
{kind=link}
{kind=link}
{kind=link}
个性化服务中跨系统用户建模方法研究综述
[牛亚真1, 2  , 祝忠明
, 祝忠明1 ]
, 祝忠明|
|


系统地分析和总结跨系统用户建模的主要方法基于统一用户模型的方法,主要是试图通过构建标准的本体或者通用的用户模型来满足不同系统的个性化需要;基于用户模型间映射和融合的方法,主要通过一定的映射规则对不同系统中用户模型进行映射和融合,实现跨系统的个性化服务;分布式开放用户建模方法,主要是基于社交网络、互操作、关联开放数据等来构建用户模型。通过对这些方法的比较分析,指出跨系统用户建模的发展趋势。
This paper summarizes and analyzes the main methods of cross-system user modeling. The first one is a top-down approach, involving standard Ontologies or unified user models; the second research direction is a bottom-up approach based on mappings between different user model representations; the third one is distributed and open user modeling, based on the Social Web, interoperability and LOD. Finally,it points out the tendency of the cross-system user modeling.
个性化服务的一般过程可以概括为:收集与用户相关的数据;根据收集到的数据推断出用户的特征喜好和需要;对系统进行定制,满足用户的需要。其中,用户建模是个性化服务的核心和基础。一般地,系统单独地构建各自的用户模型,同一用户在不同系统中会具有不同的用户模型。这就造成:同一用户的信息(如登记注册信息等)会在不同系统中重复出现,造成数据冗余;当新用户登录系统时,由于系统中没有或者只有很少的与新用户相关的数据,容易导致冷启动(Cold Start)问题[ 1]。构建跨系统的用户模型可以很好地解决上述问题。跨系统的用户建模是在多应用场景中,以用户为中心构建能够满足不同系统需要的用户模型[ 2]。利用这种方法可以更有效地捕捉和组织用户的兴趣和爱好,同时实现不同系统中用户数据的共享和重用。
这是一种自上而下(Top-down)的方法,试图定义标准的本体或者通用的用户模型来满足不同系统的个性化需要,主要关注用户模型本身的可重用性。早在20世纪末,已经有很多学者对此进行了相关的研究[ 3]。下面介绍和分析几个典型实例:
(1)OntobUM
OntobUM是一个基于本体的统一用户模型框架,由Razmerita等[ 4]于2003年提出,试图以本体作为构建用户模型的标准。OntobUM框架集成了三个本体:用户本体(定义了用户的不同属性及其关系)、领域本体(定义了特定领域和应用的概念及其关系)、日志本体(定义了用户与应用系统之间的交互产生的语义关系)。为了使用户模型通用,OntobUM把数据存储成RDF/RDFS的格式。该模型通过用户模型的本体编辑器(UPE)提供显性定义,生成用户本体;同时,通过智能服务(Intelligent Services)工具更新和维护用户模型产生的隐性数据,提供个性化服务。
这种方法主要关注用户模型本身的可复用性,目标在于开发出一种支持用户模型重用的描述语言和表示方式。该方法在知识管理系统(KMS)中得到了应用,主要是试图构建一种可以被不同系统接受的本体,从而使由本体集成的用户模型在不同系统中适用。OntobUM也可以应用于其他不同领域的本体环境中,这充分体现了本体的可重用性。但是,由于本体设计是依赖于用户的知识和研究者的经验,设计本体的精确性并不高。
(2)UUCM
Niederée等[ 5]于2004年提出了UUCM(Unified User Context Model),它是一种基于本体的统一用户情境模型,不仅描述了用户的相关特征,而且结合了用户的工作情境信息。其中,对于关系的描述,既描述了用户之间的关系,还描述了给定领域中的资源之间的关系。该模型基于“情境护照(Context Passport)”来抽取和聚合不同的个性化系统收集的用户数据,通过跨系统交流协议CSCP(Cross-System Communication Protocol)交换用户信息,是一个可扩展的多维度用户模型。同时,还用到了“元模型(Meta-model)”,这实际上是一种可共享的本体,不同的系统正是依赖此共享本体来实现个性化的服务。
“情境护照”是一种隐喻性的说法或概念,它是把用户及其情境信息封装为“Context Passport”,使之可以伴随用户在跨系统之间流转和使用,通过出示“情境护照”,提供用户情境信息,从而获得情境化敏感的或个性化的服务。这种方法要求所有的个性化应用系统必须依照UUCM框架构建用户模型,并且支持CSCP协议,这在实行中有很大的限制。研究者们试图利用机器学习技术来解决这种限制,但是这需要大量的用户访问不同系统,产生有规则可循的用户群数据。
(3)GUMO
Heckmann等[ 6]于2005年提出了GUMO(General User Modeling Ontology),作为在语义网环境下分散的用户模型的一种统一表示。该方法是采用OWL表示用户模型的词汇和相互关系,OWL本体语言为定义本体提供了一种富表达力的语言,能够捕捉领域知识的语义。GUMO中的用户模型是根据UserML[ 7]设计的,UserML把用户模型的维度分解成Auxiliary、Predicate、Range三个部分。例如,某用户的兴趣是足球,可以表示成:auxiliary=hasInterest,predicate=football,range=low-medium-high。
利用GUMO的优势在于它的语义一致性很强,用户模型数据被融合入本体中,并且以可折叠树的形式浏览和访问。把本体引入到用户建模中,给用户模型带来了丰富的语义,极大地提高了系统的自适应性[ 8]。GUMO利用OWL构建复杂的用户模型概念,并以图的层级形式表示出来,这样可以表达相当全面的用户模型的特征维度。目前,GUMO已经在用户模型服务和泛在服务中有了广泛的应用。
从上面三个实例可以看出,为了满足不同系统间信息的交换,这些方法引入了本体的概念,利用本体的共享性和可重用性构建统一的用户模型。然而,所有的应用系统采用统一的用户模型,意味着用户特定领域的特征不能够被充分地表达。
这是一种自底向上(Bottom-up)的方法,通过映射技术对不同系统中用户模型的数据进行聚合,完善用户模型,为系统提供更丰富的用户信息,从而满足不同系统间的个性化服务。下面介绍和分析两个典型实例:
(1)GUC
GUC(Generic User-model Component)是一个利用语义网技术表达用户模型的通用元件,由 Sluijs等[ 9] 在2005年提出。它既提供存储用户数据模型的功能,又支持模型中用户数据的交换。GUC的每一部分都有明显的界线,应用程序和用户是相互独立的。对每一个应用程序,都有一个模式映射到联合的本体;对每个用户,都有一个UAV知识库(User Application-View Repository)存储用户的信息。该方法通过一个描述不同系统用户模型的数据结构的模式,使用匹配和融合技术构建一个可共享的用户模型;同时,通过基于数据调谐(Data Reconciliation)规则的模式映射来完成不同系统间的数据交换。
模式映射方法在GUC中是应用的关键,很好地起到了交换数据的作用。GUC很容易配置,主要应用于自适应网络信息系统(AWIS),可以与AWIS关联在一起。实施GUC框架强调配置的灵活性,然而目前GUC的可扩展性并不突出。不同的应用系统必须经过订阅才能向GUC上传数据,这给很多系统造成了不便。另外,用户需要知道哪部分信息被应用,所以用户的隐私权和授权认可问题需要解决。
(2)SUM
2005年,González等[ 10]提出了一个基于多代理的智能用户模型SUM(Smart User Model),用来支持异构的分布式环境中的跨领域的个性化推荐。在该模型中,使用属性-值(Attribute-Value)对的集合来表示用户特征,利用智能代理技术获得单个的用户模型,然后对用户模型进行聚合。SUM不仅从推荐系统中学习用户的特征,还可以把用户的特征传递给其他的推荐系统。为了使SUM可以在不同领域的系统中应用,首先定义应用领域i中的用户模型(UMi)。通过加权图G(SUMi,UMi)构建SUM和UM之间的关系,并且由加权图数据填充用户模型。
该模型中结合了智能自适应控制系统(Smart Adaptive Systems)、智能代理(Intelligent Agents)、支持向量机(Support Vector Machines),其中智能代理的应用主要是为了使不同版本的用户模型被包含在一个统一的用户模型中。SUM还采用了机器学习法中的归纳法和演绎法,实现了开放的、分布式的、异构的推荐系统中的个性化服务,用户可以在不同领域中相互交流信息。另外,情感因素[ 11]的引入可以更加全面地描述用户的特征。目前,该模型还处于研究阶段,没有实际的应用。
从上面两个实例可以看出,这些方法大多是通过映射技术来融合不同的用户模型,可以是异构的用户模型共存,也可以是把分布式的用户模型实例聚合成一个用户模型。
构建跨系统的用户模型,关键是实现用户模型的复用。通过分析以上实例,可以从用户特征表示方式、用户模型复用方法、关键技术支撑以及模型的可扩展性和自适应性几个方面进行比较分析,如表1所示:
| 表1 跨系统用户建模方法特征比较 |
可以看出,这两类方法都是基于语义网技术的支撑,本体在用户模型的复用中起到了很大的作用。正是基于本体的复用性和共享性,很多系统都试图利用本体来实现与其他系统之间的交流。第一类方法自上而下,致力于构建一个可以适用于所有系统的用户模型,从而实现跨系统服务;第二类方法自底向上,主要考虑如何把不同系统间的用户模型映射和融合成一种统一的形式,从而可以在不同系统间相互交换数据。实际上,构建一个可以满足所有系统需要、满足所有情境的通用本体并不容易。尽管这种方法可以实现模型的共享和系统间的交互,然而,现实中很难让系统由原本已有的用户模型向新的共享模型转换。与基于统一用户模型的方法相比,基于用户模型的映射的方法显得比较灵活。然而,由于不同系统中数据的异构性,不同用户模型模式映射过程会比较繁杂。
开放用户建模
在语义网环境下,跨系统的用户建模方法已经由集中控制系统向动态联合的服务系统转变。很多学者对此进行了研究,下面介绍几个典型实例。
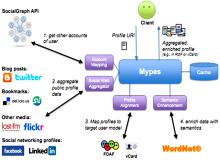
Mypes提供了一种连接社交网络(如Facebook、LinkedIn)、社会媒体(如Flickr、Delicious、Twitter)、Google等应用中不同用户模型数据的服务,可以对异构的数据进行一致化,并且能够通过WordNet[ 12]来增强用户模型的语义化。Mypes使用户可以浏览分布在不同系统中的用户模型数据,同时以RDF或vCard的格式使应用系统对用户模型进行聚合、语义增强。Abel等[ 13]于2010年利用Mypes聚合了基于表单(Form-based)和基于标签(Tag-based)的用户文档,并且构建了社会网络的用户模型,包括账户映射(Account Mapping)、用户模型数据的聚合(Profile Aggregation)、用户模型数据的对准(Profile Alignment)、语义增强(Semantic Enrichment)几个部件,如图1所示:
 | 图1 基于Mypes的用户模型数据的聚合和语义增强[ 13] |
该方法通过对基于表单和基于标签的用户模型数据的聚合和语义增强,涵盖了用户的显式数据和隐式数据。主要采用基于WordNet的语义增强,以便对基于标签的用户数据进行很好的归类。该模型的实现还需要多方面的支持:APIs标准(如OpenSocial[ 14]),验证与授权协议(如OpenID[ 15]),开放授权(如OAuth[ 16]),Web标准(如RDF、RSS)和具体的微格式(如hCard[ 17]或RelTag)等。基于Mypes的跨系统用户建模方法能够更加全面地捕捉用户的信息,提高用户推荐系统的质量。不同系统中的用户模型数据相互补充,很好地解决了系统的冷启动问题。随着FOAF[ 18]、SIOC[ 19]、GUMO[ 6]等标准的出现,连接分布式的用户数据变得容易起来。
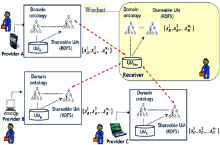
Carmagnola[ 20]于2009年提出了用户模型互操作的逻辑架构,利用互操作性很好地解决了分布式用户模型的语义异构问题,如图2所示:
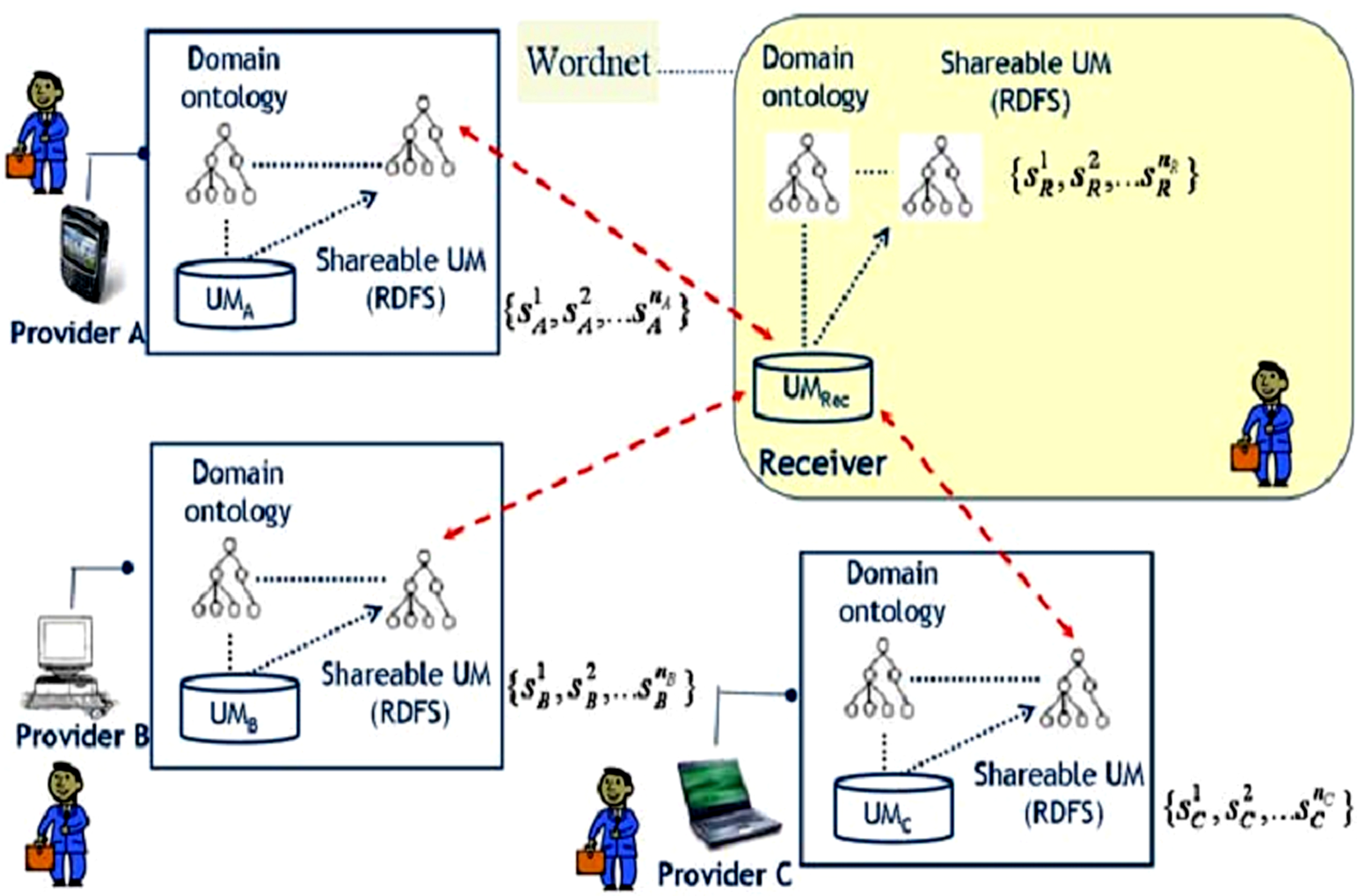 | 图2 用户模型互操作的逻辑架构[ 20] |
每个系统都有一个可共享的用户模型,并且与领域本体相关联。需要用户模型数据的系统(Receiver)从已具有可共享用户模型的系统(Provider)中获得用户数据,再结合特定的领域本体构建属于自己的用户模型。
本方法实现了跨系统的用户建模,通过共享和重用用户数据,采用共享的词汇格式(如FOAF、vCard等)来表示用户模型不会产生数据异构的问题。在开放动态的环境下,要求所有的系统采用共用词汇表的方法是不切实际的。该方法采用中间解(Intermediate Solution)和语义映射技术来表达用户模型,具有很好的灵活性。然而,要求每个系统维护一个可共享的用户模型才能进行互操作过程,用户模型数据的任何变化都需要复制到可共享用户模型中。而且,用户模型的互操作过程需要很多方面的计算能力,导致反应结果的推迟。为了适应动态的变化,系统需要定期地检查与更新用户模型。
随着关联开放数据(Linked Open Data,LOD)的产生和应用,用户在Web上已不是单一孤立的个体,用户在不同系统之间、不同的用户之间都存在着潜在的关联。目前,在Web上已经产生了很多相互关联的用户数据,利用关联数据构建用户模型是一种很好的尝试。2011年,Ye等[ 21]提出了基于CUM(Core User Model)的用户建模框架,主要包括概念映射(Concept Mapping)模块、关联(Interlinking)模块、更新(Updating)模块,如图3所示:
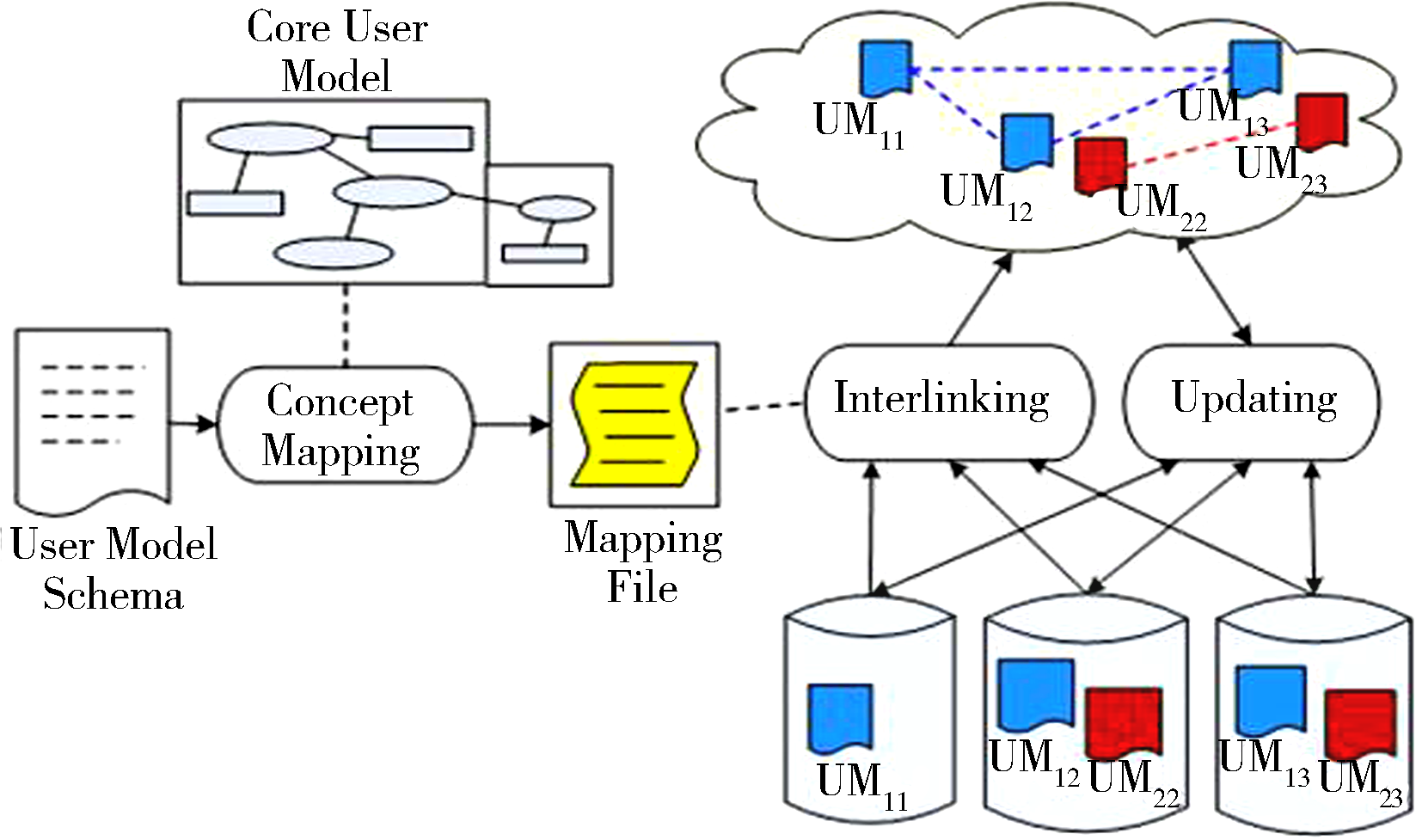 | 图3 关联数据驱动的用户建模框架[ 21] |
其中,用户模型模式(User Model Schema)是对用户模型的抽象描述,定义了用户模型的组成元素。通过概念映射,形成映射文件,包括概念之间的一致性、术语的联合和特定领域的词汇。根据映射文件进行关联,对于少量的数据可以人工完成。大量数据需要自动地完成关联[ 22],通常使用基于模式的匹配(Pattern-based Matching)和基于属性的方法(Attribute-based Methods)。该方法采用核心用户模型(Core User Model, CUM)来描述用户共同的属性和特定领域的特征,并以FOAF的形式来表示[ 21]。CUM使用rdf:seeAlso属性来扩展表达用户的其他特征。
这种方法主要借鉴关联数据的应用,把系统的用户模型按照一定的程序和规则发布成关联数据,不同系统中的同一用户之间就产生了相互关联。这样,关联的用户模型构成了不同应用系统间的跨系统用户模型,可以提供更加全面完整的用户信息。LOD的应用,不仅允许推断用户之间的关系,还可以在更高层次的概念上对用户的兴趣进行聚类。目前,该方法还没有具体的应用,但为跨系统用户建模开辟了新的路径。
上述三个实例分别从社交网络、互操作、关联开放数据的角度实现了跨系统的用户建模,都是分布式开放的用户建模方法。主要是把分布在不同系统中的数据收集聚合,或者对不同系统中的用户模型数据进行关联一致化。如何把Web上大量分布式的、异构的用户数据进行概念的一致化是分布式开放用户建模的关键,数据开放也是跨系统用户建模面临的首要问题。分布式开放用户建模不仅需要语义网技术的支撑,还需要其他政策、法规等方面的支持。目前,这种方法是语义网环境下用户建模的一种新范式。与前面两类方法相比,本体在分布式开放用户建模中也承担了重要角色,如用户特征的表示、用户关系的表达等。这种方法更加注重数据的开放性和交互性,具有更好的可扩展性和自适应性,试图随时随地构建满足用户需要的模型。可以说,分布式开放用户建模是Web发展的必然结果。
随着Web的发展,用户面临着越来越严重的信息过载的问题,个性化服务为用户提供了一个很好的出路。跨系统的用户建模可以为用户提供多系统、多应用领域的个性化服务,从而构建更加全面丰富的用户模型,很好地解决了传统用户建模中的数据冗余和冷启动问题。本文比较分析了跨系统用户建模的一些典型实例,在此基础上指出了跨系统用户建模的发展趋势——分布式开放用户建模。社交网络、互操作、关联开放数据的发展和应用,为跨系统的用户建模提供了新的契机。
目前,个性化服务的研究已经从关注用户模型的本身向用户模型的构建过程转变,不同系统之间形成一种动态联合的服务模式。在分布式、开放的Web环境中,如何尽可能全面地收集用户信息、如何有效地组织异构数据源、如何实现不同系统间的数据交换和共享、如何快速地适应不同用户的需要、如何高效地捕捉用户的兴趣和爱好是要考虑的重要问题。语义网技术的发展、关联开放数据的发布和应用,为这些问题的探索和研究提供了有效的途径。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|