{kind=link}
{kind=link}
{kind=link}
面向专利分析的法律状态分布式采集系统的设计与实现*
引用本文
吴红, 王凤英, 付秀颖. 面向专利分析的法律状态分布式采集系统的设计与实现* . 现代图书情报技术, 2012, 28(12): 66-71
Wu Hong, Wang Fengying, Fu Xiuying. Design and Establishment of Legal Status Distributed Collection System Based on Patent Analysis. 现代图书情报技术, 2012, 28(12): 66-71
Permissions
Wu Hong, Wang Fengying, Fu Xiuying. Design and Establishment of Legal Status Distributed Collection System Based on Patent Analysis. 现代图书情报技术, 2012, 28(12): 66-71
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
面向专利分析的法律状态分布式采集系统的设计与实现*
摘要
针对专利分析对法律状态需求量庞大而法律状态需单项获取的矛盾,设计并实现基于网络的法律状态信息采集系统。系统通过分布式架构启动多台机器进行搜索,通过一致性Hash算法并引入虚拟客户节点,克服进程分配中的不均衡问题,配合以网页识别,实现包括法律状态在内的专利信息批量、经济、快速获取,有效解决专利现状分析中的数据获取瓶颈问题。实例表明,融入法律状态的专利分析,能使分析结果更为全面、客观和丰富,并更具针对性。
关键词:
分布式架构; 一致性哈希; 专利法律状态; 存活寿命; 信息采集
中图分类号:G354 TP391
Design and Establishment of Legal Status Distributed Collection System Based on Patent Analysis
Abstract
Aiming at the contradictions that patent analysis has enormous demands for legal status, while legal status is acquired singly, the paper designs and realizes a legal status information collection system. The system adopts the distributed framework, which conducts searches by multiple machines, and overcomes the unbalanced process distribution by consistent hashing algorithms as well as visual client nodes. Besides, using identification of Web pages technology, it is able to acquire patent information that includes legal status in a batch, economic, quickly process. It also presents a solution to the information acquiring bottleneck problem in today’s patent status analysis. The application example shows that combining patent analysis with legal status makes the analysis results more comprehensive, objective, multiple and specific.
Keyword:
Distributed architecture; Consistent hashing; Patent legal status; Survival life span; Information collection
1 引言
专利法律状态是指一项专利或专利申请当前所处的法律状态[ 1],具体有公开、授权、驳回、中止、宣告无效等。专利制度的作用机理是通过赋予专利权人对其发明创造在一定时期内的排他权来获取利益,利用法律和经济手段促进发明创造,且只有有效专利(专利权处于维持状态的专利)才具有法律赋予的排他权,并且从专利个体特点来看,技术含量高的专利会带来较高收益,也具备较长的寿命[ 2],所以有效专利数量和存活寿命的整合分析,能更为客观、全面地展示专利现状。有效专利数量和存活寿命指标有赖于专利法律状态,基于此,专利法律状态信息的有效采集对于专利分析显得非常重要。
2 需求及技术思路
互联网上有丰富的专利信息资源,隐藏于Hidden Web[ 3]数据库中,目前学者们已开始研究基于Hidden Web数据库的专利信息采集并取得了一定成果,如:Ntoulas等[ 4]研究通过构造有效的Hidden Web爬虫来自动发现和下载网页信息;吴琳等[ 5]利用网址命名特点获取专利数据的详细网页,并通过网页解析提取所需信息,合并数据后形成双语对照的语料数据库;梁莹等[ 6]基于多Agent的专利资源协同获取模型,实现对企业间专利信息的协同获取和整理;张红等[ 7]利用Internet免费检索并获取中国专利全文方法。另外,还有一些商业公司开发了专利信息检索系统,如北京恒和顿公司开发的HIT_恒库支持高速稳定下载专利全文,日本Kazuya Ujihara开发的GetIPDL可以下载专利文本文件和图像文件。上述研究虽然对专利现状分析所需数据提供了很大的方便,但均不涉及法律状态采集。
| 表1 三种法律状态信息获取途径比较 |
如表1所示,我国专利法律状态信息的公开获取渠道主要有以下三种:查阅法律状态登记簿副本;检索国家知识产权局制作的专利光盘数据库;检索Hidden Web数据库,如登录国家知识产权局网站(http://www.sipo.gov.cn)或中国知识产权网(http://www.cnipr.com)检索。不论是哪种途径,法律状态信息只能根据申请(专利)号单项获取。现状分析动辄需要调取数以万计的法律状态,由于专利从申请、审查到审查之后获得授权,以及专利权在保护期限内维持的全过程中,法律状态是动态变化的,不等查阅完毕,有些专利的法律状态又会发生变化,所以上述途径在经济性、时效性上基本上不可取。法律状态信息获取成为专利分析中的一大难题,目前虽然有从有效专利角度的研究报道,但均不涉及专利存活寿命分析指标。
为有效解决专利现状分析中的数据获取瓶颈问题,本文研究开发了基于Hidden Web数据库检索的法律状态信息采集系统。以国家知识产权局网站公布的专利信息为信息源,借助专利分类号、专利名称、专利权人等清晰概念构成检索策略;通过分布式启动多台计算机搜索、PHP的Snoopy类远程信息读取、网页分析、数据存储等技术生成包含法律状态信息在内的本地数据库;通过本地数据库的检索、统计、分析,得到有效专利数量、专利存活寿命等现状分析数据指标。
3 系统设计与实现
系统主要由三个模块组成:概念检索模块、专利网页信息抽取模块和专利信息分析统计模块。程序均由PHP编写,并在Linux系统中测试成功。在专利网页信息抽取模块中,主要使用PHP中的Snoopy(http://snoopy.sourceforge.net/)类,Snoopy可以模拟浏览器来获取网页内容,甚至以get或者post方式发送表单数据,抓取网页内容、网页文本内容 (去除HTML标签)和网页链接,支持设置 user_agent、 referer(来路)、 cookies 和 header content(头文件)等,效率高且不需要服务器特定配置支持。整个专利信息获取分析过程如图1所示:
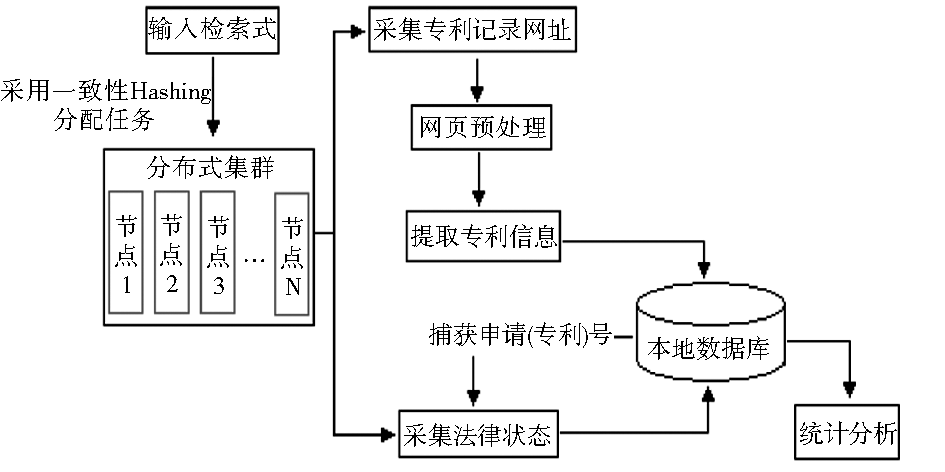 | 图1 系统数据采集分析流程 |
(1)登录国家知识产权局网站,在高级检索界面输入检索式;
(2)使用一致性Hashing方法分配给客户端执行任务;
(3)远程获取每条记录对应的网址;
(4)通过步骤(3)得到的每条记录链接,读取远程网页的源文件并提取包括申请(专利)号在内的有用数据信息,生成本地数据库;
(5)进入法律状态检索界面,依据申请(专利)号获取法律状态信息,并更新本地数据库;
(6)对数据库进行单项、组配分析统计,包括根据法律状态对有效专利、专利存活寿命的统计分析。
3.1 分布式架构
为提高信息采集效率,解决网速慢、数据获取时效性差的问题,系统采用分布式架构:一台Linux主机作为Web和Gearman服务器,其他Linux主机作为Gearman客户端节点Node,每个Node运行有N个页面(进程),用于执行专利检索任务。
Gearman服务器在系统中作为调度者和管理者,主要负责分配任务,而Gearman客户端则主要负责执行采集远程专利信息至本地的任务。每个页面(进程)预设相关执行任务的函数,等待接受命令执行任务。系统接受用户输入条件,将此搜索条件简单处理后,使用Snoopy类submit()方法获取该检索条件的首页结果。从首页结果页中,采用字符串匹配的方式,获取全部的页数和专利链接。系统随后连接到Gearman服务器,Gearman再将获取剩余页码和对应于专利链接中的具体专利信息的任务分配到Gearman客户端。由于国家知识产权局网站上网页的格式及网页中的关键词是固定的,因此在远程获取到专利信息(HTML页面信息)时,使用字符串匹配方法即可获取到需要的信息。
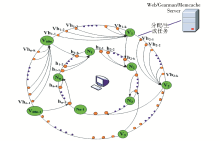
Gearman服务器分配任务采用一致性哈希(Consistent Hashing)方法。一致性哈希主要起到负载均衡的作用,使得任务能够合理平均地分配到各个Gearman客户端。实际操作时,由于实际节点过少容易出现负载任务不均衡问题,故引入虚拟节点(即逻辑节点),与实际节点是多对一的对应关系(如60:1),所有实际节点在内圆环中均匀分布,所有虚拟节点在外圆环中均匀分布:首先用232 个点分别对内、外圆环进行均匀分割,用CRC32[ 8]算法计算出Gearman任务的哈希值,并映射到外圆环中,然后从数据映射到的位置开始顺时针查找,将任务分配到找到的第一个虚拟节点上;再用CRC32算法计算出虚拟节点的哈希值,并映射到内圆环中,然后在内圆环上从数据映射到的位置开始顺时针查找,将任务分配到找到的第一个实际节点上。系统引入虚拟节点的分布式架构如图2所示, V为虚拟节点,N为实际节点,Vh为Gearman任务落到虚拟节点上的哈希值,h为Gearman任务落到实际节点的哈希值。
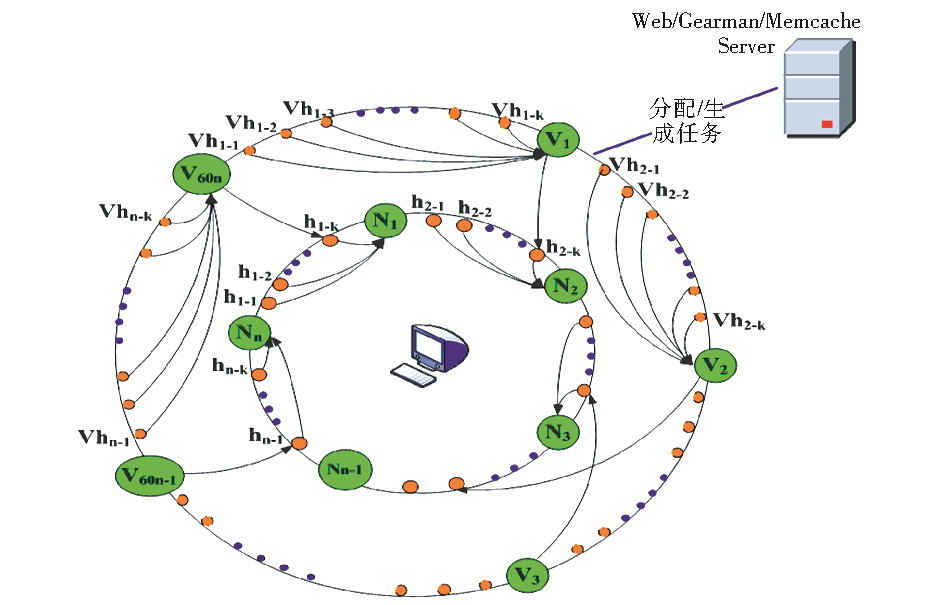 | 图2 系统引入虚拟节点的分布式架构 |
3.2 获取符合检索条件的专利信息网址
系统接受用户输入条件,并将用户请求处理形成一个检索字符串,使用PHP中Snoopy类提交表单,远程获取中国知识产权网上每条记录的网址。该网址用于获取每条记录申请(专利)号、申请日、发明名称等不包含法律状态的信息。获取代码如下:
include 'Snoopy.class.php'; //包含Snoopy类
﹩snoopy=new Snoopy(); //实例化Snoopy类
…… //设置Snoopy类的相关参数
﹩formdata=array(flag3=>'1',selectbase=>'0',sign=>'0',recshu=>'20',searchword=>﹩workload['searchword']);
//表单的内容
﹩url="http://211.157.104.87:8080/sipo/zljs/hyjs-jieguo.jsp"; //提交地址
﹩snoopy->submit(﹩url,﹩formdata); //提交表单
﹩snoopy_result=﹩snoopy->results; //获取结果页
//通过字符串匹配等操作获取每条记录的网址
﹩pos=strpos(﹩snoopy_result,'table border="0" align="center" cellpadding="0" cellspacing="0"');
……
3.3 获取专利信息
使用PHP的Snoopy类,根据每条记录的网址获取该记录对应的页面HTML源码, 通过字符串匹配等操作抽取出有用信息(该页面HTML源码中不含法律状态信息),如申请(专利)号、申请日、发明名称、申请(专利权)人、摘要等,生成本地专利数据库。获取代码如下:
/*获取专利信息(不包括法律状态)*/
…… //设置Snoopy类的相关参数
﹩snoopy->fetch(﹩llink); //此处的网址(﹩link)是通过第一步获取的
﹩snoopy_result=﹩snoopy->results; //获取结果页
﹩data=getcontents(﹩snoopy_result); //获取专利的具体信息
function getcontents(﹩contents) //获取专利的具体信息getcontents函数
{
﹩startpos=strpos(﹩contents,'申请号:');
﹩endpos=strpos(﹩contents,'申请日:');
//通过字符串匹配等操作抽取页面中的专利具体信息,生成本地专利数据库
﹩apply_num=substr(﹩contents,﹩startpos+12,﹩endpos-﹩startpos-12);
……
}
3.4 法律状态信息抽取
转入法律状态检索界面,利用获得的申请(专利)号,使用PHP的Snoopy类获取该记录对应的页面HTML源码,通过字符串匹配等操作抽取出页面中的法律状态信息,如历次法律状态变化涉及的法律状态类型和法律状态公告日,并更新本地专利数据库。获取专利具体信息的代码如下:
/*利用Snoopy类抓取专利法律状态*/
…… //设置Snoopy类的相关参数
﹩searchword='申请号='.﹩apply_num.'%'; //此处的申请号(﹩apply_num)经由第一步获取
﹩data=array(recshu=>'null',searchword=>﹩searchword,page=>''); //表单内容
﹩url="http://search.sipo.gov.cn/sipo/zljs/FlztResult.jsp";
//获取法律状态的网址
﹩snoopy->submit(﹩url,﹩data); //提交表单
﹩snoopy_result=﹩snoopy->results; //获取结果
/*通过字符串匹配等操作获取法律状态并写入数据库*/
﹩reg='/< table border="1" cellspacing="0" cellpadding="0"(.*?)<\/table>/s';
preg_match_all(﹩reg,﹩snoopy_result,﹩matches);
if(﹩matches[0][0])
﹩result=implode("",﹩matches[0]);
……
4 实验及结果分析
4.1 采集效率测试
在实验环境中,系统的分布式架构采用一台Linux主机作为Web和Gearman服务器,其他三台Linux主机作为Gearman客户端节点Node,每个Node运行有4个页面(进程)。测试输入式为:申请(专利权)人=同济大学,数据选取自2000年1月1日以来申请的、截止到2011年5月18日公开的发明专利数据,检索结果共有2 329项专利条目。测试6次,本系统与不采用分布式架构(即一台主机完成所有的任务)的系统的耗时情况如表2所示:
| 表2 采用分布式架构与不采用分布式架构的耗时比较 |
实验数据证明,本系统能显著提高获取专利信息的时间效率。
4.2 实验数据
我国对专利数据的权威性统计来自国家知识产权局规划发展司(简称规划发展司)。为验证系统对专利现状分析的贡献,以浙江大学、清华大学等我国有效发明专利排名前10位的大学发明专利(包括申请)作为实验数据集,取规划发展司公布的数据与系统采集的数
| 表3 10所大学有效发明专利数量 |
表3是规划发展司在2011年4月14日公布的《2010年中国有效专利年度报告》中,对截止到2010年12月底上述10所大学有效发明专利数量的展示[ 9],这也是规划发展司迄今为止(截止到2012年7月9日)对上述10所大学有效发明专利数量的最新统计。
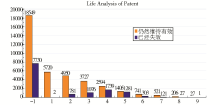
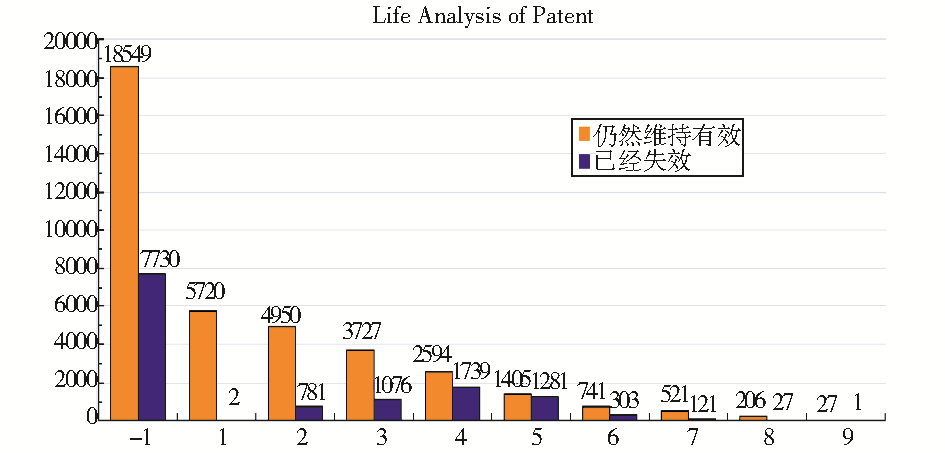 | 图3 利用本系统采集的专利数据 |
图3是系统以“申请(专利权)人”检索框内输入大学校名、选择“发明”为检索策略,从国家知识产权局网站获取的上述10所大学的发明专利数据,数据效果采用PHP中的JpGraph图类形成,通过柱状图的形式展现(由于我国专利在2000年之前数量较少,所以数据选取自2000年1月1日以来申请的、截止到2011年5月18日公开的发明专利数据);纵坐标表示数量,横坐标中“-1”表示尚未授权的发明专利申请,其余数字表示专利存活寿命。
系统采集的每所大学发明专利(包括专利申请)的数据详情如表4所示:
| 表4 我国有效发明专利持有量排名前10位的大学数据 |
4.3 实验结果分析
从表3可以看到,规划发展司对有效发明专利数据的统计仅仅是一个总量。但是,依据规划发展司公布的同期我国有效发明数量为564 760项[ 9]可以得知,10所高校的有效发明数量占到我国有效发明总数的3.52%,说明高校的技术创新活动非常活跃,专利热情高涨;再依据国家知识产权局“有效专利的数量更能体现专利的水平,更能反映企业、地区乃至国家的核心竞争力”的观点[ 10],可以初步推断上述10所大学的专利综合实力排名如同有效专利数量排名,即浙江大学最高,其次是清华大学,……,同济大学以776项排名第10。
然而,我国专利法规定,专利权人在专利授权时要办理登记手续,否则就视为放弃已经取得的专利权;专利授权后,专利权人有缴纳年费的义务,否则专利权会因没交年费而提前终止,不再有效。所以要获得专利证书就必须办理登记手续,这样授权专利存活寿命多超过一年而自然进入两年。拿到专利证书后,专利权人就会面临是否缴纳年费以维持专利权继续有效的选择。通常当维持专利权有效带来的收益大于维持成本时,专利权人才会继续维持权利有效,而且专利维持时间越长,说明创造经济效益的时间越长,市场价值越高。基于上述分析,通过图3、表4可以清楚看到:
(1)在公开的51 501项专利数据中,有超过93%的专利是最近5年授权的,有18 549项正处于审批阶段,有5 329项发明专利已经失效,专利9年内的失效比例高达21.1%,19 891项有效专利是51 501项专利(包括专利申请)“前仆后继”的共同结果。
(2)发明专利的最长保护期限是20年。从专利存活寿命的角度看,有14.7%的专利存活寿命不到两年,存活寿命超过5年的不到7%,其中存活寿命为6年的仅有3.59%,7年的仅有2.35%,8年的仅有0.97%,9年的不到0.001%。高校专利的“短命”说明众多专利没有在经济活动中发挥作用。
(3)依据E= 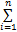
| 表5 10所大学专利平均存活寿命排名 |
考虑到中国发明专利已高居世界第二位[ 9]、上述高校都不乏发明专利的前提,专利综合实力利用平均存活寿命整合有效专利数量来体现更为客观,即清华大学最高,其次是西安交通大学,北京航空航天大学排名第10。
分析获知,有效专利数量与专利综合实力并不等价。融入法律状态指标的专利分析,能从市场价值角度更加具体、客观、准确地展示专利现状,揭示存在的问题。虽然上述大学技术创新活跃,有效专利数量增长迅速,数量庞大,但与市场联系不够紧密,市场价值不高,耗费大量科研资源获得的众多专利不过是一堆“科研成果”而已。
5 结语
针对我国“虚高”的专利数据和现有专利现状研究分析的局限性,设计并实现了基于国家知识产权局网站公开数据的专利法律状态信息采集系统。系统根据用户的检索策略对专利信息进行定向采集,批量获取包括法律状态在内的专利信息,进而分析得到有效专利数量和专利存活寿命指标。实例证明,融入法律状态的专利分析,能使分析结果更加全面、客观和丰富。该系统最突出的优点是充分利用网络专利信息资源,采用分布式架构并引入虚拟客户端节点,通过网页识别实现了专利信息的批量、经济、快速获取,有效解决了专利现状分析中的数据获取瓶颈问题,使专利分析从以往的纯理论研究走向实际应用。
研究存在的不足是仅从有效专利数量和存活寿命两方面对专利综合实力进行评价,分析不够全面;尚未实现以专利主体为单位,对其专利法律状态信息的跨网站批量采集。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|