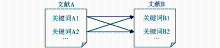

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于向心扩散加权XML模型的异构用户个性化模式匹配方法
[李树青 , 刘晓倩]
, 刘晓倩]
, 刘晓倩]
|
|


介绍一种利用同文词语共现和引文词语共现分析实现的领域本体自动构建方法,该本体采用加权XML模型,利用概念联系中的权值设定可以有效地表达用户兴趣程度的差异,并利用基于向心扩散的扩散激活方法对用户兴趣特征及其联系提供更强的表达能力,以便于发现更有价值的潜在用户兴趣。进而介绍如何利用该本体按照“先打碎后重构”的策略将异构用户个性化模式转换为可以进行比较的一致模式,并对相关的异构用户个性化模式匹配方法做出详细说明。最后总结相关测试实验及其结果。
This paper introduces an automatic construction method for domain Ontology implemented by words co-occurrence analysis in both document and citation. This Ontology adopts weighted XML model and uses weight in concepts and their relationship to express the difference of users’ interest effectively,which can improve the ability of expressing users’ interest and their relationship with centripetal weight spreading activation strategy in order to explore more valuable users’ interest. Meantime, this paper also discusses how to use this Ontology to transform heterogeneous user personalized profile to consistent comparable model with the broken-and-reconstruction strategy, and how to match corresponding heterogeneous user personalized profile in detail. Finally, the result of correlative tests and experiments are concluded.
用户个性化模式是实现个性化信息推荐服务的基础,合理地选择和设计用户个性化模式对于提高信息推荐服务的有效性非常重要。目前,基于本体的用户个性化模式设计方法已经成为一种主流方式。笔者以前的研究采用了同构异值的加权个性化本体设计方法,利用本体中的权值差异来表征用户兴趣的差异[ 1]。这种方法简单易行,也便于人们理解。然而,它也存在很多问题,如不同的用户兴趣差异程度很大,同构异值的设计方法往往需要在现有的用户个性化本体中引入大量的无关内容来进行补齐填充,从而形成一致的模式,因此带来大量的冗余计算,这一问题在用户个性化本体的权值扩散过程中表现尤为明显。异构设计方法可以给用户个性化本体带来一种新的解决思路,使其可以在结构上不受拘束地被扩展和自定义,以便更好地表达用户个性化兴趣特征。但其中的关键问题和难点并不在于此,如何实现对不同的异构用户个性化本体进行相似度比较,从而完成个性化信息推荐服务,才是亟需解决的重要问题。
造成用户个性化本体结构相异的因素主要有两个:本体节点语义不统一,不同用户所产生的个性化本体节点内容往往随意性很大,复杂的语言现象导致最终很难对不同的用户个性化本体进行比较和相似度判断;节点联系不统一,不同用户对组成自己兴趣特征的不同概念之间的关系,往往有不同的理解,比如有人采用层次型的组织方法,也有人采用网络型的组织方法,甚至还有人采用多维结构型的组织方法。即便是把概念联系限定在层次型结构中,相关类目和组织次序也会因人而异。
因此,要想解决异构用户个性化模式之间的相似度计算问题,就必须解决上述两个问题。
对于用户个性化模式而言,早期的表达方法往往采用关键词向量和类别向量[ 2]、概念集合[ 3]等方法,后来学者开始尝试使用本体来表达用户个性化模式[ 4, 5]。如将传统的用户个性化模式中的关键词通过本体映射转换为概念词[ 6],完全使用本体来直接构建用户个性化模式[ 7],利用本体来构建细粒度用户个性化模式但却没有本体的自动构建方法[ 8]等。较新的研究提到了利用WordNet本体来实现“森林模型(Forest Model)”,并据此测度用户个性化模式之间的相似度,来实现社交网络中的朋友查询[ 9]。国内类似的研究使用本体来构建高校专家的集成信息,但是信息的收集方法却需要手工进行[ 10]。
对于这些异构用户个性化模式相似度的比较,相关方法的研究也由来已久。从总体上看,该问题属于信息异构问题。信息异构有三个层次,分别是句法(Syntax)、结构(Structure)和语义(Semantic)[ 11]。句法层次是其中最为简单的问题,主要原因在于数据格式的不一致,随着诸如XML、RDF和OWL等各种标准格式的推出,该问题已经逐渐得以解决。随之而来的主要是结构层次和语义层次的问题。其中,语义层次的异构问题仍没有取得较为明显的突破[ 12]。
借助本体工具和本体映射方法是一种解决信息异构问题的有效手段,在信息集成和信息转换领域中应用很广,但是面向于整个网络的通用本体并不存在,得到广泛使用的仍然以面向特定领域的领域本体为主。本文所采用的本体也是一种面向学术文献的领域本体。在使用不同本体时,本体映射方法是建立用户与服务之间联系的关键条件[ 13],它也是一种测度实体相似性的方法[ 14]。具体的本体映射方法有编辑距离匹配、语义匹配和结构匹配等,也有很多学者通过引入其他方法来解决,如人工智能技术等[ 15],还有学者尝试使用与协同推荐方法的结合来处理这一问题[ 16]。
然而,现有研究仍然存在很多问题:
(1)用户个性化本体表达能力亟需提高。为了实现这一目标,学者们引入了本体概念的加权表达方法和扩散激活(Spreading Activation)方法。
加权本体是一种有效的用户个性化模式解决方案。传统的个性化本体主要利用节点及其联系来表达各种语义关系,后续的研究发现,与兴趣权值的结合是一种有效的个性化本体构建方法[ 17]。它是一种“概念空间[ 18]”的发展和扩展,实践证明也是有效的[ 19]。它结合了本体方法和兴趣权值方法,有助于个性化本体的创建和进化。但现有的方法往往侧重于对概念加权,而忽略了对概念联系权值的考虑。
同时,在本体中引入语义网络中的扩散激活方法来增强对本体概念相似度的测度能力也是可行的[ 20]。扩散激活方法通过初始概念集合和相应的初始权值来寻找本体中的其他相关概念[ 21]。该方法可以较好地解决推荐系统中常见的冷启动问题,即使用现有的本体作为用户初始个性化模式,可以完成基本的概念扩展和关系识别[ 22]。复杂的方法还考虑了向上层概念的扩散或者对不同的概念联系采用不同的扩散方法等[ 23]。但是,相关的研究并不多见[ 24]。
在前期研究中,笔者也证实了引入加权表达和扩散激活方法的有效性,本文所采用的方法也沿用这一思路[ 25]。
(2)本体设计过于简单。由于缺乏有效的本体自动构建方法,同时诸如WordNet等传统人工组织方法效率低下,难以有效扩展,所以很多研究不得已在精确性和完备性上取得一定的折中,比如只使用用户最为关注的兴趣特征来提高精确度,当然在一定程度上以牺牲完备性为代价[ 26]。有学者只关注于is-a的基本联系[ 22],还有学者没有使用全部的本体成分,利用简化的结构设计了一种利用用户会话中最能反映用户兴趣特征的相关关键词组成图结构来表达用户个性化模式,而且采用了权值扩散的构造策略[ 27]。还有学者利用本体技术实现了个性化新闻推荐,但是仍然采用传统的向量模型来构建用户个性化模式[ 28]。虽然自动构建的本体在可读性方面逊于人工编辑的本体,但在可行性和易用性方面仍有优势。
本体自动构建需要解决如何从词语中识别概念等级及其联系,具体包括三种联系:属种关系(Generic Relationship)、实例关系(Instance Relationship)、整部关系(Whole-part Relationship)[ 29]。从现有的知识库中自动获取本体也是一种可行的方案,但是它需要知识库作为前提[ 30, 31]。其他常见的方法有词语共现分析方法、句法模式识别方法和词语上下文分布相似度方法等。其中词语共现分析方法简单易行,属于内容分析方法的一种[ 32],目前被广泛地应用于聚类研究[ 33]、战略情报研究[ 34]、专利地图绘制[ 35]等方面,同时词语共现分析方法也有助于从特定领域中快速自动构建本体。但是它却难以区分上述三种等级关系,只是将其全部转换为上下级的相关联系[ 36]。不过,这一缺点对于处理用户个性化本体而言,问题并不明显[ 37]。
为了提高利用词语共现分析方法自动构建本体的有效性,有学者利用了包括分类相似性和内在概念相关度在内的多种相似度关系,实践证明具有可行性[ 38]。该方法的有效性还依赖于抽取上下文的调节参数、数据集合的规模与质量等[ 39]。本文采用了一种综合考虑同文词语共现和引文词语共现的方法,并据此实现了领域本体的自动构建。
(3)异构用户个性化本体的相似度计算方法需要探索。为了测度异构本体之间的相似度,必须要解决词语之间的语义相似度(Semantic Similarity)问题[ 40]。根据使用领域知识的类型不同,该方法可以分为基于分类结构的方法、基于概念的信息内容方法和基于上下文环境相关度的方法。最早的基于分类结构的方法往往侧重于测度两个概念之间的最短距离[ 41],复杂的考虑往往还会结合概念的所在层次,如认为概念所在层次越高相似度越小等。该方法的问题在于仅仅利用本体层次结构信息,因此本体信息的完备性、同质性和覆盖度都会影响测度的有效性[ 42]。而且这些方法往往忽略诸如共有上级节点等其他非最短路径信息[ 43],并且对不同路径的定量化区分也做得不足[ 44]。最早的基于概念的信息内容方法是根据最近共有上级概念的信息量[ 45],但是这种方法往往需要对概念进行迭代计算以寻找最近共有上级概念,而且一旦现有的分类层次体系发生变化,重新计算的需求将会导致可扩展性较差,同时它对分类体系的完备性要求更高[ 46]。基于上下文环境相关度的方法认为如果两个词语所在的上下文环境越相似,则两个词语的语义相关度越大。词语共现分析方法本身就是一种常见的基于上下文环境相关度的方法。本文所探讨的异构用户个性化本体相似度测度方法,是一种利用词语共现分析方法得到的加权本体,通过权值差异程度来间接测度概念内容和结构的差异。值得注意的是,该方法也可以为异构XML信息查询提供一种新的思路[ 47]。
自动构建的领域本体必须在语义上具有丰富的特点,同时还能尽可能地表达出各种不同的概念联系。在学术文献这个特定的研究领域中,本文将文献的关键词作为构建领域本体概念的主要数据源,同时采用词语共现分析方法来识别概念联系,并引入下面两种设计策略:
(1)考虑同文词语共现和引文词语共现两种概念联系
传统的词语共现分析方法主要考虑同文共现关系,然而不同文献关键词不仅在一个时间点上具有相关性,而且还会在不同的时间点上具有相关性。利用引文之间的时序关系,可以更好地发掘出关键词的演变序列关系和时序相关性,这也充分印证了引文网络分析与其他方法的结合日益密切[ 48]。
从引文关系中发现引文词语共现对如图1所示:
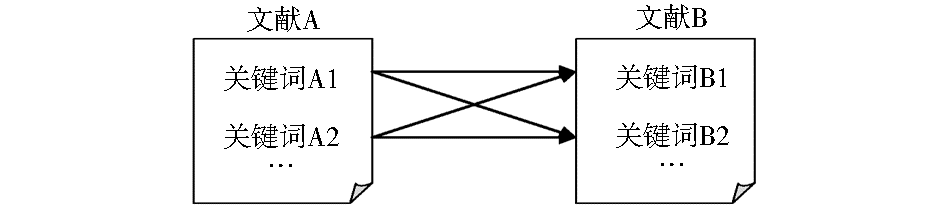 | 图1 从引文关系中发现引文词语共现对 |
可以看出,关键词对(A1,A2)和(B1,B2)都是同文词语共现关系,由于文献A引用了文献B,所以还可以从中得到4个引文词语共现对,分别是(A1,B1)、(A1,B2)、(A2,B1)和(A2,B2)。
当然,对于不同含义的关键词共现对,应该予以不同的权重处理。对同文词语共现对赋予1的权值,而对引文词语共现对赋予0.5的权值。最终将所有的关键词共现对分组归类,并对权值进行累加,可以得到最终的带有权值的关键词共现对集合。这个权值在一定程度上可以揭示关键词共现对的有效性,权值越高,相应的关键词共现对越常见,实际语义相关性就越高,反之亦然。在实际运算中,可以考虑忽略那些权值较低的关键词共现对。最终可以对所有的权值规范化处理,如利用最大权值对所有的权值进行归一化处理,将权值限定在0到1之间。
这种关键词共现对具有两个特点:通过赋予不同的权重处理可以表达不同用户的兴趣特征;共现对为有向链接,如(A1,B1)表示A1的出现导致了B1的出现,本文称为关键词共现对链接。
(2)考虑网状的语义组织结构
该设计策略是将所有的共现对按照文档频率进行整序,将所有的共现对梳理成低文档频率词指向高文档频率词的次序,最终形成一个完整的网状领域本体组织结构。该结构的内核由一组具有较高文档频率的核心关键词组成,外部由多层较低文档频率的关键词组成,不同层次之间的关键词存在由外层指向内核的共现对链接关系。这种设计结构便于以后的权值扩散,权值可以由处于外层、专指性较强的一般关键词逐渐扩散到处于内核、概念含义更为广泛的核心关键词。
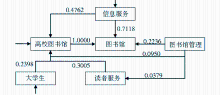
在实现上,该本体采用了加权XML模型,其中的每个概念对应一个XML节点,每个概念联系对应一个XML节点联系。同时,每个XML节点联系都被赋予对应的概念联系权值。部分结构如图2所示:
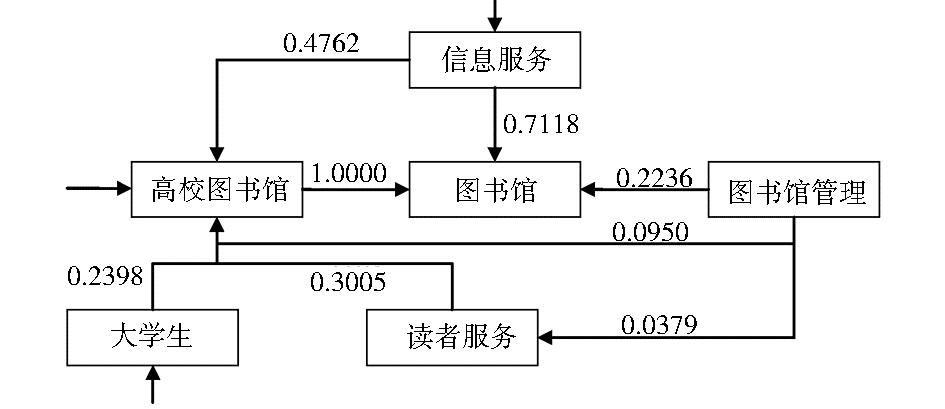 | 图2 带有概念联系权值的领域本体部分示意图 |
对应的加权XML模型信息如下所示:
<Root>
<Nodes>
<图书馆 id=1 DF=16856/>
<高校图书馆 id=2 DF=10937/>
<信息服务 id=4 DF=4268/>
<读者服务 id=9 DF=2169/>
<图书馆管理 id=12 DF=1552/>
<大学生 id=20 DF= 1171/>
...
</Nodes>
<Edges>
<id=214531 sid=4 tid=1 weight=0.7118/>
<id=143471 sid=12 tid=1 weight=0.2236 />
<id=1150132 sid=4 tid=2 weight=0.4762/>
<id=1972140 sid=9 tid=2 weight=0.3005/>
<id=1588519 sid=20 tid=2 weight=0.2398/>
<id=8831 sid=12 tid=2 weight=0.0950/>
<id=1375122 sid=12 tid=9 weight=0.0379/>
...
</Edges>
...
</Root>
其中,DF表示词频,weight表示权值,sid和tid分别表示关键词共现对链接的起始关键词和终止关键词。
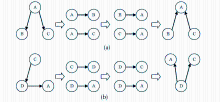
对于结构不同的各种用户个性化模式,必须通过将其映射到一个一致的参考本体(Reference Ontology)中,才能完成最终的相似度比较。为此,本文采用了“先打碎后重构”的策略。
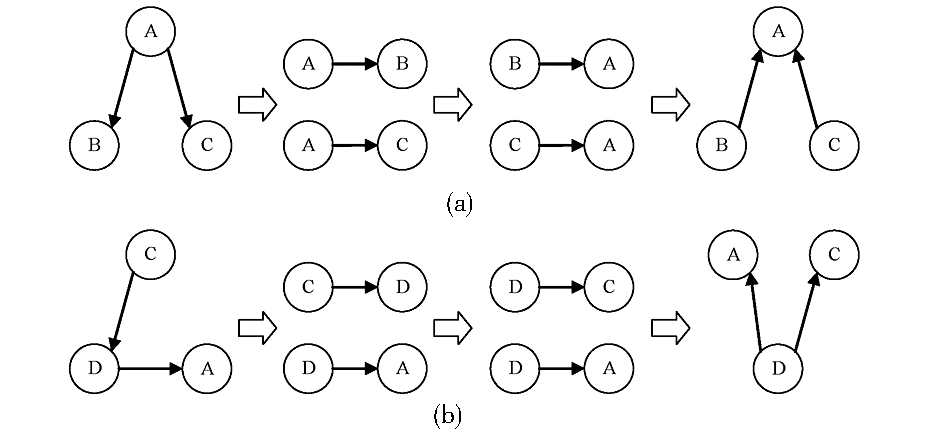 | 图3 重构异构用户个性化模式实例 |
如图3所示,用户个性化模式a和b的结构差异很大,甚至在节点内容上也完全不一致。将每个用户个性化模式打碎后,会各自得到一组由两两关键词组成的词语对,如模式a得到的词语对为(A,B)和(A,C),模式b得到的为(C,D)和(D,A)。接来下,对得到的这些词语对进行重构。首先是将每个词语对整理成低频关键词指向高频关键词的次序,以便于后续将其纳入到领域本体结构中。假设A、B、C和D这4个关键词的文档频率大小序列为A>B>C>D,则最终得到的4个序列,分别是(B,A)和(C,A)、(D,A)和(D,C),构成的最终个性化模式。
值得注意的是,由于不同的用户个性化模式会在每个关键词链接上具有反映不同兴趣差异的权值,而重构后的用户个性化模式只是重整了结构特征,对相关权值没有做调整。但是,重构后的用户个性化模式具有了和领域本体结构相似的链接指向关系,因此为后续的权值扩散提供了结构基础。
本文提出了一种沿着关键词共现对链接、由外层关键词向内核关键词进行权值扩散的迭代算法。具体的权值扩散计算如下:
weight(link(Tm,Tn))=c 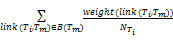
其中,link(Tm,Tn)表示关键词Tm和Tn共现对链接,weight()为共现对权值函数,B(Tm)表示以Tm为终点的所有关键词共现对链接,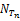 表示以关键词Tn为起点的关键词共现对链接总数,coef为衰减系数,由于权值扩散是采用由外层向内核的迭代扩散方式,因此在每次迭代中通过引入一个不断衰减的系数来控制权值扩散的强度,c为保证权值迭代计算收敛的常量因子,设置为0.8。
表示以关键词Tn为起点的关键词共现对链接总数,coef为衰减系数,由于权值扩散是采用由外层向内核的迭代扩散方式,因此在每次迭代中通过引入一个不断衰减的系数来控制权值扩散的强度,c为保证权值迭代计算收敛的常量因子,设置为0.8。
完整的具体算法伪代码如下:
// 衰减系数初始值
double coef=0.8;
// 迭代运算
while(coef>0.0001){
// 取出现有用户个性化模式中的每个关键词共现对链接
for each linki in profilek {
// 取出当前关键词共现对链接的所有有效后续关键词共现对链接
Collection links=getValidOutLink(linki);
// 循环处理以当前关键词共现对链接终点为起点的所有后续关键词共现对链接
for each linkj in links {
// 利用公式(1)得到扩散的权值
getWeight(linkj);
// 将其加入到现有的用户个性化模式中
addToProfile(linkj);
}
// 控制衰减系数
coef= coef/2;
}
值得说明一点,代码中引入的getValidOutLink()函数,主要是去除无效的较低权值的关键词共现对以降低计算量。在经过权值扩散的重构用户个性化模式中,利用权值的差别既可以表达共有关键词共现对链接的兴趣差异度,也能很好地测度模式中结构的差别。
本文设计的方法主要比较两两用户个性化模式的关键词共现对链接权值差异,并据此测度最终的相似度,计算公式如下:
similarity(profile1,profile2)=1-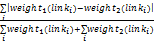
其中,weight1(linki)表示一个用户个性化模式profile1中的关键词共现对链接,分子为两个用户个性化模式中所有关键词共现对链接权值差值的绝对值之和,分母为两个模式的所有关键词共现对链接权值之和,显然,该相似度最大为1,最小为0。
笔者对万方和CSSCI两大中文期刊数据库进行了文献数据获取,抽取了图情领域期刊文献共59种,其中核心期刊35种,时间跨度为2000到2009共10年,总共获得202 759篇有效文献,共计232 987个有效引文链接,限于数据集合的有限性,不包含不属于图情领域文献的引文链接。
实验获取的关键词总数为113 626,通过同文共现和引文共现获取的关键词共现对共计2 059 083个,其中按照低频关键词指向高频关键词的有序化整理,最终得到982 402个。通过可视化软件Gephi,以关键词为节点、关键词共现对链接为边,最终得到的这个领域本体在宏观上表现为一个内核紧密、外层逐渐疏松的基本形态,如图4所示:
 | 图4 图情领域本体的宏观结构特征 |
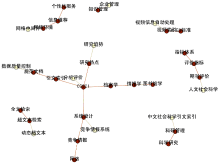
其中,处于内核的、具有最高文档频率的关键词及其共现关系如图5所示:
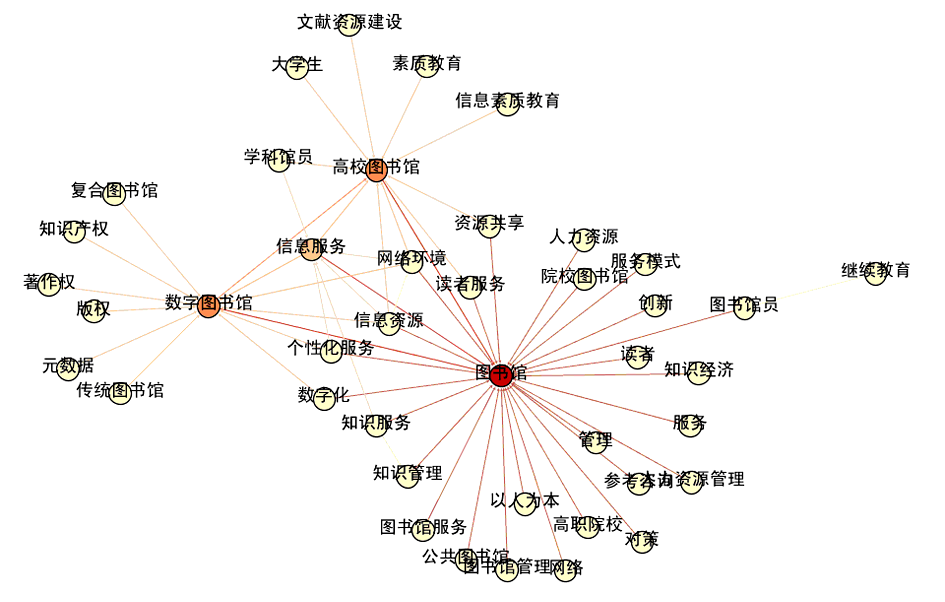 | 图5 图情领域本体的核心关键词及其共现关系 |
图5中节点颜色的深浅表示了入度的大小,可以看出,“图书馆”、“数字图书馆”、“高校图书馆”等都是最为常见的核心关键词,也是最易于与其共现的关键词,链接颜色的深浅表示链接权值的大小。
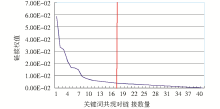
处于外围的关键词共现对数量极大,权值也极小,实验对其进行了除去处理。本文设计了一个去除低权值关键词共现对的方法,即在图6中寻找权值变化曲线中的拐点,只保留处于拐点左侧的有效关键词共现对。具体方法描述如下:选择所有的以某一特定关键词为起点的关键词共现对链接,按照权值大小降序排列,然后由高权值链接开始,比较各个相邻的两两链接权值差值,如果连续有10次差值小于预设定的阈值0.00046,则认为首次开始计数的关键词链接权值为截止阈值。以“个性化”为例,以它为起点的链接权值变化趋势如图6所示:
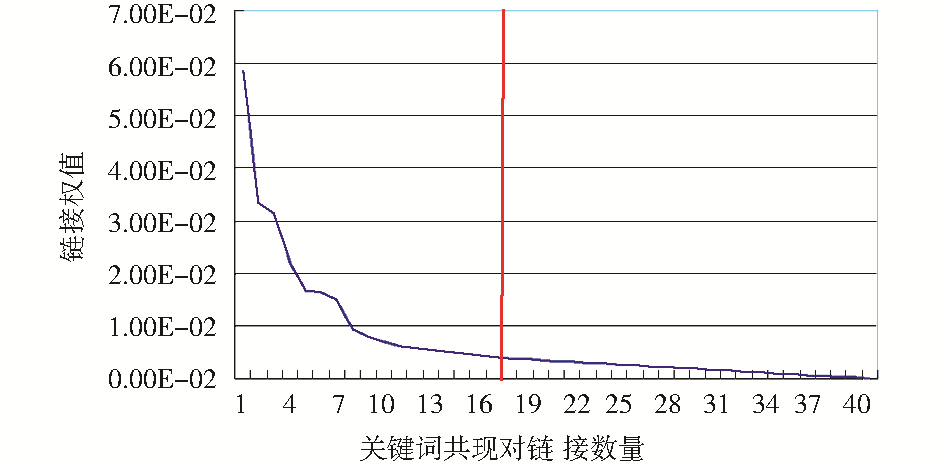 | 图6 以“个性化”为起点的关键词链接权值 |
由高到低的变化趋势可以看出,大量的关键词共现对都具有较低权值,真正具有较高权值的链接数量并非很多。其中竖线标记的第17个关键词共现对权值(为0.00415335)就是截止阈值。
为了便于测试分析,本文抽取了第一作者为南京地区的共计5 438篇图情领域的文献,作者共计2 392人,其中发文数量大于10篇的有55人。这些作者拥有足够多的文献数据,所以可以利用每位作者所发文献的关键词来表示他们各自的研究兴趣。
每个作者的初始用户个性化模式构造方法说明如下:抽取每个作者的每篇所发文献,抽取每篇文献中的所有关键词;将每篇文献中的关键词分成一组,按照文档频率升序排列,并自动构建出所有低频关键词指向高频关键词的共现对链接;对相同的关键词共现对链接进行累计,以出现次数作为权值,可以对每个作者,得到以一组相关联系的关键词共现对链接来表示的原始个性化模式。如抽取的南京大学苏新宁教授所发文献共计11篇,如表1所示:
| 表1 作者发文信息 |
从中自动构建的相应个性化模式如图7所示:
 | 图7 反映作者兴趣的原始个性化模式 |
按照该方法,可以对所有的作者做相同的处理。可以看出,不同作者所对应的不同个性化模式在结构和权值上都具有较大的差异。
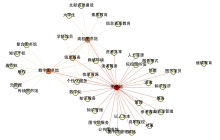
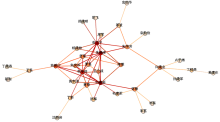
利用本文所述的权值扩散方法和相似度比较方法,对这55位作者进行了两两比较,以分析作者之间的兴趣相似度,部分兴趣相似度较高的作者及其关系如图8所示:
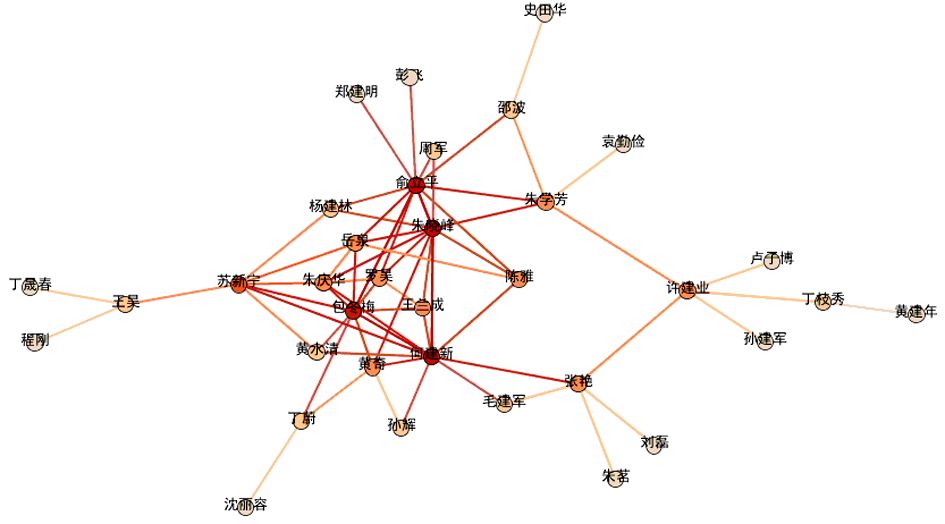 | 图8 南京地区图情领域学者之间的兴趣相关度 |
其中,节点颜色越深,表示与该节点作者兴趣相近的作者数量越多,而链接颜色越深,则表示两者兴趣越相近。
本文所探讨的异构用户个性化模式相似度比较方法可以应用于各种特定领域的个性化信息推荐服务,同时也可以作为一种领域本体映射的解决方法。在研究实践中,笔者选择了学术文献这个特定的研究领域,并尝试将异构用户个性化本体引入到现有的个性化学术文献信息推荐系统中。从目前的使用效果来看,该方法实现了预期的目标。未来研究将重点放在对领域本体的设计改进上,如现有的主流方法主要考虑双词共现,而多词共现的现象也很值得关注,从中也可以发现更多的概念联系。另外,引文词语共现对充分反映了概念的时序演化关系,因此在现有的领域本体中通过引入时间维度来构建多维本体结构,可以实现更好的概念表达效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|