{kind=link}
个性化推荐系统中用户多态聚类研究
[刘剑涛 ]
]
]
|
|


针对传统协同过滤算法依赖单一用户需求形态影响推荐效果的问题,提出一种基于用户多态聚类的数字图书馆个性化推荐方法。该方法以改进的海明距离计算候选邻居集,结合多态相似度进行二次聚类,预测用户的多态需求度并形成推荐。实验表明,使用多态聚类产生的推荐精确度上优于单一聚类产生的推荐。
Traditional collaborative filtering algorithm is usually dependent on single kind of user requirement to generate clustering and this may affect the accuracy of recommendation. In view of the problem, this paper proposes a personalized recommendation method in digital library based on users’ polymorphic clustering. This method uses an improved Hamming distance to calculate candidate neighbors, then combines polymorphic similarity to cluster again, finally forecasts user’s requirements degree and generates recommendation. The experiments show that recommendation based on polymorphic clustering is more accurate than the single’s.
随着数字图书馆规模的不断扩大,“信息过载”和“资源迷向”[ 1]问题给用户准确、快捷地获取所需信息造成极大困扰。个性化信息服务通过分析用户行为与需求,为用户进行智能推荐,实现 “信息找人”的主动服务,逐步成为数字图书馆发展的趋势[ 2]。
基于用户协同过滤的推荐是目前应用较为成功的技术[ 3],它以分析用户信息需求的表现为基础,对用户群中的相似用户进行聚类,并综合这些相似用户对相关文献的评价形成系统对指定用户的偏好预测。传统的协同过滤方法计算用户相似度主要依赖用户对文献的评分,其他还有依赖图书借阅记录以及访问(点击)次数等。Bobadilla等[ 4]在计算评分相似度的基础上进一步利用权值区分用户高评分和低评分所表达的需求差异,武建伟等[ 5]在分析图书借期的长短上提出基于密度的聚类算法,宋擒豹等[ 6]以统计网络文献的访问次数寻找相似的用户群。这些研究的方向主要是从需求表现的深度上对数据稀疏和维度灾难[ 7]问题做了优化处理,但是单一的需求表现还不足以完全表示用户的真实需求,如借期长的书可能是用户忘记归还,评分低的图书可能是用户一时情绪波动,点击次数高的文献可能是得到诱导等,用户原始需求的不准确表示将直接影响到最终的推荐效果。
多态性一般是指生物体在一定时间和空间上存在形态多样性和状态多样性的简称。用户在利用数字图书馆时所表现出的信息需求同样具有多态性特征,多样性的形态可以定义为用户对文献资料的点击、下载、借阅、收藏、共享、评分、评价等,多样性的状态表现出用户对文献不同的偏好程度。为了从广度上挖掘深层次的用户需求,本文提出一种兼顾多种用户形态特征及其相关度的多态相似度,并结合以改进海明距离为基础的聚类算法,实验结果表明新方法能有效提高推荐质量。
由于传统协同过滤算法是依赖单一的用户需求形态,利用多态性来提高推荐效果的相关研究大多采取混合协同过滤的方法。较早出现的是结合人口统计(Demographic)和心理统计(Psychographics)的协同过滤[ 8],用户在注册时往往被要求登记年龄、性别、职业以及兴趣类别等信息,系统在协同过滤之前可以有效缩小聚类的范围,是一种解决数据冷启动和数据稀疏的有效方法。类似的还有混合内容的协同过滤[ 9],通过分析图书流通书目或查询关键词内容的相似度来识别用户兴趣分类,再基于用户评分产生聚类。此外,也有挖掘用户隐性需求的例子,Kim等[ 10]收集购物商城中访问时间、收藏等隐性需求构建基于决策树的推荐方法,Trujillo等[ 11]在已实现的数字图书馆推荐系统中,结合人口统计、心理统计和电子文献下载次数三种形态构建用户兴趣模型,并以用户兴趣度来计算相似度。但后两者都没有涉及用户主动性的评分。
综上所述,多态性的推荐方法所集成的用户形态数量有限,不仅不能很好地兼顾用户显性需求和隐性需求的同时表达,而且也无法体现不同形态所反应出的需求强度。本文提出的方法可以依据实际应用环境自由组合,并重点突出用户需求表现强烈的用户形态,同时在传统协同过滤上的适当改进,并不影响与基于内容或人口统计等其他算法的混合。
基于用户协同过滤的推荐流程由构建用户-项目关联矩阵、搜寻最邻近用户集合、根据规则产生推荐三部分组成。其中比较用户相似度并产生最邻近用户集(聚类)是推荐系统的核心,直接影响到推荐的准确性。比较常用的相似度计算有基于距离的方法,如欧式距离、海明距离,以及余弦、修正余弦相似性函数和Pearson相关系数等。为了从信息行为的广度上挖掘用户潜在的需求,需要对用户多态的需求度进行定量比较。
多态的用户需求可以用一个集合Form表示,Form={点击,查看,借阅,收藏,共享,评分,评价,…}。真正相似的用户应该在各个表现形态下尽可能的相似。徐茜等[ 12]在本体映射的概念相似度计算中提出一种基于概念定义、概念实例、概念结构三个方面的综合相似度计算方法,参照本体概念相似度组合形式,本文将其引入到用户相似度的计算中,并能满足用户需求集合Form中的形态自由灵活地组合构成多态相似度的要求。基于以上分析,任意两个用户X,Y之间的用户多态相似度可以定义为:
PSim(X,Y)= 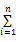
其中,Weighti表示第i个形态的权重,并且满足 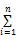
基于协同过滤的推荐效果之所以不如基于内容的推荐,主要原因在于要求用户对所有阅读过的文献都做出主动评分并不现实[ 13],但是在数字图书馆的实际应用环境下,用户在借阅、收藏或者评价之前都会事先点击浏览,因此点击次数是需求表现的基本形态,以此构建向量矩阵可以尽量减少数据稀疏的问题。李彬等[ 14]在文献[6]的基础上优化了以点击计算海明距离的聚类算法,本文参考文献[6]和文献[14]的聚类流程,结合多态思想对该算法做出进一步改进。推荐方法分为三步:计算相对点击和评分差的海明距离得到每个用户的候选邻居集;结合多态相似度对邻居集二次聚类;由最邻近用户预测当前用户的需求度,选择前N条生成推荐列表。
文献[6]和文献[14]中候选邻居计算首先以点击次数构建URL-User关联矩阵Mm×n,然后对于∀M[i,j]>0,令M[i,j]=1,再计算用户向量间的海明距离Hd(X,Y)= 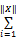
(1)改进1:相对点击次数的度量
定义相对点击h(xi,yi)=xi/(xi+yi),其中xi,yi分别表示用户X和Y对文献i的点击次数。显然,当h的值等于1或0时,X和Y在文献i的点击相似度上最小;当h=0.5时,表明X和Y的点击次数完全相同。则改进的海明距离可以表示为:
Hd(X,Y)= 
(2)改进2:引入评分差加权的概念
不同评价分值差异反映了用户对文献的主观需求度,对评分差异较大的文献加权可以在相对点击相同时凸显相似距离。式(3)对评分值大于3的单点距离h'=|h(xi,yi)-0.5|做了2倍加权处理,score∈[1,5]。
h'=

(3)候选邻居的聚类过程
经过重新定义的海明距离保持了距离越小相似度越高的特征,因此候选邻居的聚类与原方法[ 6]基本一致,主要是增加了依赖评分的加权步骤。过程如下:
①输入用户对每个文献的点击次数和评价分值。以点击次数构造一个由m个用户和n种文献构成的向量矩阵Hm×n=(hitsij)m×n,其中元素hitsij记录了用户i对文献j的访问次数,没有点击过的文献记为0。同理建立评分矩阵Sm×n。
②由公式(2)计算矩阵Hm×n两两用户的改进海明距离,当双方的点击都是0时,令h(xi,yi)=0.5。由此建立行向量间的对称矩阵 
③根据Sm×n按公式(3)对 
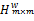
④以矩阵 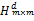
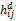
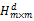
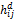 ≤Λ,将第i个用户和所有满足这个条件的第j个用户聚为一簇,否则i自己作为一簇,最终得到由m个簇构成的候选邻居集,记为N={c1,c2,...cm}。
≤Λ,将第i个用户和所有满足这个条件的第j个用户聚为一簇,否则i自己作为一簇,最终得到由m个簇构成的候选邻居集,记为N={c1,c2,...cm}。
上述步骤快速得到的是较为粗糙的聚类,存在两个问题:虽然考虑点击,但忽视了评分细节以及其他形态上的差异;每个用户都对应产生一个簇,存在大量冗余邻居。文献[6]和文献[14]是通过比较文献的点击率来确认用户与候选邻居的所属程度,但大量文献背景下用户的点击可能很不平衡,较易引出误差。参考文献[14]中类不一致度的定义,结合多态相似度重新定义簇的质量,对候选邻居集进一步修剪。
(1)簇的质量
qualityc= 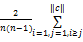
其中, PSim(i,j)表示两个用户之间的多态相似度, 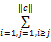
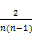
| 表1 用户形态的数据类型和参考相似度 |
例如是否借阅体现的是用户在维度上的绝对差异,采用公式(5)的距离公式,而评分更多的是从程度上区分差异,公式(6)余弦相似度更为适用。显然,以这种方式构成的簇的质量越大,候选邻居的相似性就越大,聚类就越准确。
Simborrow(X,Y)=1-( 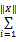
Simpoint(X,Y)=( 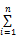
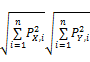
(2)二次聚类过程
二次聚类参照文献[14],重新定义了一种具备多态性特征的簇的质量。由于对部分相似函数做了变换,簇的质量越大表示相似性越强,聚类过程中相关质量大小比较相应做了调整。
①根据公式(4)计算所有候选邻居集N内每个邻居集ci的质量 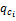
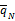
②对任意ci⊂cj,若 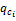
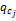
③对所有ci∈ N(1),若 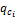
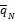
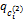
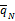
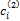
④对N(2)可依据聚类的精度要求重复以上过程,直至得到满意的聚类结果。
得到最近邻居集后可以利用邻居的多态信息行为来预测当前用户对每个文献的需求度,并选择需求度最高的N条文献推荐给用户,即产生Top-N推荐。常用的预测方法是Sarwar等提出的启发函数[ 15]。
Pu,i= 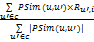
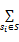
公式(7)对该启发函数做了扩展,其中PSim(u,u')是当前用户和邻居集内其他用户的多态相似度;Ru',i表示用户u'对文献i的多态需求度,其定义类似于多态相似度的定义,由各形态的分量及其权重组成。
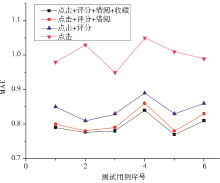
为了验证本文推荐方法的有效性,本文藉点击、评分、借阅和收藏4种形态来实现多态聚类并形成推荐,并与单纯基于点击海明距离的聚类[ 6]作对比。实验数据来自某高校MyLibrary系统数据库,抽取的数据包括5 000种热门借阅的图书,以及400名活跃度较高的学生,记录了近年来用户的点击次数、评价分值、借阅历史和收藏历史这4种信息行为,选择热门图书和活跃用户可以尽量避免数据稀疏对实验结果带来的影响。在用户各形态的相似度度量上,评价分值和点击次数分别选用余弦相似度和改进的海明距离,而借阅和收藏与否则用传统海明距离。同时,多态相似度的计算采取逐个组合的方法,分别是{点击,评分}、{点击,评分,借阅},{点击,评分,借阅、收藏}。
实验中数据的80%作为训练集,20%作为测试集,推荐性能的度量采用平均绝对差MAE=( 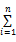
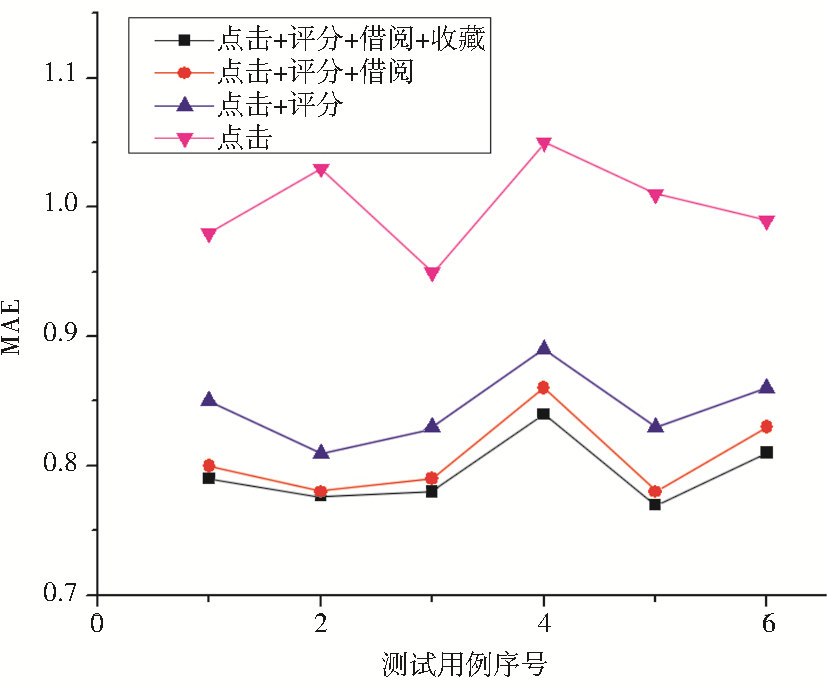 | 图1 推荐方法的MAE比较 |
从图1可以看出,单纯基于点击行为产生的推荐误差最大,而以点击和评分组合的二态聚类产生的推荐在精度有了大幅度提高,说明引入改进海明距离和多态相似度是有效的。当分别叠加是否借阅和收藏后,精度提高的幅度有所减少,原因包括:二次聚类是相似度更细粒度的比较,差别越来越不明显;使用收藏功能的用户相对较少,且在多态相似度中分配的权值较小。
在数字图书馆的应用平台下,特别是以集成统一检索平台为代表的MyLibrary系统,收集了大量用户显性或隐性的需求,但却没有得到充分的挖掘。本文在传统协同过滤方法的基础上,提出多态相似度的概念,对用户在多种需求表现形态上的相似度进行综合度量,并以此生成聚类和推荐,从底层更为直接地表现了用户的需求。同时,该方法在实现时可依应用环境选取相似度和权值,具有较强的灵活性和扩展性。但是,以点击次数为主的聚类过程并没有从根本上解决冷启动和数据稀疏的问题,可以考虑混合其他推荐方法加以改善。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|