
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于N-Gram的专业领域中文新词识别研究
[段宇锋 , 鞠菲]
, 鞠菲]
, 鞠菲]
|
|


以植物学作为专业领域的样本,对专业领域的新词自动化识别进行探索。研究选取《中国植物志》作为样本集,在ICTCLAS切词的基础上采用N-Gram统计的方法提取新词的候选项,然后分别按照词频(TF)、文档频率(D)和平均词频(TF/D)对新词候选项排序,取一定范围内的候选项作为识别出的新词。实验结果表明,词频TF筛选新词候选项的识别效果最好,F值为0.65。该方法能够自动产生专业领域的用户词典,具有较强的可移植性。
The paper researches automatic new word recognition in specialized field which is represented by phytology. A set of 200 documents on plant description randomly drawn from “Flora of China” is taken as sample set. At first, draw new words candidates are drawn by N-Gram method based on words split by ICTCLAS. Then all the new words candidates are sorted respectively by term frequency (TF), document frequency (D) and average term frequency (TF/D) and the candidates are selected among certain boundary as true new words. The experiments show that new words recognition according to TF is the best and F measurement is 0.65. This method can automatically produce user dictionary of specialized field and is highly portable.
汉语分词是中文信息处理的前提和基础。通用领域中新词对分词精度的影响超过了歧义切分[ 1],张德鑫[ 2]认为中文分词中超过60%的错误来源于新词;黄昌宁等[ 3]认为新词造成的分词精度失落至少比分词歧义大5倍以上。因此,提高新词识别性能,能够在很大程度上提高分词的准确度,推动中文信息自动化处理的发展。
已有研究通过中文构词的规律和统计学的规律能够识别出通用领域的词语,但是对于一些专业领域的词汇识别精准度不高,难以推进对于专业领域文字资料的自动化处理。基于这种考虑,本文将比较成熟的N-Gram算法应用到专业领域的中文新词识别中,在切词的基础上采用N-Gram统计方法提取新词候选项,然后分别按照词频(TF)、文档频率(D)和平均词频(TF/D)对新词候选项排序,取一定范围内的候选项作为识别出的新词。实验证明本文的应用取得了比较好的效果,能够在其他领域推广。
目前新词与未登录词都没有统一的定义,两者的涵义模糊,使用不一。譬如,张海军等[ 4]认为新词识别领域主要包括未登录词识别和新词识别两个方面,未登录词指未在当前所用词典中出现的词,新词是指随着时代的发展而出现或旧词新用的词。该定义将新词和未登录词并列。孙茂松[ 1]将未登录词分为两类:新涌现的通用词汇或专业术语等;专有名词即命名实体,比如中国人名、外国译名、地名、机构名等。该定义认为未登录词包括新词。鉴于两者概念相互交叉,本文不对未登录词识别和新词识别两个概念加以区分,统一采用新词识别的说法。
新词识别按照采用的技术主要分为基于规则的方法和基于统计的方法。
(1)基于规则的方法根据构词学原理,配合语义信息或者词性信息构造模板,匹配发现新词。郑家恒等[ 5]根据汉语构词法规则建立不同的规则库, 对加工后的文本候选串进行选取,确定新词语。Chen等[ 6]将把现代汉语平衡语料库作为训练样本,自动提取新词识别的规则。该方法在检测单字语素上有较高的准确率和召回率,取得了比专家设立规则更好的效果,但该文并没有给出确定新词边界的方法。吴涛等[ 7]设计了一种改进的统计后字符串最大匹配的中文分词算法。基于规则的方法准确率较高,但是需要人工编纂的规则和语言学研究基础,而且多与领域相关,可移植性比较差[ 8]。
(2)基于统计的方法是通过词条组成或特征信息进行统计,从而识别新词。常用的几种统计量或统计模型有:SVM[ 9]、t测试原理、N-Gram、Markov模型(HMM)、条件随机场模型、神经网络模型、最大熵模型等。譬如,秦浩伟等[ 10]通过语素生产率(MP)筛选新词。李钝等[ 11]利用单字之间的同现词频信息以及它们出现的时间规律确定候选新词字串,利用候选字串中各字符相邻、有序、频繁出现的特点,采用改进的关联规则挖掘算法进行新词的识别。韩艳等[ 12]通过左右邻信息获取二元候选登录词种子,进而在二元候选未登录词种子的基础上不断扩展,从而识别出不限长度的新词。丁建立等[ 13]在分析网络新词特点的基础上, 利用汉语词群现象和词位的概念提取出示范抗体, 在遗传算法进行过程中有针对性地注入该抗体。实验表明, 该方法对于分词碎片中符合词群现象的新词有极高的识别率, 对于一般网络新词的识别率也基本令人满意。基于统计的方法适应性强,可移植性好,方法灵活,然而对语料库的要求比较高,会产生垃圾串,而且难以处理“长词中含有短词”的情况[ 11]。
有研究将基于规则的方法和基于统计的方法相结合应用于新词识别研究。一般思路是先用基于统计的方法得到候选字符串,再利用基于规则的方法剔除垃圾串,符合规则的候选字符串作为识别出的新词。崔世起[ 14]通过训练集获得垃圾串词典、垃圾头词典、垃圾尾词典、词缀字词典以及独立词概率等参数,然后在基于词的串频统计的基础上,利用语言学知识对新词检测问题分类细化,针对不同模式的新词采取不同的垃圾串过滤算法,提高了新词识别的性能。
有些研究在分词的基础上进一步处理文本以提高识别精度。韩客松等[ 15]用空格替代文本中的标点符号和常用字,在非空格的字符串中,对共现率最大的字符串通过最大长度匹配识别新词。魏莎莎[ 16]剔除文本中的姓名后,对分词碎片进行词频统计,识别高频共现词,利用MP函数(Mutual Information函数和Partial Information函数线性叠加得到的新统计函数)筛选新词。此外,贺敏[ 17]和黄玉兰[ 18]也基于预先分词来提取重复串,然后使用语言学规则和统计特征来检测有意义串。
当前研究采用的语料大多是报纸或者网页,重在研究提高通用领域中新词的识别。与此相比,专业领域的词汇往往不太符合一般构词规律,将用于通用语料的识别方法用于专业领域效果往往不尽如人意。鉴于此,本文提出基于N-Gram的新词识别方法,用于探索专业领域的新词研究。
N-Gram算法具有语种无关、不需要语言学处理、对拼写错误的容错能力强、不需要词典和规则等优点。基于新词识别领域的研究现状,本文采用N-Gram作为基本算法。
N-Gram算法的基本思想是:
(1)将文本内容按字节流进行大小为N的滑动窗口操作,形成长度为N的字符串,每个字符串称为gram;
(2)对全部gram的出现频度进行统计,并按照事先设定的阈值进行过滤,抛弃垃圾字符串,得到新词。
基于N-Gram算法的新词识别方法根据是否分词分为基于字符和基于词两类。贺敏等[ 19]在基于字和基于字符的新词识别试验中证明基于词的N-Gram识别效率更高。张海军等[ 20]证明基于字符的N-Gram识别能够得到较高的召回率,而基于分词的字符串识别能够得到较高的准确率。随着样本数据容量的增大,两者的差别先是增大继而减少,当样本容量极为巨大时,差距很小,但是这种量几乎不可能达到。
因此本文采用了基于词的N-Gram算法识别新词。对样本使用ICTCLAS分词系统处理后,以词为单位进行大小为N的滑动窗口操作。
本研究以植物学作为专业领域的样本,选取《中国植物志》作为样本文本集来源。从中国植物志网络版(http://frps.plantphoto.cn/dzb_list2.asp)中随机抽取了200篇植物的物种描述文本,长度在300-600字之间,总样本字数超过70 000字。选取这样的样本集有两个原因:
(1)植物物种描述文本包含大量新词,其行文方式和构词方式与日常用语不同,能够有效地代表专业领域的特殊语境,很好地反映专业语境对于新词识别带来的影响。图1显示了中国科学院计算技术研究所研发的ICTCLAS分词系统对番茄枝科植物毛叶鹰爪花的描述文本分词的结果,“小枝”、“长圆形”、“长椭圆形”、“基部”等专业词汇都不能正确切分。
 | 图1 ICTCLAS切词结果 |
(2)《中国植物志》是目前世界上规模庞大、所含种类非常丰富的一部植物学巨著,全书80卷126分册5 000多万字。记载了我国301科3 408属31 142种植物的科学名称、形态特征、生态环境、地理分布、经济用途和物候期等[ 21]。这本书是中文植物描述最权威的著作,适合作为植物学领域文本的代表。
在ICTCLAS切词的基础上采用基于N-Gram统计的方法提取新词的候选词,通过不同的评价函数过滤垃圾串,识别新词,从而形成专业领域的用户词典,提高ICTCLAS在专业领域的切词精度。主要分为以下几个步骤:
(1)样本数据预处理:将从网上得到的PDF格式文档转变为TXT格式的纯文本文档,去除其中的英文字符,将部分英文标点更换为中文标点格式,得到纯中文文本,每个植物描述单独作为一个文档,这些文档形成实验集。
(2)制作标准集:对实验集中的文档手工分词,切分后的文档集合作为标准集。本研究以手工分词作为正确的分词结果,通过与标准集的对比判断新词识别算法的优劣。
(3)字符切分:使用ICTCLAS分词系统对样本进行初步切分,分出的词作为元字符(Gram),初步切分产生的样本集合为切词集合。
(4)识别候选词:按照标点符号,将文本切分成句;识别N-Gram,去掉标点,以切词得到的字符串整体作为单位即一个Gram,N取值2-4,分别识别2-Gram、3-Gram、4-Gram字符串;获得新词候选项,删除字符串长度超过6的N-Gram,其余作为新词候选项。以切词集合中的一句话为例,识别候选词的过程如图2所示:
 | 图2 识别候选词 |
(5)删除垃圾串:根据评价函数对新词候选词进行排序,对比观察几种评价函数对于词语排序的影响,按照一定的阈值筛选新词。根据已有研究,本文选取了三种常用的评价函数:词频、文档频率、平均词频[ 22]。上述指标的定义如下:
①词频(TF)指字符串在文本中出现的频率。字符串作为整体同时出现的次数越多,越有可能是独立的词语。
②文档频率(D)是指出现字符串的文档数目。D计算量小,有些字符串也许出现总次数不多,但是每篇文献都有提到,那么也可能是独立的词语。
③平均词频(TF/D)是指平均每篇文档中字符串出现的次数,该值越高,字符串越可能是新词。计算公式为TF/D= 字符串出现的频率/出现字符串的文档数目。
(6)统计准确率和召回率。准确率和召回率的统计方式各异[ 10, 16, 19],本研究采取了与文献[12]相同的统计方式,准确率(P)、召回率(R)、F值的定义如下:
准确率(P)= 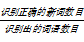
召回率(R)= 
F= 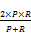
标准库中有4 019个词,其中有2 336个词是ICTCLAS切词系统没有识别出来的新词,占总词汇量的58.12%。
对新词候选项分别依据TF、D、TF/D排序,如表1所示。
由表1可知,评价函数对新词识别具有显著影响。ICTCLAS切词产生大量的单字,这些字重复出现,没有确切语义。分别根据TF、D和TF/D排序,排位前20的字符串长度大多大于1,这些字符串能够表达一定的语义,是新词的可能性较高。其中按照TF排序与按照D排序筛选出很多相同的字符串,但是按照TF/D排序前20的字符串与前两者排名前20的字符串大多不同,其中包含大量的地名。这可能是由于样本最后常常有一段文字描述植物的生长习性和标本采集地点,同一物种的植物生长的地点相近,表示这些地点的字符串仅仅在样本中属于同一物种的少数植物描述文本中反复出现,显现出TF值小但TF/D值较高的特点。
| 表1 前20位词语比较 |
为了确定最优的评价函数和阈值,本研究对新词候选项分别依据三种评价函数排序,删除取词范围外的字符串,统计P、R、F的值,评价识别效果。取词范围为排名处于[0,percent]内的字符串,percent为新词候选项总数的百分比。没有数据显示在专业领域文本中新词的比例为多少,但是根据已有研究,50万字的人民日报科技政治类的语料统计发现了新词5 849条[ 23],126 656万字的天涯论坛语料统计后发现新词6 176条[ 24],可以推断未登录词在通用领域文本中所占比例大约为0.4%,因此,将percent取值范围设定为0.2%至5%。
(1)选取评价函数
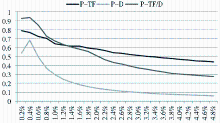
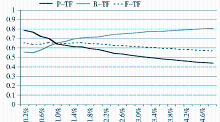
在取词范围比较小时,TF/D作为筛选的评价函数得到的新词识别准确率比较高,但是随着取词范围增大,准确率下降很快。虽然用TF作为评价函数,新词识别准确率会随着取词范围的扩大而降低,但是其降低的速度没有TF/D作为评价函数时下降得快。取词范围大于1.2%时,用TF作为筛选标准得到的准确率比其他两者的准确率高。用D作为取词标准得到的准确率较低,如图3所示:
 | 图3 三种筛选方法的准确率比较 |
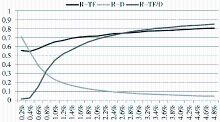
按照TF和按照TF/D作为取词标准,召回率随着取词范围的增加而上升;而依据D作为取词标准,召回率则随着取词范围的增加而下降。在取词范围小于2.4%时,依据TF取词的召回率较高;而大于2.4%的范围取词后,以TF/D作为筛选标准得到的召回率比较高,如图4所示:
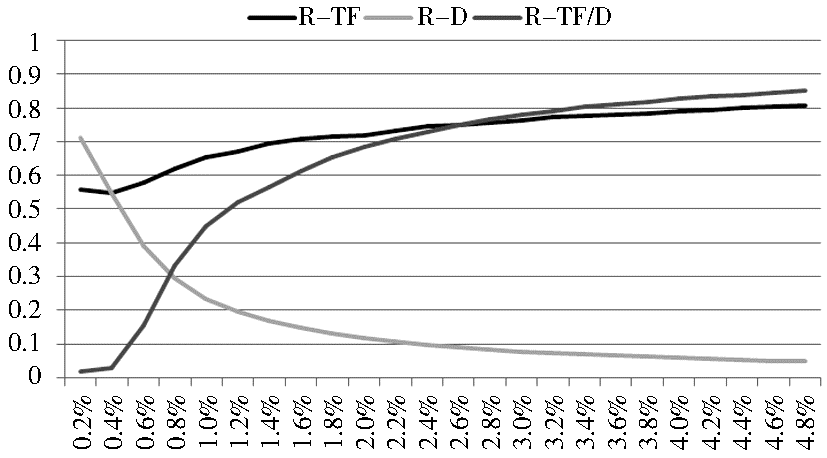 | 图4 三种筛选方法的召回率比较 |
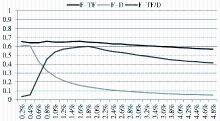
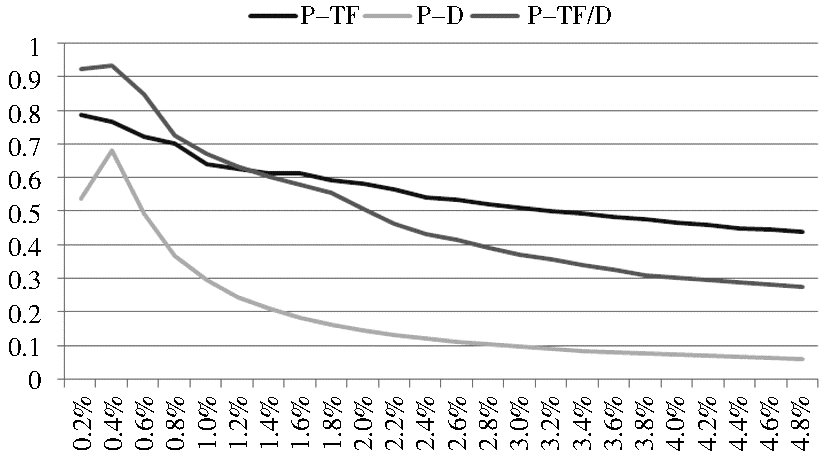
采用F值综合评价准确率和召回率,结果如图5所示:
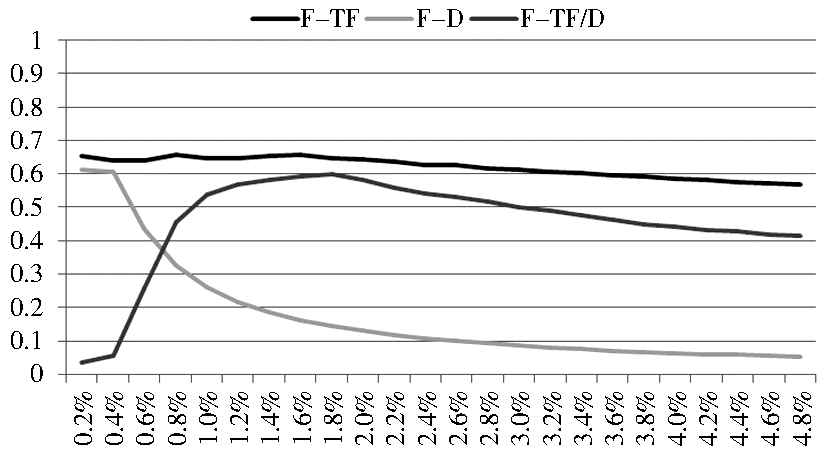 | 图5 三种筛选方法的F值比较 |
以TF作为评价函数的新词识别在所有实验中的F值均高于其他两者。综上,笔者认为TF是相对最为合适的评价函数。
(2)选取合适的阈值
随着取词范围的增大,以TF为评价函数,新词识别的准确率下降,召回率上升,F值总体呈现先上升后下降的趋势,但是总体变化不大。在取词范围为1.6%时,F值最大,能够在尽可能不影响准确率的基础上得到较高的召回率。此时词频的阈值为30,过滤识别新词416个,准确率为61.30%,召回率为70.67%,F值为0.65,如图6所示:
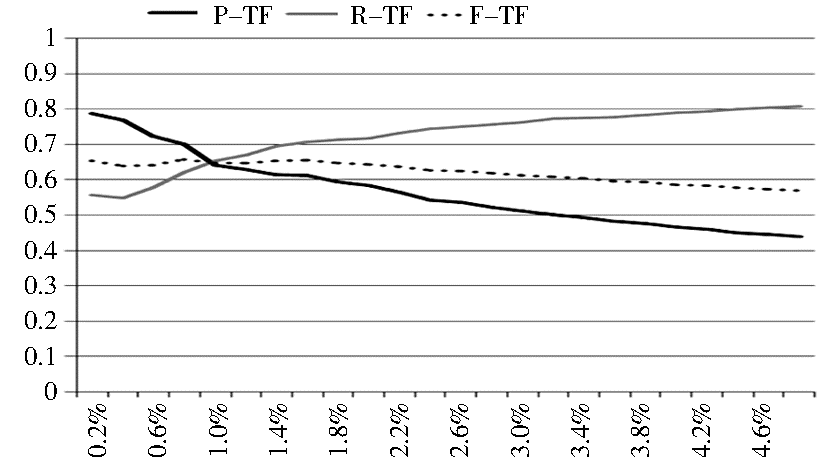 | 图6 按频率取词效果随取词范围的变化 |
国内也有其他基于N-Gram的新词识别研究。譬如,吕美香等[ 25]提出的新词识别方法分为两部分:切词和过滤。切词分为三个步骤:切分训练语料,形成预处理文档;通过与停用词典匹配生成分词碎片,采用N-Gram算法生成2-6元的多字词短语;对关键词候选集去重,并统计词频以及GF/GL权重值。过滤分为4个步骤:设定词频以及GF/GL权重阈值,对低频词进行过滤;通过比较GF/GL权重,进行子父串的比较,对大量冗余词进行过滤;通过与抽词词典匹配,对已收录的词语进行过滤;通过ICTCLAS切分总结成词规则,进一步实行规则过滤,提高新词准确性。其实验结果显示准确率为40%[ 25]。
汉语分词是中文信息处理的前提,但现有的方法常常不能够识别专业文献中的特殊词语,降低了汉语切词的准确率。包括ICTCLAS在内的切词系统大多提供了用户词典接口,用户可以根据自己分析的语料的特点加载词典。但是采用手工方式生成用户词典工作量大,对专家的依赖性高,而且这种方法不具有可移植性,如果要处理一个新领域的语料,必须耗费资源重新添加用户词典。本研究将N-Gram算法应用到中文新词识别领域,该方法获得61.30%的准确率、70.67%的召回率,F值达到0.65。
本研究提出的方法和工具有待完善:
(1)改进算法:可以将N-Gram算法与其他理论融合,提升识别效率。
(2)增加方法的适应性验证:本文以《中国植物志》为样本,验证了该算法在植物学领域的有效性。尝试在其他领域样本上的实验,为算法修正提供依据。
(3)增加样本量:在更大规模的样本集上做实验,以更好地剔除样本带来的偶然性波动,进一步验证算法的性能。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|