{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
科技文献话题演化研究
[贺亮 , 李芳]
, 李芳]
, 李芳]
|
|


提出一种研究话题演化的方法,利用LDA话题模型抽取科技文献的话题,通过计算话题的强度和特征词,研究话题的演化趋势。对NIPS 论文集与ACL论文集进行实验,结果显示了机器学习领域以及计算语言学领域的一些发展状况,从而验证该方法的可行性。
This paper uses LDA model to generate topics from the scientific literature,then calculates the strength and feature key to find the evolution trends of topics. The experiments on NIPS anthology and ACL anthology show the trends of machine learning and computational linguistics, and also prove the feasibility of the proposed calculating method.
科技工作者如何快速地获取相关领域的最新研究动态,是一个值得关注的问题。为了解最新的研究工作,科技工作者会关注该领域的关键问题,这些问题都用到什么样的技术,这些技术的发展历程以及最新特点等。因此,对科学文献的话题演化进行研究,可以帮助科技工作者从大量的学术会议和科技文献中提取出有用的信息,这具有重要的现实意义。
话题演化研究,需要首先从大量的语料集合中提取出潜在的语义信息。Blei等[ 1]提出的LDA模型可以挖掘大规模语料的语义信息,是机器学习、信息检索等领域很流行的一个模型。因此,目前国内外相关研究中,对文本语义信息进行挖掘通常都使用LDA或其扩展的话题模型。
本文首先利用话题模型即LDA模型对语料建模,挖掘出该领域中相关技术或研究子领域,然后研究这些技术及子领域在整个时间段上的演化情况。
对于科技文献的研究,主要是利用其作者、文本信息、引用信息和时间信息,进行话题的发现和演化的分析工作。
即挖掘文献中的隐含的语义信息。目前主要有两类方法:
(1)利用话题模型进行话题发现,这里话题(Topic)的定义是一组词的概率分布。根据文集的文本信息可以利用LDA及其拓展模型(CTM、DTM等)进行建模[ 2, 3],发现话题;如果结合作者信息,有作者话题模型(ATM)及其拓展模型(ACT、TATM等)[ 4, 5, 6],通过对该模型的推导可以得到每个作者在话题空间上的分布,通过分析该分布就可以了解在某一特定领域(话题)都有哪些专家,以及这些专家关注的研究领域(话题)是什么;结合文献引用信息,即考虑到文献间引用关系对话题生成过程的影响,有继承话题模型(ITM)[ 7]。
(2)通过构造网络图,利用文献的文本信息以及文献间的引用信息进行话题发现。有学者使用词组(Term)来表示话题,然后利用词组在文集中的分布关系并结合文集之间的引用关系发现话题[ 8]。
话题会随着时间属性变化,往往反映在两方面:话题强度随着时间的推移而发生的变化,话题内容随着时间的推移而发生的变化。根据如何结合话题模型的生成和时间属性的关系,可以将基于话题模型的话题演化分为三种方法:
(1)将时间信息作为可观测变量,结合到LDA话题模型中。基于这种方法的模型是TOT(Topic Over Time)模型[ 9],它不依赖于马尔科夫假设,而且将时间看作是连续的可观测变量。
(2)利用话题模型对整个时间段上的文集进行建模,再检查话题在时间上的分布来衡量演化,即事后检验的分析。有学者利用话题的后验概率去定义话题的强度[ 10, 11],通过计算每个时间点上的强度得到其强度的变化趋势,对这些话题的变化趋势进行分析,以捕获科技发展的一些特点,例如一些技术的应用走向,是偏向理论性的研究还是偏向于实际应用等[ 11]。斯坦福大学的一个开源话题建模工具TMT[ 12]也是基于这种方法进行分析,通过简单地统计不同时间段的词频得到话题内容随时间的变化。
(3)将文档根据其时间信息离散到时间序列上对应的时间节点,依次地处理每个时间节点上的文档,然后根据每次话题的变化,形成话题随时间的演化。有学者直接利用动态生成模型(DTM、ITM)对文档建模得到话题演化结果[ 3, 7],也有学者利用各时间段话题关联的方法衡量话题演化[ 13]。
为了提出一种方法能够针对任何文集, 例如新闻报道[ 13]、数字文献等, 本文只考虑文献的时间和文本信息,而忽略作者和引用信息。采用LDA话题模型,找到潜在话题并对话题的强度和内容这两个特性进行研究,提出不同的计算公式,通过这两个特性的分析可以找到热点话题以及话题的演化特性。
本文的方法可以分为两个步骤:
(1)LDA话题的生成。这部分主要利用LDA模型对整个时间段文集进行建模,抽取话题,并且获得LDA模型的后验参数。
(2)话题的演化研究。按照一定的时间粒度,将文档集合离散到相应的时间窗口中,然后依次处理每个子文档集合。计算这些子集中话题的强度,可以得到话题强度趋势变化;利用本文提出的话题特征词即为话题内容的表示,计算这些子集话题的特征词,可以得到话题内容演化情况。
LDA模型是三层的变参数层次贝叶斯模型,假设一篇文档是由一些潜在的话题混合表示的,而每一个话题是由词及其在话题上的概率分布表示的。
对文集进行整个时间段上的建模,根据LDA话题抽取的结果,定义话题的支持文档如下:假设某一文档d中有至少10%的词是由话题z生成的,那么该文档是话题z的支持文档。根据该定义,一篇文档可以支持多个话题。本文使用的符号如表1所示:
| 表1 文中使用到的符号 |
应用LDA模型训练文集,在这一过程中忽略文档的时间戳信息。根据文档的时间戳,划分各个子集,通过话题在这个子集上的分布描述话题在这个时间上的状态。本文对话题的趋势分析包括两个方面:话题强度和话题内容。通过研究话题的强度和内容如何随时间变化,可以得到话题的发展轨迹以及演化路径。
(1)话题强度计算
话题强度主要描述了话题的关注度,也就是说,讨论某话题的文章数越多,说明该话题的强度越高,可以被认为是热门话题。
话题的强度使用文献[14]中提出的文档支持率进行描述。通过计算话题每年的强度,即可以得到话题强度在时间上的变化趋势。时间间隔t的话题z的文档支持率S(z,t)计算公式如下:
S(z,t)=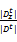
其中,分子表示t时间段话题z的支持文档个数,分母表示该时间段文档的总数。
(2)话题内容计算
话题的内容使用特征词来表示。一般来说,在LDA模型下,话题通常使用概率最高的一些词来表示,但是这种表示方法无法表现出话题在不同时间段中的特征。因此,本文参考向量空间模型中TF-IDF权重的计算方法,提出一种在LDA模型下的类TF-IDF权重。在LDA模型下,文档中每个词都被分配到一个话题下,通过计算话题z在时间段t的词w的类TF-IDF值,选取类TF-IDF值最高的10个词作为该话题z在时间段t的内容表征。
首先计算类TF值,即统计话题z下词w的词频,公式如下:
tf'(w,z,t)=
其中,分子为t时间段所有文档中被分配到话题z下的词w的个数,分母为t时间段话题z下所有词的个数。
计算类IDF值,即统计话题z下词w出现在多少个时间段内,公式如下:
idf'(w,z)=log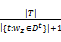
其中,|T|为划分的时间段总数,|{t:wz∈Dt}|表示包含属于话题z的词w的时间段数,为了防止分母为0,分母加1。
这样计算出来的类IDF值会使得话题z下的主要表意词(一般来说是类TF值最高的那些词)的类IDF值很低甚至小于零(因为主要表意的词显然会出现在每个时间段中),因此为了降低类IDF值的影响权重,在计算最终的类TF-IDF值时,给类IDF值加上1,从而公式变为:
tfidf'(w,z,t)=tf'(w,z,t)×(idf'(w,z)+1)(4)
本文对机器学习领域和计算语言学领域的发展趋势进行研究。NIPS会议是神经计算和机器学习领域最好的会议之一。ACL论文集包括了所有计算语言学主流的会议论文,涵盖了该领域的主流的研究内容和技术。因此,本文将NIPS论文集[ 15]和ACL选集[ 16]作为研究的语料数据集。
实验利用Gibbs Sampling方法进行参数的推理,使用了开源的Gibbs Sampling工具[ 17],模型参数α,β分别设置为 50/K和0.01。
实验数据分为NIPS论文集和ACL论文集。其中NIPS论文集选取了从2003年至2010年间总共1 832篇文章。ACL论文集包含了ACL、COLING、EACL、EMNLP等众多会议,选取其中1985年至2009年间总共11 072篇文章。以上语料只取标题和摘要,并过滤停用词、低频词等。
对NIPS论文集进行LDA建模,话题个数设为50。然后通过公式(1)计算话题每年的强度,比较话题的强度,发现热门话题。
通过计算,2007年至2010年每年最热门的5个话题如表2所示:
| 表2 2007年至2010年热门话题 |
可以看出,NIPS会议中近几年来最热门的话题并不是固定的,主要集中在:马尔科夫决策过程(MDP)、神经网络(Neural Network)、机器学习方法(Learning Methods)、高斯过程(Gaussian Process)以及话题模型(Topic Model)。
为了进一步了解NIPS会议近年来的研究状况,将利用话题逐年的强度变化和内容变化来分析NIPS会议的变化趋势。
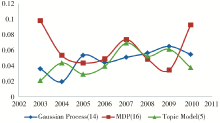
选取三个近几年的热门话题进行分析,如图1所示:
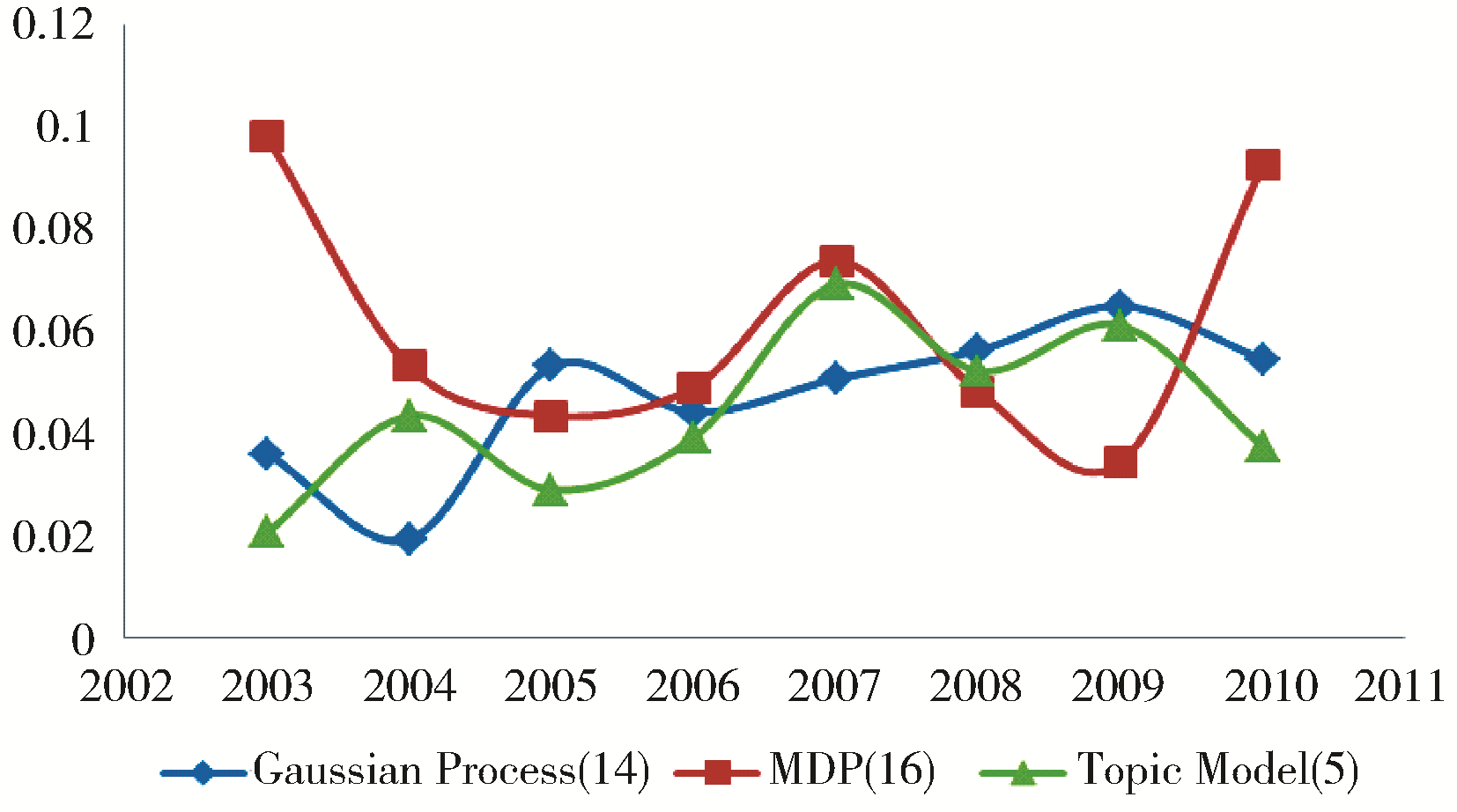 | 图1 NIPS热门话题强度变化趋势 |
可以看出,虽然同为近几年的热门话题,但它们的变化趋势也不尽相同,高斯过程(Gaussian Process)的话题强度基本保持着上升的势头;话题模型(Topic Model)在2003年出现后也吸引了很多研究者的目光,但在2007年之后对该技术的研究热情开始下降;而马尔科夫决策过程在2003、2004、2006、2007以及2009年都是NIPS会议最热门的研究领域之一。
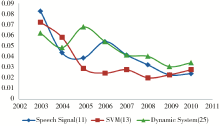
另一方面,语音信号(Speech Signal)、支持向量机(SVM)、动态系统(Dynamic System)这些技术呈现出了明显的下降趋势,这表明NIPS会议对这些领域的研究或是对这些技术的使用越来越少,如图2所示:
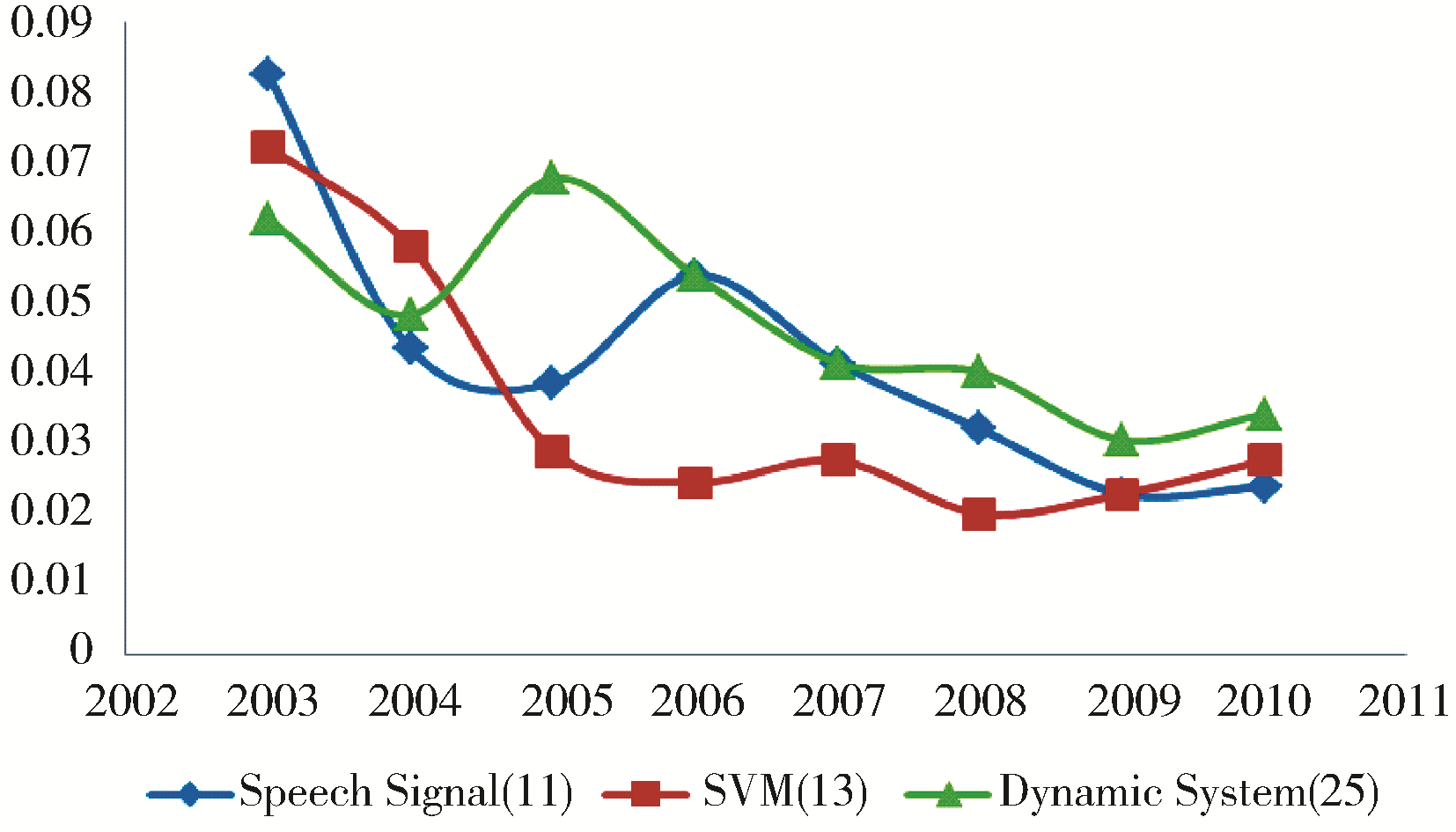 | 图2 NIPS冷门话题强度变化趋势 |
以核方法(Kernel Method)为例研究话题的演变情况,考察该技术在NIPS会议上的研究动向。
使用公式(2)-公式(4)计算该话题的类TF-IDF值,选取每年TF-IDF值最大的10个词作为该话题在当时的内容,可以得到该话题的内容演化路径,如表3所示:
| 表3 核方法的内容演化情况(2003-2010) |
可以看出,在2003-2010年间,前几年核方法相关的技术研究没有太大变动,但是从2008年开始出现了特征词多核学习(Multiple Kernel Learning,MKL),并在之后两年都处于比较靠前位置。这说明了多核学习技术作为一个比较新的技术,在2008年后引起了参与NIPS会议的研究者的关注。
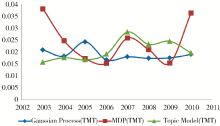
使用斯坦福大学提供的开源话题建模工具TMT作为Baseline方法对NIPS文集进行建模分析,与本文的方法得到的实验结果进行对比。
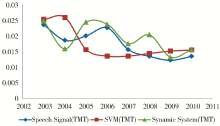
选取与4.2节相同的热门话题与冷门话题,得到它们的强度变化趋势如图3和图4所示:
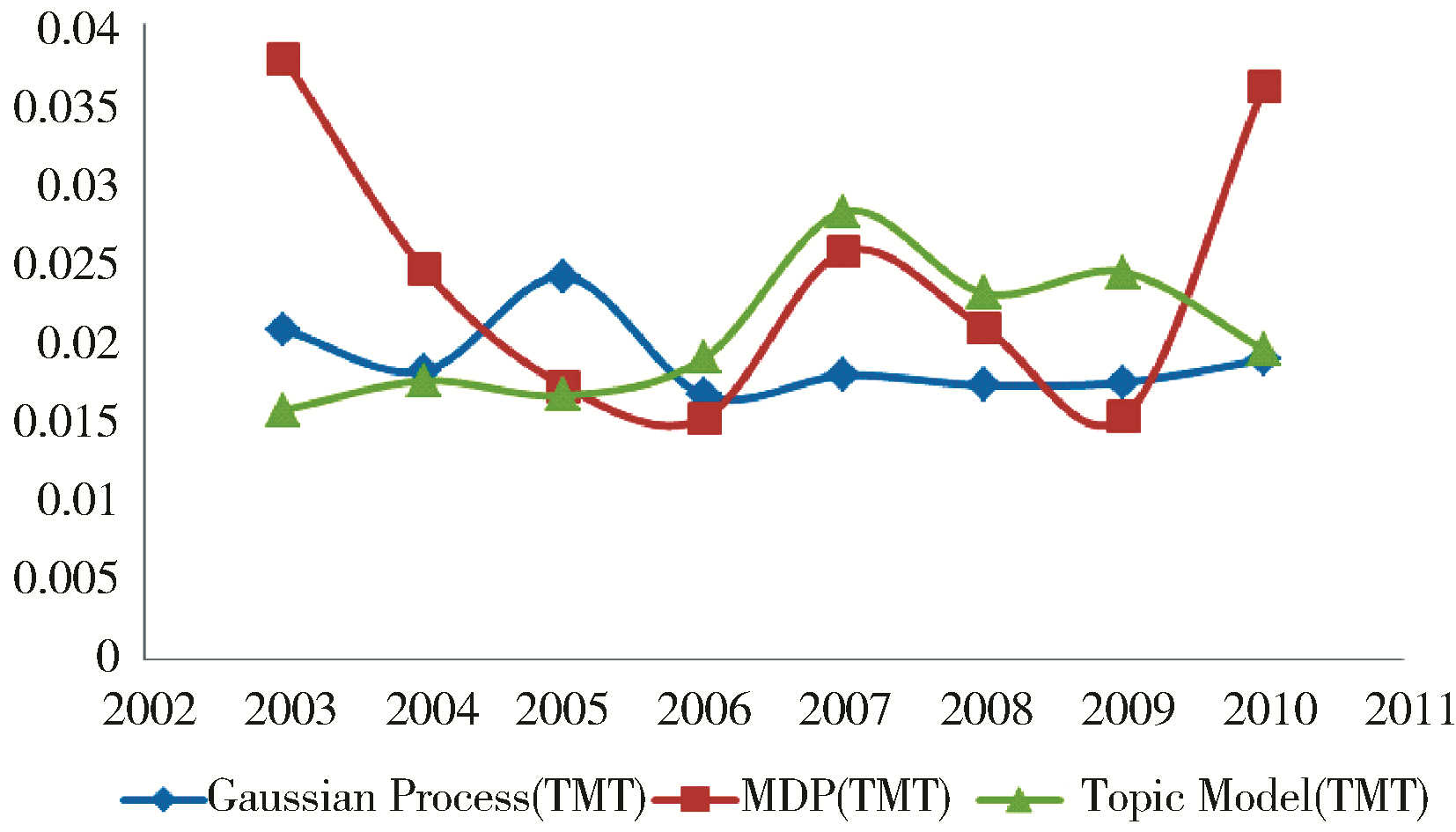 | 图3 NIPS热门话题强度变化趋势(TMT) |
同样选取核方法得到其内容演化情况,如表4所示:
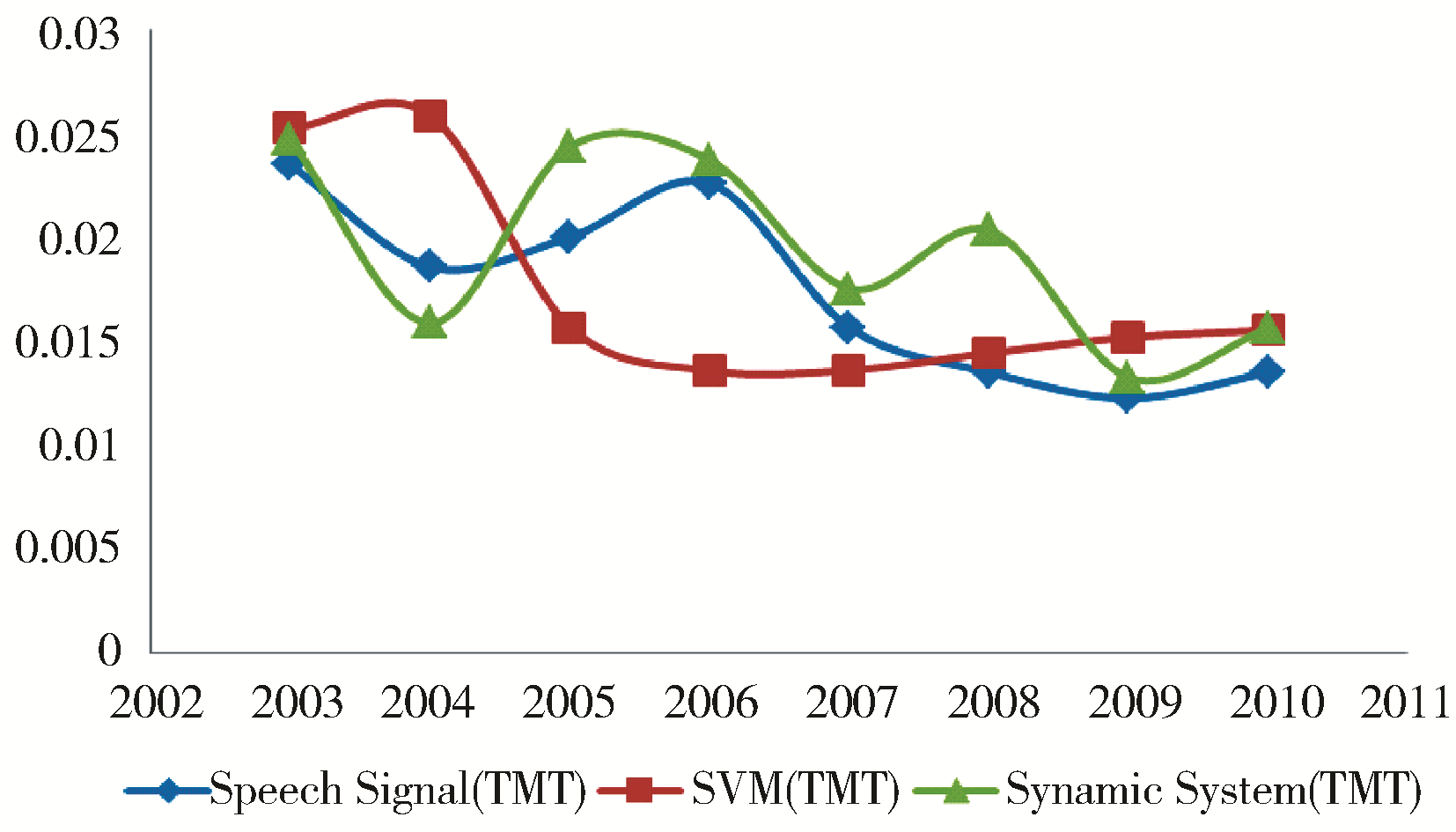 | 图4 NIPS冷门话题强度变化趋势(TMT) |
| 表4 Baseline方法得到核方法的内容演化情况(2003-2010) |
通过对比可以发现,在话题强度演化,包括热门话题的演化(图1和图3)以及冷门话题的演化(图2和图4),得到的变化趋势状况基本一致;而在话题内容演化上(表3和表4),Baseline方法只在2009年探测到了多核学习技术(MKL)的出现,本文的方法在2008至2010年中均发现了该技术。据查,2008年NIPS会议上确有相关的文章如《Multi-label Multiple Kernel Learning》,2010年也有相关文章如《Multiple Kernel Learning and the SMO Algorithm》,因此本文的方法比Baseline方法要更精确。
对ACL论文集进行LDA建模,话题个数K设为100,然后通过公式(1)计算话题每年的强度,比较话题的强度,发现每年的热门话题。
对于热门话题和冷门话题的强度变化趋势在文献[13]中已有完整的分析,从内容上来分析话题变化趋势情况,以基于统计的机器翻译(Stat.MT)为例,分析该领域近年来的技术变化情况。
同样方法得到该话题的内容演化路径,如表6所示:
| 表6 基于统计的机器翻译的内容演化情况 |
从表6可以总结出基于统计的机器翻译领域近20年的技术变化趋势,例如从基于例子的方法(Example-based)向基于短语的方法(Phrase-based)转变,以及BLEU评分方法在该领域的盛行,如图6所示:
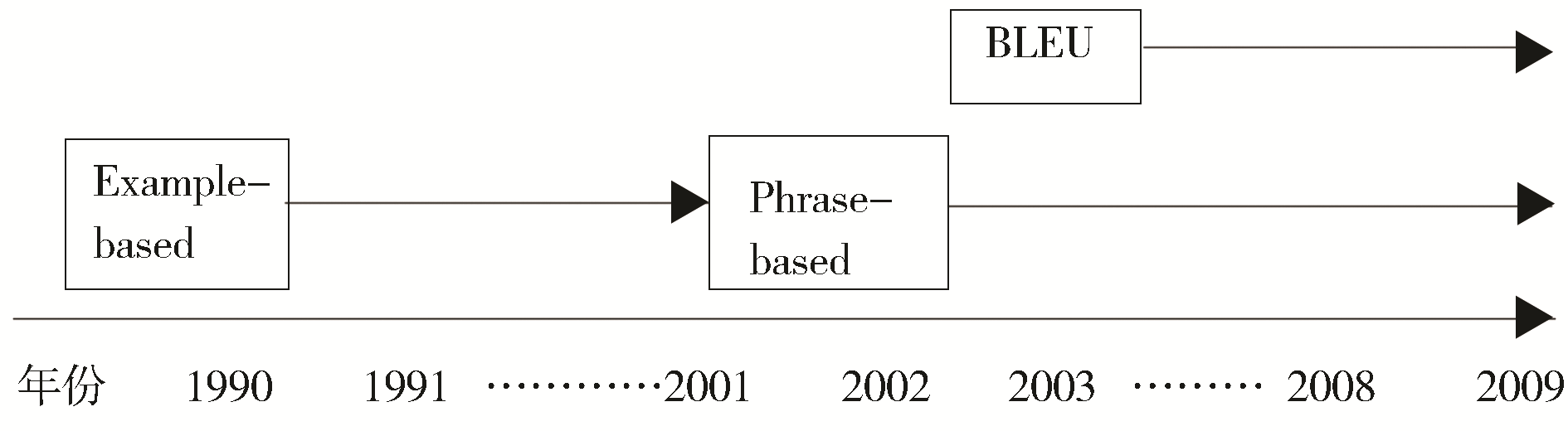 | 图6 基于统计的机器翻译的技术趋势图 |
通过查阅文献, BLEU方法在ACL会议上首次出现是2002年的《BLEU: A Method for Automatic Evaluation of Machine Translation》,到目前该文章被引用达2 000多次,说明该评分方法的重要性,这与本文的结果是一致的。
机器翻译这个话题在整个时间段上都出现,类似的如语义角色(Semantic Role)话题,通过分析其演化情况,可以看出在2004年后PropBank语料库在该领域相当流行。针对另一类话题,即新话题,比如情感分析,分析其演化情况,可以看出在2002年后该领域出现意见挖掘的技术研究,2004年开始出现情感分析的技术研究。但在2002年之前,该方法抽取出的特征词都杂乱无章,没有实际含义。这是因为在2002年之前该话题强度基本都趋于零,说明该话题还不存在,因而得到无意义的特征词。
使用上述方法对其他话题进行分析,展示出ACL会议中的一些其他趋势,包括基于语法的研究(如范畴语法)变得冷门;一些机器学习方法(如核方法、SVM)从20世纪90年代末开始被大量地运用到计算语言学的研究中。与同样研究ACL会议的文献[11]中的结论进行对比后发现,本文的结果与文献[11]大体一致,但也有一些新的发现。例如在文献[11]中提到,关于语义学(Semantics)的总体研究趋势是一个下降的趋势,但本文的结果发现了语义学的子领域语义角色(Semantic Role)研究却是一个上升的趋势。同时,在文献[11]中只展示了话题的强度变化情况,但本文的实验结果还能展示话题的内容演化情况,例如在1994年后Penn-Treebank在语法解析(Parsing)领域成为主要的语料库等。
通过对上述两个会议的实验,可以分别得到它们各自的发展特点。有一些话题在两个文集上都有出现,比如机器学习方法话题。通过比较它们的演化情况,可以发现,在ACL论文集中,机器学习方法主要作为解决计算语言学领域问题的一种手段,大多用到主动学习(Active Learning)的方法;而在NIPS论文集中,机器学习方法则是作为研究对象,研究的技术除了主动学习外,还包括半监督学习(Semi-supervised )、多实例学习(Multiple-instance)、多标签学习(Multi-label)等。
本文方法也存在一些不足,主要体现在话题演化结果精度上的偏差。例如,在NIPS会议中,多核学习方法首次出现在2008年,但事实上在2005年的NIPS会议上就有一篇关于多核学习的论文,之后两年没有相关研究的论文,直到2008年后开始出现多篇多核学习的论文,通过观察话题历年特征词演化分析,2005年该特征词出现太少,因而没能在2005年发现该方法。
在分析、借鉴近年来国内外研究工作的基础上,本文提出了科技话题特性分析以及科技话题趋势分析的方法。介绍了如何利用话题模型的方法对科技文献进行建模分析,包括话题抽取过程、热门话题评判规则、话题特征词的计算选取方法;利用ACL文集以及NIPS文集进行大量实验,总结出计算语言学与机器学习领域的一些发展特点,并将结果与其他方法得到的结果进行对比;验证了本文的方法对科技文献的分析是行之有效的。
本文的核心工作在于提出了一种LDA模型下的类TF-IDF评分方式,能分时段计算话题词权重,从而得到话题在不同时间段上的特征词,最终形成话题的演化路径。通过该方法得到的话题演化路径既不用考虑话题同一性问题,同时又能挖掘出不同时间段的特征,拥有较高的准确度。
未来可以进一步改进抽取特征词的方法,以获得更高的精确度;还可以考虑进一步挖掘话题的特点,更好地探索话题之间的关联。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|