



{kind=link}
{kind=link}
{kind=link}
{kind=link}
利用LDA的领域新兴主题探测技术综述*
引用本文
范云满, 马建霞. 利用LDA的领域新兴主题探测技术综述* . 现代图书情报技术, 2012, 28(12): 58-65
Fan Yunman, Ma Jianxia. Review on the LDA-based Techniques Detection for the Field Emerging Topic. 现代图书情报技术, 2012, 28(12): 58-65
Permissions
Fan Yunman, Ma Jianxia. Review on the LDA-based Techniques Detection for the Field Emerging Topic. 现代图书情报技术, 2012, 28(12): 58-65
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
利用LDA的领域新兴主题探测技术综述*
摘要
以LDA为基础,系统梳理新兴主题探测以及主题趋势探测技术中的LDA以及其他LDA改进主题模型的发展现状。介绍LDA的变分推导和Gibbs抽样两种参数推导算法;总结近年来LDA模型的改进,包括对主题演化建模的主题模型、对文档内容和元数据联合建模的模型、采用在线式学习的主题模型及将LDA和引文分析相结合的主题演化方法等,并对不同的改进模型进行深入对比和分析;梳理NIH-VB、TIARA、VxInsight等几种主要的主题模型可视化技术。最后通过对LDA模型的总结分析,探讨利用LDA模型探测领域新兴主题时的关键研究问题。
关键词:
主题模型; LDA; 引文分析; 主题模型可视化
中图分类号:TP393
Review on the LDA-based Techniques Detection for the Field Emerging Topic
Abstract
Based on LDA,this paper reviews the development of the LDA model and several models which improve the LDA for the filed emerging topic detection.It describes two parameter inference algorithms of variational derivation and Gibbs sampling, and reviews the improvement of LDA in recent years,including the one modeling the evolution of the topics,the one modeling jointly with the content of document and meta data,the one with online learning, the topic evolution method combining LDA and citation analysis and so on;then compares and analyses different kinds of improvement models in details. The paper also reviews several main visualization techniques such as NIH-VB,TIARA and VxInsight. Finally,it discusses the key research problems of detecting the emerging topic by using LDA.
Keyword:
Topic model; LDA; Citation analysis; Topical visualization
1 引 言
作为科研人员,要跟踪所在学科的最新发展动向,就要跟踪该领域的最新会议文献、最新发表的论文及专利文献等,分析这些文献中发表的新观点、用到的新技术,得到最新的研究热点。但是,文献资源电子化的增长速度很快,研究人员要从浩瀚的文献资源中发现某一领域的科学前沿非常困难。而且新兴技术的出现往往是几个学科相互交叉的结果,而从一个学科去发现别的学科中出现的新技术和新主题更加困难。
文本挖掘技术是帮助科研人员从海量文献中快速发现新兴主题的途径之一,而主题模型作为一套新的能够对文献资源进行语义抽取的算法[ 1],提供了一种解决问题的新方法。主题模型已经成为国际上的研究热点,并且引起越来越多研究人员的注意。笔者在WOS(Web of Science)数据库中以“topic model”为检索词,检索途径为“主题”,时间范围为2002年1月1日到2012年12月1日,共检索到276条数据,结果如图 1所示:
 | 图1 每年的论文数量及每年的论文被引次数 资料来源:http://apps.webofknowledge.com,2012-12-11 |
虽然主题模型能够在语义上对文档进行表示,但是对从事特定领域的分析人员来说,仍然需要一些主题模型的知识,这无疑加大了对主题模型的学习难度。如果对主题模型产生的主题进行可视化展示,就能够帮助研究人员快速、直观地了解领域的研究进展,这是很有意义的。
另外,主题模型对于文档的语义表示是一种概率化的单词抽取,存在不确定性。如果将引文关系和主题模型相结合,能够对主题模型存在不确定性这一缺点进行改进。因此,本文对这个方向进行了综述。
以最简单的主题模型LDA(Latent Dirichlet Allocation)为例,介绍主题模型中的一些基本概念,总结几种LDA模型的主要的扩充算法,并分析几种主要的可视化技术,接着对引文关系引入主题模型这一方向进行分析。最后,指出主题模型存在的问题,并展望未来的发展方向。
2 LDA模型及其算法改进
2.1 LDA模型简介
主题模型是文本降维技术的一种。最常用的文本降维技术是词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF),将文档集表示成以文档为行,以单词为列的矩阵,但是TF-IDF形成的矩阵往往非常稀疏,而且不是以语义的形式表示文档,只是从词频的角度表示文档。Nigam等[ 2]从语义上表示一篇文档,提出了一元混合模型(Mixture of Unigrams),认为一篇文档谈论一个主题,可以用文章中的单词表示这个主题;Hofmann等[ 3]提出PLSI (Probabilistic Latent Semantic Indexing),认为一篇文档由条件依赖于文档的多个主题组成,表示主题的单词服从于主题的多项式分布;Blei等[ 4]提出LDA,认为文档是由服从多项式分布的主题组成,每个主题由服从于主题的多项式分布的单词组成。
LDA是文档、主题和单词组成的三层贝叶斯产生式模型[ 4]。一篇文档的LDA产生过程为:
(1)抽取文档的长度NPoission(β);
(2)抽取文档在主题上的分布θmDir(α);
(3)for n=1 to N;
(4)抽取一个主题zmnMultinomial(θm);
(5)抽取单词wmnMultinomial( 
其中,α和β是LDA的先验参数,θ和Φ是两个需要估计的参数。对于参数近似估计算法主要有两类:变分推断算法,包括均值场变分推断(Mean Field Variational Inference)[ 5]和崩溃性变量推断(Collapsed Variational Inference)[ 6];利用马尔科夫链蒙特卡洛方法(Markov Chain Monte Caro)的Gibbs抽样[ 1, 7]。两种算法的对比分析如表1所示:
| 表1 LDA参数的两种近似估计算法的对比分析 |
2.2 LDA模型存在的问题
在建立LDA模型时,提出了6个假设:
(1)文档之间可交换;
(2)主题之间可交换;
(4)文档是多个主题经过有限次混合而成;
(5)文档是主题上的多项式分布;
(6)文档集中主题的个数K是已知并且固定的(可以使用无参贝叶斯的方法去掉这个假设[ 13, 14, 15])。
其中,文档之间可交换的假设认为文档之间没有先后顺序。而实际上文档中主题的产生往往有顺序,比如在“天宫一号”发射之前,网上新闻集中于讨论“天宫一号”准备的情况,而发射之后,“天宫一号”的运行情况是关注的焦点。显然此假设存在没有对主题随时间的演化关系进行建模的不足。
主题之间可交换的假设认为主题之间没有层次关系和先后关系。实际上在一个关于体育的语料库中,讨论的主题有篮球、足球,这些主题之间是存在层次关系的。显然,假设存在没有对主题之间的层次关系进行建模的不足。因此,研究人员对LDA模型进行了各种改进。
2.3 改进的LDA模型算法
(1)对主题演化过程建模的LDA
这类模型将时间信息结合到主题模型中,得到的主题表现出随时间轴演化的趋势。最具代表性的是DTM(Dynamic Topic Model)[ 16]。DTM将时间离散化,然后按照时间片将语料库分割,形成按照时间序列的文本语料片(Slices),在每个片内主题是可交换的,对每个时间片内的文本按照静态主题模型建模。同时,每个时间段的主题模型的参数依赖于前一个时间片段的参数。
DTM的优点在于能够利用时间序列对整个语料库进行建模,从而揭示一个语料库中主题随时间的演化规律。但是,DTM没有考虑每个时间片段内文档数目对主题数目的影响,也没有对时间片段间主题的动态关系进行建模。同时,DTM存在如何寻找最优时间切片方式的问题。
cDTM[ 17] (continuous time Dynamic Topic Model)利用布朗运动(Brownian Motion)对主题的演化建模,从而将DTM中时间细粒度的选择这一关系到计算复杂度的问题转化为一个模型选择的问题。
TOT模型(Topic Over Time Model)[ 18]和DTM不同的是,不利用马尔科夫性将时间离散化,而是认为每个主题与某一个时间戳的连续分布有关,对共现词和文档的时间戳共同建模。
(2)对主题间层次关系建模的LDA
层次LDA主题模型(Hierarchical LDA, HLDA)能够对主题之间的层次关系进行建模。HLDA不需要预先指定主题的数目,在生成层次主题结构的同时自动确定主题数目。HLDA的缺点在于不能拥有同一层次的两个主题。
CTM(Correlated Topic Model)的生成过程和LDA生成一篇文档的过程非常类似,只是主题分布从一个逻辑斯蒂分布中抽取。它能够根据一个主题推测出另外的主题。但是,由于逻辑斯蒂分布和多项式分布不是共轭分布,因而后验分布的计算开销比较大[ 11]。
PAM分布(Pachinko Allocation)[ 13]利用DAG (Directed Acyclic Graph)构建一棵层次树。树的叶子节点对应单词,而内部节点对应主题。PAM的主题既可以建立在单词上,也可以建立在主题上,从而能够对主题的层次关系建模。同时,PAM中每个节点是其子节点的某一任意分布,因此,可以获取任意的、嵌套的、非结构的数据主题以及主题之间的关系。
(3)词序有关的LDA
文档中单词的顺序包含对于理解文档的主题含义有用的信息,下面给出几种这方面有关的模型。
BGTM(Bigram Topic Model)[ 19]认为,当前一个单词的主题概率的分布当且仅当依赖于前一个单词的主题概率分布,每个单词的生成过程都是一个独立的LDA。和LDA的不同之处在于:对于每个单词都抽取一个主题分布;一个单词的生成的概率条件依赖于前一个单词的主题分布。
LDACOL (LDA Collocation Model)在BGTM模型的基础上,引入了一组随机变量x来标识当前一个单词和前面一个单词是否形成一个词组[ 20]。一个单词的生成不仅仅受到主题分布的影响,也受到一个随机的贝努利分布的影响,这个分布决定当前词和前一个词是否形成一个词组。
TNG (Topical N-Gram) 模型[ 20, 21]将LDACOL模型进一步推广,认为主题不仅仅是一个个单词组成的主题,而是更具有理解性和解释性的词组。Mann等[ 22]利用TNG将主题模型和文献的共引分析相结合,提出了一套主题模型的文献计量学指标。
可以看出,BGTM和LDACOL模型都是TNG模型的一种特殊情形,当所有xi=1,即得到BGTM模型;当σ只依赖于前一个单词时,即得到LDACOL模型。
(4)对文档主题和元数据联合建模
主题模型本质上只是从词的共现对文档进行语义分析,没有利用文本自身具有的元数据。最常见的是和文档的作者联合建模的ATM和TAM。
ATM (Author-Topic Model)将文档的作者元数据引入到模型中,对文档的内容和作者联合建模,每个作者是主题的多项式分布,每个主题是单词的多项式分布[ 23]。ATM通过计算作者在每篇文档的内容上的熵,可以预测一位作者倾向于使用哪些主题或者一位作者对哪些主题感兴趣。
王萍[ 24]提出TAM (Topic-Author Model),TAM可以用于研究领域的专家发现、文献标注、重要文献的发现、文献相似度分析与文献推荐以及研究趋势分析。
TAM和ATM相同之处在于都是对文档的内容和作者联合建模,不同之处在于ATM是利用作者-主题的分布生成文档中的每个单词,而TAM是首先生成文档的每个单词,然后从文档中随机选择一个单词,根据该单词所对应的隐含主题生成作者。
除了结合元数据作者外,也有研究者结合其他的元数据对主题模型建模[ 25, 26]。
(5)基于引文分析的主题模型
LDA是一种概率式的产生式主题模型,表示主题的单词的生成具有不确定性,研究人员探索是否能将文档之间的引文数量这一定量的、确定性的指标引入到主题模型中,改进对主题演化的预测。同时,引文分析本身具有一些缺陷:
①时滞性。最新的研究进展一般发表在会议论文而不是期刊中[ 27],而由于SCI中的引文关系需要经过专家评审才能入库,因此会议论文被收录到SCI中需要更长的时间。
②引文收集的不完备性。Goodrum等[ 28]将同一个关键词分别在Citeseer和SCISearch中检索,无论在引文的数量还是引文的来源上都存在较大的差异[ 29]。
③引文分析方法的受限制性。很多数据库比如中国的专利数据库[ 30]中不存在引文数据。
Dietz等[ 31]和He等[ 32]利用Web中的PageRank思想,认为相互引用的文献之间,被引文献的主题分布对施引文献的主题分布产生影响。Nallapati等[ 26]提出将施引文献和被引文献构成一个文献对,将文献对放在主题模型中联合建模,主题之间的影响是服从于一个超参数决定的概率分布。这两种模型将主题的生成过程引入了参考文献,但是没有将引文的数量这一定量指标引入到对主题演化的预测中。
Mann等[ 22]提出了结合引文分析和主题模型的文献计量学评价指标体系,比如主题影响因子(Topic Impact Factor, TIF)。对于某个给定主题k,在某个时间段t内,其主题影响因子的定义为:
TIF(k,t) = 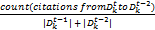
其中, 
在实际应用方面,贺亮等[ 33]利用LDA话题模型抽取科技文献的话题,然后计算话题的强度和影响力,最后针对热门和冷门话题以及影响力高和影响力低的话题,进行了趋势分析。但这种方法没有考虑时间维度和业内领军人物等因素。
(6)在线式主题模型
LDA是离线式地对文本进行分析,当要处理的文本是文本流时,不可能取得所有的文本进行建模。
Alsumait等[ 34]提出OLDA (On-Line Topic Model),将LDA主题模型用于文本流,识别出文本的主题以及主题的演化规律。首先根据已有的文本数据构建一个主题模型,然后对于新到的一篇文档,增量式地构建出一个实时更新模型,这个模型同样也是每篇文档主题的混合和每个主题的单词的混合。这种方法的优点在于,通过新的数据流中的信息来增量式地更新当前的模型,而不需要访问以前的数据。同时这种方法也可以用于跟踪随时间变化的主题以及实时探测新的主题。
Hoffman等[ 35]引入了在线式的变分推断方法,利用一种随机的自然梯度算法来判断收敛到目标函数的程度,实验表明,相较于传统的变分推断算法,该方法的收敛速度以及对参数的估计的效率和准确度(以F值为测度)更好。
Banerjee等[ 36]提出了LDA模型的在线式版本,并提出将在线式推断和离线式推断相结合的模型。该方法通过在线式的学习文本流的主题内容,以离线方式更新整个语料库的主题内容,从而在离线式方法的性能和在线式方法的高效之间取得了平衡。
(7)小 结
当前对LDA的改进主要有6类,这些改进中对主题演化过程建模的LDA、对主题间层次关系建模的LDA、词序有关的LDA是对LDA所做的6个假设的扩充,每个模型从一个或两个假设的角度进行了扩充。对文档内容和元数据联合建模在文档主题基础上引入了与文献内容密切相关的外部信息;结合引文分析的方法则更进一步,文献的引文关系本身就能反映主题的演化关系,将它与LDA结合起来,能进一步发挥二者所长,结合引文分析的方法在未来基于科技文献的主题演化分析或者新兴主题发现方面有着较大的应用前景;在线式主题模型因为可以通过新的数据流中的信息来增量式地更新当前的模型,而不需要访问以前的数据,可以用于跟踪随时间变化的主题以及实时探测新的主题,未来可能会成为对网上动态信息分析发现主题演化的研究热点。
以上这些模型的对比分析如表2所示:
| 表2 各种扩展模型的对比分析 |
3 LDA模型的主题可视化
产生的主题如果能以一种直观、图形化、可交互的方式呈现出来,能够避免研究者学习复杂的主题模型,有助于快速理解文档的主题,直观地观察主题之间的关系和发展趋势。最具代表性的主题模型的可视化技术分为以下几种:
3.1 二维节点-连接图
这类图以二维的点线图表示主题以及主题之间的相似关系。对于文档的可视化分为三步:
(1)将文档(主要是摘要)通过主题建模得到一组主题,进行降维同时保持文档的语义不丢失;
(2)通过KL散度计算文档步骤(1)中得到的主题)两两之间的相似度;
(3)采用DrL(Distributed Recursive Graph Layout)算法将成对的文档以及步骤(2)中得到的相似度进行可视化。
其中最典型的是NIH-VB(NIH Visual Browser),它是一个面向NIH的、对申请基金的项目的文档进行可视化的浏览器[ 37, 38],如图2所示:
 | 图2 NIH-VB对NIH数据可视化展示① |
可以看出,NIH-VB提供了用户交互的功能,比如查询、放大、缩小以及导出数据等。利用NIH-VB可以直观地把握某一个时间段内NIH资助项目的主题分布,但是不能展示主题随时间的演化。
3.2 二维河流式图
河流式图是一种比喻,将主题的强度表示成河流的宽度,其随时间的演化构成一条河流。比如TIARA,几个主题放在一个图中,横轴表示时间,纵轴表示每个主题在各时间点上出现的强度,从而便于发现在某一个时间点主题的对比关系[ 39],如图 3所示。
图3中每一层表示一个主题,层中的多个Label是从文档中抽取的具有时间代表性的关键词。虽然对关键词的提取可以采用LDA, 但是如何评价这些关键词
① 资料来源:https://app.nihmaps.org/nih/browser/,2012-12-11
 | 图3 TIARA的图形表示[ 39] |
以及决定时间片最优的粒度是这种技术要解决的问题。
3.3 三维地势图
该技术将文档进行主题建模,然后采用VxOrd算法计算出每个文档的位置,然后将类似的文献聚在一起,形成一个山峰,如果在短时间内出现大量的文献,那么该山峰非常陡峭,不同类别的文献之间的联系形成山脉。比如VxInsight,广泛用于文本挖掘、专利发现和领域知识管理[ 40],如图4所示:
 | 图4 VxInsight给出的主题分布图[ 40] |
每座山峰在不引起混扰的情况下,用主题的前n个单词表示。
3.4 几种可视化技术的对比分析
几种可视化技术的对比分析如表3所示:
| 表3 各种可视化技术的对比分析 |
通过上述比较,可以看到以NIH-VB为代表的二维节点连接图的方式,可以直观地把握某一个时间段内NIH资助项目的主题分布,但是不能展示主题随时间的演化;二维河流图的可视化方式将主题的强度表示成河流的宽度,并以河流方式展示了主题随时间的演化,但也存在如何评价抽取出的关键词,并决定时间片最优的粒度的问题;以VxInsight为代表的三维地势图的优势在于能够很清晰地发现某个时间点上核心期刊、核心文献是什么,哪一个领域是最热门的;不足之处在于要观察某一个领域在某个时间阶段的发展趋势,需要形成多份视图。
对于文档采用主题模型可视化,可以总结为:从一个或多个数据源收集文档集;对收集到的文档数据清洗;对文档集主题建模,提取出主题词;将对文档的相似性计算转化为对主题之间的KL散度计算;利用图形布局算法图形化,利用主题中的前n个单词标注。
4 结语
主题模型作为一套新的能够对文献资源进行语义抽取的算法[ 1],提供了一种帮助科研人员在海量文献中发现新兴主题的新方法。近年来,由于基本的主题模型存在一些问题,业界对LDA模型从主题演化、主题层次等方面进行改进,本文系统梳理了LDA主题模型以及各种改进模型,将各种模型分为对主题演化过程建模的LDA、对主题间层次关系建模的LDA以及词序有关的LDA等6类,并认为由于LDA本身是概率式产生模型,存在不确定性,结合引文分析这一可以反映主题演化的文献计量方法,能够克服引文分析的时滞性、不完备性以及方法受限制的缺点,将充分发挥二者的优势。该研究对于系统把握LDA及其改进模型的发展脉络和各自优缺点,把握利用LDA模型开展科学论文中新兴主题发现的关键问题和研究方向具有理论和实践意义。
主题模型未来的发展有两个重要方向:用于在线动态更新的网络信息发现主题演化和新兴主题,在线LDA将具有很好的应用前景;用于科学文献中新兴主题的发现,将LDA和文献中通过引文关系展现出来的主题演进关系结合,与文献作者元数据结合将有研究和应用潜力。
为了推进主题模型的实际应用,将LDA分析结果以可视化形式呈现,会促进LDA模型分析的可理解性,并推进LDA模型的应用。因此,在实践上将主题模型技术与可视化技术结合起来应该是该算法实际支撑应用的一个重点突破点。
根据对当前主题模型及其改进算法的分析和主题模型在新兴主题探测方面应用的分析,可以预见,将主题模型应用到新兴主题探测上,还需要解决以下几个关键问题:
(1)明确新兴主题的定义及其判定指标;
(2)如何充分利用主题模型和文献计量学中的相关方法,发挥文献本身的元数据的优势,实现利用主题模型进行新兴主题的抽取;
(3)抽取出的主题和领域词汇集的关系,主题模型抽取出的主题词可能并不是领域内的标准术语,因此需要探索如何和领域词汇集结合。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|