
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于本体的个性化图书推荐方法研究*
引用本文
汪英姿. 基于本体的个性化图书推荐方法研究* . 现代图书情报技术, 2012, 28(12): 72-78
Wang Yingzi. Research on Ontology-based Personalized Recommendation Method for Library Resources. 现代图书情报技术, 2012, 28(12): 72-78
Permissions
Wang Yingzi. Research on Ontology-based Personalized Recommendation Method for Library Resources. 现代图书情报技术, 2012, 28(12): 72-78
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
基于本体的个性化图书推荐方法研究*
摘要
针对目前图书馆馆藏日渐增多致使用户获取资源负担加重的问题,提出一种混合式图书推荐方法。该方法用语义手段描述图书资源和借阅者,建立用户兴趣与图书资源特征的联系,通过查询修正与基于规则和实例的推理实现个性化推荐,同时在推荐结果中加入辅助推荐。根据用户的反馈信息分析、调整推荐流程,在一定程度上减少传统协同过滤方法的“新用户”和“新对象”问题。实验结果表明,该方法可以提高推荐的命中率,具有良好的效果。
关键词:
本体; 混合式推荐; 个性化推荐; 用户偏好
中图分类号:TP391
Research on Ontology-based Personalized Recommendation Method for Library Resources
Abstract
The huge increase of library resources makes users’ cost of accessing valuable knowledge becoming much higher. For this problem, the paper proposes a hybrid recommendation method for library resources, which adopts semantic technologies to describe library resources and borrowers, establishes the association between user preferences and library resource features. Through query modification, rule-based and case-based inference, the method realizes personalized recommendation. Meanwhile, some auxiliary recommendation approaches are integrated. The recommendation process can be analyzed and optimized according to users’ feedback. Additionally, this method reduces the “new user” and “new item” problems in traditional collaborative filtering method to a certain extent. Experimental results show that the proposed method can enhance the hit rate.
Keyword:
Ontology; Hybrid recommendation; Personalized recommendation; User preference
1 引 言
高校图书馆蕴藏有丰富的图书资源,传统的图书馆服务模式仅靠用户主动提交查询关键字来获取所需的信息,属于被动服务模式。近几年来,基于用户兴趣的个性化推荐方法逐渐受到研究者的重视[ 1, 2]。个性化的推荐方法充分考虑用户以前个人或与其相似的用户群体的偏好,主动帮助用户从大量的图书资源中搜寻出用户可能感兴趣的资源, 并及时推荐给用户。 目前, 比较流行的推荐方法包括基于内容 (Content-based)、 基于协同过滤(Collaborative Filtering)以及组合式(Hybrid)的推荐方法三种模式[ 2]。
本文针对高校读者群具有特定专业背景或研究领域的特点,分别使用图书领域本体和用户本体来描述图书资源和读者资源,提出一种基于本体的混合式图书推荐方法,建立图书资源本体和用户本体,设计推荐过程模型和语义推理规则,并对结果进行分析验证,实现图书资源个性化推荐。
2 文献总结
个性化推荐技术是个性化定制服务[ 3]的一种。本体[ 4]是语义网(Semantic Web)的关键技术,为实现计算机自动处理概念以及它们之间关系提供了支持。将本体技术与个性化推荐技术相结合,是目前很多计算机学者较为关注的一个研究方向。本体在个性化推荐系统中的作用主要有两个方面:通过本体技术进行领域知识建模,构建领域知识库;基于本体的语义表示和规则推理,扩展查询系统的功能或进行基于语义的个性化推荐。例如文献[5]使用本体和基于规则的推理技术建立了一个基于情境的音乐推荐系统,通过用户所处情境、情绪和偏好提供音乐推荐。文献[6]则开发了一个支持本体的学者信息整合和推荐系统,使用本体完成了有效的语义化操作。文献[7]则研发了一个基于领域本体和SWRL的知识推理型专家系统,根据患者的体检结果为医生推荐抗糖尿病药物及治疗方法。
本体技术已经在众多的领域中获得了较好的应用。在图书个性化推荐系统中,不仅需要对图书进行本体表示,还需要建立读者的本体表示。在个性化推荐过程中,基于语义自动计算出与读者本体属性最为接近的图书资源,从而找出最为可能的资源推荐给读者。文献[8]和文献[9]分别从信息检索和知识表示的角度,研究了图书馆资源的本体构建技术和方法,并给出具体的应用,实现了图书信息的基于本体的语义检索和基于知识的资源组织。文献[10-12]则分别提出基于本体的数字图书馆用户本体模型和系统推荐框架,通过对用户偏好进行分析并建模,实现了对用户个性化的资源推荐。
本文在充分借鉴上述研究成果的基础上,在设计推荐系统时,不仅考虑读者个人以前的兴趣偏好,而且将与读者相似的其他读者群的兴趣偏好也作为辅助推荐参考,同时在推荐的结果中加入评价反馈机制,并设计混合式的推荐流程,实现对用户个性化需求的最大满足。
3 推荐方法的实施
3.1 本体设计
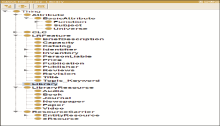
本文遵循以下几个步骤建立本体:确定本体覆盖的领域范围;确定建立本体的目的;考虑现存的本体资源;列出本体中的重要概念词语;确定类目与类目的层次关系;确定类的属性;确定对属性值的描述;创建实例;检查一致性。图书资源本体主要覆盖图书馆馆藏概念,目的在于描述馆藏资源,同时必须包含对推荐有益的概念。根据对图书馆的理解和参考现有的权威图书分类法[ 13],本文设计图书资源本体的主要类有:馆藏(书、论文、报纸、期刊杂志等)、资源载体类型(实体资源、电子资源)、基本属性(宇宙属性、学科属性、功能属性)、中图分类号、馆藏具体特征(标题、主题词、主要责任人等)和图书馆,类之间的关系分别用对象属性(ObjectProperty)或数据属性(DataProperty)对应。本体类层次结构如图1所示,建立的图书本体即推荐方法的数据源。本文选用斯坦福大学开发的本体编辑工具Protégé 4.2构建本体,本体描述语言选择OWL-DL[ 14]。
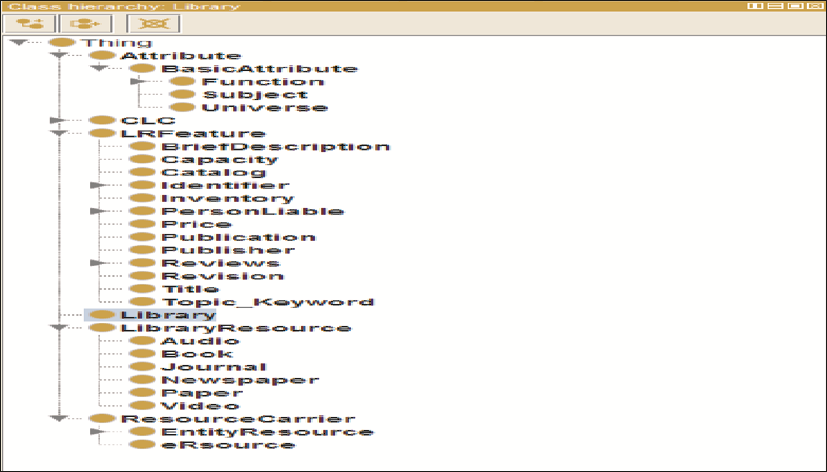 | 图1 图书资源本体的类层次结构 |
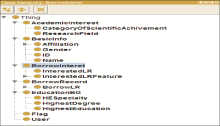
建立借阅用户本体主要覆盖用户的基本概念和能够反映用户行为的概念,目的是表达用户借阅相关的个性特征,因此本体中大部分为影响用户借阅偏好的概念。此外,本文采用基于规则的推理方式解决推荐过程中个性化匹配问题,逻辑规则需要有效的数据源才能进行推理,而借阅用户本体便是应用规则的数据源。用户特征信息的获取方式主要有显式获取和隐式获取两种,很多时候用户并不愿意主动填写表单或问卷来提供自己的个性信息[ 1],因此,目前很多应用都采取了通过观察用户正常的交互行为,自动推测出用户的兴趣偏好。本文主要使用隐式获取用户兴趣的方法,借阅用户本体的主要类有:用户、基本资料(姓名、性别、隶属等)、教育背景(最高学历、最高学位、最高学历专业)、学术兴趣(研究领域、科研成就类别)、借阅记录和借阅兴趣(感兴趣的馆藏及其特征)。其中借阅兴趣由学术兴趣、教育背景和借阅记录几方面信息归纳得到,通过本体中实例(Individual)描述具体用户特征,从而间接反映出用户的个性化行为,类之间的关系选用对象属性或数据属性描述。本体类层次结构如图2所示,构建工具与描述语言同图书资源本体。
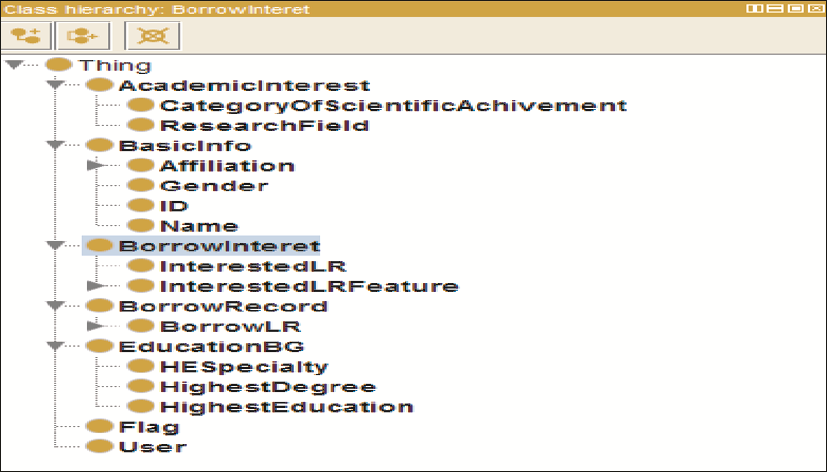 | 图2 借阅者本体的类层次结构 |
3.2 查询修正
传统单文本框一键触发查询的用户查询界面已经无法满足现代用户检索书目的需要,尽管基于关键字的检索有诸如语义模糊的弊端,但还是有办法减少这些问题。目前比较流行的解决方案是分类别检索,例如常州大学图书馆书目检索界面(http://219.230.159.165:8080/opac/search.php)和中国台湾国立中央大学图书馆馆藏查询界面(http://opac.lib.ncu.edu.tw/search*cht)。
本文采取分类别多可选条件联合的查询方式,针对用户的查询不完整、模糊等问题,使用查询修正的方法进行语义补充。查询修正的主要思想是:解析用户查询,判断其是否指定了查询的类别,默认是“全部(All Fields)”;提取指定的类别与其对应的查询,建立一个规范格式的“查询索引”;将查询索引转换成SPARQL[ 15]语言在图书资源本体中检索。一个具体的例子如下:在书目检索界面输入“无线能量传输”并指定查询类型“标题”或“主题词(关键词)”,其生成的查询索引结构如表1所示:
| 表1 查询索引结构 |
生成的SPARQL查询语句如下:
PREFIX LRonto:
SELECT ?lr ?sn
WHERE { ?lr LRonto:hasSN ?sn.
{?lr LRonto:hasTitle ?title. FILTER regex(str(?title), “无线能量传输”,”i”)}
UNION
{?lr LRonto:hasTopic ?topic. FILTER regex(str(?topic), “无线能量传输”,”i”)}
}
3.3 基于规则的推理
在完成用户查询的初检后,对其结果进行个性化过滤,这一步骤主要依靠效用知识(一组逻辑规则)作用于借阅者本体完成。本文建立推理规则将用户的借阅偏好与图书资源的某些特征关联起来,推理得到的结果是用户可能感兴趣的图书资源的某些特征。计算机并不能完全揣测出用户的喜好,只能通过有限依据洞察用户可能感兴趣的对象,因此从理论上讲计算机只能无限接近人工的推荐。例如实际情况可以这样描述:用户的科研领域会影响到借阅偏好,因为通常研究方向是研究人员相对稳定的知识接触范围,一旦发现用户查找其研究方向之外的资料,可以理解为(但不绝对)用户在研究中遇到问题或需要此类知识的帮助,在主要需求内容(用户查询)已经确定的情况下,研究方向会影响检索内容的侧重点;对于用户借过多次的书目,可以理解为用户对这类资源感兴趣,同时可对这类资源进行分析。本文使用Apache Jena[ 16]进行推理工作,与上例情况对应的Jena Rule描述如下:
@prefix Uonto:
@prefix LRonto:
@include
[rule1: (?user Uonto:hasResearchField ?rf)(?user Uonto:hasInterestedLR ?lr)(?rf rdfs:subClassOf ?sf) -> (?lr LRonto:hasRequired
Topic ?sf)]
[rule2: (?user Uonto:hasRepeatedlyBorrow ?maxlr)(?maxlr LRonto:hasTopic ?tpc) -> (?user Uonto: hasInterestedTopic ?tpc)]
与普通过滤不同的是,定义规则只为在初检结果中筛选出可享受加权的资源并将高权重的资源排至结果列表前端,并不删除剩下的结果。这种过滤更像一种排序,考虑到一般用户只会关注结果列表的前几页,会“忽视”后面的结果内容,所以本文将这种排序视为过滤方式。为保证结果的完整性,保留了被过滤掉的记录。
3.4 推荐方法
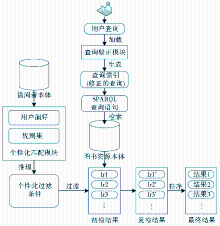
设计了以下方法以完成推荐,推荐过程的主要步骤如图3所示:
推荐的主要依据是用户的查询和用户的借阅偏好。
(1)获取用户查询Q。用户登录后输入查询Q,其中Q={(c1, q1), (c2, q2), (c3, q3) …(cn, qn)},即查询中用户指定的需求类别ci和需求值qi。
(2)处理用户查询。查询修正模块加载用户查询Q处理,生成查询索引QI并临时存储。
(3)检索满足用户查询的资源。根据QI中每个元素的具体情况和元素之间的逻辑关系将查询索引QI转换成对应的SPARQL语句Qsparql,并在图书资源本体中检索出满足条件的资源集合LR={lr1, lr2, lr3 … lrn}。
(4)获取当前用户个性化特征信息。加载借阅者本体中当前用户实例Icurrent对应的借阅偏好信息集合UP={up1, up2, up3 … upn}。
(5)获取个性化过滤条件。当前用户本体实例Icurrent与推理规则集R结合进行推理作业,将用户借阅偏好转化为图书馆馆藏资源特征集LRF={lrf1, lrf2, lrf3 …lrfn}。
(6)检索满足个性化特征的馆藏资源。以LRF为过滤条件对初检结果LR进行再度甄选,得到复检结果LR'={lr1', lr2', lr3'… lrn'}。
(7)结果排序。对复检结果LR'中的每个资源计算其对当前用户的满足程度,用总权重C表示:
C= 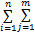
wij:upi⇌lrfj
其中,wij表示用户借阅偏好;upi对应馆藏资源的特征lrfj的契合度,默认值为1;kij表示某条规则生效后的影响系数,0 上述步骤中,最终的推荐结果列表由两部分组成。因为LR'⊂LR,所以结果列表的前端部分(即LR'部分)为经过排序处理的复检结果,余下部分为初检结果中被个性化过滤掉的部分。余下部分的结果通过统计借阅次数(TotalNOL)与用户评价(Rate)进行排序,用S表示每个资源的分值,按降序排列返回,S计算公式如下: S=Rate×TotalNOL(2) 除上述主要推荐方法,本文还整合其他形式的推荐,它们之间并不冲突。每一本书都会有相应的借阅记录,在推荐最终结果列表中,当用户选中某一本书查看详细信息时,在信息末尾加入两组辅助推荐信息:借过这本书的用户还借过;您可能感兴趣的资源。第一项由统计借书记录得到;第二项则是采用经典的协同过滤算法思想计算用户之间相似度,寻找与当前用户最为相似的用户曾经借过哪些书目,用户之间相似度采用余弦相似度[ 17]计算公式得到: sim
=cos 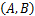
(3) 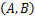
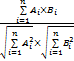
其中,A(当前用户向量)和B是从用户基本信息和借阅偏好中选出的可量化的特征组成的向量,用来代表用户,sim(A, B)值越大,B与A越相似。通过将主要推荐方法与辅助推荐方法组合提高推荐效果,尽可能让用户找到满意的结果。
3.5 反馈机制
通过用户的反馈信息对推荐流程进行检查与调整是一种常用有效的手段。本文认为在推荐过程中允许用户反馈十分重要,因此,设计反馈模块让用户分别对使用推荐的全过程进行满意度反馈和对已借书目内容进行评价。对全程使用满意度用Likert Scale[ 18]进行统计,对已借书目评价用电子商务网站常用的星级进行统计。两种反馈需分开进行,全程使用满意度在推荐结束时给出,书目内容评价须在用户阅读其内容后给出,如此安排是考虑到推荐的结果若在理论上和逻辑上确是用户所需,但是用户受到所处情境的客观影响与主观改变(如天气突变、疾病等)会间接导致对结果的不满。反馈信息将被保存,据此更新本体、语义规则及影响系数等。反馈模块加入推荐方法的循环周期也提供了整个方法自身的可伸展性。
4 实验验证
4.1 实验设计
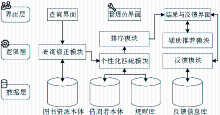
为验证本文提出的推荐方法的有效性,设计两组实验从不同角度对推荐过程进行评估。实验开始设计了一个Demo系统用于实施推荐方法,系统模型架构如图4所示:
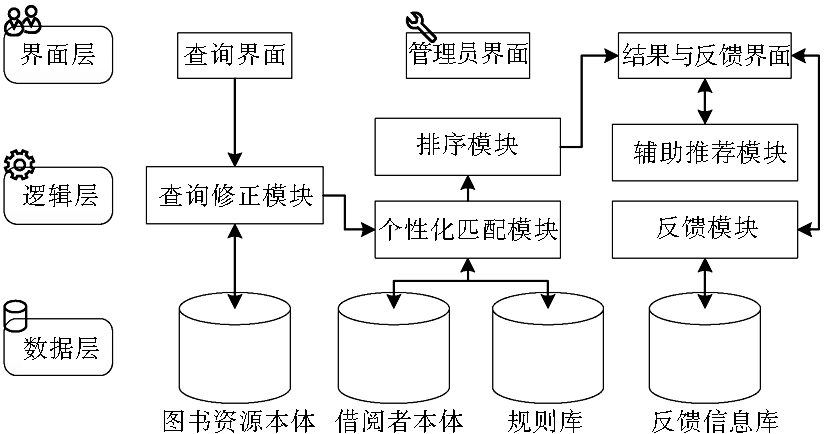 | 图4 Demo系统模型架构 |
该模型架构总体分三层:数据层、逻辑层和界面层。用户在查询界面输入查询,经查询修正模块处理,在馆藏资源本体中检索获取初检结果;个性化匹配模块依靠Apache Jena组建,接收初检结果并管理语义规则与本体,通过推理操作完成个性化过滤阶段;最终复检结果送入排序模块,结果呈现在结果与反馈界面;辅助推荐模块在结果列表中添加额外的推荐信息;反馈模块负责管理反馈信息;管理员界面可对全系统进行设置。
实验的数据样本中,馆藏资源样本来自于常州大学图书馆系统数据,在中国图书馆分类法[ 13]22个大类中(工业技术类包含下一级子类),每一类随机选取30本书目。用户样本选自常州大学信息科学与工程学院部分研究生共30人。另外,由6位老师组成的专家小组将对推荐结果进行人工评价。
4.2 第一组实验及结果分析
采用查准率(Precision)、查全率(Recall)和F-measure为标准评估推荐方法的实际表现,其公式如下:
Precision=
 | (4) |
Recall=
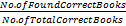 | (5) |
F-measure=
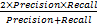 | (6) |
需要说明的是,在公式(4)中,由于每一次推荐结束用户一般只会在结果中选取至多3本书借阅,如果以用户最终选择的结果作为公式中的分子,查准率会普遍很低。本文认为虽然用户只选择了至多3本书目,但是并不代表结果中剩下的书目就是不相关内容,所以委托专家小组对这些图书进行了人工鉴别,归纳出符合当前用户需求的图书并以此作为公式(4)和公式(5)的分子,其他方面正常计算。
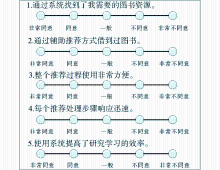
采用Likert Scale评估用户对整个推荐过程的满意度,共设计了5个Likert Item,具体设计如图5所示:
 | 图5 评估用户满意度的Likert Scale |
| 表2 系统性能实验结果 |
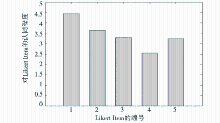
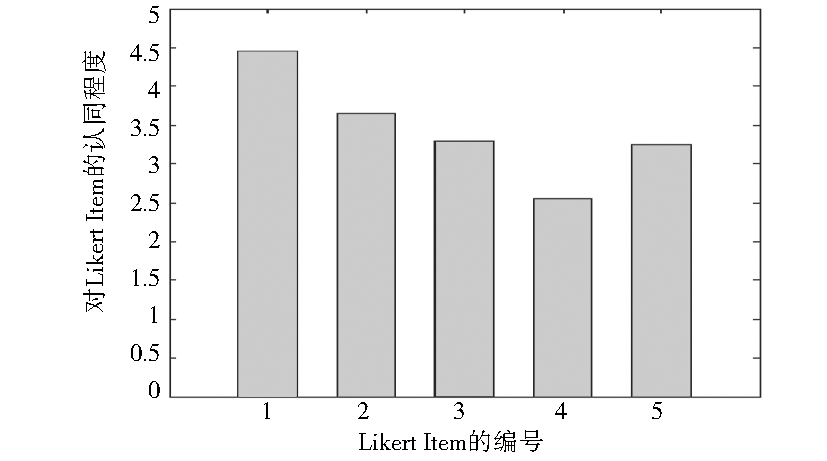 | 图6 用户满意度Likert Scale的结果 |
实验结果分别如表2和图6所示。其中表2呈现了不同数量用户使用时系统的实际效果,数据为对应用户数的平均值。取3条记录结果的平均值可得,系统的查准率约为69.0%, 查全率约为85.8%。 但从3条记录结果分布看,查准率和查全率应略高于这个平均值,使用人数越多数据变动越小,由结果可以看出,推荐方法效果良好。图6的Likert Scale中,将同意程度按1到5表示,越高则越认同。显示的结果为所有参与反馈的用户结果的平均值,可以看出,5项中有4项高于总分的60%,除第4号Likert Item的认同程度较低(响应速度)外,用户对推荐过程基本满意。
4.3 第二组实验及结果分析
将该推荐方法与传统的基于用户的协同过滤方法做横向比较,评测标准采用平均绝对误差MAE(Mean Absolute Error)。平均绝对误差可用于衡量预估值与实际值之间的平均差异,其值越小说明推荐效果越好。MAE的计算公式如下:
MAE=
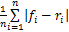 | (7) |
其中,fi表示对用户推荐的预估评分值集{f1, f2, f3 … fn},ri表示用户的实际评分值集{r1, r2, r3 … rn}。实验中分别在用户的教育背景、科研领域、科研成果类别、借阅信息统计(借阅最多、最近借阅)几个方面预定义5个规则,包括每个规则的影响系数。推荐预估分值用个性化匹配中的每个资源获得的总权重表示;实际评分由用户对书目内容的评价(5星制)转换成百分比乘以当前推荐生效规则总数(如3.4节所述,每条规则对应权重最高为1)表示。
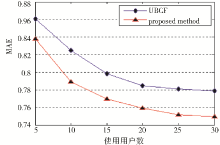
实验结果如图7所示:
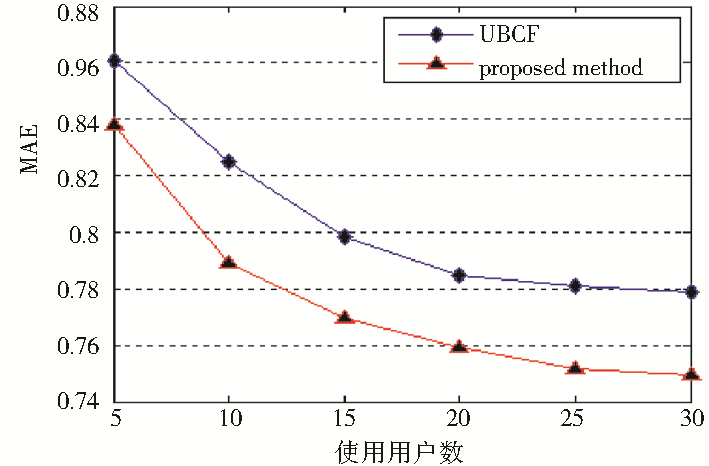 | 图7 推荐方法比较结果 |
随着用户数量增加,MAE值逐渐下降,当用户数增至一定数量,MAE值变化趋于稳定。可以发现本文提出的推荐方法整体MAE值较小,相比传统基于用户的协同过滤方法具有更好的推荐效果。
5 结语
信息过载使得研究人员在图书馆中查找资料的效率下降,本文提出一种基于本体的混合式图书推荐方法,通过修正用户的查询和个性化匹配得到满足用户需求与兴趣的图书资源。此外,组合了辅助推荐方式提供间接的支持,提高了推荐命中的可能性。由于采用基于规则的推理完成个性化匹配,面对新加入的没有使用记录的用户与未获得一定数量评价的对象,某些根据用户的历史记录或对象评价信息制定的规则无法使用,但是根据其他方面制定的规则依然可用,可见本文提出的方法受传统协同过滤方法的“新用户”与“新对象”问题的影响不大,新用户与新对象可照常参与推荐。经实验验证,该方法可行并具有良好的效果,能够提高图书借阅质量。下一步的工作是研究更科学的流程部署,例如在用户查询的同时预加载个性化匹配模块,提高推荐过程响应速度;继续研究用户借阅偏好与图书特征之间的联系,调整扩充语义规则以应对更多的用户特征,提高实用性。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|