
{kind=link}
{kind=link}
{kind=link}
基于维基百科的中文短文本分类研究
[范云杰 , 刘怀亮]
, 刘怀亮]
, 刘怀亮]
|
|


针对中文短文本自身词汇个数少、描述信息弱的缺陷,引入特征扩展的方法辅助分类。借助网络知识库维基百科抽取相关概念,并采用统计规律与类别信息相结合的方式计算概念间相关度,建立语义相关概念集合,对短文本的特征向量进行扩展,从而有效补充短文本的语义特征。对比实验表明,基于维基百科的短文本分类方法能够提高短文本分类的效果。
According to the characteristics of Chinese short texts, a method of feature extension is introduced to help text classification. Firstly, related concepts are extracted from Wikipedia and concept associativity is calculated based on the combination of statistical laws and categories. Then the semantic related concept sets are built to extend the eigenvector of short text in order to supply its semantic features. The contrast experiment shows that the algorithm of short text classification based on Wikipedia can get a better classified effect.
互联网的快速发展催生出大量的书评影评、网络聊天、产品介绍等形式的短文本,其包含大量有价值的隐含信息,对人们的日常生活产生了很大影响,所以迫切需要一些自动化工具对短文本进行分类处理。与长文本相比,短文本的长度通常小于160个字符,词汇个数少并且描述信息弱,具有稀疏性和不规范性,传统的文本分类方法不能很好地满足短文本分类的需要[ 1]。国外研究学者先后提出使用相似度[ 2]、Web核函数[ 3]、频繁词集挖掘[ 4]、潜在语义索引[ 5]等多种方式进行短文本分类,但其精确率和召回率未达到满意的效果。近年来国内学者将特征扩展思想引入短文本分类研究中,即引入额外的信息挖掘短文本所表达的含义来辅助分类。王鹏等[ 6]利用依存关系抽取词扩充短文本特征,王细薇等[ 1]利用关联规则挖掘训练文本中的共现关系,构建特征共现集作为扩展词表,但这两种方法需要处理大规模背景语料,费时费力;宁亚辉等[ 7]借助知网提出基于领域词语本体的短文本分类方法,王盛等[ 8]利用知网的上下位关系有效补充了短文本语义信息量,但知网由专家编撰词典,只包含小范围的领域和主题,词汇更新速度慢、可扩展性差,很难适应互联网用户用词新颖化、专业化的特点。
因此,本文提出的短文本分类方法将维基百科作为特征扩展的来源知识库。维基百科是目前全世界最大的多语种、开放式的在线百科全书,采用群体在线合作编辑的Wiki机制,具有质量高、覆盖广、实时演化和半结构化等特点[ 9],可以有效克服人工编纂词典的不足。该方法从大规模网络知识库维基百科中挖掘词汇潜在的语义信息,量化词汇间语义相关关系,建立语义相关概念集合,从而扩展短文本的特征向量,在一定程度上可以弥补短文本描述信号弱的缺陷。
概念是维基百科基本的组成单位,每个概念由一个特定页面描述,页面的开头对该概念进行基本的定义和解释,称之为定义句。定义句中包括了指向其他页面的链接,其构成的链接结构反映了概念间丰富的事实关联关系。每个页面属于至少一个维基类别,类别间形成的树状结构直接描述了概念所属类别间的上下位关系[ 10]。另外,维基百科中还大量存在词义消歧页面,能够有效地识别多义词。
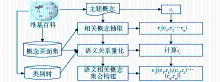
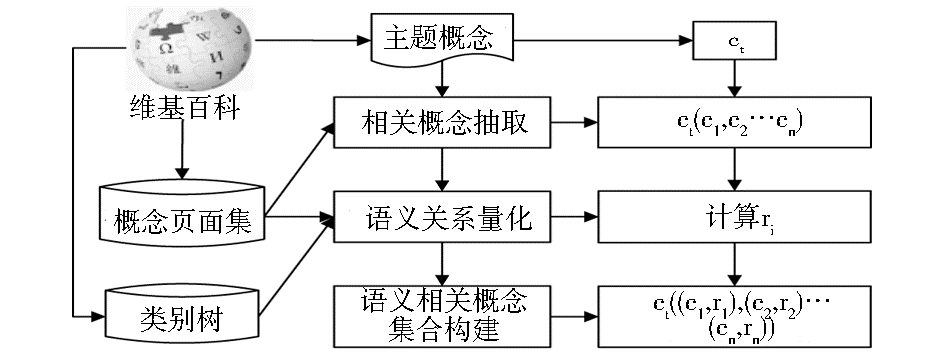
维基百科中语义相关概念集合的构建过程如图1所示:
 | 图1 维基百科中的语义相关概念集合构建过程 |
从维基百科中抽取概念的描述页面和类别之间的关系,建立XML结构的页面集和树状的类别树,通过语义相关概念抽取、相关关系量化,建立相关概念集合,找到一个概念的相关词汇并量化相关关系,为扩展短文本分类中的语义信息奠定基础。
如果概念ct的定义句利用超链接引用了概念ci,说明概念ct与ci间存在某种重要的语义关系或事实联系,从而可以构建一个与主题概念ct相关的概念集合ct(c1,c2,…,cn),ci为ct定义句中抽取出的链接指向的概念,称之为相关概念,n为链接个数。
对于具有多个含义的概念,与不同含义关联的相关概念必然不完全相同。依赖维基百科的词义消歧页面,分别挖掘不同含义页面的相关概念,并标注语义标签。如“苹果”,它既可以指一种水果,又可以指电脑生产厂商,对应的语义相关概念集合分别为:苹果<水果>(植物,果实,维生素,水果,……);苹果<电脑>(电脑公司,iPod,iPhone,美国,……)。
语义相关概念集合中的相关概念与主题概念的关联程度不同,对语义信息的补充能力也不同,所以要对这种关联关系进行量化,计算主题概念ct与每个相关概念ci的相关度。计算相关度常用的方法包括两类:分布式方法是对语料库进行统计分析,以此来判断两个词的上下文相关程度;结构化方法是在资源形成的具有联通结构的概念化体系中利用结构特点或者信息量来计算[ 11]。本文将这两种方法的思想相结合,既考虑概念之间在定义句中的统计规律,又利用概念在类别树的深度量化概念间的相关关系。
(1)统计规律
维基百科中每个概念的描述页面是由人工编纂完成的,这个过程实际上包含了人们对知识的感知,编写人员会对每个概念进行反复的判断和推敲,所以页面中往往包含了关于该概念的较准确的语义信息。如果相关概念ci在主题概念ct的描述页面出现的次数越多,说明ci对ct的解释能力越强,与ct的相关关系就越明显。用TF-IDF方法来衡量概念ci与ct描述页面的关系,其中TF定义为ci在ct描述页面中出现的频率, IDF表示反文档频率,一般采用IDF=log(N/ni)。N表示维基百科知识库中的页面总数,ni表示出现概念ci的页面频数。但由于维基百科内容浩大,截止到2011年11月,共包含387 332篇中文页面[ 12],计算出现ci的总页面个数ni过于耗时,所以本文用ci的入链个数来近似代替nj值[ 13]。ci的入链是指其他网页指向ci页面的链接,入链越多说明ci被其他概念引用的次数越多,对主题概念的影响相对越小。则基于统计规律的相关度计算公式可以表示为:
Rs=TFi·IDFi=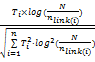
其中,Ti表示概念ci在主题概念ct描述页面中出现的次数,N表示维基百科知识库中的页面总数,nlink(i)表示ci的入链个数。为防止描述文本长短不一对TF值带来的影响,采取归一化的处理方式,n表示ct的相关概念个数。
(2)类别信息
维基百科中属于同一个类别的概念要比不同类别的概念有更近的语义关系。比如对于“基因”这个概念的定义句“基因一词来自希腊语,是指携带有遗传信息的DNA序列……”,可以从中抽取出相关概念集合:基因(希腊语,遗传信息,DNA……)。显然,根据人们对自然世界的感知,基因和希腊语的相关关系远远低于与DNA的关系,这是由于希腊语属于“语言”这个类别,基因与DNA同属于“遗传”类。可见,在相关关系权重的度量中应加入概念的类别关系。
维基百科中的类别可以形成近似的树状结构,在树状结构中,两概念距离最小公共父类越远,相关关系越小。基于类别信息对相关度计算公式的改进为:
Ri=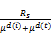
其中,d(i)和d(t)分别表示概念ci和ct在最小公共父类下的深度,μ为可调节参数,μ值越大则类别信息对相关度的影响越大。
综上步骤,构建形如ct((c1,r1),(c2,r2),…,(cn,rn))集合,并依照相关度大小对相关概念进行排序。集合中会出现一些相关概念,其相关度很小,可以认为它与主题概念的相关关系不明显;另外,集合的过于冗长会大大增加后续文本分类时特征空间的维度,造成维度灾难。故设立阈值λ,将相关概念的个数控制在λ以内。如λ取4,公式(2)中的μ取2时,“基因”这个概念的语义相关概念集合可以表示为:基因((DNA,0.33),(蛋白质,0.29),(染色体,0.11),(体细胞,0.03))。
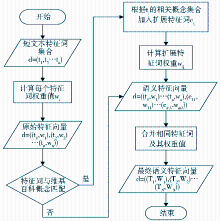
短文本分类与传统文本分类类似,包括训练和分类两个过程,如图2所示:
 | 图2 短文本分类过程 |
对训练文本进行预处理,提取表征文本的特征词,对提取的特征词利用维基百科进行语义扩展,将文本表示为由原始和扩展特征词及其权重表示的特征向量;对测试文本用同样的思想进行扩展处理,生成语义特征向量;利用KNN算法判断其所属类别。
中文文本的预处理过程包括分词和去停用词两个步骤。分词过程一般采用分词软件,将得到的词条作为文本特征提取的基础。由于自然语言中不断有新词出现,已有的分词软件不能准确地识别出文本中所有的新词[ 14],另外为便于利用维基百科进行相关概念的语义扩展时能够准确识别待扩展的主题概念,因此在处理切分时需要对分词软件进行改进,将维基百科概念词条加入词库,并设置长匹配模式,即如果一个 m-gram 概念词条被一个 n-gram 词条概念包含(n>m),且 n-gram词条涵盖所有m-gram词条的单词时,只将抽取的n-gram词条概念纳入到候选集合中[ 10]。例如,“机器学习”这个词,原始的分词系统会分为“机器”和“学习”两个词,显然丢掉了原始的含义,本文的分词方法使得分词结果尽量和维基百科的概念相符合。
去停用词的目的是消除短文本中存在的大量的高频但无意义的词语,用中文停用词表过滤这些噪音干扰,只保留汉语句子的核心部分包括名词、动词、形容词、副词作为能够表征文本的特征词[ 15]。
文本经过预处理后,一般采用基于向量空间模型(Vector Space Model)的文本表示方法。由于短文本字数少,容易造成向量空间的语义缺失和高维稀疏。将经过文本预处理后提取的特征词映射为维基百科概念,并利用语义相关概念集合补充特征词以完善文本的语义特征,对这些特征词进行消歧和权重计算,从而构建语义特征向量。将短文本表示为最终的语义特征向量的流程如图3所示。
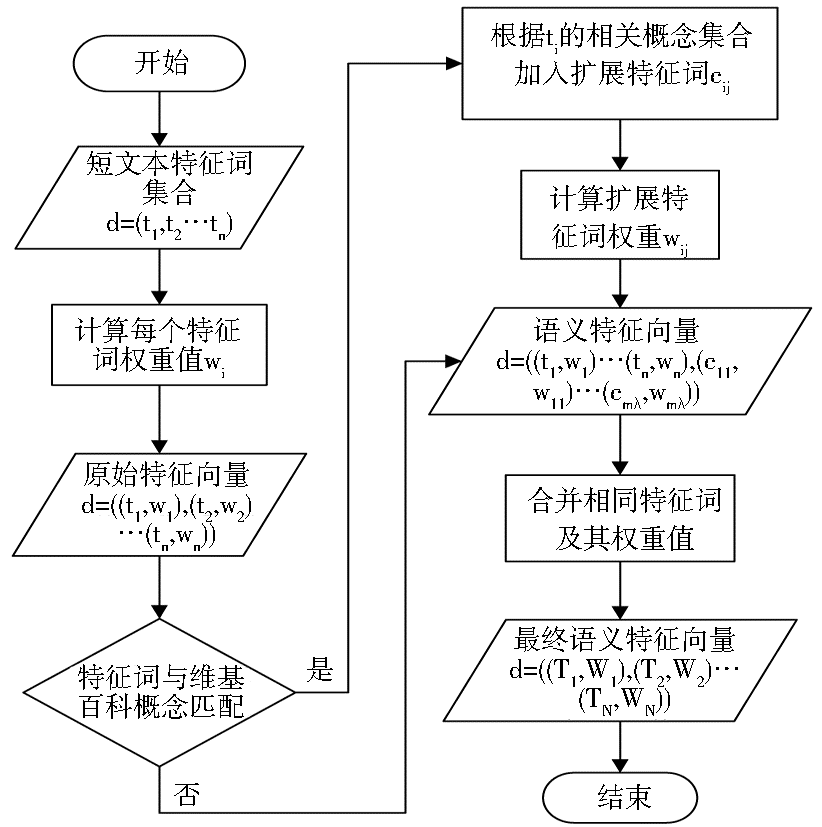 | 图3 短文本的特征词扩展流程 |
详细过程描述如下:
(1)将短文本表示为原始特征向量。利用经过预处理过程提取出的n个特征词,将测试文本表示成由一个二元组d=((t1,w1),(t2,w2),…,(tn,wn))构成的向量,其中ti表示第i个特征词,wi表示该特征词的权重。词的权重一般采用TF-IDF的计算方法。
(2)扩展文本特征向量。将短文本特征向量中的特征词与维基百科中的概念相匹配。如果特征词ti在维基百科中有对应的概念ct,则建立该特征词对应概念的语义相关概念集合ct((c1,r1),(c2,r2),…,(cn,rn))。这时,ti可看作主题概念,其相关概念集合中的所有概念即为新加入特征向量的特征词。当ti具有多个含义时,将被不同语义标签标注的主题概念对应的相关概念与特征向量中的所有特征词进行比对,相同的词越多说明该主题概念越贴近其在文本中的真实含义,则选取该主题概念与ti相匹配。若特征向量中前m个特征词能够与维基百科概念相匹配,则短文本被表示为:d((t1,w1),…,(tn,wn),(c11,w11),…,(c1λ,w1λ),…,(cmλ,wmλ))。其中,ti为原始特征向量中的特征词,cij为第i个特征词ti的相关概念集合中第j个概念, wij为特征词权重,λ为语义相关概念集合中概念的个数。
(3)计算扩展特征词的权重。权重代表了特征词表征文本的能力,而相关度代表了概念对另一个概念的解释能力,所以扩展特征词的权重既要考虑其主题概念在原文中的重要性,又要考虑与主题概念的相关关系。扩展特征词的权重值计算如下:
wij=wi·rij (3)
其中,wi为被扩展特征词ti的权重,rij为ti的相关概念集合中第j个概念cj的相关度。
(4)合并相同特征词。由于特征词之间往往有丰富的语义联系,可能会出现扩展特征词与原始特征词相同或者扩展特征词之间有重复的现象,这时需要合并相同的特征词,并将它们的权重相加求和,最终形成语义特征向量d=((T1,W1),(T2,W2),…,(TN,WN))。
本文采用KNN分类算法,将测试文本的语义特征向量与训练过程产生的文本向量集进行相似度计算。设sim(i,j)表示第i个向量与第j个向量的相似系数,则采用余弦系数(Cosine Coefficient)表征的文本相似度计算公式为[ 16]:
sim(di,dj)=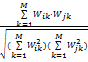
其中,di表示训练文本,dj表示测试文本,M表示向量空间的维数,Wik、Wjk表示文本向量对应特征词的权重。将计算得到的相似度值按降序排列,选取排在最前面的K篇训练文本,即K个最近邻居,将属于同一个类的文本的相似度相加求和,将该测试文本归到相似度和较大的那个类中,作为最终的分类结果。
对实验分类结果的性能采用如下三个常规性能指标进行评估:
精确率(Precision,P):
P=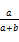
召回率(Recall,R):
R=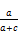
F1值(F-measure,F1):
F1=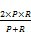
其中,a表示被正确分到某类的文档数,b表示错误分到该类的文档数,c表示属于该类但被错分的文档数。
本文从维基百科网站下载中文版XML数据集,其版本是zhwiki-20110805,包含30多万个概念页面,建立的类别体系结构中包含2万多个类别。经处理,去掉维基百科特有的冗余信息(如“维基索引”、“维基分类”、“相关人名列表”……)以及年代名词(如“1980年代”、“1975年”……),提取236 646个具有实际意义的概念。
实验的语料库为新浪、腾讯等各大网站的不同类别跟帖中的评论,选取其中60 000个短文本语料,涉及财经、军事、体育、娱乐、社会以及科技6类。平均每类10 000个语料,其中8 000个短文本作为训练集,2 000个作为测试文本。
实验分为两组:第1组采用传统的文本分类方法,即未进行特征扩展;第2组采用本文提出的短文本分类方法。实验中使用中国科学院的ICTCLAS进行分词,并将维基百科中提取的概念加入分词词典,概念的相关度计算公式(2)中μ值取2,语义相关概念集合的阈值λ值取4,KNN分类算法中的K值取30。实验结果如表1所示:
| 表1 实验结果比较 |
通过实验结果可以看出,经过基于维基百科的特征扩展,短文本分类结果较传统分类方法的精确率、召回率和F1值都有所提高。说明利用维基百科寻找特征词的相关词汇,并扩展到特征向量中,能够从语义层面上对短文本隐含的信息量进行挖掘和补充,从而提高短文本分类的效果。
本文引入特征扩展的思想,提出一种基于维基百科的中文短文本的分类方法。该方法利用维基百科中概念间的链接关系建立词汇的相关概念集合,并基于概念的描述页面和类别树计算主题概念与其相关概念的相关度。在短文本分类过程中,针对短文本长度短、所描述概念信号弱的问题,利用相关概念集合对短文本进行特征扩展。实验证明本文提出的这种短文本分类方法,能够提高文本分类的效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|