

{kind=link}
{kind=link}
{kind=link}
一种利用Vague集理论改进的协同过滤推荐算法
[张慧颖1 , 薛福亮1, 2  ]
]
]
|
|


针对项目特征难以表达问题,提出采用Vague集理论对其进行提取与表示,在此基础上进行项目相似性聚类,利用聚类内项目相似性对未评分项目进行评分值预测,从而消除协同过滤推荐的稀疏性问题,进而基于预测后的评分矩阵进行相似用户聚类,并在项目聚类簇内实施协同过滤推荐,使推荐更有针对性。实验结果表明,该方法无论在推荐精度还是推荐相关性上都更为有效。
Aiming at the difficulty of project features expression,this paper brings forward to extract and represent it with vague sets theory.Then similar item is clustered to predict missing evaluation values of item, thus eliminating the sparsity problem of collaborative filtering recommendation. Based on the predicted rating matrix,similar users are clustered,and collaborative filtering recommendation is implemented in the space of item cluster to give more targeted recommendation. Evaluation results show that the proposed method is more effective both in the accuracy and in relevance of recommendations.
目前,推荐系统依据其采用的核心技术可以分为基于内容的推荐、协同过滤推荐和混合推荐。其中协同过滤方法对具有相似购物偏好的用户进行聚类,依据他们之间购物偏好的相似性进行交叉推荐。而基于内容的推荐则利用项目特征与用户购买行为特征的相似性实施推荐。如果用户对产品的评价信息非常完整,协同过滤推荐精度是非常准确的,而实际应用中因为数据的稀疏或者因为新产品没有足够的评价数据,会导致相似用户的聚类效果不佳,从而产生稀疏性以及冷启动等问题[ 1]。
国内外学者针对协同过滤的数据稀疏性问题提出了很多解决方法。最经典的是使用用户个人社会信息对基础数据进行补值[ 2],但这种方法可能会涉及到个人隐私;也有提出采用奇异值分解技术来缩减稀疏评价矩阵的维度,以消除评价矩阵的稀疏性[ 3],但可能会丢失有价值的数据。Web数据挖掘理论可以对服务器日志进行数据挖掘,从而发现用户的行为模式以获取隐性的用户评价数据[ 4],从而对稀疏的评价值进行补值;同时有学者提出利用神经网络去除稀疏性,进而进行聚类推荐的框架,该方法具有较好的稀疏性去除效果[ 5]。基于内容的推荐也不断加入了新的思想,如在基于内容的产品推荐中应用了模糊数学的思想[ 6],崔春生等[ 7]首次将Vague集思想应用到了基于内容的产品推荐中,提出了一种产品相似性度量的新方法。
协同过滤是最为成熟的推荐方法,其关键是消除评价数据的稀疏性。本文提出利用Vague集思想进行商品特征的提取与表示,并基于商品特征的Vague值数据进行商品相似度计算,进而得到相似产品的聚类簇,利用同一聚类簇内产品的相似性进行用户未评分商品的评分值预测并补值,从而消除用户评分矩阵的稀疏问题。消除稀疏性后的评分矩阵使得相似用户聚类簇更为准确,同一聚类簇的用户具有相似的购物偏好,从而进行交叉推荐。本文进一步提出将相似用户聚类簇与相似产品聚类簇相结合,即在相似产品聚类簇内基于用户相似性实施推荐,使得待推荐产品更符合本次购物偏好,从而使推荐更有针对性。
本文方法的核心思想共分为三个阶段,如图1所示:
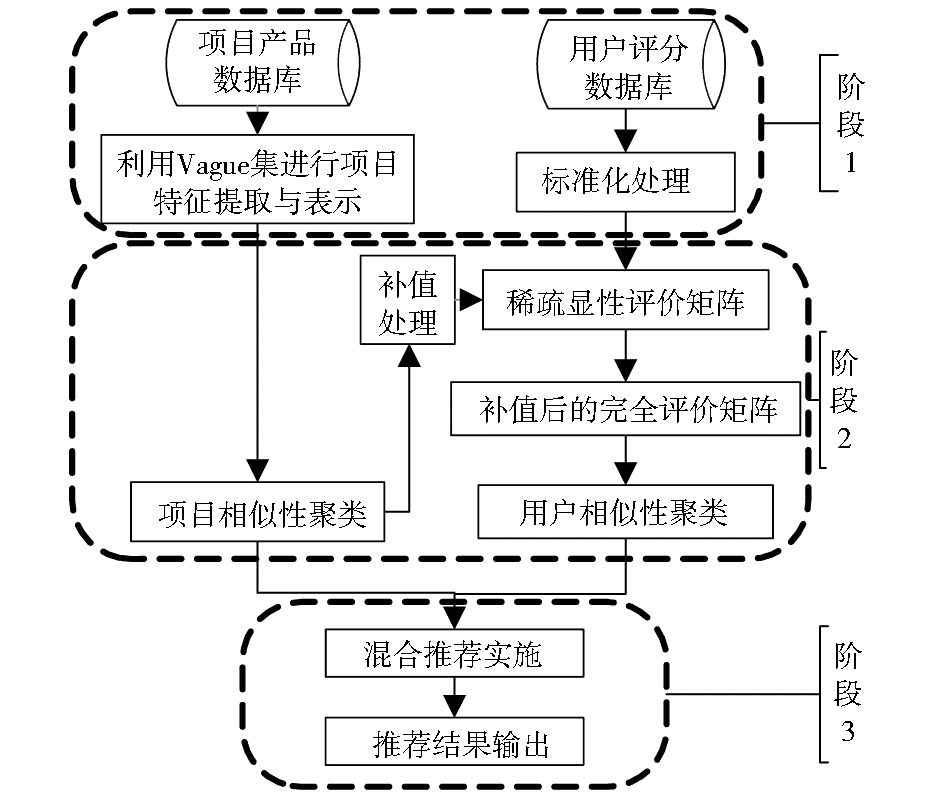 | 图1 推荐算法框架 |
(1)利用Vague集理论对项目数据库中的项目特征进行提取并对项目特征用Vague值表示,为项目相似性聚类提供保证。由于用户对项目的评分数据记录有限,因此得到的用户-项目评价数据是稀疏的。
(2)依据项目特征的Vague值来计算项目之间的相似性,并进行相似项目聚类,基于项目之间的相似性对稀疏的用户-项目评价矩阵进行补值处理,得到消除稀疏性后的完全评价矩阵。并依据完全评价矩阵进行用户之间的相似性计算与聚类,得到多个相似用户聚类簇。此处利用Pearson相关系数进行项目-项目及用户-用户之间的相似性计算,并利用K-均值聚类算法进行聚类簇的生成。
(3)利用同一相似用户聚类簇内用户购买偏好的相似性对同一项目聚类簇内的特征相似项目实施混合推荐,并向活动用户输出推荐结果。利用补值后的用户评价矩阵将会产生更精确的相似用户聚类。
Vague集是对模糊集的扩展,Vague集思想认为每个元素的隶属都可以分成支持和对立两个方面,也就是真隶属度和假隶属度,并且能够表示中立的程度,从而提出Vague集的概念。其成果对电子商务推荐系统有很好的借鉴意义。借鉴Vague的研究成果,利用Vague值进行商品特征的表示,可表达商品相对精确的接近程度,从而对相似商品进行聚类,并依据聚类内商品的相似性对未评价商品进行评分值预测。
本文所采用的符号作以下约定:
用Ij(j=1,2,…,n)来代表商品空间,n为商品数量。用X{x1,x2,…,xl}来表示商品的特征空间向量,l为商品特征属性数量。
用 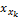
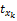
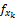


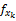
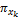


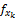
对项目特征进行提取与表示,以寻找与用户购物偏好相似的项目。依据Vague集理论,商品特征的提取与表示步骤如下所示:
(1)定义项目特征属性
项目有多个特征属性,如电影特征属性集合可表示为X={枪战,爱情,情感,伦理,恐怖,侦探,古装,…},可用xk表示为X{x1,x2,x3,…}。
(2)确定项目特征的肯定隶属度
依据xk与项目相关性程度降序排列。表示为X{x8,x5,x3,…},第8个属性相关性最高,其他依次降低。定义 
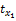
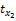
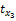
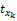
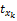

其中,|Lj|表示商品的特征数量,rk(1≤rk≤|Lj|)表示特征xk所在的排序位置。α>1是需要确定的常数,其会影响到取值的连续性。如电影I1有5个特征{枪战,爱情,情感,伦理,恐怖},分别表示为:x1,x2,x3,x4,x5。取α=1.25,运用Gaussian函数得到: 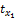
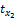
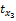
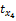
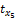
(3)确定项目特征xk的未知度
商品特征的未知度应以中间值为中心成对称分布,项目最重要特征未知度取值为0,项目所有特征未知度应满足: 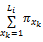
(4)Vauge值表示项目特征
由1- 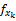
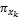
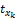
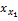
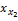
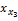

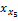
项目Ij特征采用Vague集理论提取与表示后,基于项目Vague值可进行项目相似性计算。依据文献[8]的研究,项目Vague值相似性的计算公式如下所示,其中l为产品特征数量:
simI(I1,I2)=1- 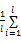

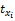
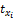

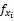


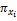
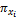
依据Vauge值表示,对项目之间相似性计算可得到项目相似性矩阵。基于项目相似性矩阵可利用K-均值聚类算法[ 9]进行聚类,方法如下:
输入:项目相似矩阵,
输出:k个聚类簇[clusIk={相似项目集合}]
方法:
①从 n个项目中依据simIi,j值,鉴定Top k个相似项目作为k个聚类簇的初始聚类中心。
②根据每个聚类的均值,依据每个项目simIi,j值计算其与聚类中心的距离;并根据最小距离将项目归入相应聚类簇中。
③重新调整聚类簇中心值(中心项目)。
④对M个用户循环计算步骤②和③,直到每个聚类不再发生变化为止。
用户-项目评价矩阵是一个稀疏的评分矩阵,基于上述产品聚类簇内产品之间的相似性对其进行补值处理。发现项目评分值的准确性依赖于对其进行评分的用户的数量,数量值越大评分相对越准确,为了提高预测准确度,使用调和权值因子来调和被不同用户数量评分的项目对预测值的贡献。调和权值因子如下:
ωmi,j=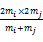
mi=
此处ni为评价项目mi的用户数量。则某用户u对项目i的预测值Pu,i可用以下公式计算得到:
Pu,i=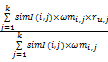
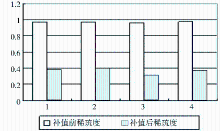
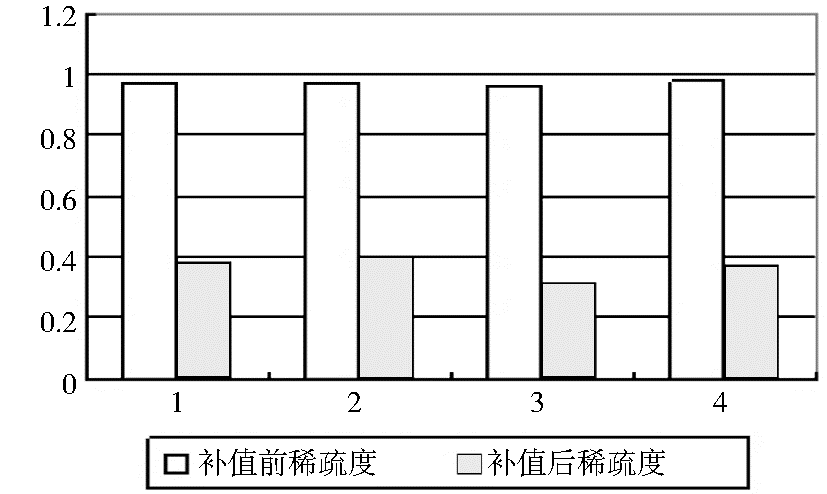
其中,k为聚类内与i最相近的k个项目。ru,j为用户u对相近项目j的评分。利用Pu,i对稀疏用户矩阵进行补值处理可得到完全用户-项目评分矩阵r'ij(消除稀疏性后的评分矩阵)。
输入:补值后的完全用户项目评分距阵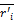
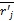
输出:k个聚类簇[clusk={相似用户集合}]
方法:
①for i=1 to M /*计算M个用户之间的相似性*/
②sim_count(i)=0
③for j=1 to M
计算用户i和j的Pearson相关系数simUi,j
if simUi,j=1 then
sim_count(i)=sim_count(i)+1
④鉴定top k个相似用户作为k个聚类簇的初始用户
⑤将用户归入相应聚类簇中
⑥对M个用户循环计算步骤③-⑤
整个用户集合空间划分为若干个具有相似购物偏好的聚类簇C={c1,c2,…,ck},对于聚类簇内某用户u可以调节聚类内用户顺序,使得c1 与u 的相似性sim(u,c1)最高,c2 与u 的相似性sim(u,c2)次之,依此类推,依据相似性程度得到目标用户的最近邻居。设用户u 的最近邻居集合用NBSu 表示。当用户对某个项目表现出兴趣,则依据相似项目聚类簇,在其最相似项目空间内进行评分预测。用户u对项目i的预测评分 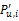
P'u,i=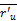
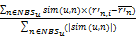
其中,sim(u,n)表示用户u 与用户n 之间的相似性,r'n,i 表示用户n 对项目i 的评分, 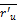

MovieLens提供的推荐系统测试数据集为公开数据集,是一个基于Web的研究型推荐系统。借鉴其公开的评分数据集,将测试记录分为训练集和测试集,训练集和测试集比重为[80%,20%]。目标用户选择在训练阶段和测试阶段都至少有一次交易记录的用户。在训练集数据空间内进行数据预处理与推荐修正,在测试集空间内实施推荐,并将推荐结果与实际用户购买行为进行比较度量。
准确率(Precision)和召回率(Recall)两个指标通常被用来度量推荐质量,准确率的定义是推荐的项目除以总推荐项目;召回率是推荐的相关项目除以总相关项目(应当检索到的)[ 8]。由于准确率和召回率一定程度上是一对相互矛盾的指标,为了平衡两者,可用平均绝对误差(MAE)来评价预测结果与最终结果的接近度,如下所示[ 10]:
MAE=
其中,M、N、pij、rij分别代表用户数量、项目数量、用户i对项目j的预测评分和用户i对项目j的实际评分。
本文提出利用Vague值进行项目特征提取与表示,利用项目之间的相似性对未评分项目进行预测补值,从而消除评分矩阵的稀疏性,使相似用户聚类效果更好,在相似项目空间内实施推荐,使推荐更有针对性,同时降低了计算复杂度。实验研究表明系统推荐结果比简单协同过滤和奇异值分解协同过滤算法效果要好很多。Vauge集理论提供了一种新的产品特征度量方法,降低了协同过滤推荐中的稀疏性问题,但对协同过滤存在的冷启动、可扩展性等问题却无法解决,这将是下一步研究的重点。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|