
{kind=link}
面向在线群体研讨的言语行为分类体系设计框架研究
[李嘉1, 2  , 张朋柱
, 张朋柱2 , 李欣苗3 ]
, 张朋柱|
|


缺乏言语行为分类体系及其构造方法论,已经成为国内言语行为自动化分析研究的一个主要障碍。以信息系统设计理论为指导,提出言语行为分类体系的设计需求,并以流程为人造物的观点,研究设计出一个包含5个关键步骤的迭代流程来满足设计需求。进一步以该方法论为指导,以E-learning环境语料为案例,提出一个适合在线问答研讨的言语行为分类体系,并验证该体系的辨别能力和泛化能力。E-learning语料环境的应用结果表明,该言语行为分类体系构造方法论具有较好的效果。
The lacking of studies on speech act analysis in Chinese context can be attributed to the short of speech act taxonomies.This research follows the paradigm of design science by proposing the design requirement for speech act taxonomy, and develops an iterative process that contains five steps to satisfy the design requirement. Further, the authors develop speech act taxonomy for E-learning environment based on the proposed methodology, and evaluate its discernment and generalization ability. The successful application in E-learning environment validates the effectiveness of proposed design framework for speech act taxonomy.
随着计算机和网络技术的发展,以BBS、网络论坛、群件、即时通讯工具、虚拟社区为代表的计算机支持的协调工作(Computer Supported Collaborative Work,CSCW)和以计算机为媒介的交流(Computer Mediated Communication,CMC)已经渗透到了工作生活的各个方面,在不长的历史内产生了海量的研讨文本数据,并且这些数据目前仍以指数级的速度在增长。传统靠人工分析研讨文本的做法,不仅费时费力费钱,而且通常不能全天在线工作。因此迫切需要能够自动分析和处理群体研讨文本,如果能够自动分析这些研讨数据的言语行为关系并得到一些有益的结论,将是开创未来许多研究与应用的第一步。而引入言语行为并对其进行自动分类是实现这类自动处理中关键的一个步骤。
言语行为理论[ 1]认为人们在以言行事。根据言语行为理论,说话的同时是在实施某种行为。因此,网络研讨平台上的发言对话可以被认为是一种言语行为的轮转。言语行为的自动分类对于机器理解和刻画研讨势态尤为重要。言语行为被用于识别说话者的意图,这对于确定答复的言语行为分类体系[ 2, 3]非常重要。言语行为识别还可以用于浅层解析,识别言语行为等价于在一个更高层面上理解用户的发言[ 4]。如果机器能够辨别出发言的言语行为分类体系,等于理解了用户基本的谈话意图,可以据此来刻画研讨势态。因此,言语行为分类体系和言语行为自动分类研究对于对话系统(Dialogue System)、机器翻译和自动问答系统中问题理解和问题的自动分类具有重要的意义。
进行言语行为分类的第一步是构建言语行为分类体系。目前国内关于言语行为自动化分析的研究还较少,而言语行为分类体系的缺乏是主要障碍。据笔者所知,目前还没有系统化的关于构建言语行为分类体系的方法论,因此本研究试图提出面向在线群体研讨的言语行为分类体系构造方法论,并通过一个E-learning环境的语料来说明这一方法论的实施。
国外已经对言语行为分类体系进行了一系列研究,并发展出了若干个经典的言语行为分类体系。
最流行的分类体系叫DAMSL[ 5],最初被定义成通用的言语行为体系。其他的一些在特定语料上开发的分类体系,如CallHome[ 6]或VerbMobil[ 7],后来也变得流行。DAMSL是Dialogue Act Markup in Several Layers的缩写。对话在4个不同的层次上被标注,分别是Communicative Status,Information Level,Forward-looking Function和Backward-looking Function。另一个基于DAMSL被广泛使用的分类体系叫SWBD-DAMSL[ 8],它基于Switchboard Corpus[ 9]。80%的类别以原始或修改版出现,只有一些类别被加入(例如Communicative Status中的“Non-verbal” Category),而另一些DAMSL的类别则被进一步细分(例如“Statement-Non-Opinion”和“Statement-Opinion”)。为西班牙语对话语料CallHome[ 6]设计的分类系统包括最初版本的232种言语行为标签。这体现了一般类别(如Statement/Question)和一些更特殊描述(如发言是否描述了发言者的情感状态)的结合。
在所有为单个项目设计的言语行为分类体系中,有一个叫VerbMobil[ 7]。它也是一个单层标注体系,包含大概33个言语行为标签。这些从执行过的行为出发来表述发言,如Greet, Give Reason, Reject, Feedback Positive等。另一个为单一项目设计的分类体系是Estonian Dialogue Corpus (EDiC)[ 10]。这个分类系统包括两层标注:高层说明发言的一般类型(Ritual, Questions/Answers, Directive, Additional Information, Repair等),总共有12种类型,其中7种存在配对标签(即一种对应开始,另一种对应回答),5种只有单个标签;低层则在更多的细节上描述发言,每个高层类型可能有好几个子类型,例如Rituals可以进一步分成Greeting,Thanking,Apologizing等,Questions/Answers则可以进步分成WH-Questions, Open and Closed Yes/No Questions,Refusal to Answer,Yes/No Answers等,低层标注中总共有126个标签,各类别在大小上差别很大。
言语行为分类体系及其自动识别相关的应用研究主要集中在对话系统、机器翻译和自动问答系统三方面。对于对话系统而言,言语行为被用于识别说话者的意图,这对于确定答复的言语行为类别[ 2, 3]非常重要。另一种经常使用言语行为的场合是机器翻译,一个正确识别的言语行为可以帮助解决翻译发言中的歧义[ 11]。一个发言的语法规则并不总是与实际的意图相一致,例如:“Could You Close the Window?”实际上并不是一个问题,而是一个请求。同时,不同的语言在语法上有不同的礼貌形式来表达同一件事情。另外,言语行为分类体系对于自动问答中问题的自动分类也具有重要的意义[ 12, 13]。问题分类是根据疑问句的疑问语义进行分类,这种分类可以帮助理解问题的疑问语义以及问题的回答。因此本研究对解决对话系统、机器翻译和自动问答系统中言语行为分类体系建立的问题具有一定的积极作用。
根据设计科学的研究模式,设计既是一个产品又是一个过程[ 14, 15]。Walls等[ 15]提出了一个规划信息系统设计理论(Information Systems Design Theories, ISDTs)的模型。这一理论包含了指导一个ISDT设计产品的4个组成部分:核心理论(Kernel Theories)、元需求(Meta-Requirments)、元设计(Meta-Design)和可测试的假设(Testable Hypotheseses),如表1所示:
| 表1 一个ISDT设计产品的组成部分[ 15] |
其中,核心理论支配元需求,而元设计通过为IT人造物(IT Artifact)提供详细的设计说明来完成元需求。可测试的假设被用来检验元设计是否满足了元需求。
基于Walls的模型,提出了一个言语行为分类体系研究框架,如表2所示:
| 表2 面向研讨平台的言语行为分类体系研究框架 |
言语行为理论(Speech Act Theory)[ 1]最初是由英国哲学家J. L. Austin在20世纪50年代提出。在语言学(Linguistics)和语言哲学(Philosophy of Language)大部分的历史里,语言主要被看作是一种表达事实声明(Factual Assertions)的手段,而语言其他的使用则常常被忽略。Austin的工作,尤其是他的著作“How to Do Things with Words”[ 1],让哲学家更多地注意语言典与非陈述性用法。他引入的术语,尤其是“Locutionary Act”, “Illocutionary Act”, 和“Perlocutionary Act”,在后来称为言语行为的研究(Study of Speech Acts)中起到了重要作用。所有这三个行为,尤其是“Illocutionary Act”,现在统称为言语行为(Speech Acts)。
言语行为理论认为人们在以言行事。根据言语行为理论,说话的同时是在实施某种行为,说话者说话时可能同时实施三种行为:言内行为(Locutionary Act),言外行为(Illocutionary Act)和言后行为(Perlocutionary Act)。言内行为是说出词、短语和分句的行为, 它是通过句法、词汇和音位来表达字面意义的行为。言外行为是表达说话者的意图的行为,它是在说某些话时所实施的行为。言后行为是通过某些话所实施的行为,或讲某些话所导致的行为,它是话语所产生的后果或所引起的变化,是通过讲某些话所完成的行为。
美国的哲学语言学家Searle扩充了Austin在言后行为上的工作[ 16]。他的主要贡献是试图定义执行动作的必要条件和充分条件。Searle还提出了言语行为的几个维度,并以此为基础提出了言语行为的分类体系,他将言外行为分为5类,每一类行为都有一个共同的、普遍的目的。这5大类是:
(1)阐述类:陈述或描述说话者认为是真实的情况;
(2)指令类:试图使听话者做某些事情;
(3)承诺类:说话者自己承诺未来要有一些行为;
(4)表达类:表达对某一现状的感情和态度;
(5)宣告类:通过说话引起骤变。
每一类中的行为都有同样的目的,但具有同样目的的言外行为可能具有不同程度的言外之力。
本研究满足核心理论的基本需求包括辨别能力和泛化能力两部分:
(1)辨别能力:用来衡量言语行为标签定义的清晰程度。言语行为标签定义越清晰,其辨别力越强;否则辨别力越弱。
(2)泛化能力:用来衡量一个言语行为分类体系推广到其他领域的难易程度。泛化能力越强的言语行为分类体系,其包含的类别标签越容易被重用到其他领域。
元需求直接来自于核心理论,而元设计的目标是引入一系列预期能满足元需求的人造物[ 15]。鉴于言语行为分类体系设计研究的特殊性,在本研究中引入的人造物不再是系统设计,而是流程设计,即言语行为分类体系设计的基本步骤和流程。下面分别介绍5项满足基本需求的流程设计。
(1)领域和语料的选择
研讨平台是一个很广泛的概念,具体领域包括网络论坛、博客、微博、聊天室、即时聊天工具、群决策支持系统等。各种不同的平台有各自的特点和相应的信息组织模式。
(2)基础言语行为分类体系的选择
为了保证构建的言语行为分类体系的辨别能力和泛化能力,构建新的言语行为分类体系时一般要以前人提出的言语行为分类体系为基础。
(3)语料试标注
在语料试标注阶段,标注者首先阅读语料,然后根据自己的理解对语料进行试标注。试标注的时候,遇到前面已有类别无法解释的新发言时,标注者可以提出新的类别来让该发言有类可依。在试标注的过程中,标注者还可以尝试更改前面的标注。
(4)类别合并和拆分
由于在试标注过程中对无法归类的新发言一般采用随遇随标的方法,因此会产生很多新类别。这些类别在产生的时候没有经过仔细考虑,而且一般数量庞大,因此很多类别需要合并。另外,那些实例数特别少的类别(如少于1%)要考虑和其他类别合并。对于一些实例数特别多的类(如超过50%),要考虑进一步拆分成两个或两个以上的类别。
(5)评估者间信度测试
为了说明一个言语行为分类是有效的,需要保证这个分类是客观存在并且可重复操作的,其中一个方法就是测量评估者间信度。评估者间信度给出了一个测量不同主观判断之间的同质性或一致性的值。当不同的评估者之间没有足够的一致性,要么是因为指标设计有缺陷,要么是因为评估者没有很好地理解这个指标。
有很多统计指标可以用来确定评估者间信度,不同的统计指标适合不同类型的数据和指标。常见的指标有联合概率(Joint-Probability of Agreement)[ 17]、科恩Kappa(Cohen’s Kappa)[ 18]、弗雷斯Kappa(Fleiss’ Kappa)[ 19]、评估者间相关性(Inter-Rater Correlation)、 一致性相关系数(Concordance Correlation Coefficient)[ 20]和组内相关系数(Intra-Class Correlation Coefficient)[ 21]等。本研究采用科恩Kappa指标来测量评估者间信度。假设两个评估者把N个东西分到C个互斥类,科恩Kappa就是测量两个评估者间的一致程度[ 18]。一般认为Kappa值大于0.75时一致性较好;Kappa介于0.4和0.75之间时一致性一般;Kappa小于0.4时一致性较差。
需要说明的是,以上步骤(3)-(5)是一个迭代的过程,往往需要经过多次反复才能收敛到一个较为稳定的分类体系。
可测试的假设是用来测试元设计是否满足元需求[ 15]。在本研究中,关心的是设计的言语行为分类是否具有足够高的判别能力和通用能力。其中判别能力可以用评估者间信度来测量,泛化能力可以通过在将来的研究中从本领域向其他领域转移时言语行为类别的重用率来测量。
本案例所使用的语料数据来自PedaBot[ 22]在线研讨系统,在这个研讨系统内学生可以讨论与课堂内容相关的技术问题。PedaBot系统是phpBB系统的一个变种,用户登入PedaBot系统后,可以像一般的论坛一样发表帖子。帖子按照回复关系组织成Thread。用户在发言的时候有两种选择:创建一个新的主题或者回复一个已经存在的帖子。这样,在一个主题内,用户发布的帖子就以树状的形式组织起来,除了根节点以外,其余每个帖子都有唯一的父节点。
PedaBot是一个使用英语的研讨平台,美国南加州大学的Viterbi工程学院从2004年开始使用PedaBot系统配合本科生和研究生的操作系统课程教学,鼓励学生在课后加入PedaBot系统讨论与课程相关的问题,并将学生在PedaBot系统中的表现作为考核学生成绩的一部分。从使用情况上看,PedaBot主要是一个用于教学辅导的系统,学生提出自己不懂的问题或在作业中遇到的困难,其他同学和老师一起来讨论并解决这些问题。本研究一共收集了2个学期的研讨记录,包括291个Threads和1 135条发言,参与研讨的学生为168人。
本文选择技术类网络论坛作为PedaBot语料的基础言语行为分类体系。Kim等[ 23]发展的针对技术论坛的言语行为分类体系。这个类别包括2个大的分类(Question,Answer)和3个单独类(Resolution, Reproduction and Other)。Question进一步又包含4个子类(Question, Add, Confirmation, Correction),而Answer进一步包含5个子类(Answer, Add, Confirmation, Correction,Objection)。
除此之外,Joty等[ 24]也发展了一套描述网络论坛的言语行为分类体系,包括12个类别,如表3所示:
| 表3 Joty等的网络论坛中的言语行为分类体系[ 24] |
本文将以这些网络论坛领域的言语行为分类体系作为E-learning领域言语行为分类体系的基础。
本研究发展了一套类XML的语法来进行语料标注。使用类XML语法的好处是数据类型的数据值可以自说明,方便将来计算机自动化处理。下面以一个Thread的帖子为例说明标注方法。
16341 := [QCONF]
16347 -> 16341 := [NO_A]
16409 -> 16341 := [QCONF]
16412 -> 16409 := [NO_A]
Subject: question about the exams
Body: Hi,
thanks
Subject: Re: question about the exams
Body:
Subject: Re: question about the exams
Body:
Subject: Re: question about the exams
Body:
标注者首先识别出每一个帖子的言语行为关系,并且在RELATION_TILESET中标出。例如,16347->16341:= [NO_A]表示POST_ID为16347的帖子回复了POST_ID为16341的帖子,并且POST_ID为16347的帖子对POST_ID为16341的帖子有一个NO_A的言语行为关系。又如16341 := [QCONF]表示POST_ID为16341的帖子有一个QCONF的言语行为类别,但是没有“->”的记号以及被回复帖子的POST_ID,说明这是主题里的第一个帖子。
根据Samuel等[ 25]的研究,特征短语(Specific Cue)在识别言语行为类别时是至关重要的。为了在将来服务于自动化分类算法,本研究中不仅让标注者指出一个帖子属于哪种言语行为类别,还让标注者努力用类XML的语法来标记特征短语。例如,在POST_ID为16341的帖子中,
在进行正式工作之前,语料中涉及到系统问题的帖子(如报告磁盘空间配额不够)和幽默类的帖子被全部被删除,因为它们和教学无关。笔者聘请了1位博士生、3位硕士生和1位本科生作为专家,在熟读语料之后,各自提出了一套分类体系。经过若干次充分的小组讨论之后,专家提出了一个初始的言语行为分类体系,包含4大类、22小类,如图1所示:
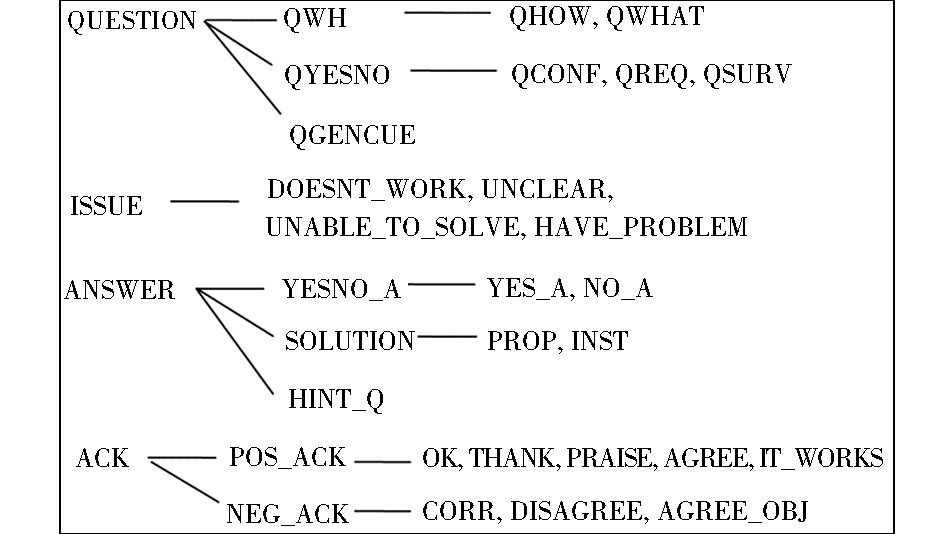 | 图1 初始的言语行为分类体系 |
其中,QUESTION表示以任何形式提出问题,ANSWER表示以任何形式回答所提问题,ACK表示对提供的答案进行评价,ISSUE用来描述遇到的一个难题。
专家通过讨论确定了图1所示22个类别的定义和判定要点。从某学期的研讨记录中随机挑选了100个Thread让4名标注者独立完成标注。标注完成后计算各类别的Kappa值,并统计各类别样本出现的次数。一批Kappa值不够高的类别(如Q_GENCUE, CORR,DOESN’T_WORK, UNABLE_TO_SOLVE等)考虑删除。同时,一批样本数量不够多的类别考虑与其他类别合并,如QREQ与QCONF合并。在这里没有发现需要拆分的类别。另外,ACK被拆分为POS_ACK和NEG_ACK,分别对应正向态度和反向态度。经过数轮的调整,最终给出的言语行为分类体系,包括5大类18小类,如表4所示:
| 表4 最终的言语行为分类及各类别描述 |
每一个大类代表一个高层言语行为类别,每一个小类代表一个低层言语行为类别。这样高层言语行为类别和低层言语行为类别构成具有层次关系的树状结构,其中一个高层类别包含若干个低层类别言语行为分类的层次关系树体现了言语行为分类之间的逻辑层次关系,可以为言语行为分类提供一定的帮助。在底层言语行为的分类效果无法满意的时候,如果高层言语行为的分类效果令人满意,仍然可以用高层言语行为分类的结果,虽然会在一些细节上损失一些信息。同时,某些机器学习算法依赖前一个发言的言语行为类别作为特征来训练分类器,这时也可以选择对应的高层言语行为类别来避免规则过分依赖某一具体低层言语行为类别的问题。
基于表4所提的言语行为分类体系,本研究聘请了1位博士生、2位硕士生和1位本科生各自独立地对随机选择的另外100个Thread共432个帖子进行标注,然后计算两两评估结果之间的科恩Kappa值。这4位标注者中有两位的母语是英语,一位的母语是朝鲜语,另一个的母语是汉语。低层言语行为类别的评估者间Kappa值如表5所示:
| 表5 低层言语行为类别的评估者间信度(Kappa值) |
从表5可以看到,所有低层言语行为类别的Kappa值除PROP外都超过了0.7,并且PROP的Kappa值也接近0.7,因此可以认为低层类别是定义良好的。其中QWHAT、QHOW、QSURV、UNCLEAR、YES_A、HINT_Q、OK、THANK和IT_WORKS的Kappa值超过了0.9;QCONF、NO_A、PRAISE、AGREE_OBJ、DISAGREE的Kappa值超过了0.8;HAVE_PROBLEM、AGREE的Kappa值超过了0.7。Kappa值在一定程度上反映了一个言语行为类别分类的难易程度。
高层言语行为类别的评估者间Kappa值如表6所示:
| 表6 高层言语行为类别的评估者间信度(Kappa值) |
从表6可以看出,所有高层言语行为类别的Kappa值都超过了0.7,因此可以认为高层类别是定义良好的。除ANSWER外,其他高层言语行为类别的Kappa值都超过了0.85,即认为取得了较高的一致性。
本文言语行为分类体系虽然是在E-learning的语料环境下提出的,但是很容易被移植到其他所有具备问答特性的在线研讨环境中。由于该言语行为分类体系体现了提问、回答和评价所必须的所有言语行为类别,因此从理论上说一个以在线问答讨论为目的的研讨平台都应该大致适用于这套言语行为分类体系。兼容的典型目标平台包括各类技术论坛(如JavaEye,CSDN)、邮件列表、各类讨论技术问题的聊天室和群(如QQ群)等。有理由相信,当本言语行为分类体系移植到其他问答研讨类平台时,只需要处理与该平台相关的特殊言语行为类型(如即时聊天平台中的招呼类言语行为),而与提问、回答和评价相关的言语类别只需要花很少的力气就可以顺利移植。
本研究根据Wall的模型研究提出了面向在线群体研讨的言语行为分类体系设计框架。在这一研究中提出了构建言语行为分类体系的两大需求:判别能力和泛化能力。同时,以流程为人造物的观点,研究设计出一个包含5个关键步骤的迭代流程来满足设计需求。本文对于填补面向在线研讨言语行为分类体系构造方法论的空白,具有重要的理论意义。同时,以所提的框架体系为指导,提出了一个适合E-learning环境的言语行为分类体系。不仅验证了所提方法论的有效性,同时还为其他以问答讨论为目的的在线研讨平台开发言语行为分类系统提供了重要参考依据。
言语行为分析是大规模自动化处理言语文本的第一步,而言语行为分类体系在言语行为分析研究中又处于基础地位。对于目前国内言语行为分析研究的现状而言,缺乏一个有足够辨别能力和泛化能力的分类体系常常是研究面临的一个瓶颈。由于缺乏分类体系这一基础数据,很多自动化分析方法不能应用,这严重限制了言语行为自动分析这一研究方向的发展。从这个意义上说,本文对于促进国内研讨文本的言语行为自动化分析研究做了一点有益的尝试。
未来,笔者将以所提的框架体系为指导,研究即时通信领域和群决策支持系统领域的言语行为分类体系,从而进一步拓展该框架的应用领域。
(致谢:感谢美国南加州大学信息科学研究所高级教育技术研究中心的Jihie Kim博士为本研究提供的语料和相应支持。)
Acknowledge and appreciate
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|