


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
PLSA在图情领域专家专长识别中的应用
[张晓娟 , 陆伟, 程齐凯]
, 陆伟, 程齐凯]
, 陆伟, 程齐凯]
|
|


Based on the dataset of authoritative journal in the field of library and information science,this paper tries to apply Probabilistic Latent Semantic Analysis (PLSA) algorithm to process documents representing expertise,in order to locate the research areas of experts in this field. The experiment results show that this method is feasible and achieves good results.
进入21世纪,人类社会正由信息管理社会迈向知识管理社会。有效的知识管理不只是对文档中的知识进行管理,更需要对人们头脑中的知识进行管理[ 1]。在企业或组织中,了解“哪些人拥有哪些特定知识”是该企业或组织进行有效知识管理的重点。于是,一些企业或组织正在或者已经建立了专家检索系统。专家专长识别作为专家检索的一方面[ 2],是利用和创造知识的重要环节,引起了业界和学界的广泛关注。其中,专家专长识别的任务为:利用企业或者组织内外能够表征专长的各种文档或资源(如电子邮件、 报告、 数据库文件和网页等),根据专家名识别出其专长(主要包括个人的隐性知识如方法、知识、能力等[ 3],如研究领域、技能等)。由此可见,专家专长识别是基于文档的处理方法,是一种特定类型的信息检索方法。
概率潜在语义分析(Probabilistic Latent Semantic Analysis,PLSA)作为LSA的演化形式,利用概率模型来表示“文档-潜在语义-关键词”三者之间的关系,从而能够从语义层面而非单纯字面上去表达和理解文档,可有效解决词语之间的同义与多义等问题。该方法已被应用于信息检索、信息过滤、自然语言处理和机器学习等领域。
鉴于此,本文采用概率潜在语义分析方法来识别图书情报领域专家的专长,其中,所探讨的专家专长为专家的研究领域,即通过专家的研究成果(学术论文)来定位该专家所属的研究领域。
专家专长识别作为专家检索的其中一项任务,相对于另一任务(即根据专家专长返回专家名)来说,学界对此相关探讨较少。早期的专家专长识别方法主要通过专家本人描述自己的专长领域,并以此构建数据库,再利用传统数据库查询语言来识别专家专长,该方法的主要缺陷是专家参与的主观性以及对数据库的操作缺乏灵活性。于是,学者尝试通过分析专家产生的文档(如报告、会议记录、出版物等)以及这些专家所从事的一些事务(如网上行为)来识别专家专长,其常用的技术有社会网络标签分析、博客语义分析、本体技术分析等。如Budura等[ 4]认为用户所使用的一些社会软件在一定程度上能反应其专长,于是,通过从社会书签中选择该用户所使用的标签来识别专家专长;Dom等[ 5]通过专家之间的发送邮件关系来构建图,再利用Hits与PageRanks算法来识别专家专长;Tsai等[ 6]认为博客空间作为群体智慧和社会关系的重要来源,是网络用户展示专长知识和表达观点的场所,于是,以用户的博客内容为研究对象进行语义分析和概率建模,实现专长识别和意见挖掘;John等[ 7]通过对用户添加标签的行为进行社会网络分析,从而识别专家专长;Khan等[ 8]针对很难获取网络上有用信息的问题,提出一个基于 P2P的在线专家专长知识匹配系统,结合本体技术,利用 RDF语言存储专家专长,最终实现用户之间的知识共享;赵红斌等[ 9]借鉴文本自动分类思想,基于文档权重归并法,采用N元语言模型,构建了专家研究领域识别实验系统。
综上可知,目前并无统一的专家专长识别方法,而大多研究采用了其他领域的研究方法,但目前仍未有学者将PLSA相关算法运用到专家专长识别这一相关研究中。
PLSA是Hoffman[ 10]针对潜在语义分析存在的缺陷而提出的,即采用概率模型来表示“文档-潜在语义-关键词”三者之间的关系。首先做如下假定:一个文档集合 D={d1, d2,…,dM},文档集D中所有词组成的词集合 W={w1, w2,…,wN},文档集D中可能包含的潜在语义(即文章主题)集合Z={z1, z2,…zK}以及文档和词的共现频率矩阵C。其中,M表示数据集D中的文档个数,N表示文档集D中不同词的个数,集合Z中的主题个数K值需人工设定,矩阵C的元素ci,j(di,wj)表示词 wj 在文档 di中出现的频率。概率潜在语义分析假设文档和词之间的概率是条件独立的,并且潜在语义在文档或词上分布也是条件独立的。在以上假设的前提下,可使用式(1)来表示“文档-词”的条件概率:
p(d,w)=p(d)p(w|d)(1)
在“文档-词”条件概率中引入文档主题可得:
p(w|d)= 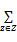
根据贝叶斯公式将式(2)转换为式(3):
p(d,w)= 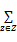
其中,p(w|z)表示潜在语义在词上的分布概率,通过对 p(w|z)排序可以得到潜在语义的一个直观的词表示;p(d|z)表示文档与潜在语义(即文档主题)分布概率。
概率潜在语义分析使用最大期望(Expectation Maximization, EM)算法对潜在语义模型进行拟合。在使用随机数初始化之后,交替实施E步骤和M步骤进行迭代计算。在E步骤中计算每个(d,w)对产生潜在语义z的先验概率,如下:
p(z|d,w)=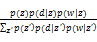
M步骤(使似然函数最大)使用式(5)至(8)对模型进行重新估计:
p(w|z)=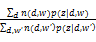
p(d|z) =
p(z)= 
R≡∑d,wn(d,w) (8)
当L期望值(见式(9))的增加量小于一个阈值时停止迭代,此时得到一个最优解,从而获得p(w|z)与p(d|z)的分布情况。
E(L)= 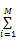
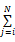
根据Song等[ 11]对专家专长(即专家的出版物质量和数量)的定义,将专家所发论文作为其专长证据的主要来源。考虑到因数据集过大而造成进行PLSA运算时迭代时间与存贮空间的开销太大,则需采用一些具有代表性的数据进行实验。另基于如下事实:期刊的级别越高,所收录的论文更能代表专家的研究方向。于是,本实验采用图书情报领域具有代表性的两权威期刊的论文数据作为实验数据集。
本实验以网络爬虫的数据采集方式从中国知网上下载《情报学报》和《中国图书馆学报》近30年的论文数据,并将采集的数据进行处理后存入本地MySQL数据库中,其字段包括:Title(标题)、Author(作者)、Address(地址)、Journal(期刊)、Year(年份)、Keywords(关键词)、Abstract(摘要)。存储数据共有6 564条记录,包括来源于《情报学报》的2 382条记录以及《中国图书馆学报》的4 182条记录,通过分析论文的摘要、关键词、题名来获得专家的专长信息。
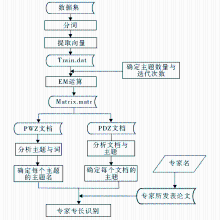
本实验的主要流程如图1所示:
 | 图1 实验总体流程 |
其主要思路为:对数据集进行分词处理,建立相关的词向量Train.dat,再利用PLSA的EM运算步骤对该词向量进行迭代,从而获得存有主题与词以及文档与主题之间关系的矩阵,通过对此矩阵数据进行解析,获得每个主题下词的分布情况,以及每个文档所属主题的情况,最后统计某专家所发表论文所属主题的频度,将频度高的对应主题定位为该专家的专长。其实验过程主要有三步:词向量构造、文档-主题-词分析以及专家专长识别。
(1)词向量构造
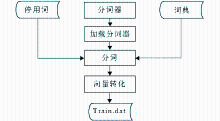
本实验的词向量生成过程如图2所示:
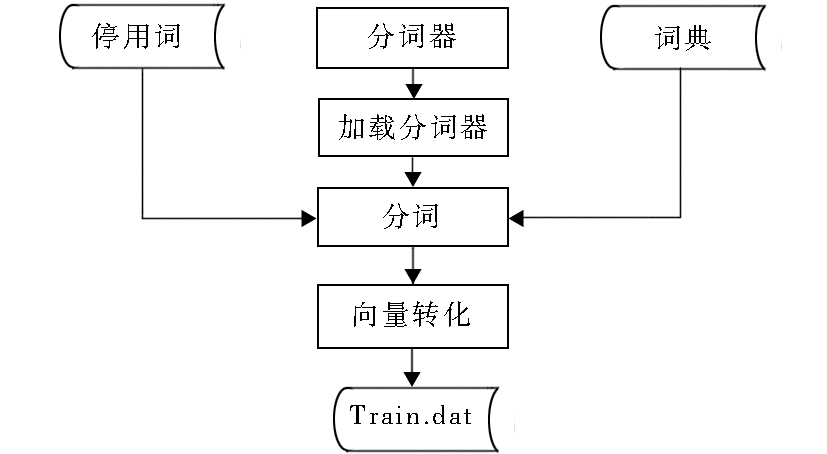 | 图2 词向量生成过程 |
首先对每篇文档(即数据库中的一条记录)中待处理字段进行分词以及去除停用词处理,再统计该文档中每个词在此文档中所出现频次,最后将其存贮在Train.dat中,其数据格式为:dj—w1:p1 w2:p2……wi:pi。其中,dj表示文档编号,wi表示该词在整个数据集中的编号,Pi表示该词在该文档中的出现频次。图3为Train.dat数据的具体存贮格式,每一行表示一篇文档的词信息。
 | 图3 Train.dat的数据格式 |
(2)文档-主题-词分析
当Train.dat生成后,调用PLSA中EM步骤迭代来获取存贮主题与词、文档与主题之间关系的Matrix.matr矩阵。考虑到迭代结果尽可能包含所有的主题以及迭代时所需要时间和内存空间开销,本实验将主题数设置为250,迭代次数设置为500。
①主题-关键词分析
从Matrix.matr中读取出主题与词之间的对应关系写入pwz.ser文件,得到每个主题下的词分布情况,且这些词按其在该主题下的权重降序排列,数据的存贮格式为:zi— w1:p1 w2:p2……wN:pN。其中,zi表示主题编号,w1表示词编号,p1表示词w1在该主题下的权重。图4为主题号为z145下的词分布情况。
 | 图4 主题z145下的词分布情况 |
考虑到某些主题下所分布词的权重过低,则这些主题并无太大的存在意义,本文通过设定词权重阈值为3.0E-4以此来筛选出此类主题,即当某主题下最高的词权重小于该阈值时,将其视为无意义主题。基于如下事实:即某一主题下权值越高的词越能表达该主题。选取每个主题下权值排名前5的词,再经过人工剔除与主题名无关的词如“作用”、“准备”等,以及词之间的顺序调换,以此来确定每个主题的主题名。对于无意义主题,并未对其进行主题名提取,最后得到的主题编号与其对应的主题名如表1所示:
| 表1 主题编号及其对应的主题名 |
因本文采用的数据集有限,则表1中的主题不可能包含图情领域所有的研究主题。本实验主要通过某主题下词权重来确定主题名,则提取出的主题名存在着概念粒度不一样以及概念之间交叉重叠现象,而本文主要考虑到主题名如何有效表达主题,则对此类现象并未进行深入探讨。
②文档-主题分析
Matrix.matr中也存贮了文档与主题的对应关系,通过对其解析,将分析文档与主题的对应关系并存贮在pdz.ser中。其格式为:di—z1:p1z2:p2……zN:pN。其中di表示文档ID,z1表示主题编号,p1表示该文档包含主题的概率。图5表示编号为190文档所包含主题的情况。
 | 图5 文档与主题之间关系 |
实验把每个文档下排在前三个主题作为该文档所属的主题,则文档190包含的主题为编号分别为28、73、7的主题。
(3)专家专长识别
| 表2 专家“邱均平”所发论文对应的主题号 |
专家专长识别的主要思想为:统计专家所发表论文的所属主题频度,将频度高的主题所对应主题名作为该专家的专长。本文以专家“邱均平”为例,其所发论文对隶属的主题如表2所示。经过统计表2中所出现主题的出现频次,排名前10的主题如表3所示,其中,将无意义主题统一标识为“*”。最后识别专家“邱均平”的专长如表4所示。
| 表3 出现频次前10的主题号及主题名 |
| 表4 表4 “邱均平”的专家专长 |
通过调查分析,网络信息计量学、知识管理、信息评价、文献计量学、信息经济学、信息分布规律都是该专家曾经或者现在的研究方向,而对信息素养未曾做过相关研究。
本文选取在《情报学报》和《中国图书馆学报》总发文超过5篇的30名专家作为评测对象,其中图书馆学和情报学各15名专家。因本实验的最终结果为:根据专家名返回与之相关的专家专长,其返回结果根据其相关性进行排序,故采用信息检索中的评测指标对专家专长识别结果进行评测,其选用的指标为P@N。另考虑到如下情况:一些专家的研究比较集中在两三个领域中,而另外一些专家的研究领域会更多,则本文分别统计了N=3、5、10这三种情况的实验结果。通过实验将每个专家名返回的专长识别结果反馈给相应专家,使其结合自己的研究领域对实验结果进行评价,最后统计每个专家专长识别结果的P@3、P@5、P@10值,再对这三个值分别求平均值,得到的评测结果如表5所示:
| 表5 实验评测结果 |
本文尝试将PLSA引入到专家专长识别中,并取得了较好的实验效果,证明了该方法的可行性。因本实验处于初探阶段,存在以下不足之处:
(1)数据集不全面。专家在学术领域的论文除了该领域的权威论文,其他核心期刊也收录了表征其专长的论文,这将会影响到专家专长识别的全面性,后期研究将会尽可能地从各种级别的期刊中全面获取表征专家专长的论文数据集。
(2)未考虑作者顺序。实际上,第一作者更能代表专家在某一领域的研究专长,而第二、三或者第四作者可能只表示某专家只是涉足某个领域,而并非一定从事该领域的研究,而本文未将不同顺序的作者进行区别对待。
(3)主题名的交叉重复。在为每个主题提取主题名时,只考虑到该主题名尽可能表达主题,而忽略了主题名之间的概念粒度以及概念之间是否存在交叉重复现象。
(4)对照实验的缺乏。本文只是停留在探讨如何将PLSA运用到专家专长识别领域,而该方法未与已有专长识别方法进行比较。
以上不足之处正是笔者后续工作将要深入研究的地方。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|