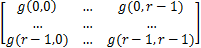 | (2) |
其中归一化系数为:
α=
 | (3) |
(2)设f(x,y)为原图像(x,y)点的灰度值,以其为中心取一个r×r的窗口,窗口内像素组成的点集以A来表示,设f'(x,y)为经模板处理后的(x,y)点的灰度值输出,有:
f'(x,y)=α(x,y)∈Af(x,y)g(x,y)(4)
由f'(x,y)输出重新组合而成的图像即为经高斯模板处理后的图像。从公式(4)可以看出,其生成的权值不为零的元素组成的系数矩阵与原始图像进行卷积。原始像素的值有最大的高斯分布值,所以有最大的权重。相邻像素随着距离原始像素越远,其权重也越小,每个像素的值都是周围相邻像素值的加权平均,最终呈现出来的效果就是图片变“模糊”。
(3)设f(x,y)为原图像(x,y)点的灰度值,f'(x,y)为经高斯模板处理后的图像中(x,y)点的灰度值,设p(x,y)为(x,y)点处原图上的灰度值和处理后图像上的灰度值之差,即:
p(x,y)=f(x,y)-f'(x,y)(5)
又设:
p'(x,y)=f(x,y)+p(x,y)(6)
由于高斯模板本质上是一种低通滤波器,具有平滑函数的作用。图像中物体边缘部分中心像素的灰度值和其周围的像素点的灰度值之差较大,在与模板进行卷积处理时会被平滑(被抑制),因此和其他像素点相比,边缘灰度值变化量较大,公式(5)中p(x,y)输出的正是这种变化量。公式(6)中将这种变化量叠加到原来的灰度值f(x,y)上,增强了原图中边缘部分的灰度,起到了一种“锐化”的边缘增强效果。
实际上,设高斯模板G的归一化系数为α,设矩阵:
A=
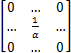 | (7) |
又设系数矩阵:
G'=αA+(αA-αG)(8)
即为锐化高斯模板,将G'和原图像进行卷积可输出边缘增强的图像,等价于公式(5)、公式(6)中的处理效果。
3 基于锐化高斯模板的文本特征项权重调整方法
3.1 基本思想
张爱华等[ 12]认为特征项权重因子应具备以下特点:对所属文档的代表性;区分不同文档的能力;对所属类别的代表性。在其基础上,本文将权重因子的特点归纳为以下两点:
(1)对所属文档的代表性
所选取的权重因子应能够唯一地表示一篇文档。传统TF-IDF权重计算方法中,文档的代表性通常采用词频(TF)表示。
(2)对所属类别的代表性
包括两方面含义:要体现出在某类别下空间上或数量上的分布特征,如传统的TF-IDF权重计算方法;要体现所属类别特点。在许多相关研究中,体现所属类别代表性的因子通常为文本特征选择中的评估函数值,例如某维度的CHI值或IG值。
以往研究中,对特征项权重的改进主要集中在加入一个或多个权重因子,或者对现有的权重因子进行改进以加强其代表性。本文提出一种能够增强权重因子对所属类别代表性的文本向量特征项权重调整方法,该方法主要依据的思想是:在某个文档集中,某个类别是由多个拥有相似属性(如描述相似主题、相似事物或者以相似角度描述事物)的文档子集组成。某子集内的某个文档与该子集内的其他文档之间的相似性比其与不同子集内的文档的相似性高。对于某一个子集,存在一些特征项,其在不同文档间的权重方差比较小;同时也存在另一些特征项,其在不同文档间的权重方差比较大。一般而言,该子集中权重分布差异较大的那些特征项所含的信息量往往比子集中的其他特征项所含的信息量大。强化这些特征项将有利于增强类内文档子集相对于其他类内子集的区分度,从而增强了该特征项在各类别中的区分能力。
3.2 方法构建
, 
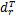
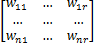
基于上述思想,如果将某个子集中权重方差较大的特征项称为该子集的“边缘项”,那么锐化高斯模板图像处理可以类比于对“边缘项”的权值调整。据此本文提出一种基于锐化高斯模板的文本特征项权重调整方法,具体步骤如下:
(1)设一维高斯函数:
g(x)=
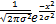 | (9) |
其中x为维度值。设平滑半径为r,可得长度为r的高斯数列,即一维高斯模板:
Gr=[g(0),g(1),…,g(r-1)](10)
其中归一化系数为:
α=
 | (11) |
设长度为r的系数数列如下:
A=[ 
设一维锐化高斯模板为:
(2)设类别Ci中一篇文档dj=(wj1,wj2,…,wjn),调整后的文档特征向量为 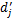
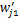
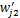
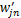
sk=sim(dj,dk)∈[0,1], 1≤k≤m(14)
将{sk|1≤k≤m}按递减顺序排序,设s1≥s2≥s3≥…≥sm,构造由 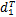
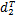
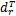
Dj=(
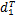 | (15) |
令:
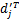
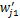

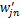

求得:
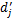
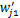
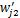
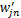
从上述过程可以看出,该调整方法考虑了特征项在相关文档中的分布。公式(15)中,在r不大的情况下,与文档dj相似的前r篇文档往往是属于同一个子集。公式(16)中,利用一维的锐化高斯模板 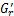
4 实验结果与比较
4.1 实验设计
实验采用搜狗自然语言实验室的文本分类语料库[ 13],选取其中1 800篇新闻文档作为实验对象,包括汽车、财经、IT、健康、体育、旅游、教育、招聘、军事9大类,每类200篇文档,其中100篇作为训练文档,100篇作为测试文档。分词部分为中国科学院计算技术研究所分词库ICTCLAS2012,采用一级标注集标注词性。特征选择方法采用GHImax。文档表示采用VSM模型,分别在200、400、600、800、1 000、1 200、1 400、1 600、1 800、2 000维度下进行实验。特征权重计算采用传统TF-IDF和两种常见的权重计算方法LOGTF-IDF和LOGTF-IDF-CHI[ 12],具体公式如下所示:
wTF-IDF=tfidlog
 | (18) |
wLOGTF-IDF=log(tfid+1)log
 | (19) |
wLOGTF-IDF-CHI=log(tfid+1)log 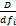
其中,tfid为特征项i在文档d中出现的次数,D为训练集中的文档总数,dfi为特征项i的逆文档频率,即训练集中出现特征项i的文档数量。
为了消除文本长度对特征权重的影响,对特征权重进行归一化处理,这里采用常用的Cosine归一化,具体公式如下[ 14]:
wid=
 | (21) |
其中,wid为文档d的特征项i的权重,N为特征向量的维数。
实验采用中心点法和K-最近邻方法(KNN)作为分类器的分类算法,其中KNN邻居数K=15,设锐化高斯模板半径r=5。相似度计算采用常用的Cosine函数,公式如下[ 14]:
sim(di,dj)=cosα=
 | (22) |
其中,sim(di, dj)表示文档i和j之间的相似度,wik表示第i个文档的第k个属性值,n为特征向量的维数。
本文采用宏观F测度值(Macro-averaging F-measure, MF)作为分类效果评价标准。
4.2 文本分类实验结果与分析
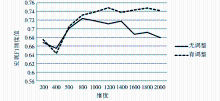
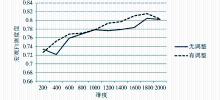
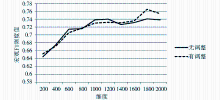
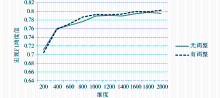
在不同维度下,分别应用KNN和中心点分类方法对采用本文方法调整(有调整)和不采用本文方法调整(无调整)进行实验对比,结果如图1至图6所示:
 | 图1 KNN分类法下TF-IDF实验结果 |
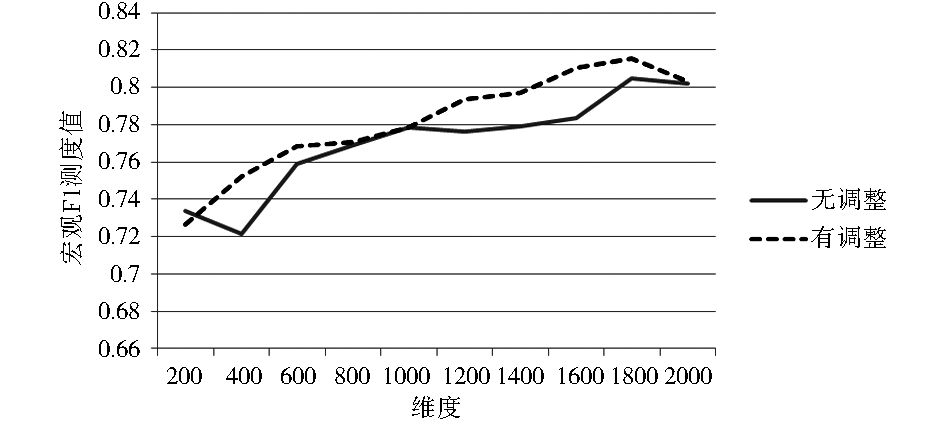 | 图2 KNN分类法下LOGTF-IDF实验结果 |
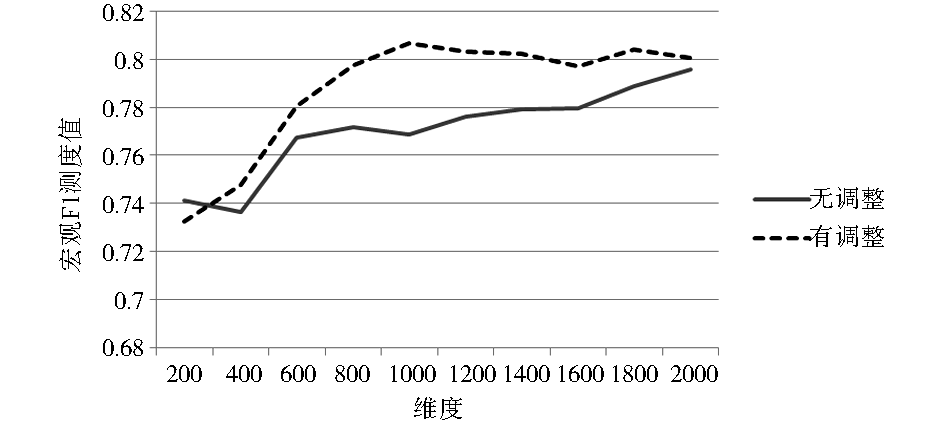 | 图3 KNN分类法下LOGTF-IDF-CHI实验结果 |
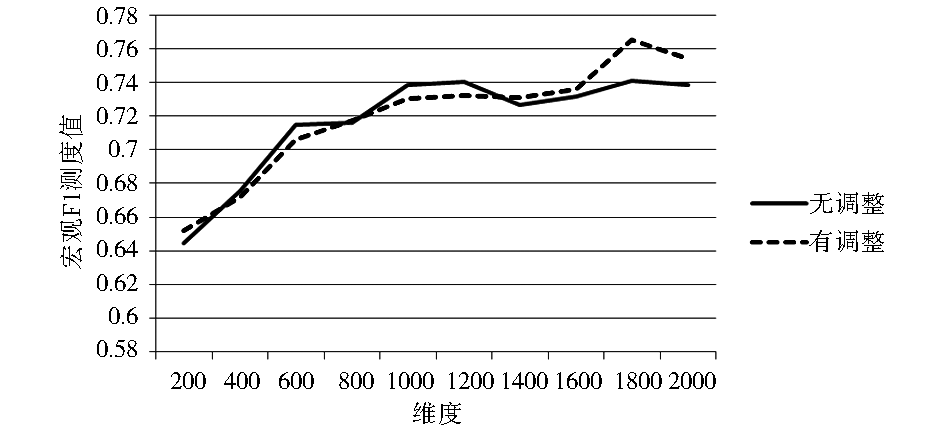 | 图4 中心点分类法下TF-IDF实验结果 |
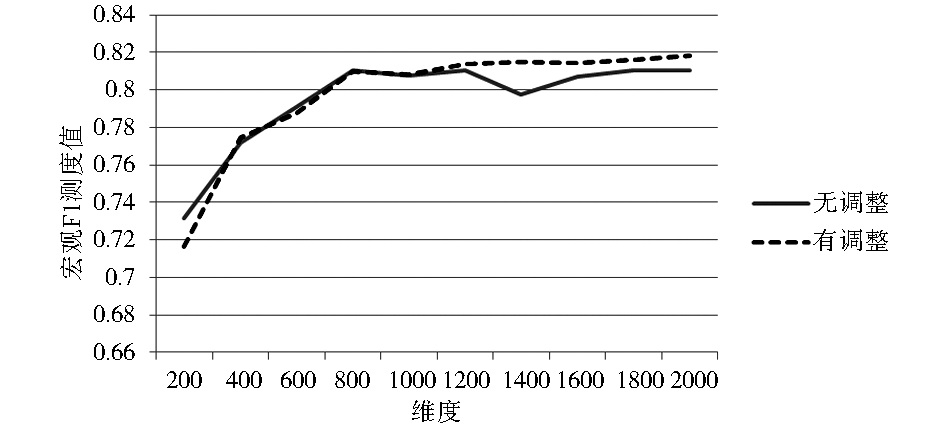 | 图5 中心点分类法下LOGTF-IDF实验结果 |
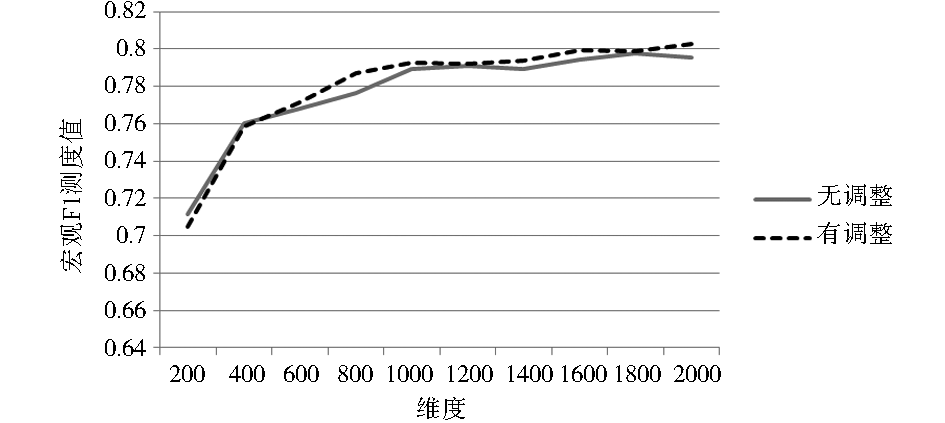 | 图6 中心点分类法下LOGTF-IDF-CHI实验结果 |
(1)KNN分类方法
从实验结果可以看出,在KNN分类法下,基于高斯模板的文本向量模型权重调整方法的确起到了提升分类效果的作用。
(2)中心点法
从实验结果可以看出,本文方法对中心点法的影响不大。中心点法中,中心向量的某一维度上的权值是由该类别中所有其他向量在该维度上的权值的平均值构成的。因为在中心点法中,特征权重方差较大的特征词的权重对中心向量的影响较小,而本文的权重调整方法是针对特征权重方差较大的特征词,故权重调整的效果会被削弱。与之相反,KNN分类方法本质上是一种均权重的投票分类策略,可以明显地体现出本文所提出的权重调整算法的效果。
5 结语
本文介绍了文本分类所涉及的一系列技术,并且受图像处理领域中的高斯模板处理技术启发,提出了基于高斯模板的文本特征项权重调整方法。实验表明,该权重调整方法能有效地提高分类器的性能。与其他特征项权重调整方法相比,本文方法的特点主要在于将图像处理技术运用在文本分类技术中,考虑了特征项在当前文档及其相似文档中的分布,文档特征项权重的计算受其相似文档影响。
但是本文中的基于锐化高斯模板的文本向量模型权重调整方法还有以下两个不足之处:
(1)解释性不强。本文还不能用数学语言来描述实验结果产生的原因,对实验结果的解释还仅仅处在推理和模拟高斯模板处理图像过程的层面上。未来研究应该集中于探究权重调整过程的数学逻辑,从数学层面解释实验结果。
(2)权重调整方法的效果与分类器过度耦合。本文提出的文本向量模型权重调整方法是基于相似度邻域的。实验数据表明,当使用中心点法进行分类时,权重调整方法并没有取得很明显的效果。在目前的各种文本分类器中,权重调整方法可能仅适用于基于邻域投票分类的分类方法。如何令权重调整方法适用于更多分类方法(如支持向量机等)是进一步研究的主要内容。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|