{kind=link}
{kind=link}
{kind=link}
基于特征度和词汇模型的专利技术功效矩阵结构生成研究
[陈颖1  , 张晓林
, 张晓林2 ]
, 张晓林|
|


针对目前专利技术功效矩阵结构的构建大多由人工完成的现状,提出一种基于特征度指标和矩阵构建词汇模型的矩阵结构生成方法。特征度指标用于提高构建矩阵结构的候选技术词、功效词的相关度,矩阵构建词汇模型用于技术词、功效词的聚类优化和矩阵结构生成。此方法可以为自动构建专利技术功效矩阵提供技术支持和新思路。
For most of the patent technology-effect matrixes are now manually constructed,thus, a method for matrix structure construction based on feature degree and lexical model is presented. The feature degree is used for improving the correlation degree of candidate technical and effect words, and the lexical model for optimizing clustering of technical and effect words, generating matrix structure. This method provides technical support and new idea for automatically generating patent technology-effect matrix.
专利技术功效矩阵分析作为专利定性分析方法之一已经引起研究者的广泛关注。它能从技术和功效视角同时对专利进行解读,便于掌握技术重点或技术空白点,规避技术雷区。此外,还可找出本身技术(或设计)所在位置,察看该项目是否有其他竞争对手已取得专利,可作为初步侵权判断的依据。进而可根据侵权风险的技术区域、有利可图的区域、研发已呈饱和状态的区域等,拟定下一步研发策略。
专利技术功效矩阵分析的前提是构建专利技术功效矩阵。其含义包括两个方面:矩阵结构的构建,即矩阵的技术分类和功效分类的定义;矩阵单元项的填充,即将专利号(或专利数量、公司名称等)添加到对应的矩阵单元格中。其中,前者是关键和基础,其完整性和准确性对专利技术功效矩阵分析结果的有效性和准确性具有决定性意义。
当前,专利技术功效矩阵结构的构建主要以手工为主。虽然有部分软件或工具声称已经实现或部分实现了自动构建,如TDA[ 1]、恒库[ 2]、台湾连颖PatentTech技术导航员[ 3]等,但从资料查证来看,实质仍是由手工完成,且其技术原则、实现效果和可信度仍需查证。
本文提出基于特征度和词汇模型的矩阵结构构建方法。首先利用基于特征度的方法将特征度低于阈值的技术词、功效词过滤掉;依据专利技术功效矩阵分析对聚类的要求,利用词汇模型对技术词、功效词进行聚类优化;最后,利用词汇模型生成阶层式矩阵结构。
吴清强[ 4]总结了主题构建的选词方法,主要分为基于词频、基于词分布和基于词位置的选词方法等。本文研究任务相当于构建专利的技术主题和功效主题,因此,选择适当的词对后续的词间关系计算、聚类分析都很重要。
文献[5]通过实验发现,短语表达技术功效特征的效果要好于单词;而对于多词短语,长的短语表现效果通常要好于短的短语,如“plant cell”好于“plant”,“converting dc power”好于“converting dc”,即专指词表达效果通常好于泛指词。对于这种情况,通常做法是在不影响原有词集合涵盖语义范围的情况下,只保留专指度高的词,去除专指度低的词。实际操作中应依据具体情况处理,从而保证词的去除不会遗失重要的技术、功效信息,进而影响后续聚类分析。
本文借鉴评价情报检索系统质量的指标——专指度(专指性)[ 6],提出评价单词或短语表示技术功效特征效果的指标——特征度S(Specificity),用于过滤掉数据集中特征度低的词或短语。
通常包含n个词短语的专指度要小于n+1个词短语的专指度,但这只是人们的经验判断。在实际的专利技术功效分析中,n个词短语可能自身代表重要的技术功效信息,不能简单将其去除。Sheremetyeva[ 7]提出了基于单个文档统计信息的“Uniqueness” (U)准则,本文译为“独特性”准则,指n词短语的频次与其扩展——n+1词短语频数之和的差值。如“link bandwidth”的频数为1,其n+1扩展短语只有“communication link bandwidth”,频次为1,则“link bandwidth”的U值为0。U值低说明候选词独立使用的可能性小。依据经验选择U=0作为阈值,将U≤0的候选词过滤掉。但U值没有考虑n+2, n+3, n+4等情况,也没有考虑词性因素。
针对研究任务要求及抽取词的特点,本文提出“特征度”指标S(Specificity),用来衡量抽取出词在表达技术、功效信息上的效果是否显著。相关定义如下:
条件1:设a, b分别代表抽取出的技术词或功效词,且b包含a。a长度为n,1≤n≤4,b长度可为n+1,n+2,n+3,n+4,但总长度≤5。
条件2:设a在所有文档集中出现频次为fa,由于可能有多个b包含a, 分别设为b1, b2, b3…bm,则b在文档集中出现频次分别为fb1, fb2, fb3…fbm。
a的S值计算公式为:
S=fa-(fb1+fb2+fb3…+fbm) (1)
本文取S的阈值为0,当S≤0时表明a的特征度小,应过滤掉。
此外,如果考虑a在b中所处位置的不同,给予b不同的词频权重,则技术词a的S值稍有变化。本文对这一情况进一步展开讨论,在条件1、条件2之外补充条件3和假设1,并对S进行定义。
条件3:设P(Position)代表a在b中所处位置。当a在b的开头时,P为F(First);当a在b的结尾时,P为L(Last)。
假设1:依据英语短语的修辞特性,处于短语后面的名词通常是中心词,其重要性要高于前面的修饰词。本文提出假设:设a包含于b1、b2,如果a在b1 中的P值为L,a在b2中的P值为F;则可认为a在b1中的重要性高于a在b2中的重要性,相应地需要提高b1的词频权重wb。可见,依据a所在位置可把b分为b1、b2两类,还可依据两类数目的比值大致确定词频权重wb,本文暂设wb=1.2,并提出a的S值,如下:
S=fa-((fb11+fb12+…+fb1m)+1.2×(fb21+fb22+…+fb2m))(2)
而且,公式(2)还可能有更复杂的情况,即处于短语后面的名词虽然是中心词,但修饰它的词重要性可能更强。此种情况通常是更强调修饰词的特性,如“gene expression”中可能要强调的是“gene”而不是“expression”,此时就不能简单认定expression在“gene expression”中的重要性高于在“expression vector”中的重要性。
本文主要任务不是分析a、b词的分布,且此种复杂情况影响有限,因此,只利用公式(1)计算S值。提出公式(2)的情况供感兴趣的研究者深入探讨。此外,对于功效词来说,不存在这种复杂情况,直接依据公式(1)计算S值即可。
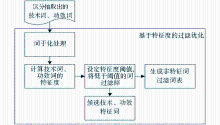
基于上述分析,提出过滤方案,如图1所示:
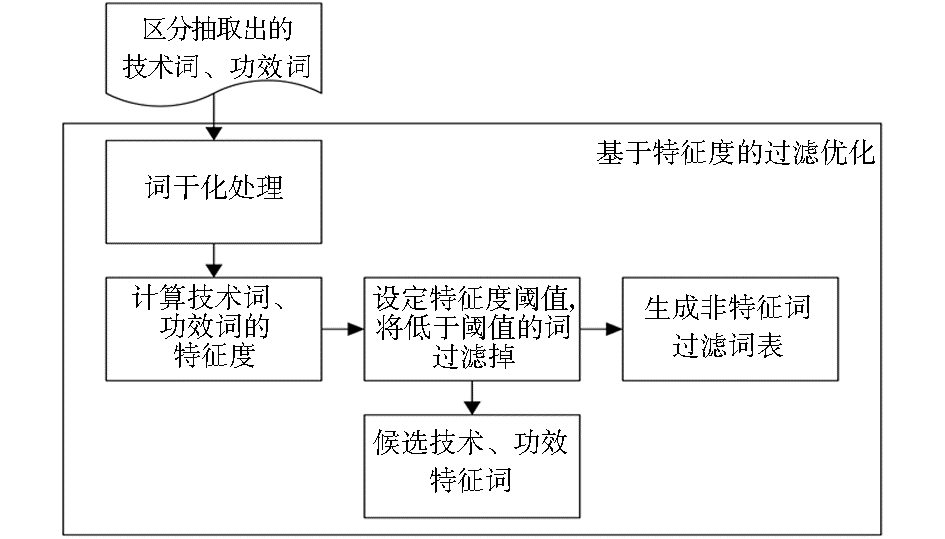 | 图1 基于特征度的过滤方案 |
过滤方案算法如下(以技术词为例):
//基于特征度的过滤算法
算法名: OptimizeDS
输入:抽取出的技术词// totaltech.txt
输出:非特征词过滤词表 // 小于特征度阈值的非技术词列表
技术特征词集合 // 用于最后聚类的技术词
//步骤1:计算技术词的特征度
新建二维字符串数组变量A,将totaltech.txt文档中所有技术词及其词频赋予A,每个词及其词频对应A中每个元素;
新建二维字符串变量T,长度与A相同,用于存储每个词及其特征值;
新建字符串变量a、b,分别代表n词和包含n词的n+1,n+2等词;
新建整型变量fa、fb分别代表a、b的词频数;
新建整型变量num代表所有b的词频总数;
依次对数组A中每个元素执行如下操作,计算每个词的特征度S;
for(i=0;i<=A.length();i++)
{ a=A[i][0]; fa=A[i][4];
for(j=i; j<=i; j++)
{ b=A[j][0]; fb=A[j][4];
if (b.contains(a)= = true)//如果b包含a
num=num+ fb;
else
break;
}
T[i][0]= A[i][0];
T[i][4]= fa-num;//存储抽取出词的特征度
}
//步骤2:将低于特征度阈值的技术词过滤掉,生成技术词过滤词表及候选技术词集合
过滤掉S值小于阈值的技术词
将数组A清空,用于存放过滤后的词及其特征度值;
将过滤词及其特征度值存入数组A;
//步骤3:将候选技术词集合中前200个高词频特征词生成技术特征词集合
//步骤4:相关文档关闭,算法结束
说明:
(1)非特征词过滤词表经过领域专家分析评价后可补充到专业过滤词表中,便于复用。
(2)特征度过滤后的词集合提高了表达技术、功效特征的效果。重复词、重复短语的去除增加了数据集的信息量。
(3)实验发现前200个高频词基本能概括主要的技术功效相关信息。
(4)处理多个专利字段时,可考虑基于位置的权重调整,如来源于Claims的词应赋予更高权重,在多个专利字段中同时出现的词应赋予更高权重等。
从词汇角度看,专利技术词通常是专利组件名称、技术流程、技术方法名称、涉及的设备材料名称等,专利功效词通常是描述性的动词短语或表示性能、用途、目标的介词短语或动名词等。有的技术词、功效词较为宽泛,需结合上下文语境才能理解;有的专业化很强,需具备领域知识才能识别出来。因此,聚类更关注将与某一技术点或功效点相关的词聚类到一起,以弥补因语境缺失带来的理解困难;还应尽量排除或减少出现次数较多、但对专利技术功效分析意义不大的词;同时,尽可能将语义相关的词聚类到一起。
从聚类角度看,要尽可能全面概括所分析技术主题专利的主要技术点和功效点。因此,对于出现频率较低、但较重要的技术词和功效词也要通过相应手段使之成为候选词。此外,专利用语除了较为隐晦、术语较多、同一事物可能采用多种称谓之外,还存在宽泛词较多的情况。此种情况是因为有的专利权利要求书力图扩大权利保护范围,会利用上位词或较宽泛的词来表述,如“approach”, “compound”等,进而增加了分析难度。相应地,在聚类结构中要尽可能体现这种层次关系。
文献[8]提出一种专利技术功效矩阵构建三维词汇模型,本文利用此词汇模型的中观词汇框架来辅助微观词的聚类,从而使在技术或功效上相似度或相关度大的词更易于聚类到一起。
将中观词汇框架看作一篇篇文档,如果两个词经常同时出现在某一词分支中,则表明这两个词的相关度大。因此,可通过给共现次数赋予权值来突出其更强的相关性。
专利中经常有同义词、近义词及上下级词,充分利用这些词及词间关系能揭示隐藏的相关性,能潜在地产生更好的聚类。相应地可考虑采用包含词间语义关系的专业叙词表或语义词典来辅助聚类。因专业叙词表不易获得,本文只初步探讨利用WordNet的语义关系实现基于词汇模型的技术词、功效词聚类优化。
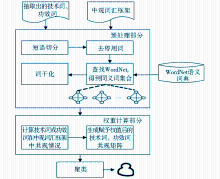
思路是利用技术词、功效词在中观词汇框架中的共现情况对共现矩阵赋予相应权值。考虑同义词因素,利用WordNet进行同义词扩展。为避免噪声数据,对抽取出的技术词、功效词只扩展其同义词。通过判断扩展后的技术词、功效词是否在扩展后的中观词汇框架中共现,来计算相应权值。涉及操作有短语切分、去停用词、词干化等。具体方案如图2所示:
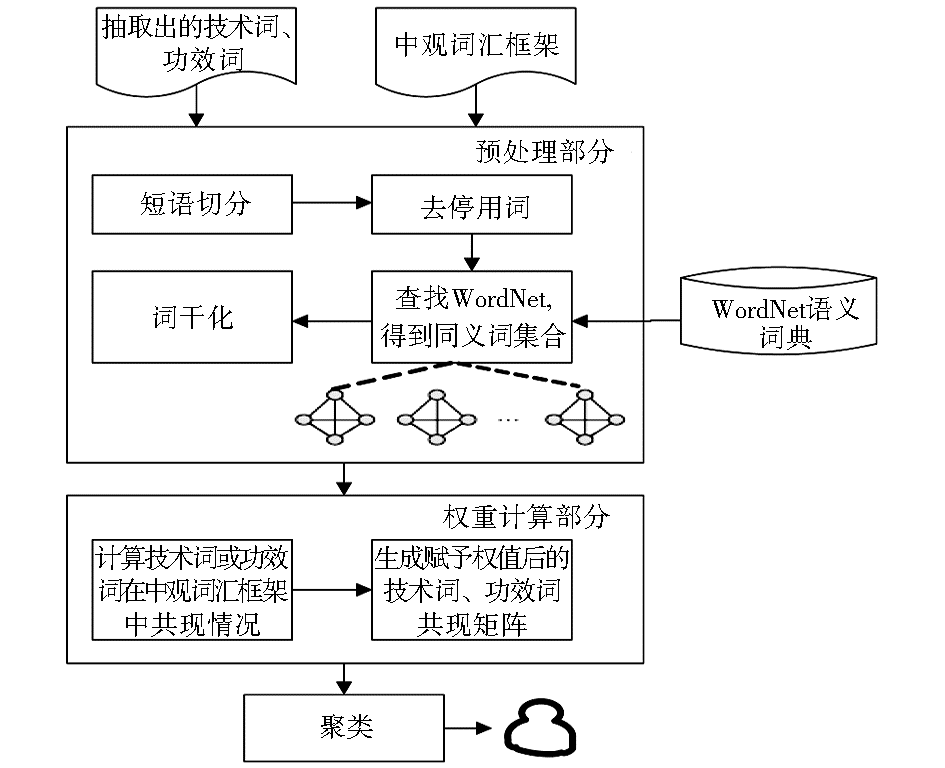 | 图2 基于词汇框架的聚类优化方案 |
(1)预处理部分
短语切分用于把短语切分成单词,方便针对每个单词查找WordNet词典;去停用词将切分后出现的停用词去除;查找WordNet得到同义词集合,用于分别得到技术词、功效词的同义词集合及中观词汇框架的同义词集合;词干化处理可简化词形,方便后续匹配工作。
(2)权重计算部分
技术词、功效词在词汇框架中存在多种共现情况。以技术词为例,设技术词T1 为“solar battery”,T2为“phase inverter”,查找WordNet后分别扩展为:T1’=“solar barrage battery”,T2’=“phase inverter”。
情况1:T1’和T2’均有一个词在词汇框架中共现,如“solar”、“inverter”共现;情况2:T1’和T2’有多个词共现,如“solar ”、“battery”、“ phase”、“ inverter”均在词汇框架中共现。依据经验两种情况所体现的重要性不同,情况2说明T1’和T2’相关性更大。为简化操作,本文只按情况一处理,即只分“存在共现”和“不存在共现”两种情况。
WordNet在调出同义词、上级词时可能会产生与分析无关的噪声词,这种情况是WordNet语义词典本身带来的。如“battery”调出同义词中包含“barrage”,中文含义是“弹幕;阻塞;齐射式攻击;拦河坝”,与本文研究中“battery”的含义“电池”不是同义词。“barrage”的出现是因为“battery”也有“group of guns or missile launchers operated together at one place”的含义。本文对这种情况忽略不计。
分析发现词在词汇框架的不同层次中共现所体现的关联强弱是不同的(层次越低,关联越强),相应所赋予的权重也应不同。本文暂不考虑此种情况,只要在一个技术或功效分支(从顶层到底层为一个分支)中共现即可,并赋予相应权重。依据中观词汇框架,共得到技术分支82个,功效分支16个。分别计算与技术词、功效词的共现情况。
优化方案主要步骤算法如下:
//基于词汇模型的聚类优化算法
算法名: WeightTE
输入:技术词、功效词集合;中观词汇框架;
输出:技术词、功效词共现矩阵;
//步骤1:预处理
短语切分; //将技术词、功效词切分成单词,将中观词汇框架中短语切分成单词
去停用词; //调用停用词表,去除短语切分后出现的停用词
调用WordNet的JWNL接口,生成同义词集合; //分别生成技术词、功效词和中观词汇框架的同义词集合
将技术词、功效词本身及其同义词集合存储成文本文件,分别为tech.txt和effect.txt
将82个技术分支、16个功效分支中词及其同义词存成文档,分别为wordtech/目录和wordeff/目录下文件;
//步骤2:计算技术词、功效词在中观词汇框架中共现情况(以tech.txt为例);
新建二维整型数组s[200][82],初始值为0;//存储词与共现框架共现权重
对tech.txt和effect.txt中每行词条执行如下操作;
for (tech.txt中每行词)
{ for(tech/目录下每个文件)
if(tech.txt当前行中有词出现在tech/目录下当前文件中)
将s数组中当前行当前列赋值为1;
//如tech.txt中第i行中有词出现在tech/目录下
j.txt文件中,则s[i][j]=1;
}
//生成技术词、功效词与词汇框架共现矩阵s[][]
新建二维整型矩阵c[200][200],用于存储词共现的权重;
依据矩阵s[][],生成矩阵c[200][200];
利用矩阵s,优化聚类共现矩阵。
//当s[i][j]==1 时,表明词i与词j有共现关系,则对
c[i][j]赋予权重1.1
//步骤3:关闭相应文档,算法结束
专家构建矩阵结构的过程虽然看似较主观、随意,但实际上仍遵循了相应规则或要点。通过专家调研及本文研究,矩阵结构用词要求总结如下:
(1)完全性:能够确实表示目标内容,不遗漏相关内容。
(2)区分性:词义明确,能清晰区分出不同技术点、功效点间的差异。
(3)精练性:因每个技术点或功效点用词不宜过多,在保证全面概括的同时应尽量精练表达。
(1)本文推荐矩阵结构词的角度
聚类得到的层次结构在一定程度上能表现技术点和功效点,且有的聚类结构层次清晰,可直接看出技术点或功效点的层次关系。但普通用户依据聚类结果直接得出矩阵结构仍比较困难。本文从词频角度、聚类角度分析进入矩阵结构词的特点。
①基于词频角度
通过初步实验,发现高频词更易于被判断为技术、功效相关词,而且总体上遵循词频越高相关性越大的规律。虽然功效词的相关性随词频降低的趋势没有技术词明显,但专家及本文实验结果一致认为高频功效词更具分析意义。
重点考虑类团中高词频进入矩阵结构,并给予相应权重。相应地,设某技术词、功效词聚类集合中词频为freg={f1,f2,f3,…,fn},找出fi=max(f1,f2,f3,…,fn)(1≤ i≤n),则Ti 最可能为此类的推荐词。当然,在实际构建矩阵结构时,应根据需要选择词频前top(m)个词。
②基于聚类角度
专利中对技术和功效的描述有时是短语或一句话,因此会包含很多相关信息。寻找相关信息中重要的信息点作为矩阵结构词也是一种好的思路。本文参考主题类标识中的“基于类内中心度”方法[ 4]从词的类团中推荐出合适的矩阵结构词。
“基于类内中心度”方法[ 4]指计算词间是否具有关系,有为1,无为0。然后累加每个词的所有关联度,获得总关联度,选择具有最大平均关联度的词汇作为主题类标识。相关公式为:
rij= 
对于词Termi,其关联度为Ni= 
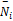

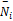
(2)本文推荐矩阵结构词的权重公式
为比较基于聚类角度对权重变化的影响,本文定义了两种聚类权重w2和w2',分别对应推荐词权重公式(3)、公式(4)。
w=(w1+w2)/2(3)
wn=(w1+w2')/2(4)
其中,w1为词频权重,w1按词频高低分为6个级别,值为1.3,1.2,1.1,1.0,0.9,0.8。w2为等级权重,依据词共现次数分为6个等级,值为1.3,1.2,1.1,1.0,0.9,0.8。w2'为频次权重,定义为关联度与当前词集合中最大共现词数之比,即w2'=Ni/cowordi,cowordi=max(coword1,coword2,…,cowordn)。
由于很多类团共现次数较少,无法推荐合适的结构词,故将所有词看作一个大类,取词在整个大类中的类内相似度进行计算,取w及wn较高词进入矩阵结构。
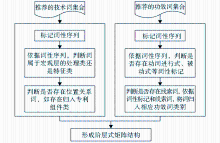
推荐出的矩阵结构词中有的词含义相似,代表同一技术点或功效点;有的则可看作某一技术点或功效点的细分。为了使所有的专利能分入相应的技术和功效类别,实际专利技术功效矩阵中所选用的技术词、功效词不宜过细。因此,结合词汇模型的宏观词汇框架和基于线索词的技术词、功效词区分规则(规则三)[ 5],尝试在宏观技术词、功效词和推荐出的矩阵结构词中建立关联,生成阶层式矩阵结构。
分析发现规则三和宏观词汇框架有一定相关性,如表1和表2所示:
| 表2 区分规则三与宏观层技术词的对应关系 |
| 表2 区分规则三与宏观层功效词的对应关系 |
由于专利技术词常为一些名词或名词术语,线索词较少,因此不易判断其所对应的宏观技术词。除表1的对应关系之外,通过技术词的语法标记序列也能初步判断所对应的宏观技术词类型,但此种方法确定的对应关系仍需人工进一步核实确认。主要有如下对应关系:如VGB/NN,JJ/VBG/NN,VBN/NN/NN大多对应宏观层技术层的“处理”,RB/NN/NN对应宏观层技术层的“特性”。
表示程度的线索词所对应的宏观功效词不易确定,要依据线索词后词的含义来判断。宏观功效层的“成本降低”、“节省能源”和“节省时间”可能与多种线索词相连,不易判断。因此,可依据推荐出的矩阵词中是否包含cost、energy和time来初步判断。但有些矩阵词可能不包含这三个线索词,此种情况下要依靠专家辅助来决定。
阶层式矩阵结构生成方案如图3所示:
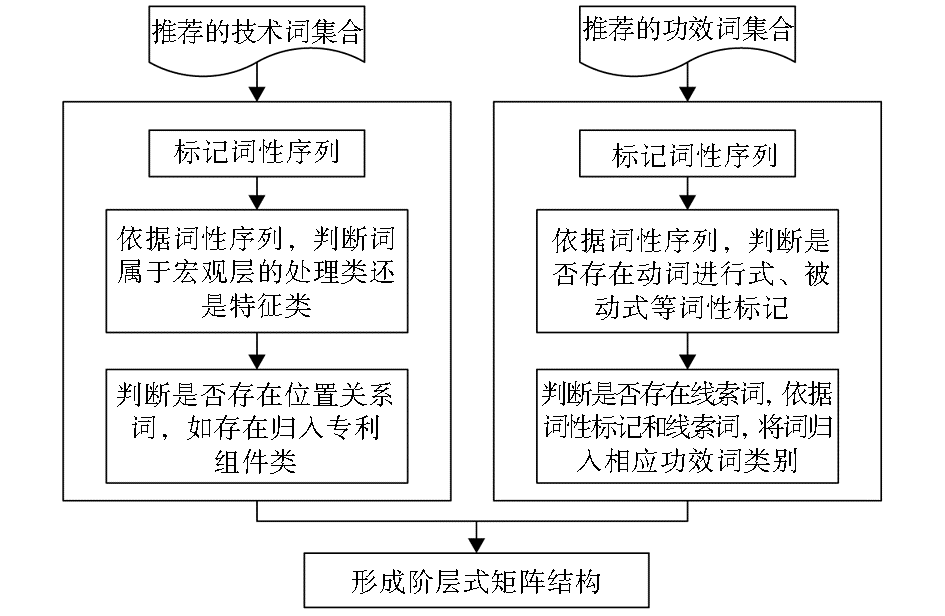 | 图3 阶层式矩阵结构生成方案 |
本文在分析专利技术点、功效点用词的基础上,分析技术词、功效词聚类优化的依据,并从两方面优化技术词、功效词的聚类效果,分别是基于特征度的优化和基于词汇模型的优化。讨论了矩阵结构的用词要求,给出推荐矩阵结构词的权重公式,并尝试利用基于线索词的技术词、功效词区分规则(规则三)和词汇模型中宏观层词汇之间的对应关系生成阶层式专利技术功效矩阵结构。为验证本文方法的科学性和可行性,笔者对“光伏系统逆变器”专利的DII摘要和权利要求书进行实验,结果表明优化后的聚类效果有明显改善,生成的阶层式矩阵结构基本符合专利技术功效矩阵分析的要求,具体将另撰文详述。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|