




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Prefuse和层次聚类的信息检索主题知识图谱研究
[肖明1  , 栗文超
, 栗文超1 , 夏秋菊2 ]
, 栗文超|
|


提出基于Prefuse的主题知识图谱系统框架,通过对信息检索领域的关键词进行共词分析、层次聚类和TreeML文件转换,实现信息检索主题知识图谱的构建。最终将信息检索研究划分为5个主题:智能化信息处理、搜索引擎相关、用户行为研究、信息系统研究和基于内容的信息检索研究。
In this paper, a thematic knowledge map framework using Prefuse is designed. Through the co-word analysis, hierarchical clustering and TreeML file conversion, the themes of information retrieval based on the framework are mapped. Finally, information retrieval research is divided into five themes: intelligent information processing, search engines related, user behavior, information system research and content-based information retrieval.
自1950年Mooers在罗格斯大学计算机协会的会议论文中首次使用信息检索(Information Retrieval)这一术语以来,信息检索在20世纪末已发展成为一门成熟的学科[ 1]。国内外学者近年来利用知识图谱方法对信息检索进行了学科分析研究。其中,Ding等[ 1]对信息检索领域高被引作者、作者研究领域进行图谱分析,揭示了信息检索的学科发展状况,但并未对信息检索研究主题进行深入分析;Rorissa等[ 2]利用知识图谱软件CiteSpaceⅡ,对信息检索进行了全面的学科分析,但其研究在一定程度上依赖于知识图谱软件的功能,而且未对信息检索研究主题进行确定;国内学者张小娣等[ 3]、赵蓉英等[ 4]利用CiteSpaceⅡ分别对搜索引擎和跨语言检索进行计量分析,尽管他们的研究在一定程度上揭示了信息检索的学科进展,但并未对信息检索整个学科进行主题分析。基于上述原因,本文提出一种新的主题知识图谱框架,采用层次聚类等方法,创建了信息检索主题知识图谱并进行解读,以便为国内外从事信息检索研究的有关学者提供参考。
Heer等[ 5]提出了Prefuse的信息可视化框架。Prefuse为数据建模、数据可视化以及用户交互提供了丰富的软件库,可以支持表格、图和树的显示,还具有支持动态显示、动态查询等功能[ 6]。
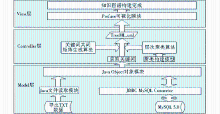
本文在Prefuse可视化组件的基础上,提出了基于Prefuse的主题知识图谱系统框架,如图1所示:
 | 图1 基于Prefuse的主题知识图谱系统框架 |
该框架基于MVC架构进行设计,包括模型(Model)层、控制(Controller)层和视图(View)层。各模型层的主要功能及开发流程如下:
(1)Model层
Model层的主要功能包括:形成关系对象模型(O/RM),实现对象与数据库中表的连接,完成数据模型的增、删、查、改等功能。Model层的主要开发流程包括:利用MySQL数据管理系统来构建数据库;构建数据处理层,形成基于Java的关系对象模型(O/RM),便于建立数据表与Java对象之间的转换,方便Java执行针对数据表的增、删、查、改等操作。
(2)Controller层
Controller层的主要功能是完成知识图谱显示前的准备工作,包括数据处理、构建算法和生成相应的文件。Controller层的主要开发流程包括:获得关键词数据;设计关键词共词矩阵算法和层次聚类算法,对关键词进行共词处理和层次聚类;将获得的聚类转化成TreeML格式的XML文件,生成主题聚类文件,供视图层接口使用。
(3)View层
View层的主要功能是完成知识图谱的显示。View层的主要开发流程包括:将控制层提供的主题聚类文件提供给Prefuse接口,并进行显示。
本系统的开发环境为:JDK 1.6、Eclipse 3.6.1、MySQL 5.0。开发过程中使用的主要组件包括:JDBC连接MySQL的mysql-connector-java-5.1.7-bin.jar、DOM4J、Prefuse的Java插件包。
本文研究中用到的数据来源是Web of Science,通过主题检索来获得相应的数据。用到的主题词是“Information Retriev*”,出版时间为所有年份,数据库选择为SCI Expanded、SSCI、A&HCI、CPCI-S、CPCI-SSH,开启词形还原功能,实施检索日期为2011年11月25日。得到的检索结果共计有46 561条记录,其文献类型、数量及所占百分比情况如表1所示:
| 表1 文献类型、数量及所占百分比 |
信息检索主题知识图谱的构建包括以下三个主要步骤,即数据预处理、关键词共词分析和聚类、绘制知识图谱。
对关键词进行去重处理以后,共计得到49 827个关键词,总频次为110 373。选取频次最高的前100个关键词,将其中的“信息检索(Information Retrieval)”一词剔除,以剩下的99个关键词作为构建主题知识图谱的数据基础。
根据此前获得的关键词表,构建如表2所示的数据表。其中,“所在文献ID”为关键词所在文献的所有ID号,以逗号进行分割。
(1)构建关键词共现矩阵
本文基于关键词共现次数提出共现函数如下:
Nij = Ki + Kj - Kij (1)
其中,Nij为矩阵中关键词共现次数;Ki为关键词i所在文献ID集合中的元素数量;Kj为关键词j所在文献ID集合中的元素数量;Kij为关键词i和关键词j所在文献ID合集中的元素数量。
| 表2 关键词频次及所在文献ID表(局部) |
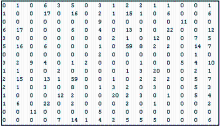
根据上述共现函数,通过编程获得了99×99的关键词共现矩阵,将其作为聚类的基础,如图2所示:
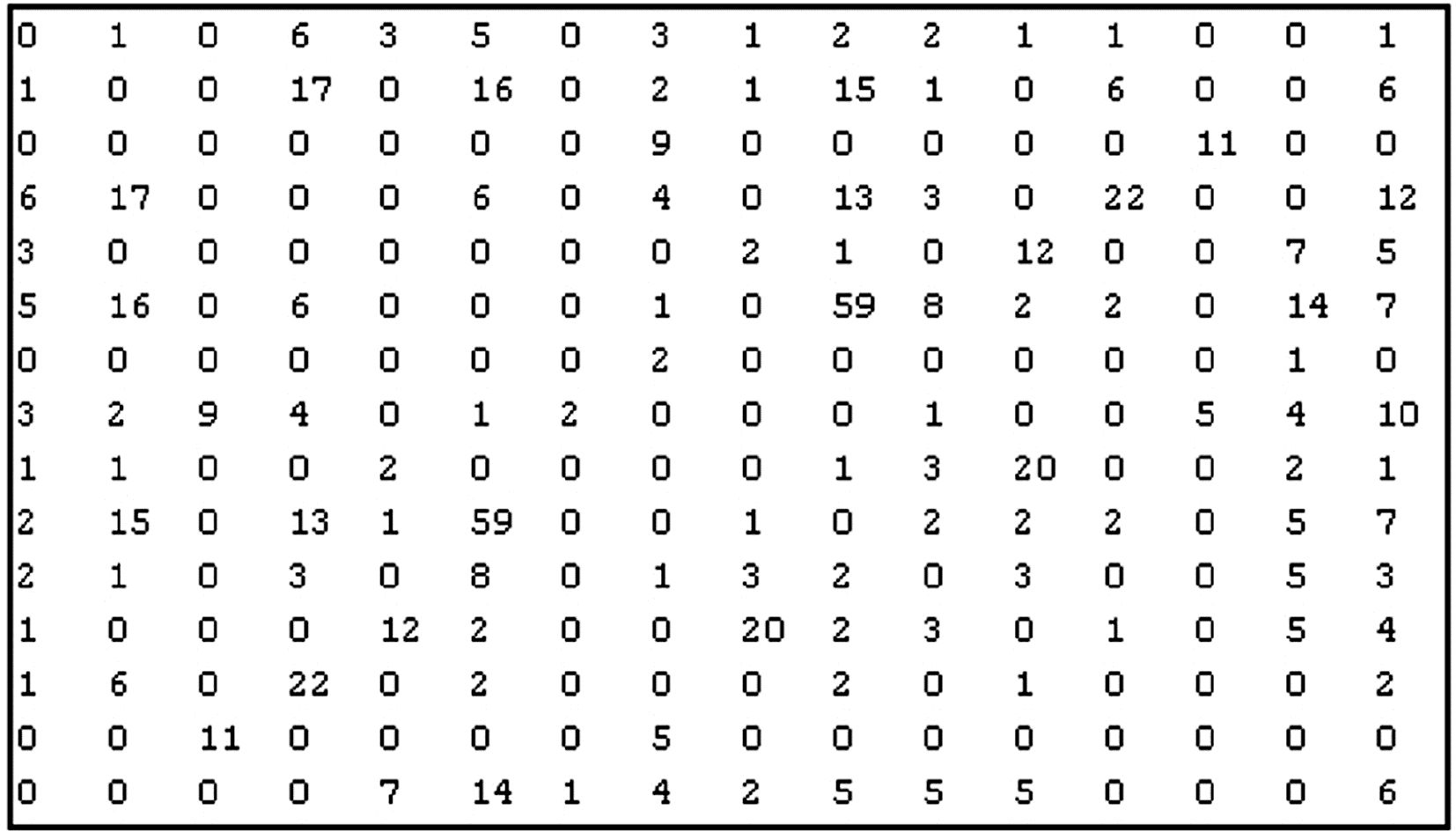 | 图2 关键词共现矩阵(局部) |
(2)进行聚类
对信息检索的主题聚类,本文主要采用“自底而上”的AGNES算法。该算法由Kaufman和Rousseeuw首次提出[ 7],其思路是:如果子类C1中的一数据点与子类C2中的一数据点之间的距离是所有属于两个不同类别的数据点之间距离最小的,那么C1和C2可以被合并。这是一种单连接方法,其每个类可以被类中的所有元素或数据代表,两个类之间的相似度由这两个类中距离最近的数据点对的相似度来确定[ 7]。
通过Java编程自行实现AGNES算法,具体实现流程如下:
输入:99个关键词、频次及其所在文献ID,终止条件为达到簇的数目k;
输出:k个簇;
初始化99个簇,包含属性关键词、频次及其所在文献字符串,将每个对象初始为一个簇,放入包含99个簇的簇队列ArrayA中
获取关键词共词矩阵MatrixA
Repeat
for ArrayA.size()
获取ArrayA的最后一个元素LastA
根据MatrixA,分别计算LastA与ArrayA中其他元素的距离
找到与LastA距离最近的元素B
合并LastA、B,生成新的簇C
从ArrayA中删除LastA和B,将C放入ArrayA中Until达到定义的簇的数目
算法性能:
①一旦一组对象被合并,将不能撤销;
②算法的复杂度为O(n2),因此不适合大数据集计算。
距离函数为构建关键词共现矩阵中的共现函数,即:Nij = Ki + Kj - Kij。
在类目数目的确定上,本文基于以下两个原则进行考虑:
①关键词数量尽可能地分布均衡,由于每个研究主题的确定是在多个研究方向的基础上发展起来的,所以认为关键词数量分布应该比较均衡;
②参考已有研究成果,例如,王知津等[ 8]、王智红等[ 9]分别将网络信息检索研究主题分为5个部分和4个主题。
根据上述原则以及研究中针对阈值的不同测试,确定分为5个相关的主题类。各类目根据相似性聚类获得,所以各个类别之间也有联系,同一类别内部的联系性相对较强,不同类别之间的联系性相对较弱。
(3)确定主题名称
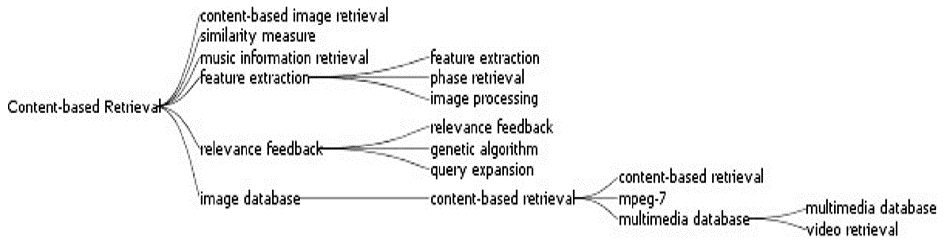
根据各个主题类中所包含关键词频次排列、关键词之间内容的联系以及已有研究成果,将5个研究主题名称确定为:“Intelligent Information Processing”、“Search Engine-related”、“User Behavior”、“Information System”和“Content-based Retrieval”。
Prefuse对树形结构的可视化采用DOITrees[ 10, 11]技术进行,需要先将数据生成Prefuse支持的TreeML的XML文件[ 12],然后通过Prefuse提供的组件进行可视化。
(1)生成可视化表征文件
通过编程将所得的聚类生成TreeML格式的树形表征文件,如图3所示:
 | 图3 生成的TreeML文档示意图(局部) |
其中,根目录是“tree”标签,“declarations”标签表示要显示的树形的类别,树形的值由“name”显示,其类型为“String”。“tree”的子节点是分支节点“branch”,定义为“Information Retrieval”,代表图谱的根节点中显示的标签名称。
(2)知识图谱显示
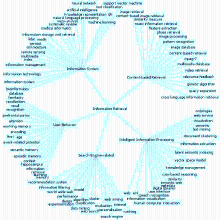
生成代表类别的TreeML文件以后,通过Prefuse提供的可视化接口,可以实现图谱的显示功能,其径向图式的显示结果如图4所示。
从图4不难看出,信息检索主题知识图谱可以分为智能化信息处理研究、搜索引擎相关研究、信息系统研究等5个主题。需要特别指出的是,各个研究主题之间并非完全独立,而是存在许多共性和交叉研究。各个主题分别利用Prefuse组件进行树形图谱显示,然后结合关键词进行主题分析。
 | 图4 信息检索主题知识图谱径向图显示 |
类别1为智能化信息处理研究(Intelligent Information Processing),其图谱显示如图5所示:
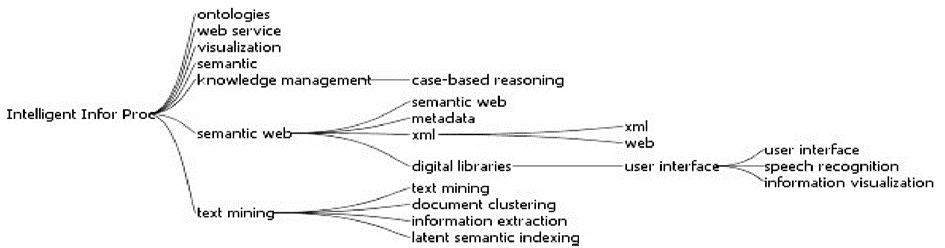 | 图5 智能化信息处理研究中关键词关系图 |
图5显示了智能化信息处理研究中关键词的关系,其中子类中的类目名称为该类目中词频最高的词,类别表示类别内的关键词相对于其他类内的关键词更加相关。图5中共计有21个关键词,其中,前5个关键词的总频次为1 334次,占类别1中关键词总频次(3 068)的43.5%。
目前,智能化信息处理主要研究涉及本体、知识管理、语义网、文本挖掘等。其中,数字图书馆研究与语义网、用户接口、语义识别和信息可视化研究最为相关。
类别2为搜索引擎相关研究(Search Engine-related),其图谱显示如图6所示:
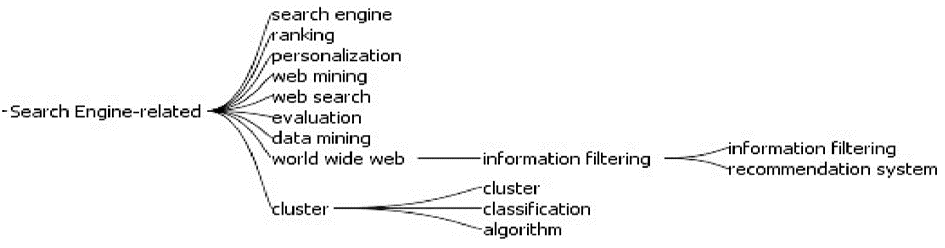 | 图6 搜索引擎相关研究中关键词关系图 |
图6中共计18个关键词,已过滤了表征信息不强的词(如因特网、万维网)。词频最高的5个关键词分别是搜索引擎、数据挖掘、聚类、评价和分类,词频总和为1 247次,占类别2中关键词总词频(2 211)的56.40%,大约30%的词表征了50%以上的信息。
搜索引擎相关研究主要是算法研究、数据挖掘研究以及其他研究。其中,算法有排序和分类聚类以及其他搜索引擎算法研究,数据挖掘主要面向网络方面,其他研究则包括个性化服务、信息过滤研究等。
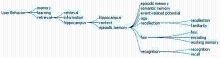
类别3为用户行为研究(User Behavior),其图谱显示如图7所示:
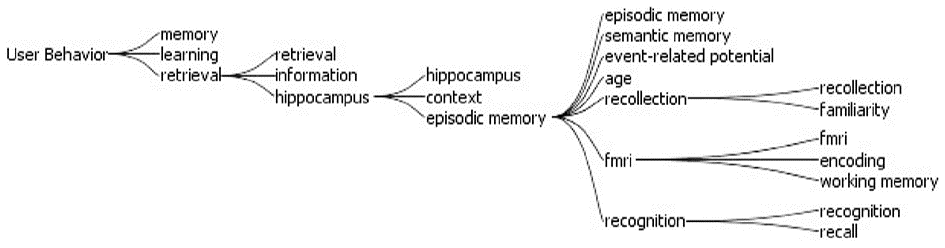 | 图7 用户行为相关研究中关键词关系图 |
图7中共计19个关键词,词频总和为2 689次。其中,海马(Hippocampus)是指大脑的海马区,它是帮助人类处理长期学习与记忆声、光、味、觉等事件的大脑区域;FMRI指功能磁功能成像,主要用于脑功能研究;事件相关电位(Event-related Potential)是指通过平均叠加技术从头颅表面记录大脑诱发电位来反映认知过程中大脑的神经电生理改变。
用户信息行为研究主要开展与用户检索行为相关的心理学研究,包括用户在信息检索过程中所进行的记忆、学习、认知、关注、编码等行为研究,以及与这些行为相关的脑部研究。
类别4为信息系统研究(Information System),其图谱显示如图8所示:
 | 图8 信息系统相关研究中关键词关系图 |
图8中共计24个关键词,总频次为3 038次。其中,遥感、信息存储与建设、索引、自然语言处理、神经网络等5个关键词的词频较高,词频和为1 213次,占类别4中关键词总词频的39.93%。目前,信息检索中信息系统相关研究呈现多学科性特征,涉及医疗、生物、地理信息等众多学科,具体研究内容包括数据库研究、医疗和生物信息学、索引、信息系统和信息管理、地理信息系统以及信息存储与检索等。
本文提出了主题知识图谱构建框架,确定了信息检索领域的研究主题,将信息检索研究分为智能化信息处理、搜索引擎相关、用户行为研究、信息系统研究、基于内容的信息检索等5个部分,并对各主题的具体研究内容进行了简要分析。通过实证研究,验证了基于Prefuse的主题知识图谱框架的实用性和可行性。不足之处在于,在信息检索研究主题名称确认方面,目前只是根据已有的研究成果和笔者的分析结果进行判断,未采用专家访谈法和专家咨询等其他方法,所以有待今后进一步探讨。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|