
{kind=link}
用户兴趣变化感知的重启动随机游走推荐算法研究
[俞琰1, 2  , 邱广华
, 邱广华1, 3 ]
, 邱广华|
|


针对目前重启动随机游走推荐算法忽略用户兴趣变化的问题,提出一种基于用户兴趣变化的重启动随机游走推荐算法。通过聚类识别用户的兴趣,建立用户兴趣模型,在此基础上,考虑兴趣的时间衰减,计算用户当前兴趣度。最后,根据用户当前兴趣度,形成用户转移概率矩阵,并做出推荐。实验表明提出的算法较传统的重启动随机游走推荐算法可以有效地提高推荐精度。
Aiming at random walk with restart recommendation algorithm ignoring user interest shift, this paper propses a new random walk with restart recommendation algorithm based on user interest shift. It identifies user interest by clustering, then creates user interest model on which estimates user’s current interest concerning time decay. Finally, it forms the transition probability to make recommendation according to user current interest. Experiment shows that proposed algorithm can improve the recommendation accuracy efficiently.
近年来,一些大型电子商务服务网站使用推荐系统为用户提供个性化的项目推荐服务,以解决信息过载问题。推荐系统根据用户与系统的交互历史以及用户的个人信息等构建用户的兴趣模型,预测用户可能感兴趣的项目。
最近,将推荐问题转换为图,使用重启动随机游走算法(Random Walk with Restart, RWR)测量图上顶点间相似度的推荐算法得到广泛关注[ 1, 2, 3, 4, 5]。RWR推荐方法具有内容独立、算法简单、考虑图整体结构、 缓解协同过滤数据稀疏性等优点[ 3, 4]。但是,目前的RWR推荐算法[ 1, 2, 3, 4, 5]忽略了用户评分项目的时间因素,没有考虑用户兴趣变化的问题,可能降低推荐精确度。在现实世界中,用户的兴趣经常随时间发生变化。比如,新生儿父母在一段时间内对奶粉有着强烈的兴趣与需求,但是随着孩子的成长,父母对幼儿教育产品可能更有兴趣。然而,传统RWR推荐算法没有考虑用户兴趣的变化,等同地处理奶粉和幼儿教育产品,这将推荐给用户一些他们已经不再感兴趣的奶粉产品。而此时,算法应该能够捕捉用户兴趣变化,推荐用户目前更加感兴趣的幼儿教育产品,从而提高推荐的精度。
本文提出一种用户兴趣变化感知的RWR推荐算法。通过聚类识别用户的兴趣,建立用户兴趣模型。在此基础上,考虑兴趣的时间衰减,计算用户当前兴趣度。最后,根据用户目前的兴趣度,做出项目推荐。实验表明提出的算法较传统的RWR推荐算法可以有效地提高推荐精度。
RWR用于度量图上顶点间的相似度[ 6]。其主要思想是从图中某个顶点出发,沿着图中的边随机游走。在任意点上,以一定的概率随机选择与该顶点相邻的边,沿着边移动到下一个顶点,或以一定的概率直接回到出发点。经过有限次的随机游走过程,图中每个顶点的概率值到达平稳状态,再次迭代也不会改变图中的概率分布。此时,图中每个点的概率值可以看作该顶点与出发点的相似度。
RWR的数学表达[ 6]为:
p(t+1)=(1-α)Sp(t)+ αq (1)
其中,p(t)、p(t+1)和q是列向量。p(t)表示第t步图中的概率分布, 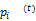
定义1[ 6]:顶点y对于顶点相似度R(x,y)为从顶点x出发重启动随机游走到y的稳定概率。
推荐问题可以转换为图中顶点选择问题,使用RWR度量顶点间的相似度。具体地,一个推荐问题能够被看作一个用户-项目二部图G={U∪I, E},其中U是用户顶点集合,I为项目顶点集合,E表示U×I边。如果用户ui评分项目ij,则在用户ui和项目ij之间存在一条边。
用户-项目二部图被存储在矩阵M中。使用M能够很容易地构建邻接矩阵 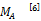
MA=
假设要从行顶点x出发,从一个特定的边
PA(x,y)=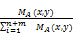
因此转移矩阵PA被构建为:PA=col_norm(MA),其中col_norm(MA)标准化MA的每行的和为1。从目标顶点出发,通过公式(1)的多次迭代,得到从用户顶点到项目顶点的稳定概率分布,将与目标用户最相似且未评分的项目推荐给目标用户。
RWR推荐算法忽略用户兴趣变化,用户相同概率地跳转到评分项目,这将引起推荐系统一定程度偏离用户目前感兴趣的资源。为了能够跟踪和捕捉用户兴趣变化,一种流行的方法是基于最近的想法,它使用时间窗口或衰减函数,强调用户最新行为更能够准确地反映用户当前兴趣[ 7]。时间窗口法通过移动时间窗口过滤过去兴趣,完全忽略窗口之外的数据。衰减函数则认为观察数据的重要性随着时间推移逐渐减少。其中,指数衰减函数[ 8, 9, 10, 11]被广泛应用于时间感知的协同过滤推荐系统中,如下所示:
f(t)=e-λ·t (4)
函数f(t)指定一个关于时间t的指数衰减函数。它表明衰减速度先快后慢,不是一个线性的过程。λ值越大,数据衰减越快,反之,衰减越慢。
指数衰减函数方法更符合人类的心理学规律,但是,现实世界常常存在一种现象:用户往往根据自己以前的购买经验,选择与以前商品较为接近的那些新商品进行购买,即用户当前感兴趣的资源与早期感兴趣的资源可能存在很大的相关性。这种情况往往发生在作为用户长期兴趣的项目之间。这样的兴趣随着时间衰减的速度应该比短期兴趣的衰减速度缓慢。因此,如果能够有效识别用户的长期兴趣,区分不同兴趣对推荐的影响,将进一步提高推荐的精度。为此,本文采用指数衰减函数,并考虑用户长期兴趣和短期兴趣的不同的衰减速度,结合RWR推荐算法,发现用户当前兴趣,以提高推荐精度。
推荐算法
目前RWR推荐算法基于假设:不管项目何时被收集,所有项目具有相同的重要性。这是不合理的,因为一位用户的兴趣可能随着时间改变,不同的项目应该具有不同的重要性。为此,本文提出考虑用户兴趣变化的RWR推荐算法,首先聚集目标用户的评分数据,识别用户的兴趣,进而建立用户兴趣模型,根据不同种类的用户兴趣设置不同的衰减速度,最后结合RWR算法,为用户提供个性化推荐。方法分为4个主要阶段:识别用户兴趣、构建用户兴趣模型、时间衰减用户兴趣和项目推荐。
使用聚类识别相关的项目,以发现用户的兴趣。
定义2:一个用户的兴趣集合P为向量空间P={P1,P2,…,Pk},k表示用户兴趣数目。其中Pi(i∈[1,k])为第i个用户兴趣, 它由用户评分的相关项目的集合组成,即Pi={ii1,ii2,…,iil}。属于相同用户兴趣的项目间存在强相关性。
聚类是数据挖掘中的一个重要技术,它将数据对象划分为多个簇。划分的原则是同一个簇中的对象之间具有较高的相似性,而不同簇的对象差别较大。k-means算法是经典的聚类方法,具有简单、快速、可伸缩性和高效率的优点,但是需要预先确定聚类的数目k,而合理的k值事先不易确定。因此,本文使用改进的Auto-k算法[ 12],它能够自动选择一个全局最优的聚类数目。Auto-k认为最好的聚类结果应该是最大化聚类内部的相似性和聚类之间的不相似性,最小化聚类间的相似性和聚类内部的不相似性。根据Auto-k的思想,笔者提出定义3至定义7量化聚类内部和聚类间相似性。
定义3:项目ip和项目iq之间的相似度S(ip,iq):
S(ip,iq)=
其中,R(ip,iq)表示在用户-项目二部图中,从项目ip出发,到达项目iq的稳定概率。当ip≠iq时,R(ip,iq)≠R(iq,ip), 此处取两者的均值作为项目ip和iq之间的相似度。
定义4:用户兴趣Pi内部相似度Stra(Pi)为:
Stra(Pi)=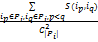
其中,|Pi|是兴趣Pi包含项目的数目,为兴趣Pi中取出两个项目的组合数目。可见,Stra(Pi)为兴趣Pi内部的项目间相似度均值。
定义5:用户兴趣集合P内部相似度Stra(P)为:
Stra(P)=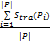
其中,|P|为用户兴趣集合P包含的兴趣数目。Stra(P)为P中的兴趣内部相似性的均值。
定义6:兴趣Pi与兴趣Pj之间相似度Ster(Pi,Pj):
Ster(Pi,Pj)=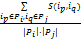
其中,两个兴趣间的相似度为两个兴趣中包含的项目之间的相似度的平均值。
定义7:用户兴趣集合P中兴趣间相似度Ster(P)为:
Ster(P)=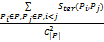
其中,|P|为兴趣集合的兴趣数目。 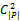
通过最大化Stra(P)和最小化Ster(P)可以优化聚类的结果。但是,最大化Stra(P)和最小化Ster(P)常常不能够同时达到。因此,需要一个两者之间的平衡。结合Stra(P)和Ster(P)为一个单一的标准,使得算法更加实际和方便,如下所示[ 12]:
CF=β·Stra(P)+
其中,β在0与1之间,是一个实验权重,本文设定β=0.5,Stra(P)和Ster(P)对于CF具有相同影响。
识别目标用户兴趣的算法描述如下:
输入:用户-项目评分矩阵;
输出:目标用户若干兴趣;
步骤1:根据用户-项目评分矩阵,使用RWR计算目标用户评分的n个项目之间的相似度;
步骤2:for k=1 to n
选择k个最初的聚类中心;
通过k-means方法聚类群体,得到聚集结果P;
通过公式(5)-(10)计算P的CF值;
结束。
最后,取P=ArgMax(CF)作为最优的聚类结果,用于目标用户兴趣集合。
向量空间模型是目前流行的用户兴趣模型的表示方法。它将用户兴趣表示为k维特征向量{(P1,w1),(P2,w2),…,(Pk,wk)}。向量的每一维由一个聚类产生的用户兴趣Pi以及兴趣度wi组成。权重取实数值,表示用户对某个类别的兴趣程度。这里,假设用户对类似的项目具有相同的兴趣度。某个兴趣中的项目越多,则可以认为用户对这类兴趣度越大。因此,本文提出如下兴趣度wi的定义。
定义8:用户兴趣Pi的兴趣度wi为:
wi=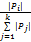
其中,|Pi|为Pi中相似项目数目,它所占总体的项目越多,则它的兴趣度越大。
一些用户的兴趣随着时间快速变化,而另外一些用户兴趣在相当长的时间内保持不变;相同的用户对不同的用户兴趣也有不同的态度,有的兴趣衰减得快,有的衰减得比较慢。一般来说,用户在不同时间对某些类别资源的访问行为基本一致,则可认为用户对该类别资源保持一定的长期兴趣。通过统计用户在不同时间段访问资源类别出现频率估计用户的长期兴趣。为此离散化时间为时间槽。时间槽T为一个时间单位(如7天)。本文定义兴趣Pi的衰减速度λi为:
λi=1-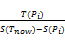
其中,S(Tnow)为目前时间所处的时间槽,S(Pi)为兴趣Pi第一次出现时间所在的时间槽,T(Pi)为Pi中的项目所经历的时间槽的个数。衰减速度为0与1之间的实数,Pi中的项目在不同时间槽出现的次数越多,越可能是长期兴趣,λ越大,兴趣衰减速度越慢。反之,兴趣衰减越快。
这样将兴趣Pi当前兴趣度wi更新为:
wi=wi·f(t) (13)
显然,兴趣的兴趣度越大,则目标用户越有可能跳转到对应的兴趣中的项目。由于目标用户跳转到历史评分数据项目的概率和为1,所以修改用户ux移动到项目ip的概率为:
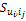
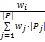
其中,ij∈Pi, 由于目标用户对这些项目具有不同的兴趣,所以目标用户到评分项目的概率不再是等同的,而是与对应项目的兴趣度成正比。
基于用户兴趣模型的推荐算法描述如下:
输入:用户-项目评分矩阵,目标用户ux,用户兴趣模型,重启动概率参数α,时间槽参数T;
输出:按降序排列目标用户未评分的项目列表;
步骤1:根据公式(14)构造转移概率矩阵;
步骤2:构造重启动向量q, 目标用户顶点对应元素设置为1,其余元素为0;
步骤3;初始化目标用户在重启动随机游走中最初的概率分布p(0)=q;
步骤4:根据公式(1)迭代更新p(t)和p(t+1),直到收敛为止;
步骤5:计算得到稳定状态向量,移除用户已经评分的项目,按照降序排列向量中的项目;
结束。
该算法的计算时间主要耗费在Auto-k和RWR计算上。Auto-k的计算复杂性高于k-means方法。k-means的复杂性为O(n), n为一位用户评分项目的数目,Auto-k的复杂性为O(n2),但是一位用户评分的项目较少,所以n值较小,并且高复杂度能够通过选择少数几个可能的分类数目的候选来实现[ 12]。RWR迭代至收敛次数相对稳定(例如,大约20次),这样,可达O(e)的时间复杂度,其中e为二部图边的数目。因为矩阵是非常稀疏的,所以算法非常有效。
为了测试提出算法的有效性,选择南京某高校图书馆2010年12月至2011年11月一年的图书借阅记录作为数据集进行评价。在这个数据集中,用户的评分是隐性反馈。当用户借阅一本图书(项目)的时候,产生一个评分。数据集包含13 746个用户,94 195个项目,197 580个用户-项目对。由于推荐算法需要考虑时间因素,因此使用保留最新方法,即对于一个目标用户,最近的评分被保留作为测试数据,所有其他的评分数据作为训练数据。用户最近的评分时间戳被认为是做出推荐的时间。
本文使用Hit-Rate指标度量推荐准确度[ 13]。当在时间t为用户做出推荐的时候,产生了一列N推荐项目R(u,t), 如果测试项目出现在推荐列表中,则称为一个击中(Hit)。对于一列N(N=10)的推荐项目,Hit-Rate被定义为[ 13]:
Hit-Rate=
其中,|U|是用户的数目,R(u,t)是Top N个在时间t推荐给用户u的项目,iu是用户u最新的实际评分项目,h(·)是一个指标函数,当iu∈R(u,t)的时候,h(iu∈R(u,t))=1,否则h(iu∈R(u,t))=0。显然,Hit-Rate的值越大,算法的精确度越高。
首先测试重启动概率α对重启动随机游走算法性能的影响。根据测试集中用户借阅图书数据,构建用户-项目二部图,不考虑时间因素,α取不同值,得到不同重启动概率α对Hit-Rate的影响,如图1所示:
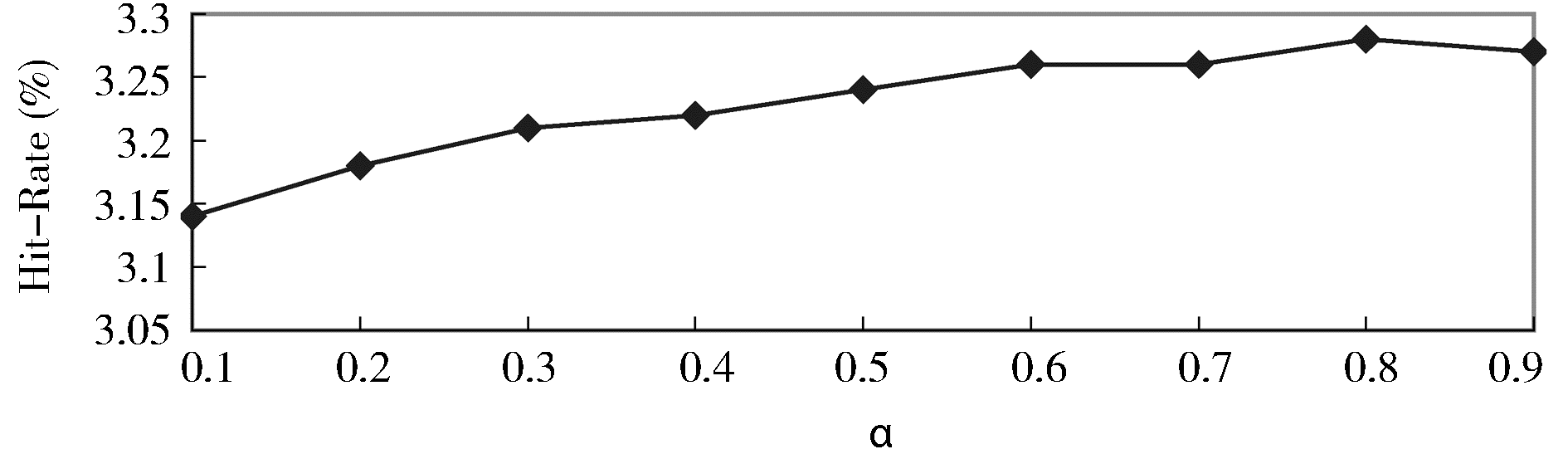 | 图1 重启动概率α对Hit-Rate的影响 |
结果显示α等于0.8的时候,推荐的准确度最高。α为重启动概率,它表示在每一次的随机游走过程中,重新返回初始节点的概率。大的重启动概率意味着局部性而非整体性,小的重启动概率意味着整体性而非局部性,α的选择同图本身的结构有一定的关系。在本文其他实验中,固定α为0.8。
实验研究了时间槽大小对推荐性能的影响。时间槽是一个时间单位,用于统计各兴趣在时间槽中出现的频率,以识别用户长期兴趣和短期兴趣。同类兴趣中的项目在不同时间槽出现的次数越多,该兴趣越可能是长期兴趣,兴趣衰减越慢;反之,兴趣为短期兴趣,兴趣衰减越快。实验首先进行项目聚类,识别用户兴趣;其后构建用户兴趣模型,计算兴趣度。此时,设置不同的时间槽的值,根据公式(12),计算不同时间槽下,用户各兴趣的衰减速度。利用公式(4)和公式(13)计算衰减后的兴趣度,根据新获得的兴趣度构建转移概率矩阵,进行RWR推荐。结果如表1所示:
| 表1 时间槽λ对Hit-Rate的影响 |
可以看出,时间槽值大于7天时推荐具有较高精确度,在时间槽为7天时,Hit-Rate的值最大,为4.78%。用户在一周内的兴趣类似,在一周以上开始发生变化。这与真实的生活经验一致。用户在一周内借阅的图书常常是相关主题的,超过一周之后,兴趣会发生变化,借阅其他兴趣的图书。
为了验证提出算法的有效性,进行传统RWR推荐算法与改进RWR推荐算法的比较。
(1)传统重启动随机游走推荐方法(RWR):根据测试集中用户借阅图书数据,构建用户-项目二部图。图中的顶点是用户集合和图书集合,当用户借阅一本图书,则在该用户和该图书间存在一条边,否则为空。边的值为1,不考虑时间因素,根据公式(2)和公式(3)构建转移概率矩阵,使用RWR算法为目标用户推荐Top N本目标用户最相关且未借阅的图书。
(2)用户兴趣变化感知的重启动随机游走推荐方法(TRWR):根据测试集中的用户借阅图书数据进行聚类,以发现用户兴趣;构建用户兴趣模型,计算兴趣的兴趣度;根据兴趣中项目出现频率,区分用户长期兴趣和短期兴趣,以确定兴趣的衰减速度,并据此重新计算兴趣度;最后根据新的兴趣度,构建转移概率矩阵,进行RWR算法Top N图书推荐。结果如表2所示:
| 表2 TRWR与RWR推荐算法比较 |
结果显示TRWR优于RWR,提高了45.73%。因此,在推荐系统中考虑用户的兴趣变化是非常重要的[ 8],用户的兴趣有所改变,不应该等同看待。本文提出的算法考虑用户兴趣变化,引导随机游走偏向用户更加感兴趣的项目,能够显著地提高推荐性能,这说明该算法在RWR中集成兴趣改变因素对于提高推荐的精度是有效的。
本文讨论了个性化推荐技术中的RWR算法,针对传统的重启动算法未考虑用户兴趣变化,难以有效地反映用户真实兴趣的情况,提出了用户兴趣变化感知的RWR推荐算法。实验结果显示该方法能够有效地提高推荐精确度。近期的工作包括在一个高校图书馆书籍推荐系统中实施部署该算法,进行在线评估,收集用户对该算法运行的实际反馈信息。为了验证该算法的通用性,还将评估其他不同的数据集合。此外,将研究其他可能的时间衰减函数,用于获得更好的推荐性能。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|