

{kind=link}
{kind=link}
{kind=link}
{kind=link}
统计机器翻译中文分词优化技术研究
[石崇德 , 王惠临]
, 王惠临]
, 王惠临]
|
|


This paper analyzes the different segmentation approaches and how they work on word alignment of Statistical Machine Translation (SMT). Then it proposes two optimization methods of Chinese Word Segmentation(CWS) based on granularity constraint and sub-word tagging. Experiment results show that these methods can improve the quality of machine translation.
目前主流的统计机器翻译理论方法是从大量平行语料中获取翻译知识,减少了翻译系统开发维护的成本,同时在一定程度上提高了自动翻译的效果。但由于计算机无法理解人类语言,机器翻译研究仍然存在许多困难,自然语言处理的各个阶段,包括词法、句法、语义等,均存在大量问题有待解决。
中文分词作为统计机器翻译的预处理步骤,对翻译效果有重要影响。中文分词在中文信息处理领域已经得到了广泛深入的研究,但是它在哪些方面对统计机器翻译产生影响,如何通过优化分词提高统计机器翻译的效果,相关的研究还较少,因此本文对这些方面进行了针对性研究。
统计机器翻译的基本思想是通过对大量的平行语料进行统计分析,构建统计翻译模型来进行翻译,其发展从早期基于词的翻译模型过渡到基于短语的翻译模型,并逐步融合句法信息,以进一步提高翻译的精确性[ 1]。
中文分词是统计机器翻译的预处理步骤,但针对统计机器翻译中的分词的研究还较少。Zhang等[ 2]考察了不同分词标准(北大、微软、香港城市大学、中国台湾中央研究院)、不同的分词方法(基于词典的机械匹配和基于字标注的条件随机场方法等)对机器翻译的影响。他们认为,不同的分词标准在机器翻译中的效果差别不大,基于词典的机械分词方法效果要略好于基于CRF的分词方法;分词准确率的F值和机器翻译评测BLEU值没有很强的联系;改正分词错误能在一定程度上提高机器翻译的准确率。Zhang等[ 3]也提出了合并使用不同的切分方法切分的训练语料,能在一定程度上提高机器翻译的效果。他们总结了不同分词在机器翻译中的一些表现,但是没有给出深入的解释。
Chang等[ 4]也对机器翻译中的分词进行了研究,他们认为在同一种切分标准下提高分词准确率并不能提高机器翻译效果,真正能够影响效果的是分词的一致性和词的粒度。
其他一些语言的翻译也存在切分需求,如日语、韩语,但相关研究较少。Paul等[ 5]提出了一种独立于语言的切分方法,首先将源语言句子切分为字,然后通过统计机器翻译的词对齐模型与英语部分对齐,并使用一种无监督的学习方法将源语言重新进行切分,然后进行统计机器翻译实验。他们对5种亚洲语言进行了翻译实验,但其基线系统是按字切分,而不是词,因此这种方法的有效性缺乏足够的实验验证。
本文从汉英统计机器翻译的原理出发,从分词对词对齐模型的影响因素进行深入分析,并以此设计相应的优化方法。
为了寻找分词方法对机器翻译的影响因素,本文首先对不同的分词表示进行翻译对比实验。翻译实验使用开源机器翻译系统Moses[ 6],从LDC[ 7]汉英新闻语料中抽取10万个句对作为训练语料;实验的开发集为2002年NIST汉英机器翻译评测语料;测试语料为2003-2006年4年的NIST评测语料[ 8]。
为了从多方面比较不同的分词方法对机器翻译的影响,本文使用包括基于断字的表示[ 9]、基于逆向最大匹配的汉语分词[ 10]、基于条件随机场的字标注分词[ 11],以及中国科学院计算技术研究所分词系统ICTCLAS[ 12]的分词方法对语料进行切分。
除了基于断字的表示,其他分词方法均采用了北大分词标准,因此,实验中机器翻译效果的不同主要来源于分词方法的不同。另外,由于机器翻译语料没有标准分词,无法评估不同分词方法在机器翻译语料上的准确率,为了与机器翻译实验进行对比,使用2005年SIGHAN评测[ 13]中的北大数据集进行分词准确率评测,包括了约110万词的训练语料和约10万词的测试语料,以辅助说明不同分词方法下分词准确率和机器翻译效果之间的关系。
分词和机器翻译的结果如表1所示,分词使用了F值作为指标,BLEU值使用了4种BLEU值的平均值作为指标。
| 表1 不同分词方法对比 |
一般认为分词准确率越高,机器翻译的效果就越好,但是从表1可以看出,分词准确率与机器翻译评测的BLEU值相关性并不强。比如BMM和CHARCRF,前者的切分F值为0.890,低于后者的0.948,而前者机器翻译的BLEU值反而比后者高0.44。
通过对几种不同切分实验的对比分析,本文认为中文分词对统计机器翻译的影响主要包括三个方面:总切分词数、词表的词数以及切分错误。
本文对实验中几种不同切分的训练语料进行了统计,结果如表2所示,其中最后一行“ENG”表示对训练语料中英语部分的词的统计结果。
| 表2 不同分词切分词数统计 |
从总的切分词数来看,CHARCRF切分方法的总词数相对较小,BMM与ICTCLAS切分词汇与英语词数量相近。按照IBM词对齐模型的原理,每一个句对中词数多的一方必然有部分词只能与空词对齐,源语言与目标语言句子词的数量差别越大则对齐效果越差。
从词表的词数来看,BMM切分得到的词表与英语词表大小相似,CHARCRF词表是BMM的2倍左右,比ICTCLAS多近30%。
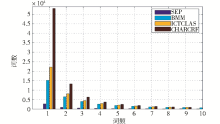
进一步对不同切分的机器翻译语料的词频进行统计,结果如图1所示:
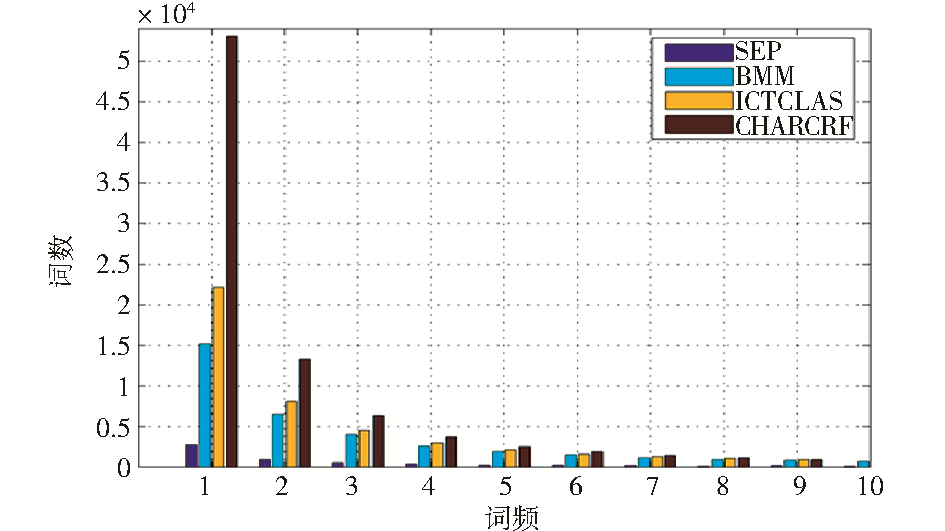 | 图1 不同分词的词频统计 |
可以看出,CHARCRF分词方法虽然准确率较高,但切分后的低频词远远大于其他切分方法,导致更为严重的数据稀疏问题,大大降低了词对齐的准确率,影响了机器翻译的效果。
在分词错误方面,通过对CHARCRF切分得到的新词进行观察发现,大量低频新词都可以进一步切分,比如“政治经济/新/秩序”中,“政治经济”被切为一个词,实际上如果将其切分“政治/经济”两个词,与英语“Political and Economic”相对应,能得到更好的词对齐结果。
Xue等[ 14]提出基于字标注的中文分词方法,将中文切分转换为标注汉字在词中位置的问题,为汉语分词提出了一种全新的思路,之后出现了各种基于字标注的分词方法[ 15, 16],其中条件随机场的字标注模型逐渐成为其中的主流方法[ 17]。
条件随机场最早由Lafferty等[ 18]提出,是一种无向图模型,它采用了链式无向图结构计算给定观察值条件下输出状态的条件概率,公式如下:
p(y|x)= 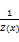
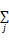
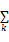
用图形表示如图2所示:
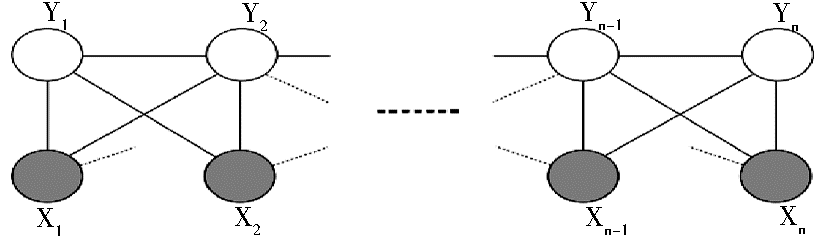 | 图2 条件随机场模型 |
其特征函数为二值函数:
f(h,y)=
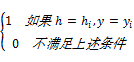 | (2) |
其中,h表示定义的特征,y表示标记集合。把图中Xn换成汉字,Yn换成每一个汉字在词中位置的标记,就可以把汉字切分转换为对汉字位置标记的标注问题。
本文使用的标注集为4种标记:Y ={S(标注汉字单字成词),B(标注汉字为词头),E(标注汉字为词尾),M(标注汉字为词头词尾以外的中间部分)}。使用的特征集如表3所示:
| 表3 分词特征 |
条件随机场模型不需要隐马尔可夫模型的独立性假设,同时避免了最大熵模型的标记偏置问题,在序列标注问题中具有更好的性能。但是,条件随机场模型也存在一定的不足,在分词中,条件随机场模型能保证较高的未登录词召回率,但也产生了大量的低频新词,影响机器翻译的性能。
从表2可知,条件随机场切分得到的词数少于其他切分方法,这导致切分的词变长、新词变多,因此需要一种方法,在确保一定的切分准确率的同时,能比较自由地调整切分粒度,避免词与词的组合构成新词。本文通过两种方法对CRF切分进行了优化:粒度约束与子串标注。
条件随机场模型本身只能依据训练语料生成切分,无法自动调整切分的粒度,本文通过约束条件模型对CRF添加粒度约束。
约束条件模型(Constrained Conditional Model)是Roth等[ 19]提出的一个一般化的学习框架,用来处理线性模型中的约束,它是一组特征函数φi和一组约束条件Cj的组合,公式如下:
fC(x,y)= 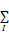
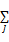
其本质是对线性学习模型添加了一系列约束特征,能够更方便地描述先验知识或对模型添加约束。
对于机器翻译的分词来说,要控制分词后的总词数,只需要控制每个词的长度,词的平均长度越短,其总词数就越大,反之亦然。基于字标注的汉语分词方法中,分词过程通过标注汉字的位置来确定。对于“B”、“E”、“M”、“S” 4个标记来说,在标注的过程中提高“B”、“E”、“S”的概率,则生成的词增加,提高“M”标记的权重,则生成的词减少。
当然,这些标记的分布不能任意修改。本文首先通过CRF模型的训练得到了一个关于标记分布的相关参数的估计,在假定这些参数的合理性的基础上,通过粒度约束对相关标记的分布进行调整,以实现调整总词数的目标。
假设lj表示相应的切分标记,μ表示粒度调整的参数,约束特征表示公式如下:
ρj=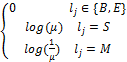
其中,粒度参数μ为正实数,如果μ>1,则标记“S”的权重增加、“M”的权重减小,相应的词长变短、总词数增加;如果0<μ< 1,则标记“S”的权重减小、“M”的权重增加,相应的词长变长、总词数减少;如果μ =1,则logμ =log(1/μ)=0,模型退化为一般的CRF模型,不对词的长度进行调整。约束特征在CRF训练得到的参数基础上,对测试结果的不同标记的权重进行微调。为了保证分词质量,一般取log(μ)在1左右的数字。通过调整参数μ,笔者对机器翻译的训练语料、测试语料进行不同粒度的切分,测试不同的分词粒度下机器翻译的效果。
依据不同分词对翻译效果影响的分析,当切分粒度变大时,则汉语词数增加,词表变小,数据稀疏程度减小,有利于机器翻译,但同时,分词错误也同样增加,这可能导致BLEU值下降;切分粒度变小时,汉语词数减少,词表变大,数据稀疏程度变大,同时分词错误也在增加,同样可能导致BLEU值降低。直观地推断,分词粒度在某一个点会有最佳的BLEU值,这需要通过设定不同的粒度进行机器翻译实验来验证。
粒度约束在调整分词词数的同时,在一定程度上降低了分词准确率,为了更好地保持分词准确率,本文使用了基于子串标注的方法。
在汉语词组成情况的研究中发现,很多汉字串的组合是相对稳定的,只要子串中的汉字连续出现,就不会被切分开,这个串可能独立成词,也可能作为词的组成部分,比如“机器”、“翻译”,这两个词本身不存在进一步切分的可能,而组合的时候可以作为一个独立的词“机器翻译”。本文把这一类比较固定的子串作为一个标注单位,通过标注其在词中的位置实现分词。
为实现子串标注,首先需要对子串进行抽取。子串抽取的目标是最大程度上保证子串在标注过程中作为词中的一个独立的单元,可以忽略子串的内部结构,除了整个子串,子串的任何一部分不会和其他的字或串组合成词,也不会独立成词,即子串内部不可分割。
本文子串的切分基于机械分词方法,分词词典有两个:第一个词典中删除了单字词和超过7个汉字的词,称为主词典;第二个词典为双字词,从中删除了训练语料中出现的能切分为两个单字词的词,称为跨标记词典。子串切分主要包括以下几个步骤:
(1)依据主词典对句子做正向最小匹配切分子串,初始最小子串长度为2;
(2)依据主词典对句子做逆向最小匹配切分子串,初始最小子串长度为2;
(3)对比前两步切分结果,切分歧义子串;
(4)依据跨标记词典切分双字跨标记子串。
Zhang等[ 20]和赵海等[ 21]分别使用了基于子串标注的切分方法,但均使用最大匹配法对子串进行匹配。本文认为最大匹配法更适用于词的切分,而不适用于切分词内部的子串,因此本文使用最小匹配方法进行子串切分。
粒度约束使CRF切分在保证一定的切分准确率的前提下,可以人为地调整切分词的大小;子串标注则保证了在粒度调整的同时能减少切分错误。两种方法结合能更好地优化机器翻译中中文语料的切分。
为了对比不同优化方法对机器翻译效果的影响,分别进行了基于字标注切分的优化实验和基于子串标注的优化实验,两类实验均使用了粒度约束。由于参数μ跨度较大,将切分后训练语料的词数与对应英文的词数比值作为粒度。实验使用的环境、语料与本文第3节相同。
表4列出了基于字标注的切分在不同粒度(0.786-1.055)下词表大小、中文切分评测的F值以及机器翻译的平均BLEU值。
| 表4 基于字标注的优化实验结果 |
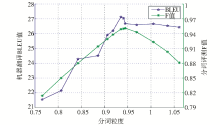
图3更直观地描述了中文切分与机器翻译的结果随粒度变化的情况。
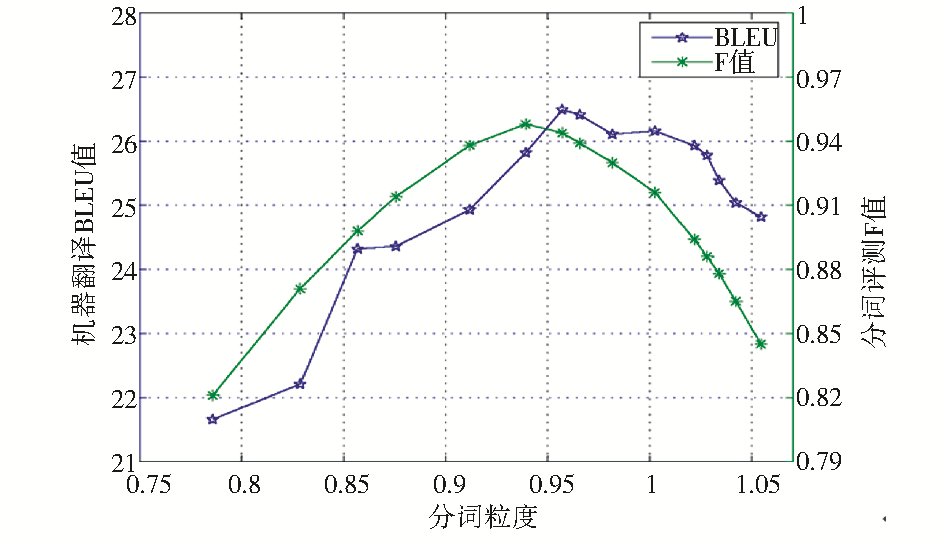 | 图3 基于字标注的粒度约束优化实验 |
从实验看出,调整分词粒度,中文分词的F值和机器翻译的BLEU值会随之发生变化。分词的F值先是单调递增,在粒度为0.939处达到顶点,随后开始递减;机器翻译的BLEU值同样先递增、后递减,在0.957处达到最佳BLEU值。
实际上,如表4灰色行所示为实验中分词F值最大的一点(粒度为0.939),即是μ取值为1,粒度约束模型退化为CRF模型的一点。从图3可以看出,这一点的BLEU值并不是最大,BLEU值最大的一点(粒度为0.957)切分的词数量要少一些。寻找BLEU值最大的一点是对分词进行优化的目标,实验证明了通过粒度约束来优化统计机器翻译的有效性。
在基于子串标注的切分中也使用粒度约束进行优化实验,详细结果如表5所示:
| 表5 基于子串标注的优化实验结果 |
对应的图形表示如图4所示:
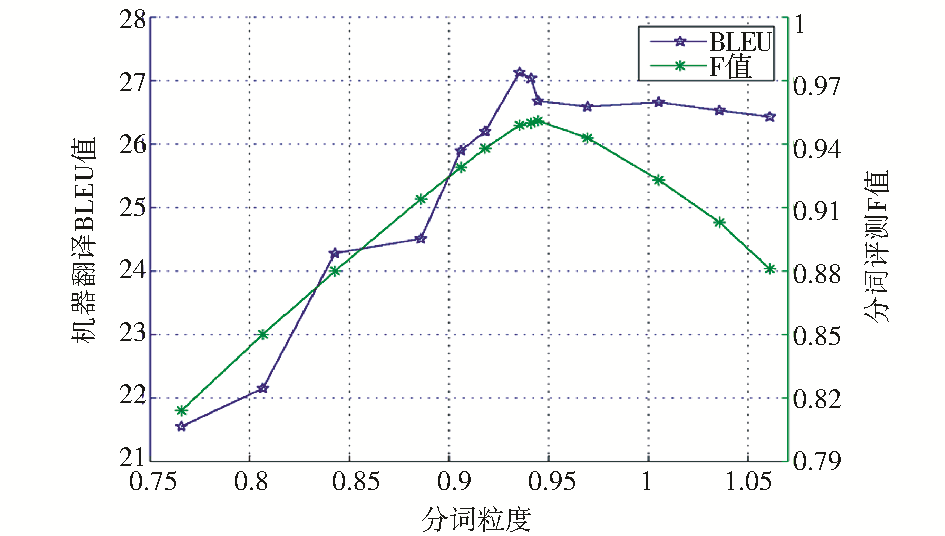 | 图4 基于子串标注的粒度约束优化实验 |
观察表5灰色行,在粒度为0.945的位置模型粒度参数μ失效,模型退化为普通的CRF切分模型,分词F值达到最高值0.951,与表4灰色行基于字标注方法的0.939对比,基于子串标注的分词准确率更高,这说明基于子串标注的分词方法本身比基于字标注的切分方法效果更好。
同时,从表4和表5灰色行的词表大小来看,基于子串标注的方法词表比基于字标注的切分方法少23.8%,说明基于子串标注的方法能有效地减少新词,缓解词对齐模型中的数据稀疏问题。
从机器翻译的BLEU值来看,基于子串标注的切分在粒度为0.935处得到最大值27.13,比基于字标注的切分方法的最大值高0.64。说明基于子串标注与粒度约束结合对机器翻译的优化效果比基于字标注的方法效果更好。
另外,图4中BLEU值在到达最高值之后随着粒度变大有一定的下降,但与图3相比下降幅度较小,主要原因是基于子串标注的方法在调整粒度的同时,能防止子串内部进行切分,保证了子串内部的连续性,减少了在基于字标注方法中容易出现的切分错误。
从本文的实验结果来看,基于子串标注和粒度约束的切分方法能够有效地减少新词的产生,在一定程度上缓解了词对齐模型中的数据稀疏问题;通过在不同粒度上的翻译实验能够找到最佳切分粒度,从而提高机器翻译效果。
本文以基于短语的统计机器翻译为例进行中文分词的优化研究,未来计划将研究扩展到其他的机器翻译方法,比如基于句法的统计机器翻译等,针对不同的理论方法研究和设计相应的中文分词优化方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|