{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
MapReduce原理及其主要实现平台分析
[亢丽芸 , 王效岳, 白如江]
, 王效岳, 白如江]
, 王效岳, 白如江]
|
|


针对海量数据处理在处理速度、存储空间、容错性、访问时间等方面存在的问题,对Google MapReduce编程模型的原理、执行流程等进行分析研究,介绍4种主要的MapReduce实现平台Hadoop、Phoenix、Disco、Mars,从编程语言、构建平台、功能特点和应用领域4个方面对4种平台进行比较分析,以期对MapReduce编程模型原理及其应用平台有一个较全面的认识。
Due to the problems in processing speed, storage space, fault tolerance, access time and others of massive data processing, this paper analyzes principle, implementation process of Google MapReduce programming model, introduces four main MapReduce implementation platforms,including Hadoop, Phoenix, Disco and Mars.Then,it separately compares them in four aspects as the programming language, building platform, functions and features, applications to have a comprehensive understanding of MapReduce programming model and it’s application platforms.
随着Internet网络资源的迅速膨胀,因特网容纳了海量的各种类型的数据和信息。海量数据的处理对服务器CPU、IO的吞吐都是严峻的考验,不论是处理速度、存储空间、容错性,还是在访问速度等方面,传统的技术架构和仅靠单台计算机基于串行的方式越来越不适应当前海量数据处理的要求。国内外学者提出很多海量数据处理方法,以改善海量数据处理存在的诸多问题。目前已有的海量数据处理方法在概念上较容易理解,然而由于数据量巨大,要在可接受的时间内完成相应的处理,只有将这些计算进行并行化处理,通过提取出处理过程中存在的可并行工作的分量,用分布式模型来实现这些并行分量的并行执行过程。随着技术的发展,单机的性能有了突飞猛进的发展变化,尤其是内存和处理器等硬件技术,但是硬件技术的发展在理论上总是有限度的,如果说硬件的发展在纵向上提高了系统的性能,那么并行技术的发展就是从横向上拓展了处理的方式。
MapReduce[ 1]是由谷歌推出的一个编程模型,也是一个能处理和生成超大数据集的算法模型,该架构能够在大量普通配置的计算机上实现并行化处理。
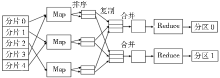
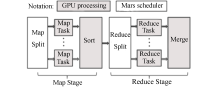
MapReduce编程模型结合用户实现的Map和Reduce函数,可完成大规模的并行化计算。MapReduce编程模型的原理[ 1]是:用户自定义的Map函数处理一个输入的基于key/value pair的集合,输出中间基于key/value pair的集合,MapReduce库把中间所有具有相同key值的value值集合在一起后传递给Reduce函数,用户自定义的Reduce函数合并所有具有相同key值的value值,形成一个较小value值的集合。一般地,一个典型的MapReduce程序的执行流程如图1所示[ 2]:
 | 图1 MapReduce执行流程 |
MapReduce执行过程主要包括:
(1)将输入的海量数据切片分给不同的机器处理;
(2)执行Map任务的Worker将输入数据解析成key/value pair,用户定义的Map函数把输入的key/value pair转成中间形式的key/value pair;
(3)按照key值对中间形式的key/value进行排序、聚合;
(4)把不同的key值和相应的value集分配给不同的机器,完成Reduce运算;
(5)输出Reduce结果。
任务成功完成后,MapReduce的输出存放在R个输出文件中,一般情况下,这R个输出文件不需要合并成一个文件,而是作为另外一个MapReduce的输入,或者在另一个可处理多个分割文件的分布式应用中使用。
MapReduce的数据模型较简单,它的Map和Reduce函数使用key/value pair进行输入和输出,Map和Reduce函数遵循的形式如表1所示[ 1]:
| 表1 Map/Reduce函数数据模型 |
MapReduce库支持多种不同格式的输入数据类型,如文本模式的输入数据,每一行被视为一个key/value pair,key是文件的偏移量,value是该行的文本内容[ 1]。MapReduce的预定义输入类型能够满足大多数的输入要求,使用者还可通过提供一个简单的Reader接口,实现一个新的输入类型。MapReduce还提供了预定义的输出类型,通过这些预定义类型能够产生不同格式的输出数据,用户可采用类似添加新输入数据类型的方式增加新输出类型。
受Google MapReduce启发,许多研究者在不同的实验平台上实现了MapReduce,并取得了一些研究成果,其中较具代表性的研究成果有Apache的Hadoop,斯坦福大学的Phoenix,Nokia研究中心的Disco和香港科技大学的Mars。
(1)平台介绍
Apache软件基金会对Hadoop(http://hadoop.apache.org/)的设计思想,来源于Google的GFS(Google File System)[ 3]和MapReduce[ 1]。Hadoop是一个开源软件框架,通过在集群计算机中使用简单的编程模型,可编写和运行分布式应用程序处理大规模数据。Hadoop包括三个子项目:Hadoop Common、Hadoop Distributed File System(HDFS) 和Hadoop MapReduce,其中 Hadoop Common是一套支持Hadoop子项目的工具,由文件系统、远程过程调用(Remote Procedure Calls,RPC)和序列化库构成;HDFS是一个分布式文件系统,提供高吞吐量的应用程序数据访问;Hadoop MapReduce是一个在计算机集群上分布式处理海量数据集的软件框架。
(2)工作流程
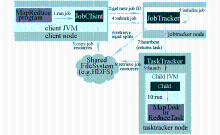
Hadoop运行MapReduce作业的整个过程如图2所示[ 2]:
 | 图2 Hadoop运行MapReduce作业工作原理[ 2] |
在最上层,有4个独立的实体,客户端、jobtracker、tasktracker和分布式文件系统。客户端提交MapReduce作业;jobtracker协调作业的运行,jobtracker是一个Java应用程序,它的主类是JobTracker;tasktracker运行作业划分后的任务,tasktracker也是一个Java应用程序,它的主类是TaskTracker;分布式文件系统(一般为HDFS)用来在其他实体之间共享作业文件。Hadoop运行MapReduce作业的步骤主要包括:提交作业;初始化作业;分配任务;执行任务;更新进度和状态;完成作业[ 2]。
Hadoop MapReduce框架包括一个Jobtracker和一定数量的Tasktracker[ 4],Jobtracker通常运行在和名称节点相同的主机上。用户将MapReduce 作业发送给Jobtracker所在集群的其他机器上分割工作,集群中其他的空闲机器,每个机器运行一个Tasktracker,Tasktracker与Jobtracker通信,在可能的情况下, Jobtracker给它们分配Map或Reduce任务。
(1)平台介绍
Phoenix(http://mapreduce.stanford.edu/)作为斯坦福大学EE382a课程[ 5]的一类项目,由斯坦福大学计算机系统实验室开发。Phoenix[ 6]是为达到共享内存系统的目的,对Google MapReduce的一种实现方式。Phoenix对MapReduce的实现原则和最初由Google 实现的MapReduce基本相同。不同的是,它在集群中以实现共享内存系统为目的,共享内存能最小化由任务派生和数据间的通信所造成的间接成本。Phoenix可编程多核芯片或共享内存多核处理器(SMPs和 ccNUMAs),用于数据密集型任务处理。
(2)工作流程
Phoenix系统包括一个简单的应用程序编程接口(Application Programming Interface,API)和一个高效运行时系统,该API对应用程序的程序员是可见的,高效的运行时系统能够自动管理线程的创建、动态任务调度、数据分区、跨处理器节点的容错。Phoenix使用线程创建并行化的Map和Reduce任务,给可用的处理器动态调度任务,为了实现负载均衡和最大化吞吐量,通过调整任务粒度和并行任务的分配来进行局部性管理。
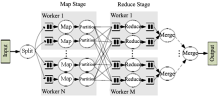
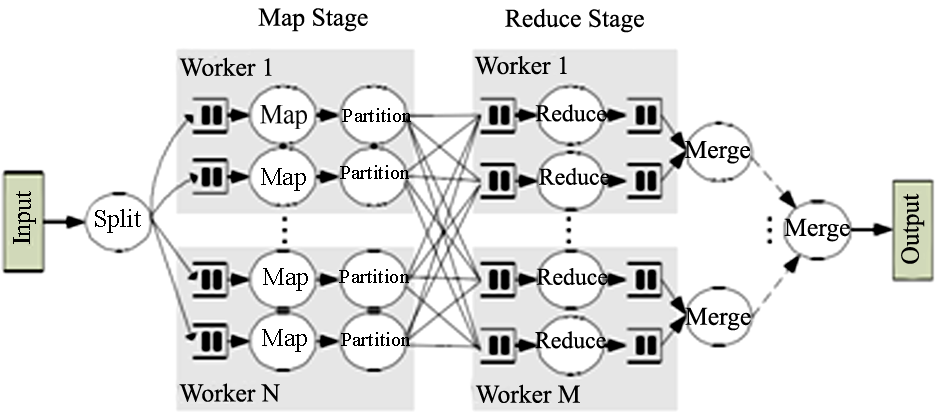 | 图3Phoenix运行时系统的基本数据流[ 6] |
图3显示了Phoenix运行时系统工作的基本流程[ 6],运行时由调度器控制,调度器由用户代码进行初始化。调度器创建和管理所有运行Map和Reduce任务线程,还管理用于任务通信的缓冲区。程序员通过scheduler_args_t结构体来初始化调度器需要的所有数据和函数指针,初始化完成后,调度器判定用于计算的内核数量,对于每一个内核,它派生一个线程,动态分配一定数量的Map和Reduce任务[ 6]。
3.3 Disco(1)平台介绍
Disco(http://discoproject.org/)是由Nokia研究中心开启的,基于MapReduce的分布式数据处理框架,核心部分由并行性很高的Erlang语言开发,外部编程接口为Python语言。Disco是一个开放源码的大规模数据分析平台,支持大数据集的并行计算,能运行在不可靠的集群计算机上。Disco可部署在集群和多核计算机上,还可部署在Amazon EC2上。
(2)工作流程
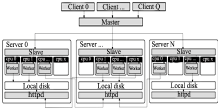
Disco基于主/从(Master/Slave)架构,总体设计架构如图4所示[ 7]:
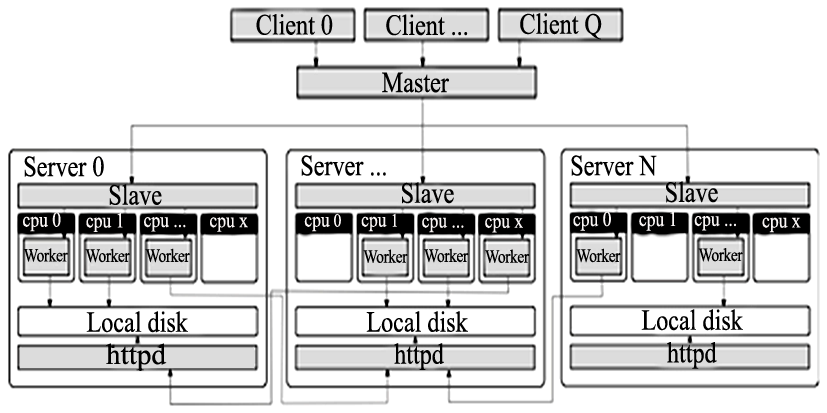 | 图4 Hadoop运行MapReduce作业工作原理[ 7] |
Disco工作流程主要包括5个部分:
①Disco用户使用Python脚本开始Disco作业;
②作业请求通过HTTP发送到主机;
③主机是一个Erlang进程,通过HTTP接收作业请求;
④主机通过SSH启动每个节点处的从机;
⑤从机在Worker进程中运行Disco任务。
客户端进程是一些Python程序,使用函数disco.job()向Master提交作业;主机Master接收作业,并将它们添加到作业队列中,以便进行调度;当集群中的节点可用时,Master启动集群中的Slave机器,Slave机器在各自的节点处启动和监控所有的进程;Workers用于执行提交作业中的具体任务,Workers的输出位置被发送到Master。Disco在每个从机服务器节点上运行一个HTTP服务器,当Worker和输入运行在不同节点时,便于数据的远程访问。用户可以限制每个节点上并行运行的Worker数量,根据集群中的可用CPU和磁盘资源,指定尽可能多的任务。
(1)平台介绍
一些研究者正在将MapReduce架构扩展到图形处理器(Graphic Processing Units,GPUs)上实现,香港科技大学的He 等[ 8],与微软和新浪合作,在单GPU上开发了Mars(http://www.cse.ust.hk/gpuqp/Mars.html)。Mars是基于图形处理器(GPUs)对Google MapReduce的一个实现,目前已经包含字符串匹配、矩阵乘法、倒排索引、字词统计、网页访问排名、网页访问计数、相似性评估和K均值等8项应用,能够在32位与64位的Linux平台下运行[ 9]。
(2)工作流程
Mars和基于GPU的MapReduce框架相似,也包括Map和Reduce两个阶段,GPU上Mars的基本工作流程如图5所示[ 8]:
 | 图5 GPU上Mars的基本工作流程[ 8] |
在开始每个阶段之前,Mars初始化线程配置,包括GPU上线程组的数量和每个线程组中线程的数量。Mars在GPU内使用大量的线程,在运行时系统的时候,任务均匀分配给线程,每个线程负责一个Map或Reduce任务,以小数量的key/value pairs作为输入,并通过一种无锁的方案来管理MapReduce框架中的并发写入。
Mars的工作流程主要有7个操作步骤:
①在主存储器中输入key/value对,并将它们存储到数组;
②初始化运行时的配置参数;
③复制主存储器中的输入数组到GPU设备内存;
④启动GPU上的Map阶段,并将中间的key/value对存储到数组;
⑤如果noSort选择F,即需要排序阶段,则对中间结果进行排序;
⑥如果noReduce是F,即需要Reduce阶段,则启动GPU上的Reduce阶段,并输出最终结果,否则中间结果就是最终结果;
⑦复制GPU设备存储器中的结果到主存储器。
在上述步骤中,①②③和⑦的操作由调度器来完成,调度器负责准备数据输入,在GPU上调用Map和Reduce阶段,并将结果返回给用户。
(1)Hadoop
Hadoop是采用Java开发的,所以能很好地支持Java语言编写的MapReduce作业,但在实际应用中,有时候由于要用到非Java的第三方库或者其他原因,需采用C/C++或其他语言编写MapReduce作业,这时候可能要用到Hadoop提供的一些工具。若用C/C++编写MapReduce作业,可使用Hadoop Streaming[ 10]或Hadoop Pipes[ 2, 11]工具;若用Python编写MapReduce作业,可以使用Hadoop Streaming或Pydoop[ 12, 13]工具;若使用其他语言,如Shell脚本、PHP、Ruby等,可使用Hadoop Streaming。
Java是 Hadoop支持的最好最全面的语言,而且提供了很多工具方便程序员开发。Hadoop流(Hadoop Streaming)使用Unix标准流作为Hadoop和程序之间的接口,其最大的优点是支持多种编程语言,只要编写的MapReduce程序能够读取标准输入,并写到标准输出,但效率较低,Reduce 任务需等到Map 阶段完成后才能启动。Hadoop管道(Hadoop Pipes)是Hadoop MapReduce的C++接口的代称,与流不同,流使用标准输入和输出让Map和Reduce节点之间相互交流,管道使用sockets作为tasktracker与C++编写的Map或者Reduce函数的进程之间的通道。Pydoop是专门为Python程序员编写MapReduce作业设计的,底层使用了Hadoop Streaming接口和libhdfs库。
(2)Phoenix
目前,Phoenix能够提供C和C++的应用程序编程接口,类似的API也可以被定义成像Java或者C#这样的语言[ 6]。Phoenix API包括两部分函数集:第一个函数集由Phoenix提供,可用于应用程序代码中来初始化系统和发出输出对;第二部分包括程序员自定义函数。
(3)Disco
Disco平台的核心部分由并行性能很高的Erlang语言开发,其外部编程接口为易于编程的Python语言。Disco代码风格指南[ 14]包含了Disco代码库的编码约定:对于Erlang而言,除另有规定外,一般采用Erlang编程规则[ 15];对于Python,除了另有规定外,采用PEP 8准则[ 16]。
(4)Mars
目前Mars提供了C和C++的应用程序编程接口API,和已有的MapReduce框架相似,Mars也有两种APIs集:一种是系统提供的APIs,用户可以通过调用库来使用;另一种是用户提供的APIs,该部分由用户实现[ 8]。Mars当前版本可运行在32位和64位的Linux系统上,支持最新的CUDA SDK 2.3。
上述4种平台的API支持的编程语言比较如表2所示:
| 表2 MapReduce不同实现平台编程语言 |
(1)Hadoop
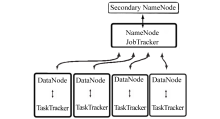
Hadoop平台搭建完成后,在一个全配置的集群中,运行Hadoop意味着在集群的不同机器上运行一组守护进程(daemons),这些进程包括:名称节点(NameNode);数据节点(DataNode);次名称节点(Secondary NameNode);作业跟踪节点(JobTracker);任务跟踪节点(TaskTracker)。
从HDFS分布式存储的角度来说,集群中的节点由一个 NameNode 和若干个 DataNode组成,另有一个 Secondary NameNode作为NameNode的备份;从MapReduce分布式计算的角度来说,集群中的节点由一个 JobTracker 和若干个 TaskTracker 组成。典型Hadoop集群的拓扑结构如图6所示[ 17]:
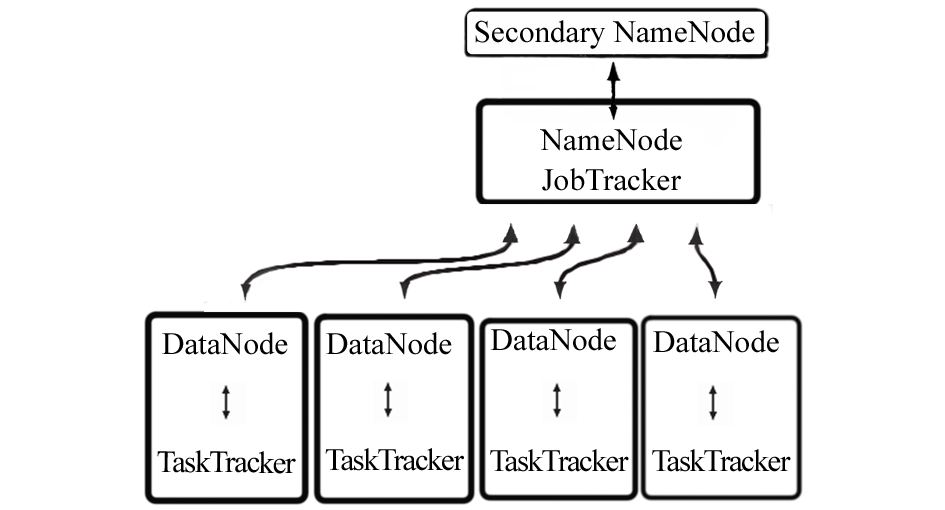 | 图6 典型Hadoop集群拓扑结构[ 17] |
Hadoop的分布式存储和分布式计算都采用了主/从结构,NameNode和JobTracker的守护进程运行在主节点上,DataNode和TaskTracker运行在从节点上,TaskTracker 必须运行在 DataNode 上,便于数据的本地计算,JobTracker 和 NameNode 则无须一定在同一台机器上。
(2)Phoenix
Phoenix系统包括一个简单的API和一个高效的运行时系统,该API对应用程序的程序员是可见的,高效的运行时系统能够自动管理线程创建、动态任务调度、数据分区、跨处理器节点的容错。运行时系统的实现是建立在PThread[ 18]之上的,也可方便地移植到其他共享内存线程库上。
(3)Disco
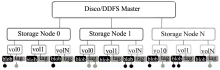
Disco平台由分布式存储系统DDFS(Disco Distributed File System)和MapReduce框架组成,DDFS与计算框架是高度耦合的,DDFS架构如图7所示[ 19]:
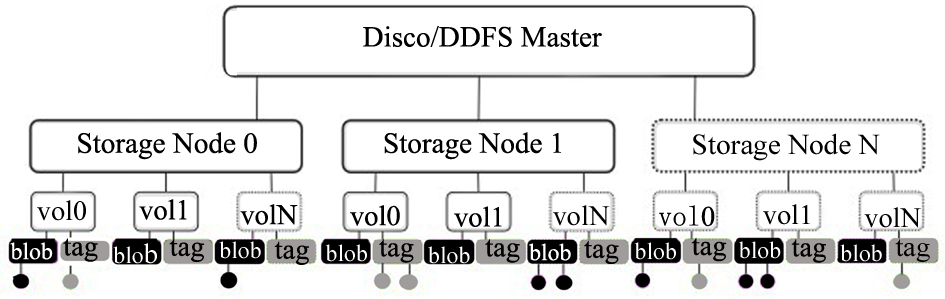 | 图7 DDFS的架构[ 19] |
DDFS嵌入到Disco内,有一个Master节点和多个存储节点,每个存储节点由一组磁盘或者卷宗组成(vol0…volN),它们分别挂载在DDFS_DATA/vol0 …DDFS_DATA/volN上。每个卷宗下面有两个文件tag 和 blob,分别用于存储标记 tag(相当于key)和标记对应的值(即value)。DDFS会监控各个节点上的磁盘使用情况,每隔一段时间进行负载均衡。
(4)Mars
Mars在多核架构模型基础上设计,提供了一个小的APIs集,这些和基于CPU的MapReduce相似。Mars运行时为Map或Reduce任务初始化大量的GPU线程,并为每个线程自动分配少量的key/value对来运行任务。由于数据分析任务涉及到大量的文本处理,Mars的APIs还设计了一个高效的字符串库。
(1)Hadoop
Hadoop是一个开源框架,通过在大规模集群计算机中使用简单的编程模型,可编写和运行分布式应用程序处理大规模数据,是目前应用广泛的开源并行编程框架。
Hadoop具有诸多优点:
①良好的扩展性:通过简单增加集群节点,可处理更大规模的数据集;
②可靠性:Hadoop致力于运行在一般商用硬件上,其架构假设硬件会频繁失效,它可以从容地处理大多数故障;
③高效性:Hadoop集群的存储和计算能力非常强,适合有超大数据集的应用程序;
④经济性:Hadoop运行在一般商用机器构成的大型集群上或如亚马逊弹性计算云(EC2)等云计算服务器之上;
⑤易用性:Hadoop方便、简单,用户可快速搭建自己的Hadoop集群,并编写出高效的并行代码。
但是Hadoop也存在一些不足,由于系统开销等原因,处理小规模数据的速度不一定比串行程序快,而且单机处理数据的性能较低;若计算时产生的中间结果文件非常大,Reduce过程需要通过远程过程调用来获取中间结果文件,这样会加大网络传输开销;作为一个比较新的项目, Hadoop在很多方面还需提升,包括稳定性、易用性、可维护性、可测试性等,特别是在MapReduce层,还未解决线性扩展问题。
(2)Phoenix
Phoenix在共享内存系统上实现了MapReduce, 利用共享内存缓冲区实现通信,从而避免了因数据复制产生的开销,但Phoenix也存在不能自动执行迭代计算、没有高效的错误发现机制等不足之处[ 20]。
(3)Disco
Disco是一个开源的大规模数据分析平台,由一个Master 服务器和一系列Worker节点组成,其中Master和Worker之间采用基于轮询[ 21]的通信机制,使用HTTP的方式传输数据。Master 服务器时刻跟踪用户应用,负责任务调度与分配,保存与应用相关的输入数据、中间值和最终结果。Worker节点则负责执行Map与Reduce任务,但是由于轮询的时间间隔不好确定,若时间间隔设置不当,则会显著降低程序的执行性能[ 20]。
(4)Mars
Mars是基于GPUs的MapReduce实现,该框架旨在为开发者提供一个基于GPU的通用框架以完成准确、高效、简单的实施数据和计算密集型任务。由于GPU线程不支持运行时动态调度,所以给每个GPU线程分配的任务是固定的,若输入数据划分不均匀,将导致Map或Reduce阶段的负载不均衡,使得整个系统性能急剧降低。同时由于GPU不支持运行时在设备内存中分配空间,需要预先在设备内存中分配好输入数据和输出数据的存放空间,但是Map和Reduce阶段输出数据大小是未知的,并且当多个GPU线程同时向共享输出区域中写数据时,易造成写冲突[ 20]。
MapReduce不同的实现平台和研究成果有着不同的功能和优缺点,主要实现平台功能特点比较如表3所示:
| 表3 不同实现平台功能特点比较 |
(1)Hadoop
Hadoop可充分利用集群的优势进行高速运算和存储,由于Hadoop在处理大规模数据上的优势,基于Hadoop的应用非常多,尤其是在互联网领域。Yahoo!通过集群运行Hadoop,以支持广告系统和 Web搜索研究,并将Hadoop广泛应用于日志分析、广告计算、科研实验中[ 22];Amazon的搜索门户A9.com基于Hadoop完成了商品搜索的索引生成[ 23];互联网电台和音乐社区网站Last.fm使用Hadoop集群进行日志分析、A/B测试评价、Ad Hoc处理和图表生成等日常作业[ 24];著名SNS网站Facebook使用Hadoop,存储日志数据,支持其上的数据分析和机器学习,还用Hadoop构建了整个网站的数据仓库,进行日志分析和数据挖掘[ 25]。淘宝是国内最先使用Hadoop的公司之一,其Hadoop系统用于存储并处理电子商务交易的相关数据[ 26];百度使用Hadoop进行搜索日志分析和网页数据挖掘工作,百度在Hadoop上进行广泛应用并对它进行改进和调整,同时赞助了HyperTable[ 27]的开发。
Hadoop已取得非常突出的成绩,随着互联网的发展,新的业务模式还将不断涌现,其应用也会从互联网领域向电信、银行、电子商务、生物制药等领域拓展。
(2)Phoenix
Phoenix是在共享内存系统上实现的MapReduce,其应用主要包括:
①词频统计:统计文件集中每个词的共现频率;
②反向链接:创建HTML文件反向链接指数;
③矩阵乘法(Matrix Multiply):密集型整数矩阵乘法;
④字符串匹配:通过键值搜索文档;
⑤K-means:通过K均值迭代聚类算法,将三维数据点分成组;
⑥PCA(Principal Components Analysis):主成分分析矩阵;
⑦直方图:在一组图像中判定每个RGB分量的频率;
⑧线性回归(Linear Regression):计算一组点的最佳拟合线[ 6]。
(3)Disco
作为一个分布式处理的轻量级MapReduce实现框架,Disco的用途主要是:解析、格式化、日志分析、聚类、概率建模、数据挖掘、全文索引和机器学习。目前Disco正被用于多种行业,解决具有挑战性的问题,涉及到大规模数据。Disco商业级的应用如:在Allston Trading,Disco用于各种各样的历史研究和现代金融领域的实时举措;在Chango,Disco是分析和竞标广告市场的核心组件;在Nokia,最大的数据分析集群运行的就是Disco,对Nokia庞大的移动数据资产进行日常分析;在Zemanta,Disco用来处理关于维基百科和维基共享资源图像的上下文数据[ 28]。
(4)Mars
Mars是一个GPUs上的MapReduce框架,包含了不同种类的Web数据分析如Web文档搜索(字符串匹配和倒排索引),Web文档处理(K均值、相似性评估和矩阵乘法)和Web日志分析(词频统计、网页访问计数和网页访问排名)等应用。由于Mars的编程接口是为图形处理而专门设计的,底层硬件比较复杂,造成用户编程难度较大,不利于其推广使用[ 20]。
| 表4 主要实现平台比较 |
表4显示了MapReduce不同实现平台,在使用难易程度、普及程度及应用领域方面的比较。这4种实现平台,除Hadoop外,其他实现都没有得到广泛应用。
现实世界很多实例都可用MapReduce编程模型来表示,MapReduce作为一个通用可扩展的并行处理模型,可有效地处理海量数据,不断地从中分析挖掘出有价值的信息。MapReduce封装了并行处理、负载均衡、容错、数据本地化等技术难点的细节,对于没有并行或者分布式系统开发经验的程序员而言,MapReduce库也易于使用。MapReduce编程模型已成功应用于多个领域,但是,当前有关MapReduce的研究主要集中在其应用上,对于算法及算法效率提高和优化等方面的研究较少,还有待于重视,以使MapReduce能更好地被应用。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|