
{kind=link}
一种面向篇级数据的作者名消歧规则和算法
[肖晶 , 梁冰, 张晓丹, 吕世炅]
, 梁冰, 张晓丹, 吕世炅]
, 梁冰, 张晓丹, 吕世炅]
|
|


在深入分析NSTL篇级元数据特点的基础上,结合模糊匹配算法,提出一种适合NSTL现有数据的人名消歧规则集,并给出基于该规则集的人名消歧算法。通过对实际数据集的实验,该算法在准确率、召回率等指标方面都有良好的表现,具备较好的消歧效果。
This paper analyzes the article level data in NSTL, then presents a rule set for name disambiguation combining with fuzzy matching algorithm, and provides the relevant name disambiguation algorithm. Through the experiment based on the actual data set, it is found that the algorithm gives a good precision and recall value, which is a good effect for name disambiguation.
重名在现实生活中是一个普遍的现象,对于海量的文献作者来说,大量的重名现象是一个不可避免的问题。随着信息技术的飞速发展以及数据量呈几何级数的增长,人们已经不再满足于普通搜索引擎提供的基于关键词匹配的简单功能,而更多地倾向于智能化程度更高的检索方式,比如基于作者实体的检索。
国家科技图书文献中心(NSTL)已有大量的中外文科技文献资源,但是,目前只能提供简单的基于关键词匹配的文献检索服务,而无法满足用户更高级别的需求。如何构建一个更智能化的搜索引擎,是当前NSTL服务亟需考虑的一个问题。较好地处理作者名消歧的问题,对于支持NSTL今后全方位地为用户提供智能检索服务和个性化服务都有重要的意义。具体表现为:
(1)能够帮助NSTL网络服务系统精确地构建以作者实体为中心的信息服务,与以往的以文献为中心的信息服务结合,可以为用户提供多角度的文献检索服务,以扩展NSTL的服务范围,并扩大NSTL的潜在用户群。
(2)能够极大地提高情报分析以及信息挖掘的准确性。NSTL拥有大量的科技文献资源,如能充分准确地分析、挖掘其中潜藏的科技情报信息,并精准、高效地提供给科研机构和科研人员,对于促进我国科研水平的进步有着极为重要的意义。
(3)能够更为准确地构建各种以作者实体、文献以及作者间的合作关系为中心的关联网络,这对于分析各领域、学科及行业内的相关科技人员的构成、结构,跨领域、学科、行业间的人员、机构间的合作关系,促进相关科研人员及机构间的合作交流,以及关键热点领域、主题的预测等,都有很重要的意义。
在国外,人名消歧研究开展得较早,许多学者都进行过探索,也针对不同的应用领域提出了不同的解决方法。Bagga等[ 1]提出了一种用于文档间共指消解的人名消歧方法。Mann等[ 2]提出了一种基于个人传记特征来构造特征向量的方法对人名进行消歧。Fleischman等[ 3]提出一种基于最大熵的方法。Malin[ 4]提出了一种基于人的社会网络来对人名进行消歧。在国内,文献[5]提出了基于社会网络的重名消解。文献[6]提出了一种人名消歧的形式化的统一框架,可以将特征属性和消歧对象间的关系集成到一起,并形成一个概率模型。在该框架中,还对文献间的关系做出了形式化的定义。文献[7]提出了一种基于互斥信息的特征属性的权值计算方法,并在此基础上提出了一种凝聚层次聚类的消歧算法。目前,这些方法大都不是面向篇级文献数据的作者名消歧方法,并且都仅是从特征选取方面来研究人名消歧的问题,同时,单一的特征属性往往不能达到较好的消歧效果,比如基于社会网络的方法就无法对单一作者文献的同名情况做出处理。另外,除了采用技术手段之外,还可以利用管理手段来解决作者实体的重名问题,如国外的ORCID(Open Researcher and Contributor ID)机构[ 8]。但是,在现实中落实推广这样的注册系统还是存在诸多阻碍,比如:如何让用户积极地参与注册并定期维护他们的相关数据;这样庞大的一个全球性的注册系统和数据库由谁来负责维护;如何发现并处理同一个作者注册多个ID的情况,并且这种注册系统也很难解决那些已有文献著作的作者名消歧问题。
基于以上考虑,本文采用技术手段对重名作者进行消歧处理,选取多个特征属性,对文献间及作者间关系进行深入研究,提出了一组可扩展的作者名消歧规则集及消歧算法,同时,依据特征属性的不同特性,结合模糊匹配与精确匹配对特征属性进行处理,既提高了消歧结果的召回率又保证了准确率。
结合实际数据情况和匹配结果,本文设计了一种简单的模糊匹配算法,并给出作者消歧的规则集,在此基础上实现基于该规则集的作者消歧算法。
在作者名消歧的过程中,如果采用精确匹配的算法对特征值进行匹配,消歧效果并不好,因为特征值往往带有一定的模糊性,容易造成过度识别的问题。因此在本方法中,对一些信息采用了模糊匹配的算法,如作者机构名、关键词等特征属性,通过模糊匹配缩小消歧的范围,再通过对唯一度较高的作者名进行精确匹配,从而达到更好的消歧效果,具体算法如下:
令S,T是两个字串,S={s1,s2,…sn},T={t1,t2,…tm},其中si,tj分别表示S,T字串中的字符,字串S与字串T的相似程度标记为sim(S,T),则:
sim(S,T)=2×card(S∩T)/(card(S)+card(T)) (1)
经过针对实际篇级数据的分析,在一般情况下,sim≥0.8时,对作者机构名的匹配效果最好。需要注意的是,本文的模糊匹配算法虽然并不能完全准确地识别出相同的机构名,但是,对于最后的作者名消歧结果的准确性的影响并不大,同时还能提高消歧结果的召回率,因为本文的最终目标不是识别同名机构,而是进行作者名消歧,在基于篇级数据进行作者名消歧时,机构名称的匹配只是一个辅助条件,结合作者名的精确匹配,最终仍然能够得到较好的结果。
在篇级数据中,最能代表作者特征属性的一般是作者名和作者所属机构,以及作者的研究领域和关注点,本文选择了作者名、作者机构以及文章的关键词作为特征属性,并结合作者合作关系网络,来对同名作者进行消歧。对于文献c来说,本文以A(c)表示c的作者集,D(A)表示A所属的机构名的集合,K(c)表示c的关键词的集合。
在对大量篇级数据进行作者名消歧预处理时,首先对人名进行初始聚类,即将相同名字的数据归为一类,则初始聚类后,所有数据可以看作一个大的集合S,各个聚类为其中的一个子集,分别表示为S1,S2,…Sn,Si为S中包含某一相同人名的最大文献子集,ax为Si中共同的人名,则有Si∈S⇔∀c1,c2∈Si.ax∈A(c1)∩A(c2) ∧ ∀c∈S-Si.ax∉A(c)。然后在此基础上识别出不同的指代实体。对于Si中的任意两篇文献,若其中存在相同的作者实体a1,a2,则本文记作:EQ(a1,a2),算法的消歧规则如下:
(1)令c1,c2∈Si,则有:
(∃a2∈A(c2).sim(D(ax1), D(a2))≥0.8∨∃a1∈A(c1).sim(D(a1),D(ax2))≥0.8) ∧ sim(K(c1),K(c2))≥0.2 ⇒EQ(ax1,ax2)
(2)令c1,c2∈Si,则有:
sim(D(ax1),D(ax2))≥0.8∧∃a1∈A(c1),a2∈A(c2).a1=a2∧a1≠ax1 ⇒EQ(ax1,ax2)
(3)令c1,c2∈Si,则有:
∃a1∈A(c1),a2∈A(c2).sim(D(a1),D(a2))≥0.8∧a1=a2∧a1≠ax1 ⇒EQ(ax1,ax2)
规则(1)-规则(3)利用待聚类的共同人名、所属机构以及文献的关键词为特征属性,基于模糊匹配算法,结合精确匹配,在篇级文献中挖掘出相同作者实体的信息,并进行二次聚类。其中,规则(1)主要针对同名作者的机构和关注领域进行约束,对于相同机构的同名作者来说,如果其关注的领域也相关,则认为是相同作者实体。如果同名作者的机构名不同,则判断其在另一篇文献中是否与自己所在机构的作者有过合作关系,这种情况多属于作者机构变迁。在规则中,本文根据具体实际情况的不同,在模糊匹配的相似度上取不同的值:对机构名称的模糊匹配,sim值取0.8;而对关键词的模糊匹配,相似度取0.2以上获得的效果最好。规则(2)表明,对于相同机构的同名作者,如果在作者合作关系网络中,与相同人名的作者实体具有一次以上的合作关系,则认为是相同的作者实体。规则(3)提出,对于任意两个同名作者来说,只要他们在作者合作关系网络中,与相同机构的同名作者具有一次以上的合作关系,则认为他们是相同的作者实体。
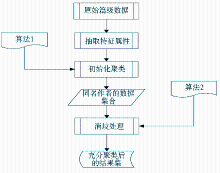
在利用本规则对大规模篇级数据进行作者名消歧处理前,必须先对数据进行预处理,完成初始化聚类,算法如下:
(1)算法1:初始化聚类
初始化:A=ϕ,S为所有文献的集合,其中A为同名作者集;
重复下面步骤,直到S=ϕ:
取S中的任一元素c;
如果∃a∈A(c)∧a∉A,则将元素a添加到集合A,创建一个新的S子集Sa,使得c∈Sa;
如果∃a∈A(c)∧a∈A,则将元素c添加到集合Sa;
令S=S-c;
返回集合A和Sa的集合,令Sa的集合为S’,则满足:card(A)=card(S’)且∀c.c∈S’⇔c∈S。
算法1首先遍历文献集中的每一条篇级数据,然后将具有相同作者名的篇级数据聚类到同一个子集,利用算法1对篇级数据进行处理后,得到一个唯一人名的集合和一个完成初始聚类的文献的集合S’,对于S’中的任一子集,该子集中的所有篇级数据都至少包含一个相同的作者名。本文需要利用消歧规则对S’进一步处理,对S’中的每一个子集继续聚类,识别出不同的作者实体。
(2)算法2:消歧处理
初始化:
调用算法1进行初始化聚类;
令Sa中的每一个元素为一个子集,则有:Sa={C1,C2,…Cm},其中Ci={ci},令Sa’=ϕ;
重复下面步骤,直到A=ϕ:
取A中的某个元素a,重复如下步骤,直到Sa=ϕ:
取Sa中的某一子集元素Ci,如果card(Sa)=1,则将子集元素Ci添加到集合Sa’中,且令Sa=Sa-Ci;
取Sa中的某一子集元素Ci,对于Sa中其他每一个子集元素Cj,利用消歧规则,如果满足:∃ci∈Ci,cj∈Cj. EQ(ai,aj),则令Cj=Ci∪Cj,Sa=Sa-Ci;
取Sa中的某一子集元素Ci,对于Sa中其他每一个子集元素Cj,如果不满足任何消歧规则,则将子集元素Ci添加到集合Sa’中,且令Sa=Sa-Ci;
令A=A-a;
返回Sa’的集合,令Sa’的集合为Seq,则满足:card(A)=card(Seq)且∀c.c∈Seq⇔c∈S。
算法2遍历作者名的集合A,针对其中的每一个元素,依据消歧规则对相应的文献子集Sa作进一步聚类处理,将Sa中满足消歧规则的元素聚类为一个子集,并将完成聚类的每一个子集添加到Sa’中。算法2的输出Seq是一个经过充分聚类的篇级数据的集合,其每一个元素Sa’也是一个集合,且Sa’中的每一个元素都是由包含相同作者实体的篇级数据所组成的集合。
基于篇级数据的作者名消歧,实质上是对篇级数据按照作者实体进行聚类的一个过程,在消歧结果中,正确识别出的作者实体数量的比例越大,表明算法的效果越好。本文采用一种常用的评价方法[ 9]:用准确率P(Precision)、召回率R(Recall)和F值来衡量算法的优劣。各个指标定义如下:
P= 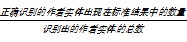
R= 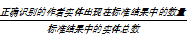
F= 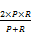
本文在NSTL中文期刊元数据中随机抽取了127条作者名为“张勇”的篇级元数据,经过人工分析,实际指代了99个作者实体,而经过本算法处理,共识别出104个作者实体,正确识别的实体数是94个。实验流程如图1所示:
同时利用其他文献中的某些方法[ 7, 10, 11, 12, 13, 14]进行实验,结果对比如表1所示:
| 表1 实验结果对比 |
可以看出,本算法的消歧结果已经能够较好地达到预期的效果,也有一定的优势。
另外,因为数据量太大,本文并没有基于整个重名数据集来进行处理,否则,将能获得更多的聚类线索,原先因为不满足规则而被识别为不同实体的作者,就能够被正确识别。所以在实际应用中,算法的消歧结果一般会优于实验结果。下面是实验中的两个例子:
a.
b.
a,b分别是两个篇级数据中抽取的特征值,本算法利用规则(1)成功地对这两个作者名作了消歧处理,识别出这两个“张勇”指代同一作者实体。
a.
b.
在上面这个实例中,利用规则(2)即可成功作出消岐处理。
本文基于对大量篇级数据的分析,提出了一种基于规则的作者名消歧算法,选取作者、机构、关键词等特征属性,结合模糊匹配与精确匹配,对大量篇级数据进行作者实体的消歧处理。相对于文本数据,文献篇级数据的规范性要好得多,所以也易于抽取特征值。但是,在实际应用中仍然存在数据错误或者缺失的情况,会影响消歧效果。
本文提出的算法虽然已经能够在具体应用中取得较好的效果,但还是有很多地方需要进一步改进,可以建立一个简易的关于机构常用限定词的词表,比如描述地域的“中国”、“北京”等,描述机构性质的“大学”、“学院”、“研究所”等,在进行模糊匹配时,对机构名中这些不同性质的词分别赋予不同的权值,最后依据加权匹配的结果来判定匹配的成功与否,这样能够得到更好的模糊匹配效果。
另外,在实际应用的过程中,还可以加入用户反馈机制,以便能够及时发现消歧结果不够理想的作者实体,进而通过修改模糊匹配参数,限制约束规则或者人工介入等方法来改进消歧结果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|