
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于FCA和关联规则的情报学本体构建
[刘萍 , 胡月红]
, 胡月红]
, 胡月红]
|
|


提出一种新的领域本体学习方法,结合形式概念分析(FCA)与关联规则挖掘从非结构化文本中获取情报学本体。该方法从文本集中通过种子-扩展机制的方法获取领域核心概念,构建文档概念格(文档×关键词矩阵),在此基础上通过形式概念分析方法来识别概念之间的等级关系,通过关联规则挖掘概念间的相关关系。最后,采用基于“黄金标准”的方法对本体学习的结果进行评价,结果表明:通过这种方法构建的本体可以达到较高的领域知识覆盖率,而且能够识别概念之间部分隐含的关系,从而验证该方法在领域本体的构建中实用且有效。
This paper presents a new approach to Ontology learning in the domain of information science. A combination of Formal Concept Analysis (FCA) and association rules is used to facilitate Ontology construction from unstructured text. This approach acquires key concepts from documents by using a seeding and expansion mechanism; formulates (key concept by document) context for concept lattice construction, and bootstraps the learning of domain-specific concept hierarchies using FCA; extracts the relationships between the concepts via association rules. To evaluate the quality of the learned Ontology, a comparison with “Golden Standard” is undertaken, and the evaluation results illustrate that it can reach high domain coverage and identify some implicit relations between concepts. It is concluded that the proposed method is practical and useful to support the process of building domain Ontology.
本体形式化地定义了领域内共同认可的知识,是语义网体系的核心。构建领域本体成为各种应用得以实现的前提,但是目前还没有成熟、统一的方法论指导本体的构建工作。传统的领域本体构建方式主要依赖专家手工构建,效率较低且更新慢,为此,国内外许多研究团体正积极探索支持本体(半)自动构建的学习方法。由于不同的领域特点各异,构建本体时所面临的挑战也不相同。以情报学领域为例,作为一门新兴的交叉学科,至今仍在发展完善中,学科边界没有清晰的界定;另外,情报学的研究对象非常庞杂,领域概念以抽象名词为主,很多核心概念并没有严格而统一的定义,影响了人们对该领域知识的理解[ 1]。已有的情报学叙词表在对领域知识进行组织和描述时,缺乏全面性、更新困难、语义不丰富,难以满足人们的需求。
本文以情报学领域文献集合为基础,采用基于种子-扩展机制的方法获取领域概念,以“文档-特征词”矩阵作为领域形式背景,通过形式概念分析和关联规则的方法挖掘概念之间的关系,实现了情报学领域本体的半自动构建。通过与“黄金标准”的对比分析,可以得出,从文献集合中学习的本体达到了较高的领域知识覆盖率,并且能够识别概念之间部分隐含的关系。
在哲学中,概念被理解为由外延和内涵两个部分所组成的思想单元。基于对概念的这种哲学理解,Wille[ 2] 于1982年首先提出了形式概念分析(Formal Concept Analysis, FCA)理论,用于概念的发现、排序和显示。
形式概念分析通过典型的代数结构——概念格,将概念深化为概念、概念的内涵、概念的外延及概念层次关系。概念的外延被理解为属于这个概念的所有对象的集合,内涵被理解为所有这些对象的公共属性集合,所有的概念连同定义在其上的层次关系共同构成了概念格[ 3]。概念格作为形式概念分析中核心的数据结构,从外延和内涵两方面对概念进行符号形式化描述, 概念格的Hasse图则可以完成概念及其层次结构的可视化工作。形式概念分析技术能够自动获取所隐含的概念以及概念之间的层次关系,强调用数学手段表达客观知识,弱化开发者对领域本体构建过程的主观影响[ 4],因此基于形式概念分析的领域本体构建受到越来越多的关注。目前具有代表性的方法主要有Cimiano方法[ 5]、GuTao方法[ 6]、Haav方法[ 7]、Obitko方法[ 8]等。
关联规则挖掘用于发现大量数据中项集之间有趣的关联,它揭示了数据项之间的位置依赖关系,通过规则的支持度和置信度进行兴趣度度量,反映所发现规则的有用性和确定性[ 9]。
在本体的构建中,关联规则挖掘常用于获取概念间的非分类关系。2000年,Maedche等[ 10]最先描述并评价了将关联规则应用于本体学习的方法。2001年,Maedche等[ 11]又提出使用已有的概念层次作为背景知识,然后利用关联规则来发现概念间的非分类关系的方法。实现关联规则挖掘的算法有Apriori算法、采样算法、频繁模式树算法和分区算法[ 9]等,其中Agrawal等于1994年提出的Apriori算法是最常用的算法[ 9]。
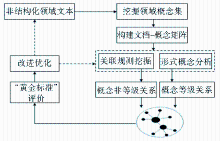
结合情报学领域特征,借鉴七步法[ 12]和骨架法[ 13]的思想,笔者设计出情报学本体学习的构建流程,如图1所示:
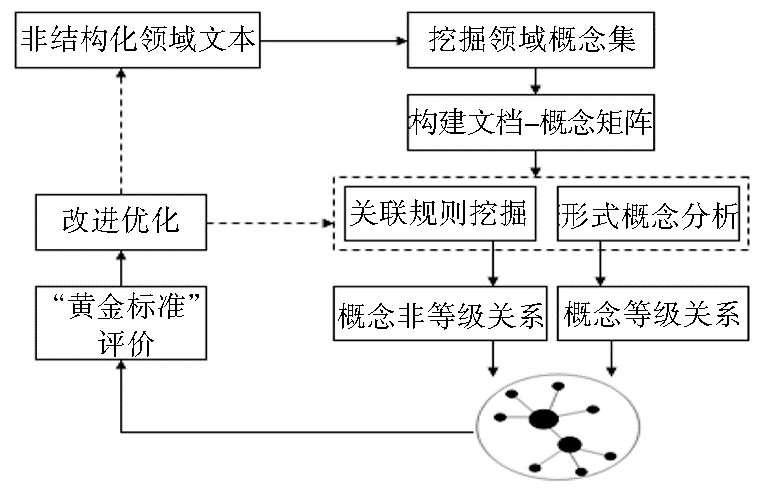 | 图1 领域本体构建流程 |
该流程包括6个步骤:
(1)分析本体构建目标,确定本体构建数据源;
(2)挖掘领域概念,构建领域概念集;
(3)构建文档-概念矩阵;
(4)通过形式概念分析挖掘概念间的等级关系,通过关联规则挖掘概念间的相关关系;
(5)采用基于“黄金标准”的方法对本体学习的结果进行评价;
(6)针对评价的结果和发现的问题进行相应的改进和优化。
构建领域本体的数据来源主要有结构化的词表和非结构化文本两类,本文重点考虑利用知识获取工具从非结构化文本中学习本体,学科领域现有的不同类型的数据库可以看作是领域的知识源。如CNKI中相应领域的期刊文献是该领域内有代表性的规范文本,是构建本体较理想的数据源。
在领域文本集的基础上进行领域概念集的挖掘。情报学领域本体的概念是指可揭示领域研究主题的关键词,所以首先要进行领域关键词的挖掘。常见的关键词挖掘方法有词库匹配法、基于N-gram的频率统计方法、中文分词和词频统计相结合的方法[ 14],已有的关键词挖掘方法大多需要对文本进行分词处理,复杂度较高。本文采用武汉大学语言信息研究中心的姬东鸿等提出的种子-扩展算法来抽取领域术语。该方法的最大优点在于利用统计方法进行抽取而不需对文本进行分词,同时省去了复杂的语言分析算法,抽取速度快且准确率较高。该方法包括种子定位和关键词确定两个阶段[ 15]。
虽然上述方法简洁有效,但是仍有可能漏掉少数可以作为领域概念的关键词,本文采用TF-IDF方法[ 16]从领域关键词集中筛选出一些权重较大、且在领域词表中出现的词作为对领域关键词集的补充。由于并非所有的关键词都能够揭示研究主题,因而需要进行人工筛选,去掉不合适的关键词,例如XML作为一种具体的信息技术,并不适合作为领域概念,所以应被删除。
在获取领域概念集的基础上,采用Obitko方法指导本体构建[ 8],具体方法是:统计每一个领域概念在每一篇领域文档中出现的次数,将文档-概念矩阵作为“对象-属性”的二元关系转换为形式背景,用形式背景来表达领域背景知识。通过造格过程,将形式背景转换成概念格,并用相关工具将概念格显化,可视化的概念格可以良好地展现出概念层次,体现概念间的分类关系。
概念间的相关关系识别是在文档-概念矩阵的基础上采用关联规则进行挖掘。基于关联规则的相关关系挖掘是一个两步过程:
(1)找出所有频繁项集:根据定义,这些项集出现的频繁性至少和预定义的最小支持计数一样;
(2)由频繁项集产生强关联规则,这些规则必须满足最小支持度和最小置信度。其中支持度即为两个概念同时出现的频次与总频次的比值,而置信度则为两个概念同时出现的频次与后一个概念出现的频次的比值,通过这种方法找出满足关联规则强关系的概念对,再通过人工识别概念间的语义关系。
虽然有学者提出通过抽取两个概念之间的动词来自动识别概念间的关系[ 17],但并非适用于所有领域,笔者通过实验发现几乎很难用这样的方法来挖掘情报学领域概念间的相关关系。
在获取本体后,需要对本体学习的结果进行评价。本文从以下两个角度进行:通过黄金标准的方法评价本体学习所获取概念的词典相似度;通过与已有的叙词表进行对比,衡量所挖掘的概念间等级关系是否合理。
最后,针对评价的结果和发现的问题对本体学习的过程进行相应的改进和优化,如扩充数据源或改进挖掘概念间关系的方法。对于本体的优化将是下一步的工作目标。
选取CNKI全文数据库的期刊文章,时间段为1989年到2010年,作者单位为武汉大学信息管理学院的2 989篇文章作为本体学习的数据源,抽取每篇文章的题名、关键词、摘要等内容生成领域文本集。
在领域文本集的基础上,采用基于种子-扩展机制的术语挖掘和专业词典补充相结合的方法,最终确定领域核心概念81个。本体学习的重要任务是识别概念间的关系,如等级关系和相关关系。
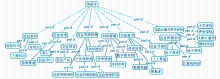
在情报学领域概念格的构建中,采用了简化的方法,由于这里的属性都是词汇,而本体所描述的重点元素也都是词汇概念,因此,可以用概念格中的属性来表示所形成的形式概念。形式背景则通过统计领域概念在领域文档中的分布情况,即文档-概念矩阵来构建。在此基础上,采用概念格生成工具Concept-Explorer[ 18]生成概念格,将概念格进行可视化,得到运行结果,如图2所示:
 | 图2 FCA运行结果图 |
将该层次结构中位于上层概念抽取出来作为情报学领域本体的一级概念。点击概念节点,找到与核心概念相连的其他特征词,通过节点的大小特征、节点间的位置关系以及连线关系判断特征词与该核心概念的关系,将其划分为该核心概念的子类或者相关类。
采用形式概念分析的方法能得到较为清晰的概念层。结合FCA的可视化结果,通过IHMC CmapTools[ 19]绘制情报学领域本体中概念间的等级关系,如图3所示:
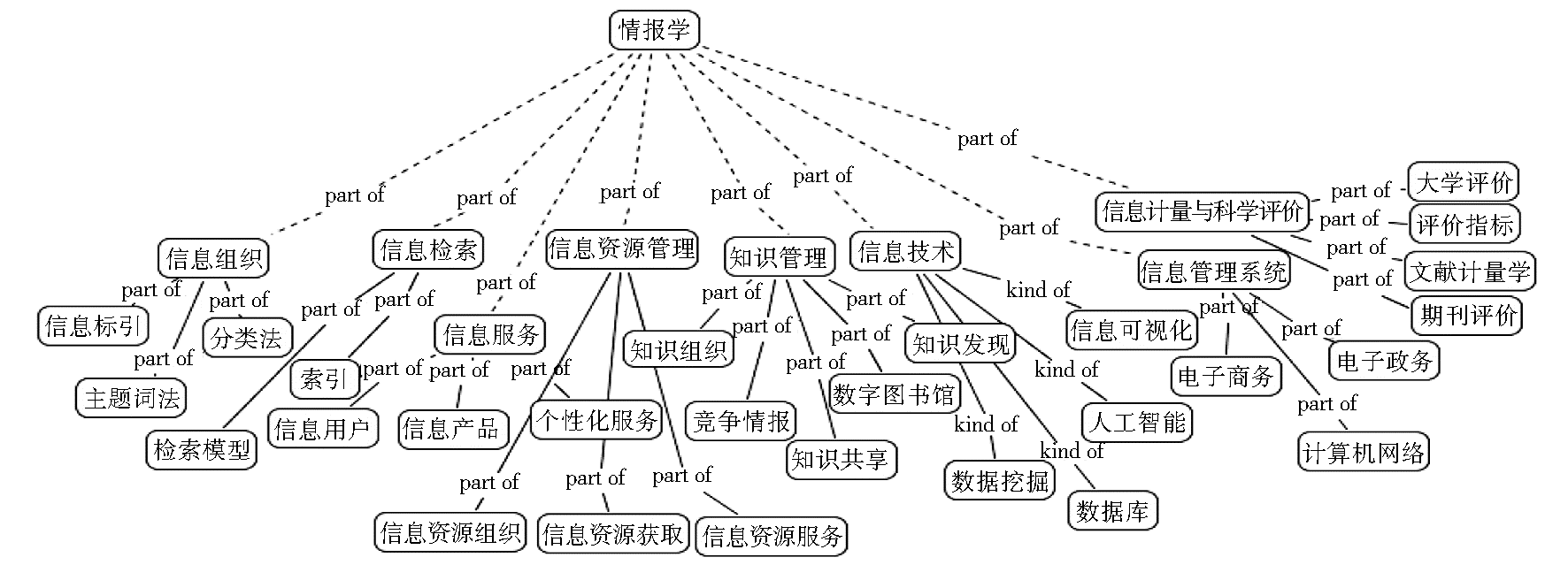 | 图3 情报学领域本体中概念间的等级关系(部分) |
通过实验发现FCA可视化的结果会受到输入的概念数量的影响。如果核心概念数量过多(>100个)时,可视化的界面将会非常复杂,不利于对层次关系的识别。在这种情况下可以先把概念分为2类或3类,再分别对各类中的概念进行层次关系识别。
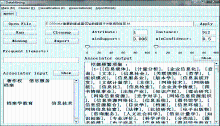
本文以一篇文章的摘要中所出现的领域概念作为一个事务,利用Apriori算法[ 9]发现候选频繁项目集,通过反复实验确定支持度与置信度的阈值,由频繁项集产生关联规则。支持度为两概念对同时出现的频次与总频次的比值,通过实验设定最小支持度为0.006,即在事务数据集中,两概念对同时出现的次数大于等于17次,而置信度则为两概念对同时出现的频次与后一个概念出现的频次的比值,实验中最小置信度为0.5。笔者用Java自制关联规则挖掘系统,输入事务数据库、最小支持度阈值、最小置信度阈值,输出D 中的频繁项集L,通过该系统挖掘的结果如图4(截图)所示。
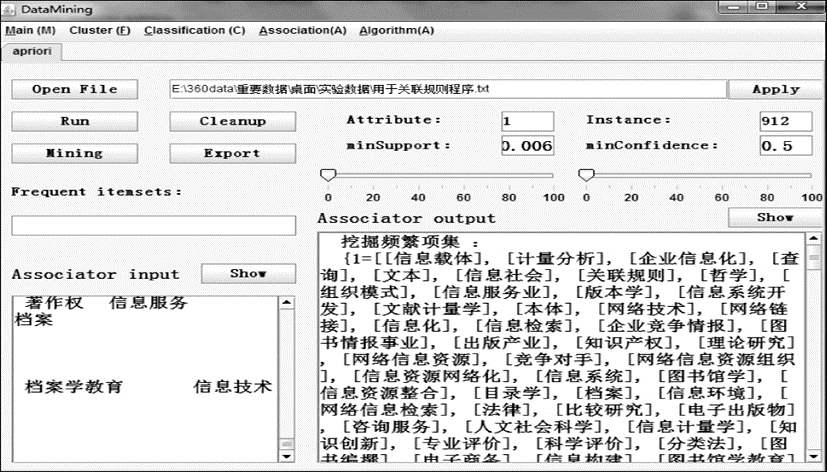 | 图4 关联规则挖掘系统界面 |
进一步整理出情报学领域本体中概念间的相关关系主要有:理论基础、研究对象、技术支持、应用、影响/效果、内容、媒介、环境支持(如表1所示),总计28个相关关系。将所挖掘出的核心概念间的相关关系添加到领域本体的框架体系中,完善情报学领域本体的构建。
| 表1 情报学领域本体中概念间的相关关系(部分) |
在获取本体后,需要对本体学习的结果进行评价。近年来,国内外研究人员开始关注领域本体的评价,并在词汇、分类等不同的层次上,从各自不同的角度提出了一些领域本体评价的方法。主要的本体评价策略可以分为4种。
(1)基于特定应用的本体评价策略,其基本思想是直接将构建的本体用于解决实际问题中去检验本体的质量,这种评价策略简单、直观,但本体应用的质量难于评估;
(2)基于“黄金标准”的本体评价策略。这种本体评价策略是将待测试本体与事先建立的“黄金标准本体”进行相似度计算,该方法适用于对本体学习的评价;
(3)基于数据驱动的本体评价策略,这种本体评价策略是通过测试本体在特定语料库中的主题覆盖程度来评价本体术语的完备程度;
(4)基于 PageRank的本体评价策略。考虑到本体间的链接关系(包括引入、扩展和继承关系),如果一个本体被其他本体参考的次数越多,该本体的质量就越高,这种评价策略主要应用于本体的排序,对用户进行本体推荐[ 20, 21]。
针对本体学习的效果,本文采用基于“黄金标准”的本体评价策略。黄金标准采用的是美国情报学家Bates组织情报学领域的研究人员共同编制的情报学百科全书(2010年发表)[ 22]。
词典相似度计算包括词重率(Lexical Overlap)、增词率(Ontology Improvement)、漏词率(Ontology Loss)三个方面。
设O1为自动生成的本体,O2为黄金标准,则词重率为O1和O2中交叉概念数目与黄金标准O2中所含概念数目的比值[ 23],如下所示:
LO(O1,O2)=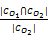 (1)
(1)
增词率为O1中所挖掘出的,但在O2中并不存在的新概念[ 23],如下所示:
OI(O1,O2)=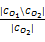 (2)
(2)
漏词率为O2中存在,但O1构建中漏掉的概念[ 23],如下所示:
OL(O1,O2)= (3)
(3)
设通过本体学习所得到的情报学本体为O1,作为黄金标准的情报学百科全书为O2,分别统计O1,O2中所包括的概念数目CO1,CO2,两者共有的概念数目C,仅存在于O1中的概念数目为CO1\ CO2,仅存在于O2中的概念数目为CO2\ CO1。按照式(1)-(3)分别计算,结果如表2所示:
| 表2 基于黄金标准的词典相似度评价 |
从表2可以看出,词重率LO为70.3%,这说明黄金标准中的大多数概念可以通过本体学习的方法获取。这些概念涉及信息计量、开放存取、信息政策与法规、信息检索、知识产权等方面。增词率OI为51.4%,表明有一些新的概念可以通过本体学习的方法获取,如信息技术、管理信息系统、知识管理等相关概念。
漏词率OL为29.7%,代表黄金标准中的超过1/4的概念并没有通过本体学习的方法获取,这些概念主要集中在信息技术中的社会关系(Social Relations in Information Technology)、法律和道德问题(Legal and Ethical Issues)、信息行为与查询(Information Behavior and Searching)等。
漏词的原因主要有三方面:
(1)本体学习实验中的数据源不够全面,漏词中所涉及的概念在所搜集的领域文档中出现较少甚至没有出现,这一点需要从数据源的扩大或改进方面做调整;
(2)翻译和表述的差异,有些概念在黄金标准中是通过一个短语进行概括的,但在中文中则需要通过几个词语来进行描述,反之亦然,例如“Information Searching and Search Models”就是“信息检索”和“检索模型”两个概念的综合表述;
(3)国内外在情报学领域的研究内容上存在差异性,比如在情报学百科全书的概念体系中更多地体现出对用户的关注,如信息行为与查询(Information Behavior and Searching)较多关注人在信息活动中的影响和作用,而国内在这方面研究还不是很成熟,所以文献中与之相关的概念较少。
除了与黄金标准进行对比评价外,笔者还将本体学习的结果与情报学叙词表(1994年版)进行对比评价。叙词表中共有领域术语1 154个,被分为6大类,23小类。情报学本体中70.4%的概念(57个)在情报学叙词表中出现,另有24个概念是叙词表中没有的,这24个概念涉及知识管理、信息技术、信息计量与科学评价等研究主题,这说明叙词表所包含的领域术语缺乏全面性。从一级概念对比来看(如表3所示),叙词表中术语的分类粒度较大,例如在叙词表的“其他”类目中是一系列与知识产权、专利保护、信息经济、信息产业与规划等概念相关的术语,这些术语是与概念“数字出版与开放存取”、“信息产业与规划”紧密相关的,而在本体中这些关联则清楚地展现出来。叙词表的二级类目基本上都能在本体概念中展现出来,除了极个别类目,如组织/人物(编号6200),没有包括进来。此外,叙词表中虽然有一些以用(Y)、代(D)来体现的术语相关关系,如工作体系Y服务体系、信息计量学D情报计量学,但表中涉及Y、D关系的术语仅占术语总数的7.1%,而且这些用、代关系大多停留在术语的同义词关系层面,实际上没有揭示概念间的相关关系。
| 表3 情报学本体与叙词表对比 |
本文针对情报学领域特点,提出一种基于形式概念分析(FCA)与关联规则挖掘的领域本体构建方法。从实验和评价结果来看,该方法能够获得较高的领域知识覆盖率,同时还能挖掘出隐含的概念间相关关系。
下一步的研究计划将从以下几方面开展:
(1)扩大领域文本集,当前的研究以武汉大学信息管理学院教师论文为数据源,数据的收集有一定的局限性,对本体学习会有影响。
(2)明确领域本体概念的定义,计划将CNKI学术词典中的术语释义和维基百科词条中对概念的解释进行整合,以补充对概念的解释。
(3)尝试自动识别概念间的相关关系,本文中基于关联规则的概念关系挖掘仅揭示了两个概念之间有关系,具体的关系类型还需要人工识别,如何利用自然语言处理和机器学习等方法实现概念间相关关系的自动识别是今后的研究方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|