
{kind=link}
{kind=link}
{kind=link}
一种基于和声搜索的协同过滤算法研究*
引用本文
王华秋. 一种基于和声搜索的协同过滤算法研究* . 现代图书情报技术, 2012, 28(12): 79-84
Harmony Search. Research of a Collaborative Filtering Algorithm Based on. 现代图书情报技术, 2012, 28(12): 79-84
Permissions
Harmony Search. Research of a Collaborative Filtering Algorithm Based on. 现代图书情报技术, 2012, 28(12): 79-84
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
一种基于和声搜索的协同过滤算法研究*
摘要
改进传统的相似度计算方法,为寻找最优的相似度函数,采用参数优化的和声搜索算法来寻找相似度函数的最优权值向量。为提高推荐速度,得到最优的相似度函数后,对于用户的推荐计算不再采用和声搜索算法。实验表明,和传统算法相比,该算法能提高预测精度和覆盖率,有更好的推荐效果,并能够更快地获得目标用户的最邻近用户,加快推荐的速度。
关键词:
协同过滤; 相似度函数; 权值向量; 和声搜索算法
中图分类号:TP311 TP391
Research of a Collaborative Filtering Algorithm Based on
Abstract
The traditional similarity algorithm of collaborative filtering is modified in this paper. In order to find an optimal similarity function, the paper presents harmony search algorithm with parameters optimization to find the optimal weights vector of similarity function. To improve the speed of recommendation, harmony search algorithm is no longer used for the calculation of the recommendation after finding the optimal similarity function. The validation experiments show that the proposed algorithm improves prediction accuracy and coverage so as to provide better recommendation. And the proposed algorithm can more quickly obtain the nearest neighbor users of the target user, which can accelerate the recommended speed.
Keyword:
Collaborative filtering; Similarity function; Weights vector; Harmony search algorithm
1 引 言
个性化推荐技术的基本原理是期望用户组和目标用户相似,这样就能比较正确地预测目标用户对没有进行评价的产品的兴趣度[ 1]。近年来,个性化推荐技术越来越重要,已经应用在很多领域中,包括数字图书馆[ 2]。
个性化推荐技术的核心技术是过滤算法。协同过滤(Collaborative Filtering, CF)是一种常用的过滤算法,其原理是:首先搜索与目标用户习惯最接近的用户群体,然后将大多数相似用户评价最高的项推荐给目标用户[ 3]。能否及时准确地找到目标用户的最近邻居关系到整个系统的推荐质量,如何进行准确并快速地计算用户相似性成为提高推荐准确性和高效性的关键。常用的相似性度量方法有余弦相似性[ 4] (简称COS)、Pearson相关系数[ 5] (简称COR)和约束Pearson相关系数[ 6] (简称CCOR)。
与传统的推荐技术相比, 协同过滤能够过滤掉多数难以自动进行内容分析的信息, 还可以共享他人的经验,具备推荐新信息的能力。但是由于需要利用用户对项目的评价数据,协同过滤存在以下需要解决的问题[ 3]:
(1)稀疏性:在许多推荐系统中,用户-项目评估矩阵相当稀疏,一般用户评价信息所涉及到的商品只能占总数的1%-2%。
(2)精确性:在用户评分数据极端稀疏的情况下,传统相似性度量方法存在一定的弊端,使得计算得到的目标用户的最近邻居不准确,推荐系统的推荐质量急剧下降。
(3)效率性:随着用户数据量的增大,传统算法将遭遇严重的效率问题,造成推荐时间过长或系统瘫痪。
为了产生精确的推荐,并满足推荐系统的实时性要求,许多学者将多种人工智能算法应用于推荐系统中[ 7, 8, 9]。一种常用的用于提高推荐系统性能的技术就是将用户进行聚类,这样可以得到相似的用户,然后,协同过滤技术就可以用于每一类相似用户中,这样可以减少计算时间,文献[7]提出了一种遗传聚类算法用于协同过滤的推荐系统中。文献[8]提出了基于聚类免疫的协同过滤推荐算法。文献[9]利用蚁群算法实现用户聚类,以提高协同过滤推荐系统的最近邻查询速度。
本文研究了一种新的智能优化算法——和声搜索算法,该算法与遗传算法、粒子群算法、蚁群算法一样,都是一种启发式搜索算法,已经被应用于许多方面[ 10, 11, 12]。由于其调音概率和随机带宽这两个参数设置随机性较大, 缺乏方向性,造成和声搜索算法在一些情况下不能很好地搜索到精度较高的解,而且容易陷入局部最优,针对这些问题,本文提出了和声搜索的参数优化方法,并将参数优化的和声搜索算法应用到协同过滤中来,提出了一种基于和声搜索的协同过滤推荐技术,将和声搜索与协同过滤算法的优点结合,对协同过滤算法的相似度函数进行改进,以解决稀疏性、精确性和效率性等问题,可以产生精确的个性化推荐结果。
2 改进的协同过滤相似度函数
w(i) 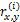
假设有一组用户U ={1,…, U},以及一组项目I ={1,…, I}。用户的评价值范围是m到M,m表示用户对项目不满意,M表示用户对项目完全满意。
对于MovieLens数据库(http: //movielens.umn.edu),可以设m=1,M=5。
用户一般只会对感兴趣的项目进行评分,没有评分的项目本文用null表示,如下所示:
rx=( 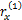
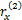
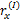
由于用户参与评分的项目并不多,这就造成了用户-项目矩阵的稀疏性。传统的相似度计算方法,如COS[ 4],COR[ 5],CCOR[ 6]等,都无法妥善处理矩阵中的null项,从而造成误差较大,基于此本文改进了传统的相似度计算方法。
对于任意两个用户u和n,假定总有都进行了评价的项目,这些共同项目可以计算出x和y的关系,在这些项目中,x和y评价的分数之差的绝对值在0和M-m之间,为了将这些评分差值归一化,用这些差异评分值除以u和n共同评价的项目总和,这样每一项的值就不会超过1,如下所示:
ru,n=( 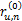
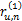
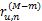
因此可以得到u和n对所有评价项目的差别如下:
ru,n=( 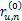
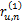
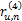




这样做的优点在于,无论u和n的评分项目有多少,都可以产生两者之间的关系向量ru,n,进而计算两者的相似度。
为计算相似度,为每个评分差异项ru,n进行加权,权值向量w和ru,n对应w=(w(0),w(1),…,w(M-m)),对于MovieLens数据库,按照如下原则设定:
(1)对于 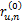
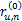
(2)对于 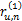
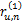
(3)对于 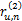
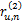
(4)对于 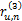
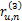
(5)对于 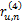
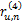
为ru,n得到如下权值向量:
w=(w(0),w(1),…,w(M-m))=(1,0.5,0,-0.5,-1)
本文定义u和n的相似度函数:
simw(u,n)=
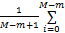 | (1) |
本文采用共同评分项的差异值rx,y解决了评分矩阵的稀疏性问题,但是,新的问题又出现了,从上面的推导中可以看出,rx,y是一个客观的值,但是其权值向量w却是一个主观设定、由人为确定的相关权值系数,但是这样的主观设定并不能保证获得一个最佳的权重向量。如何寻找一个最优的权值向量以获得最合适的相似度函数,这一问题关系到协同过滤推荐系统是否有效。不妨假设,在所有可能的权值向量w的取值中,总有一个向量能为本文算法提供一个具有最小平均绝对误差(Mean Absolute Error, MAE)的一组向量。这就需要通过不断训练和测试过程而获得最优推荐系统,为获得这个问题的最优解,本文采用和声搜索算法。
3 和声搜索算法的研究与改进
为了找到最优的相似度函数,本文采用和声搜索算法来寻找相似度函数最优的w权值。本文采用监督学习策略,其适应度函数是推荐系统的平均绝对误差MAE。权值向量的不同取值构成和声搜索算法的和声库,库中每一组和声向量代表一组可能的权值,本算法将用这样的值计算推荐系统的误差。当算法运行的时候,连续的和声库向量迭代将改善推荐系统的MAE。当MAE低于预期的阈值时和声库向量的迭代终止。
本文只使用推荐系统的一部分数据,以获得最优的相似度权值,从而获得最优的相似度函数,之后本文将利用这个相似度函数来计算测试用户和项目的相似性,即是说,这些测试用户和项目的相关计算不再用到和声搜索算法,从而提高了计算速度。
3.1 和声库向量表示
和声库向量一般都用实数表示[ 13]。本文的w向量的任意元素w(i)用小数表示,因此,用下面的方法表示w=(w(0),w(1),…,w(M-m)):
HM= 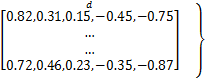
其中,和声库HM的行数为HMS,本文设为50,代表50种不同的权值向量组;列数为d,本文设为5,代表每组权值向量的个数。每一行代表一组权值向量,这些向量可以直接用于相似度函数的计算,而无需任何转换,这比遗传算法更加方便。
3.2 初始化和声库
既然w的值代表用户之间相似度函数的权重,那么可以认为在最优的相似度函数中,按照不同的权值代表的不同的用户之间的相关性,把w(0),w(1),…,w(M-m)依次放在正相关到负相关逐渐过渡的范围中。据此,得到如下的w初始化范围分布:
w0∈ 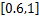
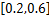
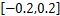
w3∈ 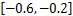
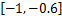
在以后的搜索计算中,也把w的更新值限制在上述范围内,这样可以保证得到合理的最优权值向量。
3.3 适应度函数
= 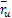
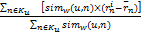
和声搜索算法的适应度函数用于描述每组和声向量对应的权值向量w的优劣程度,采用推荐系统的平均绝对误差MAE作为权值向量的适应度函数。
MAE通过比较真实评价值和预测值而得到,计算步骤如下:
(1)通过计算相似度函数,获得用户u的最邻近的k个用户;
(2)计算用户u对于项目i的预测评分[ 14]:
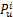 | (2) |
其中, 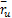
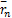
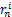
(3)最后计算平均绝对误差MAE值[ 4]:
fitness=MAE=
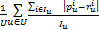 | (3) |
其中,U表示训练用户数量,Iu表示训练项目数量,MAE值越小,说明预测精度越高。
3.4 和声搜索操作
本文的和声搜索算法采用常见的操作[ 13]:和声库中选择、从和声库中选择后调音、在允许范围内随机产生。利用这三种经典的操作可以快速得到理想的优化结果。
(1)选择和随机产生:选择概率HMCR决定了是否从和声库HM中选择变量来构成新的向量元素的概率,其变化范围是0到1,一般比较靠近1,本文设为0.9。(1-HMCR)是决定是否从上下限范围内随机产生新的变量的概率。选择和随机产生操作如下所示[ 13]:
w'ij=
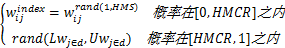 | (4) |
其中,Lwj∈d指向量组中第j个w值的下边界,Uwj∈d指向量组中第j个w值的上边界。
(2)调音:如果新的向量元素是从和声存储库中得到,那么该变量还要决定是否调音,PAR是初始调音的概率,一般比较靠近0,本文取值为[0.1,0.4],便于其动态调整,概率(1-PAR)是不需要调音的概率,调音是在原来的变量的基础上增加或减少一个随机带宽量bw。调音操作如下所示[ 13]:
w'ij=
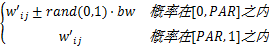 | (5) |
上述三种方法产生的新的和声将被返回并用于更新和声库。
3.5 和声搜索参数设置的改进
从和声搜索算法描述可见,该算法的调音概率和随机带宽这两个参数设置都不能随着当前变量的变化情况而发生变化,而是采用某种固定的形式,造成和声搜索算法缺乏自适应性,不能很好地跳出局部最优,本文采用如下方法动态改变这两个参数:
调音的时候,可以动态地改变调音概率PAR和随机带宽量bw的值,以提高算法的收敛性。调音概率PAR的更新公式如下:
PARi=PARmin+i×
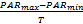 | (6) |
其中,i是第i次迭代,T是迭代的总数,PARmax和PARmin分别是最大和最小的调音概率,这样算法迭代初期,PARi比较小,运行若干次后,和声库里的向量有趋于相同的趋势,为了提高和声库向量的多样性,需要适当提高调音概率,上述公式能保证PARi趋于最大值PARmax,避免了算法早熟而收敛到局部极小。
随机带宽量bw的调节规则如下:
bwi=
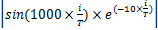 | (7) |
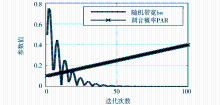
这种调节方式使得bw的值起初振荡,然后逐渐固定下来,振荡部分逐渐受阻,最终bw趋于0.000 1附近,这种调节规则对于增加算法的收敛速度和精度很有作用,如图1所示:
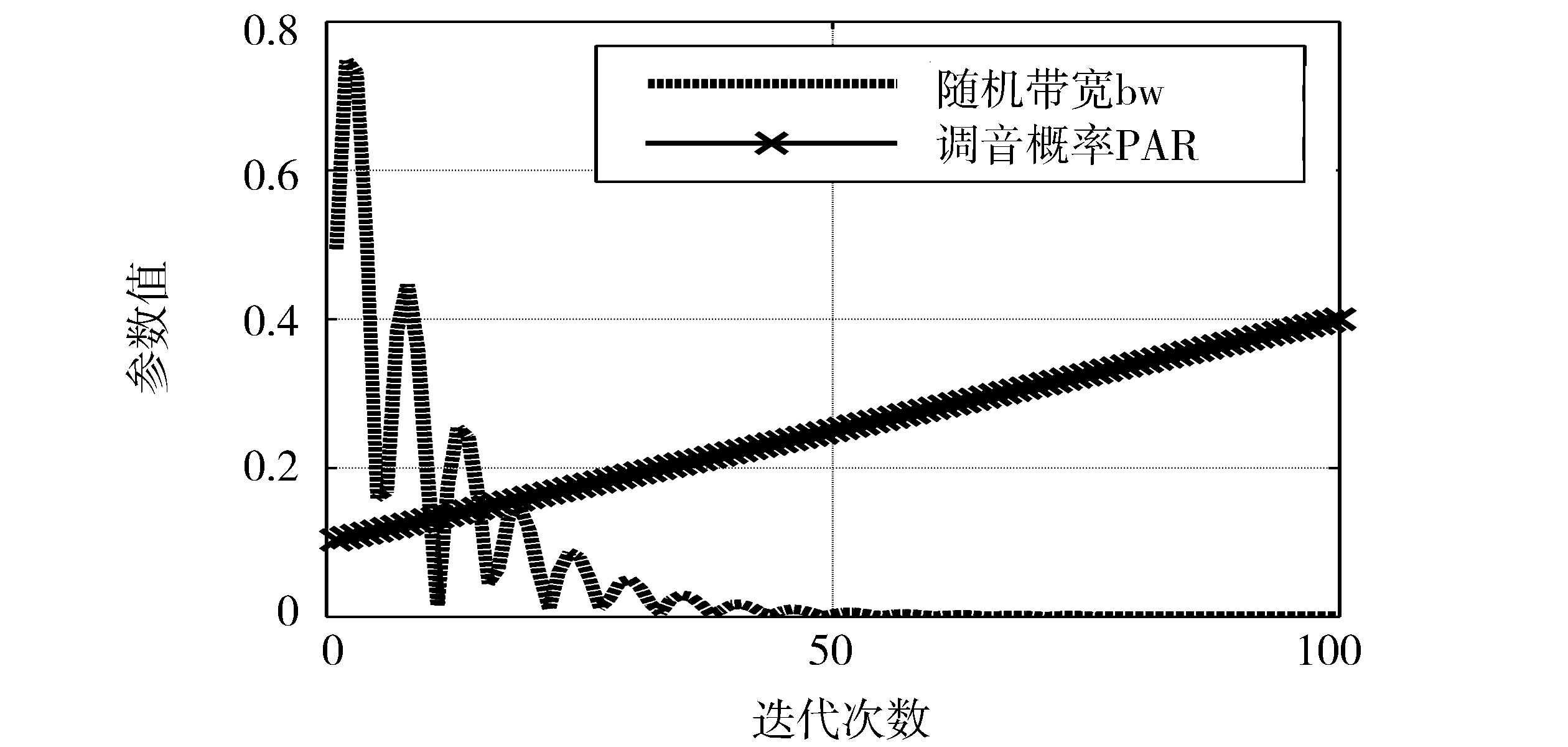 | 图1 和声搜索算法的参数设置 |
这样调整之后,音符调节概率PAR与随机带宽bw都是变量。在算法开始运行时,改进后的和声搜索算法具有较小的PAR和较大的bw,这样该算法可在全局寻优;而当迭代多次后, 算法具有较大的PAR和非常小的bw, 以便在局部范围内寻找最优解。
3.6 更新和终止
每次迭代后将产生一组和声向量,如果新的和声向量在适应度上优于和声库中的最差的向量,那么就用新的和声向量取代那个最差的向量。同时找出和声库的最佳适应度。由于是替换,因此每次迭代之后,和声库向量组的数量保持不变[ 13]。
当和声库中的最佳适应度值低于某一阈值时,和声搜索过程终止,对于MovieLens数据库(m=1和M=5),本文将阈值设为0.78;或者当算法迭代次数达到500次时,计算过程也会终止。
4 实验设计
实验数据库是MovieLens,采用两类实验来比较各种推荐系统,编程工具采用Matlab7.1。
4.1 预测和推荐质量评价实验
采用两个推荐质量评价指标[ 4]:平均绝对误差MAE和覆盖率C。
覆盖率是所有能够预测的项目占项目总数的比例,设为目标用户u提供的预测项集合为Pu={ 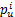
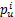
C=
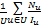 | (8) |
文中提出的算法将和传统的协同过滤算法进行比较,比如余弦相似性(COS)[ 4]、Pearson相关系数(COR)[ 5]和约束Pearson相关系数(CCOR)[ 6]。
由于提出的和声协同过滤推荐算法是一种启发式搜索算法,具有一定的随机性,因此运行算法20次,以找出其中适应度最大和最小的两次运行结果,用于和传统的协同过滤算法进行比较。用本文的算法、COS、COR和CCOR等几种协同过滤算法分别计算MAE和C这两个评价值。
只用一部分数据来训练提出的算法以获得最优的相似度函数,一旦获得该函数,就用它来对测试数据进行预测和推荐,而不必再调用和声搜索算法来寻优。
对于MovieLens数据,随机选择80%的用户作为训练数据,剩下20%的用户作为测试数据。对于用户的最近邻居个数k的设定,取在[10,100]之间。
4.2 性能实验
这类实验用于验证本文提出的算法是否比传统的相似度算法更加高效。从理论上讲,由于本文提出的相似度函数比传统的算法更加简单,因此,获得任意目标用户的k最邻近用户应该比传统算法更快,从而进行预测和产生推荐的速度也就更快。
5 结果分析
5.1 预测和推荐结果
将MovieLens数据库进行测试后,得到两个评价值的结果。
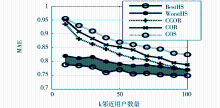
(1)平均绝对误差MAE:COS、COR和CCOR以及本文的算法得到的MAE值中,本文算法对应的MAE值最小。MAE的对比结果如图2所示:
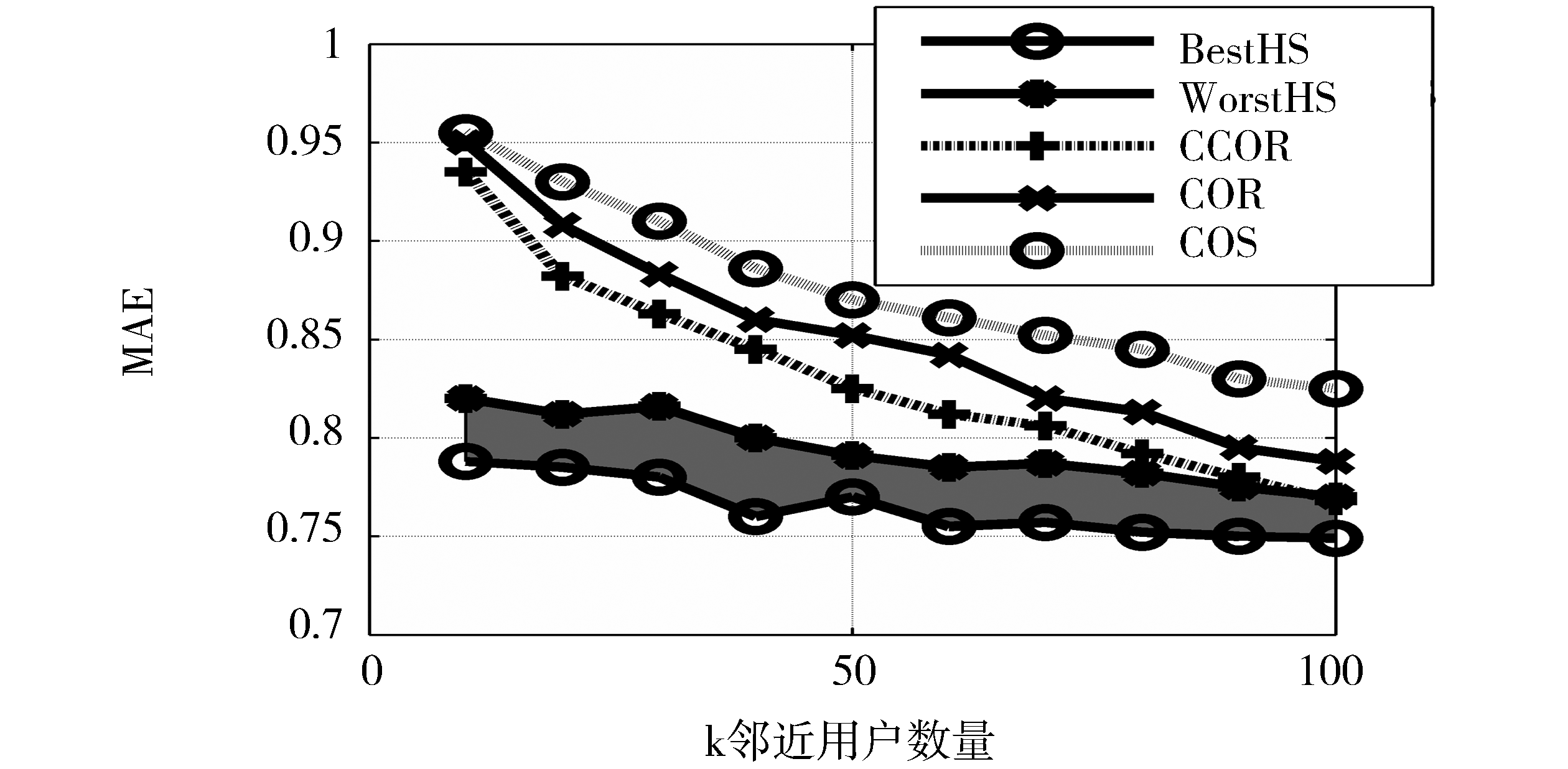 | 图2 各种算法的平均绝对误差MAE |
(2)覆盖率C:本文算法提高了k取值[10,100]时的覆盖率C,无论是适应度最大还是最小时,相比之下,本文算法可以获得最佳的覆盖率。C的对比结果如图3所示:
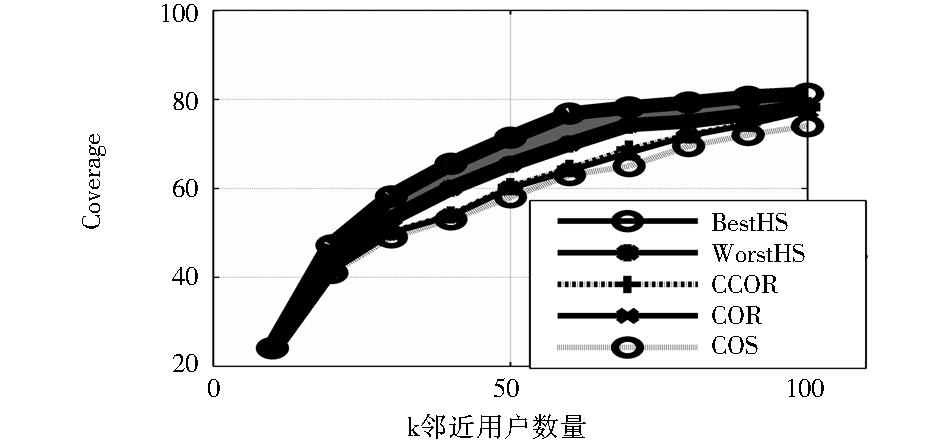 | 图3 各种算法的覆盖率C |
综上所述,本文算法提高了预测精度和覆盖率,综合考虑MAE和覆盖率C,当k取较大值时,可以同时获得最佳的MAE和覆盖率C,这将提供更好的推荐效果。
5.2 性能结果
性能比较结果显示,本文算法比传统相似度算法所用的时间更少。各种算法的运行性能如表1所示:
| 表1 各种算法的性能结果 |
为一个目标用户寻找k最邻近用户几乎占用了推荐系统的全部时间,因此简化用户之间的相似度函数的计算方法对于加速推荐过程来说就显得尤为重要。本文提出的采用自适应加权相似度函数简化了相似度计算公式,相应算法推荐速度比传统方法更快。
6 结 语
协同过滤算法存在一些问题,如评分矩阵稀疏性、推荐准确性低、推荐效率性低。为解决这些问题,本文提出和声搜索算法来获得最优的协同过滤推荐系统的相似度函数,其关键技术在于:
(1)改进了相似度计算方法,该方法利用评分等级的差异进行加权统计,如公式(1)所示。避免了直接用评分矩阵来计算用户间相似度的方式,从而解决了协同过滤中评分矩阵稀疏性问题。
(2)提出了和声搜索算法的调音概率和随机带宽的定量化计算方法,如公式(6)和公式(7)所示。可以避免和声搜索算法陷入局部极小,从而保证了该算法能找到最优的相似度权值向量。
对于标准数据库MovieLens,本文将提出的算法和经典的三种算法进行对比实验,结果表明,本文提出的算法提高了预测的精度和覆盖率,为系统提供了更好的推荐效果。
由于本文只考虑了用户评分等级的差异,接下来可以利用更多的客观信息来评价用户间的相似度,进一步改进相似度计算方法,如考虑评分等级的差异的均值和方差等因素。此外,将该算法用于数字图书馆图书推荐系统中也是今后需要开展的工作。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|