{kind=link}
FCA在医学领域文本分类中的研究和应用
[徐坤1 , 曹锦丹1  , 毕强
, 毕强2 ]
, 毕强|
|


在对文本分类技术和形式概念分析理论进行分析的基础上,针对医学领域文本的专业性特点,阐述利用形式概念分析进行医学领域文本分类的技术路线。通过中图法构建形式背景,进而生成概念格,利用概念格对领域文本进行分类,使分类效果接近人工分类。探索基于形式概念分析的医学领域文本分类的新途径。
Based on the analysis of text categorization and the theory of Formal Concept Analysis(FCA),this paper elaborates the text categorization method of using FCA according to the medical field text characteristics.It uses Classification of Chinese to construct the formal context, and generates concept lattices, which are used to classify the medical field text and make classification effect close to artificial classification.This paper explores a new approach based on FCA for medical text categorization.
网络给人们获取信息带来了方便,但随着信息爆炸式的增加,也给人们快速、准确地查找有用信息带来了困难,文本分类应信息检索的需求而出现。但由于各领域的需求不同,对所有文本进行分类是不可行的,想要取得好的效果,文本分类应该针对领域进行[ 1, 2]。医学领域文本更是具有其专业性特点,普通文本分类方法对医学领域文本分类效果不理想。本文针对医学领域特点,将形式概念分析和中图分类法(简称中图法)结合对医学领域文本进行分类,通过构建形式背景避免文本分类中中文分词的瓶颈问题。
(1) FCA理论在文本分类中的应用形式概念分析(Formal Concept Analysis,FCA)是德国的Wille[ 3]首先提出的一种通过形式背景进行数据分析的方法。用FCA分析据有如下两个优点:用二元关系表达对象之间的内在语义联系;能够用Hasse图直观地表达对象间的语义联系。
所以,FCA能够用于文本分类[ 4]。Hu等[ 5]、Wang等[ 6]介绍了应用FCA对文本进行分类的方法,主要步骤是:对文本进行预处理,抽取特征词;生成形式背景;进行文本相似度计算;选择文本分类算法;实现文本分类。
周顽等[ 7]给出了一种利用扩展概念来提取分类的规则,能够避免海量数据信息概念格构造变慢的问题,有效地利用FCA进行文本分类,取得了与KNN[ 8]、SVM[ 9]等成熟文本分类算法相当的效果。
(2)医学领域文本分类
随着医学研究的飞速发展产生了大量的生物医学知识,这些知识存在于各种形式的文本文件中。目前针对医学领域的文本分类多是由通用文本分类法修改而来的,其中以SVM方法取得的效果较好[ 10, 11, 12]。倪茂树等[ 13]提出了简单向量距离分类法,并通过实证取得了与SVM方法相当的效果。但是这些方法多是针对类似英文这样词与词之间有明确分界的语言,如果在像汉语这样词语没有明确分界的文本上应用,首先需要进行分词处理,由于中文分词对医学领域文本的效果不理想,直接影响了对医学领域文本的分类效果。目前专门针对中文医学领域文本的分类问题还未见有研究。
(3)主要工作
本文结合中图分类法,通过专家的领域知识,生成形式背景,选择建格算法构造概念格,并利用生成的概念格对文本进行分类。主要创新点包括:针对医学领域文献的特殊性设计了医学文本的分类方法;结合已有主题词表构造形式背景,避免了数据数量增多对概念格建格速度的影响;利用FCA和领域知识对领域文本分类,在避免受自然语言处理技术影响的同时可以保证较好的分类效果。
实际上,文本分类的类别间存在以层次结构组织的父子关系,形成树状或者更复杂的结构。而形式背景能很好地表达和处理这种结构。针对这一情况,本文把FCA引入文本分类系统,结合相关领域知识对领域文本分类进行研究。
FCA重视以人的认知为中心,提供了一种与传统知识表示和数据分析不同的方法,它建立在数学基础之上,根据相关语境构造出概念格,清楚地表达相关概念和其相互关系。本文选择中图法分类词表作为相关背景,通过专家参与初步构建出形式背景,在此基础上对文本进行分类,其具体过程如下:
(1)领域专家通过相关领域文本和知识,根据中图分类法构建形式背景;
(2)根据形式背景构造概念格;
(3)利用概念格对领域文本进行分类;
(4)通过专家干预优化分类结果,提取相关特征属性优化形式背景。
目前机器分类效果不理想,因此多数文献存储和开发机构多是采用人工干预文本分类,以保证分类的准确。人工分类之所以准确是因为人具有相关的知识背景,所分类别能被其他人所接受。鉴于此,本文结合中图法,由相关领域专家给出形式背景,构造相应的概念格对文献进行分类。中图分类法是由中国图书馆图书分类法编辑委员会编制的一部综合性的分类法,为国内图书馆和情报单位所使用,具有科学性和权威性。20世纪80年代美国图书馆界的相关研究证明,使用分类法有助于文本资源的分类和检索[ 14]。本文选择中图法R57消化系及腹部疾病作为形式背景,对相关文献进行分类。由于篇幅限制,这里只给出部分形式背景,如表1所示:
| 表1 胃疾病形式背景 |
通过对背景的分析,考虑到有些属性在文本中的作用和位置相近,可以对相关属性进行合并,在具体分类过程中以近义词林取代。如,消化道溃疡、胃溃疡、十二指肠溃疡可以合并成属性“上消化道溃疡”,而在匹配过程中三者只要出现其一就认为是匹配,当然可以根据出现的情况给予适当的权重。整理后的形式背景如表2所示:
| 表2 胃疾病整理后的形式背景 |
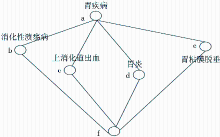
根据以上形式背景,采用渐进式的Godin算法[ 15]构造概念格,如图1所示:
 | 图1 胃疾病概念格Hasse图 |
通过分析概念格,得到如下概念,如表3所示:
| 表3 胃疾病概念表 |
其中,在概念a中包含形式背景的所有对象,属性为空,而概念f包含形式背景中的所用属性,对象为空。概念a为所构造概念格的最大概念,可以用来和其父概念相连,这里只选择胃疾病文本,所以其为顶级概念,而概念f为所构造概念格的最小概念,用来表示概念格的属性集。每个节点为一个概念,概念间的关系也通过节点之间的连接显现出来。
通过将相关文本与概念的属性匹配来对文本进行分类,根据隶属值来确定文本应该属于哪一类。因为各个概念具有多个属性,并且属性个数也不完全相同,而且属性在文本中出现的位置不一样其重要程度也不应该一样,因此,在考虑确定隶属度时必须要同时考虑这些因素。基于此,本文给出一个文本t与对应概念cj的隶属度计算公式:
S(cj,t)= 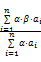
其中,n为cj包含的属性的个数;α为调整因子,当所匹配的属性处在不同位置或出现不同的次数时给予适当的权重;β为匹配变量,当所对应的属性ai在文本中有匹配时β=1,否则β=0。分式的分子是文本和对应概念的匹配值,分母是对此值进行归一化处理,即当文本特征项都不匹配时,S=0,当文本项完全匹配时,S=1,保证0≤S≤1。最后通过S与设定的阈值比较,确定文本属于哪一类。
本文先选取各类疾病文献每类10篇,通过领域专家选出特征项,生成形式背景,构造概念格。列举胃病部分分类结果,如表4所示:
| 表4 胃病文献分类表 |
规定隶属度S>0.58即可定义文本属于该类,所得结果与专家给出结果一致。扩大范围,从CBM数据库中选择300篇消化系统疾病的文献摘要作为测试对象,取S>0.50,得到效果如表5所示:
| 表5 文本分类情况表 |
在将200篇网络文本和专业文本放到一起分类时,分类效果有所下降,查全率和查准率都下降到60%左右。通过分析,找到网络文本与科技论文在用词上差别较大是产生分类效果不好的原因,下一步研究可以针对网络文本用词与医学科技论文用词的对应,构建近义词林,完善分类效果,使其应用范围更广。
在实际应用过程中,本算法能够避免自然语言处理的瓶颈问题,简化文本分类。同时也可以对已分类的文本进行自然语言处理,提出相关特征,加入形式背景,因为新加入的特征不会影响原来的概念,其加入只会使分类准确率提高。
医学领域文本专业性较强,需要具有专业背景的人才能对其有很好的理解,而FCA 是依赖于给定的对象对知识进行结构化的描述,通过FCA结合相关的领域知识生成形式背景相当于给计算机以专业知识,使计算机能更好地理解文本,使计算机处理文本分类接近于人的处理方式。本文以医学领域相关知识结合FCA对文本进行分类。在具体应用过程中,构建形式背景需要专家参与,当随着命名实体识别技术的提高,会减少构建形式背景中对专家的依赖;另一个重要因素是领域近义词林的构建和应用,直接影响到分类结果和分类方法的可扩展性,这将是下一步的工作。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|