




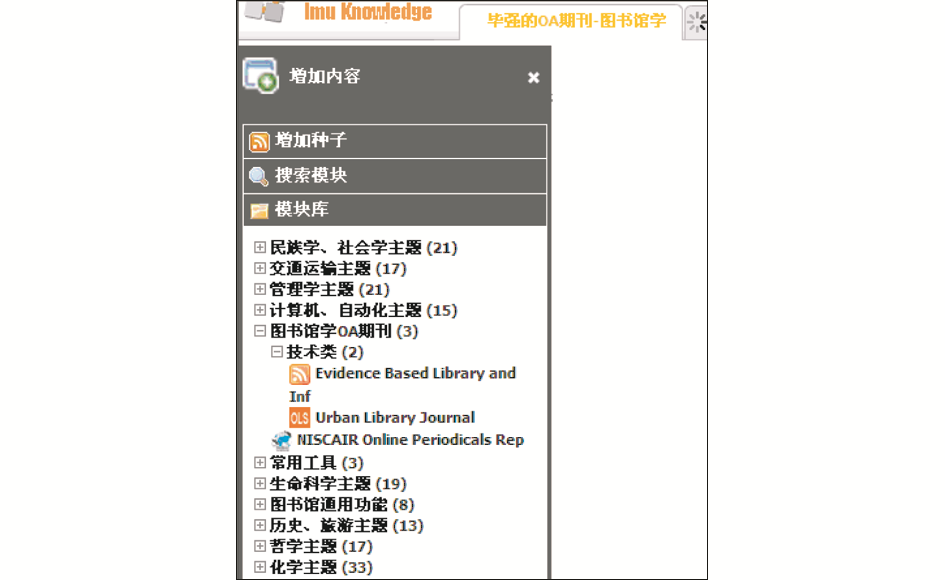


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于领域本体和RSS的OA资源集成门户设计与实现
[毕强1  , 鲍玉来
, 鲍玉来1, 2 ]
, 鲍玉来|
|


This paper presents a model of OA resources, which is a personalized semantic portal. It uses FCA methods to process and analyze the knowledge content of OA resources, then constructs an Ontology-based knowledge structure of OA resources,and builds a RSS feed to realize semantics access and push of OA resources.
越来越多有价值的OA资源为研究人员获取学术资源提供了一条崭新的途径。由于OA资源是分布式地存在于互联网上众多的异构数据源中,因此用户很难直接全面地检索到这些资源,很大程度上制约了OA资源的利用。从用户的信息需求和信息检索角度出发,建立充分揭示OA资源并能为用户提供一站式检索服务的门户,是提高OA资源利用率和推动OA运动的重要途径。
近年来,学术界对于OA资源的整合检索的研究主要集中在三个方面:
(1)元数据整合方式,通过OAI-PMH或者其他方式获取OA资源的元数据,集中存储并提供检索;
(2)基于网络爬虫技术的整合方式,通过网络爬虫技术抓取、解析和索引OA资源[ 1],集中存储并提供检索;
(3)基于EAI(Enterprise Application Integration)的跨库实时检索机制[ 2]。
尽管上述研究取得了一些研究成果,但是其提供的检索仍然是以关键词匹配为基础,结合布尔运算构造查询表达式的传统方式,没有将OA资源的检索提升到语义检索的层面。
在基于本体知识结构的RSS应用研究基础上[ 3],笔者以概念格理论为基础对OA资源的领域本体构建进行了探索[ 4],建立了基于领域本体知识结构的RSS(Really Simple Syndication)种子生成机制,并通过对开源门户平台的改造,实现了一个基于语义检索与聚合的OA资源门户系统。
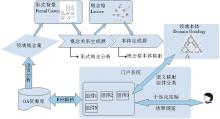
系统主要由概念关系生成器、本体生成器、RSS 处理器和门户容器等几个主要部件构成,如图1所示:
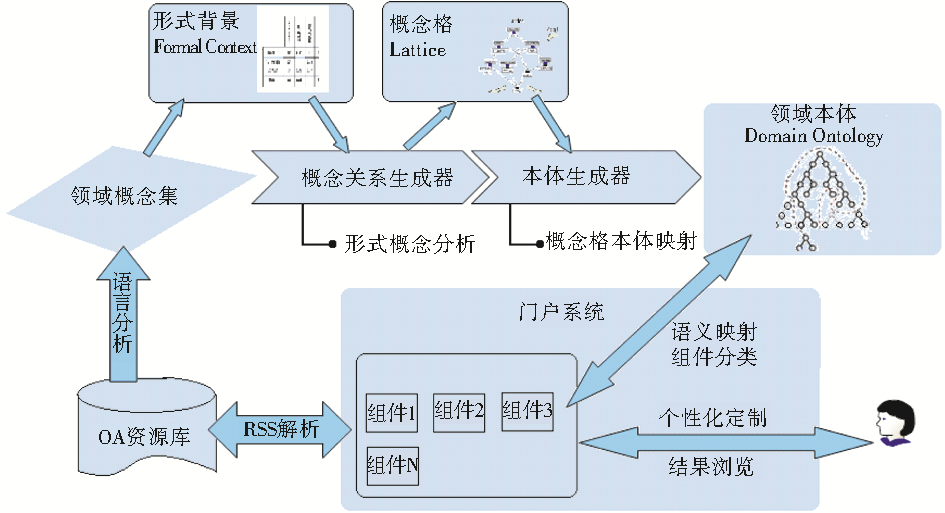 | 图1 系统结构图 |
系统通过对OA资源的语言分析获取领域概念集和形式背景,通过概念关系生成器和本体生成器来构建基于形式概念分析的领域本体。门户系统通过领域本体来进行RSS组件的分类组织,通过语义映射获取相关的概念及实际检索词,进而生成RSS种子,通过解析RSS种子从OA资源库中获取组件的内容。用户通过定制相关的组件,搭建个性化的门户页面。
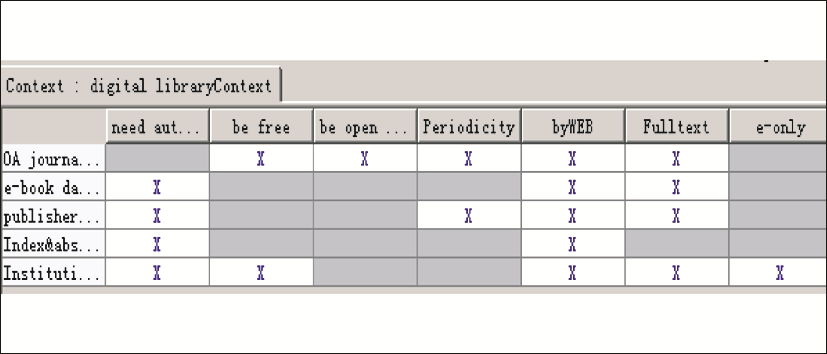
本文选取DOAJ中关于Digital Resources的文章20篇作为样本空间,应用Stanford Parser对其进行统计分析,分别得出了两个系统的关于Digital Resources的概念集。
利用Stanford Parser针对Digital Library文献中关于Digital Resources 概念和属性的提取和形式化处理,得到了 OA Journal Database、Publisher Journal Database、Index & Abstract Database、Institutional Repository等几个对象,获取了 be Free、be Open Access、Authorize、by Web、Periodicity、Fulltext、E-only等形式背景。
在概念格的基础上建立领域本体,这项工作由本体生成器来完成。本体生成器通过基于OWL的语义表述,自动生成一个领域本体[ 5]。生成原理如下[ 3]:
(1)类映射
为概念格中的每个对象映射一个本体中的对象。通过概念的内涵和外延模糊背景分析,来构建适当的本体类。在这个过程中,需要人工对自动映射生成的本体类标签进行修正。在本文中最高层次的概念应该标识为“Database Resources”,而自动映射则会标识为“Concept_1”。
(2)层次映射
层次映射是通过分析,用相应的谓词来描述概念间的关系。在本文中所有的对象与上位概念“Database Resources”都是子类的关系,这种关系的表述谓词是“rdfs:subClassOf”,在OWL类的定义中,“E-journal”是“Database Resource”的具体化(Specialization)。
(3)关系映射
概念的内涵(在形式背景中的一系列属性)到本体属性的映射。在本文中,就是将“be Free、be Open Access、Authorize、by Web、Periodicity、Fulltext、E-only等形式背景”映射为本体的属性。
(4)生成本体
作为本体构建的最后一步,此步骤将根据上述三个层次的映射,生成既包含概念格中全部概念、又包含概念关系谓词描述和属性的领域本体实例。
(5)构建本体映射知识表
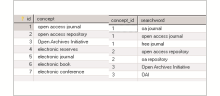
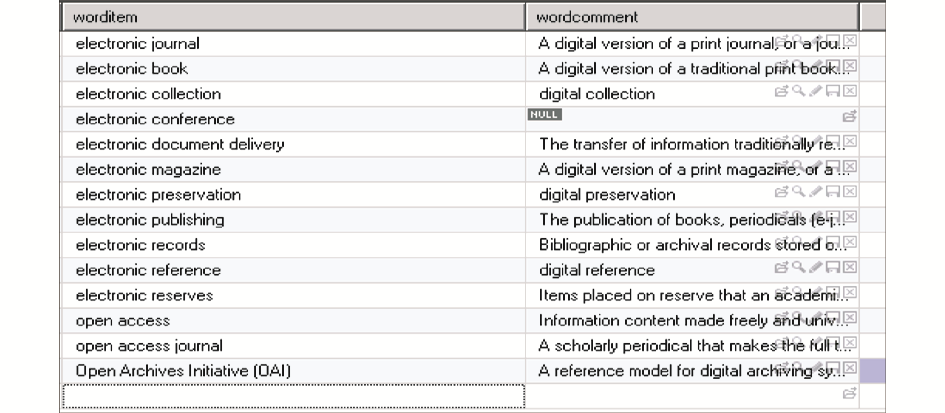
在基于一定量的OA期刊文章的语言分析统计基础上,建立概念集对应的叙词字典,如图2所示:
将获取的概念集与文本中实际出现的用词根据词频等指标建立映射字典,在这里称之为知识映射表,如图3所示,主要功能是将本体查询转化为针对某个数据源应用的关系型数据库的检索。本文中概念“Open Access Journal”在知识表中对应“OA Journal”、 “Open Access Journal”、“Free Journal”等检索词。
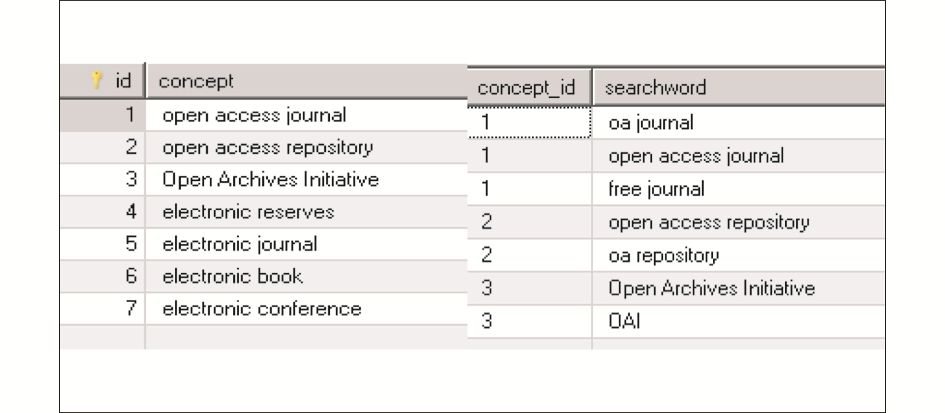 | 图3 知识映射表 |
(1)语义检索
根据用户在门户中的定制请求,即用户为其门户页面选取的领域知识主题词,通过上述本体构建的过程中预定义相关的语义规则,进行本体语义查询,检索和推理出用户门户主题词具有语义关联的语义查询条件。在这个过程中利用了SPARQL(Simple Protocol And RDF Query Language)来进行本体查询。SPARQL是为RDF开发的一种查询语言和数据获取协议,它是为W3C所开发的RDF数据模型所定义,但是可以用于查询任何可以用RDF来表示的信息资源[ 6]。
在语义检索条件生成后,通过本体知识映射表将语义查询条件映射成一组关系型数据库(本文使用MySQL)的SQL语句,实现对具体OA期刊源的检索,并将结果通过RSS种子生成工具进行处理,使得检索结果符合RSS 的格式标准。通过构建RSS种子,可以将用户通过领域本体的定制的概念,转化为一个或者多个实际的RSS种子,在门户中实时地将结果推送给用户,实现语义推送的功能。
(2)RSS解析
网络用户可以在客户端借助于支持RSS的聚合工具软件(例如SharpReader,NewCrawler,FeedDemon),在不打开网站内容页面的情况下阅读支持RSS输出的网站内容。而本文要实现RSS的在线阅读,并将RSS阅读集成到门户系统中,使得每个RSS种子都对应一个门户组件(Widget)。
(1)门户平台选择
本文选择了Posh作为门户平台,它是一个开源个性化门户平台,其用户体验类似Netvibes、iGoogle等平台[ 7];并采用PHP/MySQL/Ajax开发。同时提供窗口小部件管理、用户管理、Tab管理、皮肤管理、插件扩展、社交网络(Social Network)、书签、全文检索等,最为重要的是Posh内置了RSS的支持,不但支持RSS的在线解析和阅读,还将RSS组件化,可以便捷地实现基于RSS的信息推送。
(2)门户系统语义功能集成
Posh功能强大,但其不具备语义功能,要实现语义定制与推送需要对平台进行二次开发。可以按照两个路径进行开发:
①将本体知识映射表集成到系统的数据库结构中,在用户定制时实现概念到检索词的转化;
②用户信息中加入其学科背景属性,这样使得用户注册后第一次登录时,系统就可以根据其身份选择模块库中的相关学科的组件,为其组织一个缺省的个性门户页面。
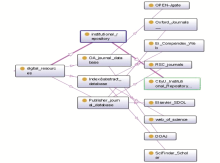
为了和Posh平台更好地结合,系统采用PHP作为开发语言,MySQL作为数据库系统,采用Apache作为发布平台;在SPARQL查询中使用了开源ARC2作为中间件;选择Lattice Miner作为概念格建格工具,如图4所示:
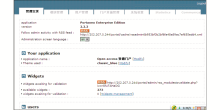
用Protégé构建本体,如图5所示:
每一种OA期刊都提供了对其资源的检索功能,例如,Urban Library Journal(http://cunylibraries.org/ojs/index.php/ulj/gateway/plugin/WebFeedGatewayPlugin/rss2)是其网站提供的最新目次的RSS种子,但是这个种子只能提供最新目次的浏览。本文中关注的是,用户通过领域本体定制概念,利用本体知识映射表转换后的关键词在这个OA期刊网站的检索结果。通过分析协议软件HTTP Sniffer分析,得到该刊的检索URL构造形式为http://cunylibraries.org/ojs/index.php/ulj/search/results?query=open+access&searchField=2,其中SearchFeild为检索点定义,取值情况为Authors=1、Title=2、Abstract=4、Index terms=120、Full Text =128,query为输入的检索词。
在获得检索式构造方式后,需要将检索结果页面进行处理,生成RSS种子。这里确定种子所需要的信息格式为:
Urban Library Journal
http://cunylibraries.org/ojs/index.php/ulj
A Content Analysis of the Strategic Plans of the Coalition of Urban Serving Universities Academic Libraries
http://cunylibraries.org/
http://cunylibraries.org/ojs/index.php/ulj/article/view/53
种子生成器是要将检索结果页处理成以上格式并输出。通过种子生成器可以得到提供用户定制和生成门户组件(Widget)的RSS种子。
本体查询模块由OWLClass、OWLInstance、OWLProperty、OWLModel等类组成。OWLClass节点代表一个OWL本体描述特征类;OWLInstance代表了一个OWLClass简单的实例(个体);OWLProperty代表一个属性可以是一个数据类型属性或一个对象的属性;OWLModel是本体模型的主体,定义本体的所有操作。
SPARQL解析主要由SPARQLEngine和SPARQLParser两个类完成。SPARQLEngine执行针对RDF的SPARQL查询,SPARQLParser处理 SPARQL查询字符串,并返回一个查询对象。
本文通过概念格和形式概念分析来改善概念间的语义关系,并在此基础上构建了领域本体。利用构建的领域本体,通过SPARQL查询、映射和RSS种子构建,将语义植入现有的门户系统平台中,实现了OA资源的Search & Retrival 到 Explore & Play的过渡[ 8],是OA资源整合服务的新的探索。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|