
{kind=link}
{kind=link}
{kind=link}
显式评分的重启动随机游走推荐算法研究
[俞琰1, 2  , 邱广华
, 邱广华1, 3 ]
, 邱广华|
|


针对目前重启动随机游走推荐算法偏重隐式评分而忽略显式评分的问题,采用监督重启动随机游走算法,使得用户喜爱的项目被访问的概率大于用户不喜爱的项目的概率,从而做出推荐。实验表明,该算法可以有效地提高推荐的准确性。
Aiming at random walk with restart recommendation algorithm mainly for implicit ratings while ignoring explicit ratings, this paper sets random walk under supervision to make recommendation, that makes the probabilities of items which user likes are greater than those of items which user dislikes. Experiment result demonstrates that this algorithm improves the accuracy of recommendation.
随着信息资源的急剧膨胀,用户在电子商务网站中寻找自己感兴趣的产品已经成为一件困难的事情。因此,电子商务推荐系统应运而生。推荐系统根据用户与系统的交互历史以及用户的个人信息等构建用户的兴趣模型,预测用户可能感兴趣的项目,推荐最适合用户需求的产品和服务。这些系统不仅能够帮助用户更好、更快地访问相关信息,也能够帮助商家提高销售量。
近年来,将推荐问题转换为图中顶点相似性排名问题,使用重启动随机游走(Random Walk with Restart, RWR)测量顶点间的相似度的推荐算法得到了广泛关注[ 1, 2, 3, 4, 5, 6]。目前,基于RWR的推荐算法研究主要针对隐式评分,而对显式评分信息研究较少。本文提出一种基于显式评分的RWR推荐算法,首先对评分进行标准化,将用户评分信息转变为用户的偏好信息,发现用户真正偏好的项目,然后采用监督随机游走,使得访问用户偏好项目的概率大于用户不喜爱的项目的概率。 实验表明,该算法较传统的RWR推荐算法能够更有效地提高推荐的准确率。
在众多的推荐方法中,协同过滤是应用非常广泛的个性化推荐技术[ 7, 8]。与传统的基于内容过滤直接分析内容进行推荐不同,协同过滤分析用户的兴趣,在用户群中找到目标用户的相似兴趣用户,综合这些相似用户对某一项目的评价,形成系统对该目标用户喜好项目的预测,即借由群体的喜好提供个性化的商品推荐服务。与传统文本过滤相比,协同过滤具有内容独立性、推荐新颖性等优点。因此,协同过滤被广泛地应用到很多主流电子商务网站中,如GoolgeNews[ 7]、Amazon[ 8]等。但是,协同过滤也存在一些缺点,其中一个就是稀疏性问题[ 9]。稀疏性是指相比于整个项目集合,大多数用户仅仅为很少的项目评分。两个用户重叠的评分项目非常少,不能够有效地识别用户之间的兴趣相似性,从而导致协同过滤方法的预测精确性不理想。
使用重启动随机游走的RWR推荐算法能缓解稀疏性等问题,具有算法简单、内容独立、推荐性能理想等优点[ 1, 2, 3, 4, 5, 6]。RWR主要用于度量图中顶点间的相似度[ 10]。它被广泛应用于信息检索的各个领域[ 11, 12, 13],其主要思想是游走者从图中某个顶点出发,沿着图中的边随机游走;在任意顶点上,以一定的概率随机选择与该顶点相邻的边,沿着边移动到下一个顶点,或者以一定的概率直接回到出发顶点。对于非周期不可约图,经过有限次的随机游走过程,游走者到达图中每个顶点的概率值达到平稳状态,再次游走也不会改变图中顶点的概率分布。此时,图中每个顶点的概率值可以看作该顶点与出发顶点联系的紧密程度(也称为关联度、相似度)。
RWR的数学表达式为[ 10]:
p(t+1)=(1-α)·S·p(t)+α·q (1)
其中,p(t)、p(t+1)和q是列向量。p(t)表示第t步图中的顶点概率分布, 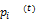
一个推荐问题可定义为由用户和项目顶点组成的二部图。通过在图上的随机游走,传递关联,发现甚至没有共同评分项目的项目间的相似性,这在一定程度上缓解了协同过滤中的稀疏性问题[ 15]。具体地,一个推荐问题能够被看作为一个用户-项目二部图G={U∪I, E},如图1所示:
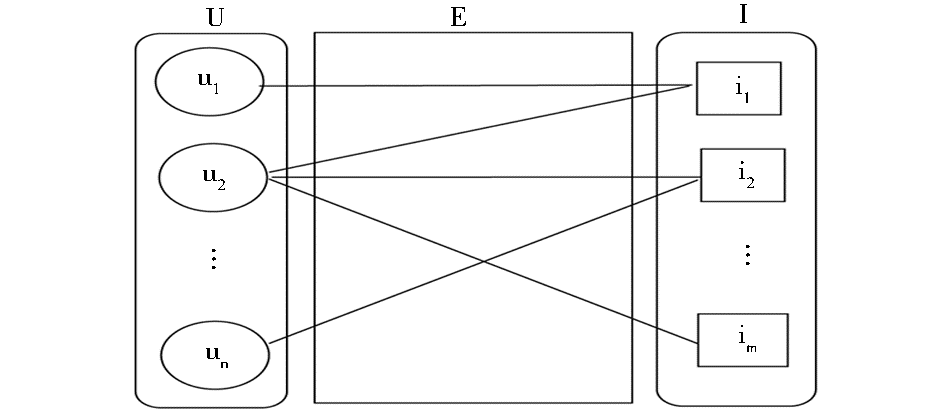 | 图1 用户-项目二部图 |
其中,U是用户顶点集合,I是项目顶点集合,E表示U×I边,表示用户对项目的偏爱。如用户ui购买/浏览项目ij,则在顶点ui和ij之间存在一条边。
用户-项目二部图被存储在一个n×m的矩阵M中。使用M能够很容易地构建邻接矩阵MA:
MA=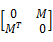
假设要从行顶点x出发,从一个特定的边
PA(x,y)=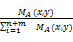
因此转移矩阵PA被构建为:PA=col_norm(MA),其中col_norm(MA)标准化MA的每行的和为1。从目标顶点出发,通过公式(1)的多次迭代,得到从用户顶点到项目顶点的稳定概率分布,将与目标用户最相关并未评分的项目推荐给目标用户。
推荐系统常常依赖于两种不同种类的评分:显式评分和隐式评分。显式评分通过对用户的在线调查和反馈等方式,获得用户对项目的评分,如1表示非常不喜欢,5表示非常喜欢。隐式评分不直接反映用户的意见,通过观测用户的行为来获得用户对项目的评分。隐式评分包括购买历史、浏览历史、搜索模式甚至鼠标移动等[ 16, 17]。目前,基于重启动随机游走推荐算法研究主要针对隐式评分,使用图上的边表示用户喜爱项目。对于显式评分的研究常常采用两种简化方法:一种考虑用户对项目的所有显式评分数据,使用评分表示边的权重[ 18],这样处理的问题是负面评分被隐式地转换为正面评分,可能造成错误的随机游走;另外一种认为负面评分需要另外的机制,所以模型不考虑负面评分,仅选择正面评分,即评分值为4、5的评分[ 1],这样的方法缺失了用户对不喜爱项目的评分的信息。
为此,本文提出一种基于显式评分的RWR推荐算法。算法首先对用户评分进行标准化,将其变为用户的偏好信息,发现用户真正偏好的项目,然后采用监督随机游走,使得用户偏好的项目被访问的概率更大,最后使用真实数据验证了算法的有效性。
基于RWR的推荐方法仅面向隐式评分,忽略了显式评分,限制了该算法的应用。为了克服这个局限,本文提出了一种基于显式评分的RWR推荐方法,主要包括以下两个步骤。
当为一个项目指定一个评分的时候,每个用户有自己的个人习惯。例如,两个用户u1、u2,他们对10个项目的评分如表1所示:
| 表1 用户u1和用户u2的评分信息 |
假设比起用户u2,用户u1趋向于给所有的项目更高的评分。在用户-项目图中,当游走者随机游走到项目i8顶点的时候,根据直觉,在下一个步骤,粒子更加可能跳转到用户u2,因为比起用户u1,用户u2指定评分4的项目更少,4的评分可以认为是用户u2强烈的偏好。但是如果仅仅依赖于显式评分模式计算用户的转移概率,则跳转到用户u1和用户u2的概率是相同的。
因此,需要转换评分信息为偏好信息[ 19]。评分标准化即为将个人的评分转换为一种更加通用的规格。
本文使用一半积累分布方法标准化评分[ 19]。给定用户ui、项目ij,以及用户ui对项目ij的评分ri,j,ui对ij的偏好概率遵循高斯分布N(μ(ui,ij), σ(ui,ij))。
μ(ui,ij)=Pr(r≤ri,j|ui) - Pr(r=ri,j|ui)/2 (4)
σ(ui,ij)=Pr(r=ri,j|ui) (5)
其中,Pr(r≤ri,j|ui)表示用户ui评分任何项目的分值不高于评分分值ri,j的可能性。Pr(r=ri,j|ui)为用户ui评分项目分值等于ri,j的可能性。
目前,基于RWR推荐方法根据用户隐式评分构建用户-项目二部图的边。对于显式评分,使用全部的评分信息表示边的权重,这样将负面评分信息隐含地转变为正面评分信息;仅仅保留正面评分作为边的权重,这样又忽略了用户不喜爱项目的信息。因此,需要使用一种监督方式,学习如何偏差一个随机游走,即比起用户不喜爱的项目顶点,使它更加频繁地访问用户喜爱的项目顶点。这样,通过学习边的强度(即随机游走的转移概率),形成一个监督学习游走任务[ 14]。给定一个目标用户顶点ui以及ui评分项目,监督学习游走的目标是学习指定边的强度(即随机游走的转移概率)的函数,从而使它更加可能访问偏好的项目顶点。
给定一个目标用户顶点ui,以及该用户的各个级别的评分项目集合I5(ui)、I4(ui)、I3(ui)、I2(ui)、I1(ui)。其中Ij(ui)(j∈[1,5])表示目标用户ui评分项目分值为j的项目集合。
对于用户-项目二部图G中的边(ui,ij),目标是计算强度a(ui,ij)=exp(ri,j·w)。w为指数函数的参数,输入为用户ui评分项目ij的评分值ri,j,计算对应边的强度a(ui,ij),建模顶点随机游走转移概率。在算法的训练阶段,将使用已知的训练数据学习指数函数,设置指数函数的参数w。
随机游走更加可能访问用户项目评分值高的项目顶点,即:存在id∈Ix(ui),il∈Iy(ui),若x
minF(w)= 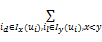
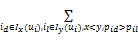
算法的目标是找到合适的w最小化等式(6)。
为求解等式(6)发现最小化的F(w),使用基于梯度优化法。F(w)求导为:
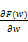
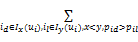
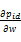
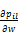
为了求解公式(7),构建随机游走转移矩阵S',其中S'i,j表示用户顶点ui和顶点ij之间的转移概率,计算公式如下:
S'i,j=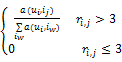
为了保证图的连通性,得到稳定概率分布,对公式(1)稍微作修改[ 20],如下所示:
p(t+1)=(1-α-d)·S'·p(t)+α·q+d·r (9)
其中,r是重启动到图中每个顶点的向量,这样保证了图为联通的,存在稳定随机分布。d为重启动到图中所有顶点的概率。设置d=0.001,只要α>>d,这些概率的不同的值仅仅导致了微小的推荐变化[ 20]。
因此,最后的随机游走转移概率矩阵S为:
Si,j=(1-α)·S'i,j+α·q+d·r (10)
向量p是重启随机游走的稳定分布,遵循特征根(Eigenvector)等式的解决方法:
pT=pT·S (11)
等式(11)能够写为pu= 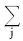
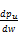
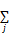
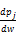
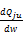
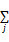
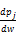
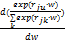
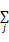
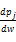
+pj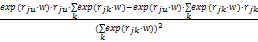
通过对公式(12)递归应用链规则计算。首先计算p,然后更新估计导数 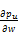
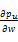
输入:用户-项目评分矩阵,目标用户ui,重启动概率参数α。
输出:按相关度降序排列目标用户ui未评分的项目列表。
①根据公式(4),根据评分信息计算用户偏好信息;
②构造公式(8)中的转移概率矩阵S;
③构造重启动向量q,目标用户s对应的顶点元素设置为1,其余元素为0;
④构造重启动向量r,所有元素设置为1;
⑤初始化目标用户在第0步骤是图中的概率分布p(0)=q;
⑥初始化 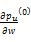
⑦初始化w=1;
⑧迭代更新p(t)、 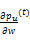
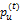
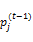
⑨步骤⑧得到包含w的随机稳定概率pid和pil,根据梯度下降计算公式(7),获得使得F(w)最小的最优值w,计算 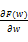
⑩根据梯度下降,重新选取w,重复步骤⑧和⑨,求得最优w;
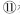
结束。
为了测试提出算法的有效性,采用GroupLens提供的MovieLens网站上的用户评分数据集。MovieLens是历史悠久的推荐系统,对用户进行电影推荐。MovieLens网站有超过50 000位用户对超过3 000部不同电影进行评分(分值1-5)。在1-5的评分中,大于3的评分可以认为是用户喜爱电影,小于3的评分表示不喜欢。MovieLens数据集合是一个标准的数据集合,仅仅考虑了评分超过20部电影的用户。数据集包含943位用户对1 682部电影的100 000个评分(1-5)。每个用户已经至少评分了20部电影。数据通过MovieLens网站收集,从1997年7月19日到1998年4月22日7个月的时间。少于20个评分的或者没有完整属性信息的用户已经从数据集合中移走。根据3折交叉验证,数据分为三个不同的集合,2/3的数据作为训练集,剩下的为测试集。
评估指标采用查准率(Precision, P)和平均倒数排名(Mean Reciprocal Rank, MRR)。P表示推荐的项目中正确的推荐所占的比例。P@K表示前K个推荐的查准率,计算公式如下所示:
P@K=
MRR表示用户实际评分的喜爱的项目在推荐列表中的位置倒数的平均值,MRR越高,表示算法的准确率越高。公式如下所示:
MRR=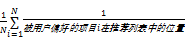
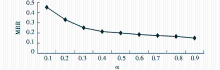
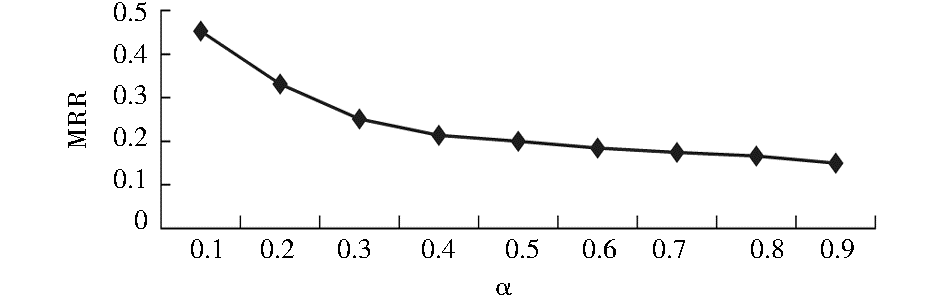
设置合适的重启动概率α。构建一个用户-项目二部图,仅仅考虑正面评分,即忽略小于等于3的评分信息。使用评分值作为边的权重,由此构建转移矩阵S。基于这样的转移矩阵S,不同的α对性能MRR的影响如图2所示:
 | 图2 α对MRR的影响 |
可以看出,随着参数α的逐渐增大,RWR的性能总体呈现缓慢的下降趋势。当α=0.1的时候,MRR的性能最佳。此处,仅显示了参数α对MRR的影响结果,α对P@10、P@20、P@50的影响结果类似。α为重启动概率,表示在每一次的随机游走的过程中,重新跳回到初始目标用户顶点的概率。小概率的重启动概率意味着整体性而非局部性,这和个人搜索和查询建议等应用中RWR的重启动概率类似。α的选择同图本身的结构有一定的关系。为此,在以下的实验中,均使用α=0.1。
为了验证提出算法的有效性,进行三种方法的比较:
(1)全部随机游走(TotalRWR):保留所有的用户评分信息,使用评分分值作为边的权重,构成一个用户-项目二部图,采用RWR计算顶点相似性[ 18]。
(2)偏好随机游走(LikeRWR):仅仅保留大于3的用户评分项目信息,使用评分分值作为边的权重,构成一个用户-项目二部图,采用RWR计算顶点相似性[ 1]。
(3)本文提出的算法(SRWR): 保留大于3的评分信息作为边,先计算偏好信息,再采用监督RWR方法计算顶点相似性。
三种方法在MovieLens数据集上的性能如表2所示:
| 表2 三种方法性能比较 |
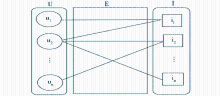
可以看出,在两种传统RWR推荐方法的比较中,LikeRWR好于TotalRWR,P@10、P@20、P@50和MRR分别提高12.82%、9.46%、7.69%和24.45%。LikeRWR方法仅仅考虑了用户正面评分信息,而忽略了负面评分信息,这构成了用户喜爱项目的一个二部网络;而TotalRWR既考虑用户的正面评分信息也包含用户负面信息,这样形成的用户-项目网络中的边包含了喜爱和不喜爱两种含义完全相反的边。TotalRWR例子如图3所示:
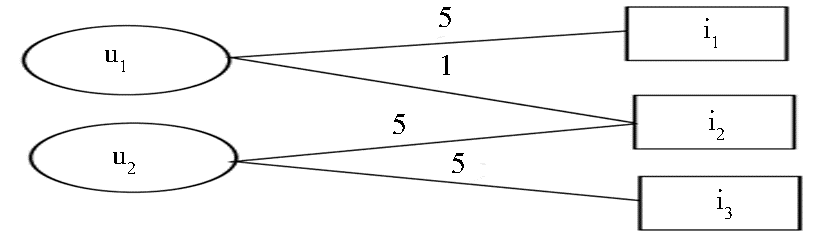 | 图3 TotalRWR例子 |
可以看出,用户u1喜爱项目i1,评分5,不喜爱项目i2,评分为1;用户u2喜爱项目i2和i3,均评分为5。考虑TotalRWR方法,用户全部评分信息构成用户-项目网络。根据RWR,i3将可能被推荐给用户u1,而根据直觉,用户u1不喜爱i2,则很可能也不喜爱i3。可见,将负面评分数据(不喜爱)隐含地转换为正面评分信息(喜爱),会造成一定的错误,从而降低RWR算法的性能。因此TotalRWR虽然考虑了全部的评分信息,但是性能却逊于仅考虑正面评分信息的LikeRWR。和传统的两种方法比较,SRWR的性能有了明显的提高,比起LikeRWR方法,SRWR方法P@10、P@20、P@50和MRR分别提高了15.91%、13.58%、11.43%和20.97%。这说明通过标准化评分,学习监督随机游走能够提高推荐的性能。
本文讨论了个性化推荐技术中的重启动随机游走算法,针对传统的重启动随机游走推荐算法主要针对隐式评分而忽略显式评分的问题,提出一种基于显式评分信息的重启动随机游走推荐算法。该算法集成用户喜爱和不喜爱项目的评分信息,通过监督随机游走,学习顶点间边的连接强度,指导随机游走朝着用户喜爱的项目顶点游走。实验表明提出的算法较传统的重启动随机游走推荐算法可以有效地提高推荐精度。该算法既保留了重启动随机游走推荐算法的内容独立性、推荐项目新颖性、缓解数据稀疏性等优点,又拓展了重启动随机游走推荐的应用范围,不再局限于隐式评分信息,对于现实世界中广泛存在的显式评分项目具有普遍的适用性。近期笔者将在一个高校图书馆书籍推荐系统中实施部署该算法,进行在线评估,收集用户对该算法运行的实际意见的反馈信息。此外,随着Web2.0的迅速发展及应用,将研究如何在该算法的基础上集成社会信息,如用户信任关系、用户标签等,以进一步提高推荐的性能。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|