{kind=link}
{kind=link}
{kind=link}
多特征视频分类挖掘实验研究
[陈芬1, 2  , 赖茂生
, 赖茂生3 ]
, 赖茂生|
|


主要描述笔者进行的分类挖掘研究实验。该实验基于北卡罗来纳大学(UNC)的Open Video项目,使用支持向量机对抽取的低层视觉和高层语义特征进行挖掘,考察不同类型的关键帧集合对于分类结果的影响并全面比较各种类型的特征及不同组合在分类中的贡献。结果表明,基于多特征的视觉和文本的结合能够取得较好的分类结果;此外,关键词和描述对挖掘效果具有不同影响。
This article introduces a classification experiment which is based on UNC’s Open Video project. In this experiment, the authors focus on the respective effects of different types of key frame collection, and compare the contribution of various features and their combination in details. Furthermore,the result shows that combination of visual and text features can achieve the best mining accuracy, and keywords and descriptions have different influence on the mining effect.
分类是视频挖掘中常见的研究内容,目标是按类存放视频各级组成部分,以便于管理、浏览和访问。分类构成了视频查询和浏览的有效辅助手段、便于用户对视频资源的使用。本文将重点放在视频分类的研究上。
视频分类领域的一些代表性研究包括Fischer等[ 1]、Chang等[ 2]、Chen等[ 3]、Pan等[ 4]、Yang等[ 5]、Rasheed等[ 6]、Yuan等[ 7]。可以看出,视频分类挖掘技术呈现多样化,并没有固定的模式,各种研究涉及了不同的特征及抽取方式、挖掘算法,并选择了不同的视频类别。
本文针对Open Video Digital Library(OVDL)项目中的数据进行分类挖掘研究。Open Video[ 8]提供了对视频进行深入开发的良好基础,尤其是它包含完整的元数据信息,除了文本元数据之外,还提供诸如故事板、快进以及海报帧等显示工具(Surrogates)。Open Video生成了三种类型的视觉工具:
(1)Base Keyframes(Base Collection):从视频文件中根据帧差进行系统、自动的抽取[ 9];
(2)Storyboards(Storyboard Collection):人工从上述数据集中选择,每个视频最多包含36个关键帧;
(3)Poster Frames(Poster Collection):人工从Storyboard Collection选择,是最具代表性的关键帧。
拥有了OVDL项目提供的多渠道信息,笔者将进行分类技术的研究、尤其关注不同大小的样本集合对分类效果的影响,即三种不同集合(Base Collection、Storyboard Collection及Poster Collection)的性能差别。
此外,现有的实验对于各种特征及其组合对分类效果的影响的研究仍然不够详细和系统;本文将对相关特征及其组合的效果进行更加系统细致的分析。
(1)视频类目的选择
本实验挑选了6个类目,如表1所示:
| 表1 视频的类目选择 |
(2)训练集(Training Set)与测试集(Test Set)
训练集包含150个视频,从相应的集合中随机抽取;测试集包含50个视频,如表2所示:
| 表2 训练集和测试集 |
本实验主要采用两种方法来评估挖掘的精确度。
(1)准确率
准确率(Precision)用来评估正确分类视频的比率,公式如下:
Precision=
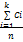
其中,k为类的数目,Ci为分类结果中与Gold Standard(每一个视频所属的正确集合类别)重合的视频数目,n是测试集的视频数目。该数值越大,分类效果越好。
(2)Cohen’s Kappa系数
Cohen’s Kappa系数是一个可靠性的统计度量,公式如下[ 10]:
k=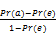
其中,Pr(a)为相对观测一致性系数,Pr(e)为一致性发生的概率。
Landis和Koch给出了对k值的解释[ 10],如表3所示:
| 表3 Kappa的解释[ 10] |
虽然没有显著的证据来支撑表3中的结论,但仍然可以使用它来进行比较,并且可以把准确率和Kappa系数结合在一起使用。
研究者已经开发了多种类型的分类器,本文选择支持向量机(Support Vector Machine,SVM)分类算法,该分类器在现有的研究中得到了广泛的应用。
(1)低层视觉特征
本实验采用的低层视觉特征主要包括:
①颜色:颜色在某种程度上描述了视频的语义信息,例如红色通常代表热情、火焰。同时,颜色对于尺寸、方向及其它特征的依赖性较小,具有鲁棒性。本实验采用HSV颜色直方图提取算法。
②纹理:本实验采用灰度共生矩阵提取纹理特征。这个方法已有较长的研究历史,也是当前人们普遍认可的一种重要的纹理分析方法。
(2)高层文本特征
除了低层视觉特征之外,本实验还利用了文本特征,主要包含4个处理步骤:
①文本转换(Transformations)。使用视频文本集合所有词汇生成一个大小为n×m的搜索空间,这里,n为视频文件的数量,m为词汇。具体实例如表4所示:
| 表4 搜索空间矩阵 |
②计算TF(Term Frequency)。识别集合中出现频率最高的词,频率可以根据具体应用来设定,本实验选择Top20。
③计算IDF(Inverse Document Frequency)。IDF有不同的计算公式,本实验中,采用Karen Sparck Jones[ 11]算法,如下所示:
IDFi=log(N)-log(n)+1 (3)
其中,N为视频文档数量,n为词i出现的文档数量。 ④计算TF*IDF。根据计算出来的TF和IDF值,再计算TF*IDF的数值。
本实验使用Open Video的两种类型文本:Description(描述)和Keywords(关键词)。Description对视频的主要内容进行了刻画;Keywords则是对视频进行基于文本检索的关键词。处理步骤如下所示:
算法:关键词(Keywords)和描述(Description)的处理步骤
①去除停用词:使用包含大约600个普通词项的停用词表文件[ 12],并且笔者做了额外的改动和补充;
②使用Porter Stemming算法得到词根形式;
③计算TF*IDF数值,选择具有最高值的20个词;
④构建词频-文档(Term Frequency-Document)矩阵。
除了使用SVM对各种特征及其不同组合进行自动分类之外,笔者还使用随机分类方法来进行效果的对比。这样,将拥有两个结果集,如表5所示:
| 表5 结果集 |
结果集1为随机分类。该种方式没有使用视频的任何特征,仅仅根据程序生成的随机数自动将视频赋予某一个类。值得注意的是,随机分类在不同的时刻有可能产生不同的结果,因此,它的运行结果是不稳定的。
结果集2为自动分类,它包含三个主要部分共17种不同的特征组合:基于视觉特征的分类;基于文本特征的分类;基于上述两种特征组合的分类。详细情况如表6所示:
| 表6 自动分类 |
(1)基于视觉特征的分类
表6列出了14个仅使用视觉特征的分类。在此环境中,数据中用来表征每一个关键帧的向量为80维:72维的颜色加上8维的纹理。
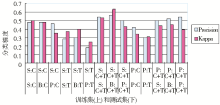
该部分的分类结果如图1所示:
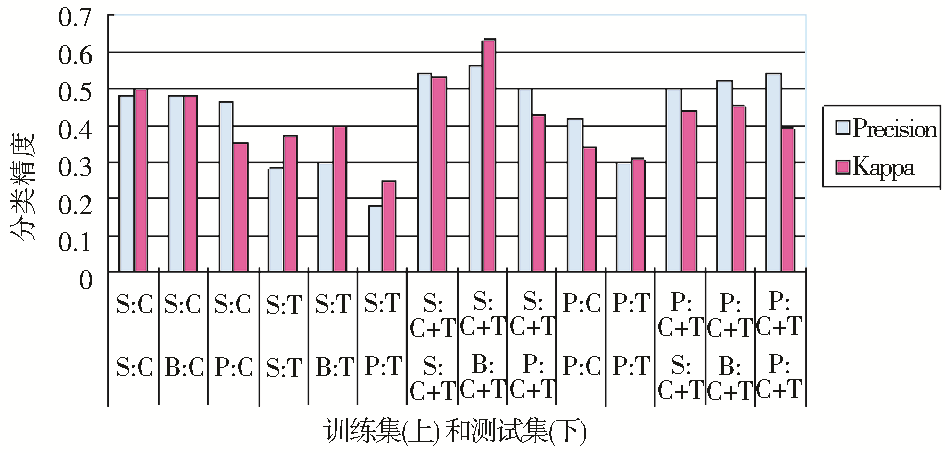 | 图1 基于视觉特征的分类结果(注:S:Storyboard Collection,P:Poster Collection,B:Base Collection,C:颜色,T:纹理,C+T:颜色和纹理的结合) |
从图1可以看出:
①相对随机分类,基于视觉特征的分类能够取得更好的效果。
②仅使用纹理特征构建的分类模式效果最差;比起纹理来,仅使用颜色能够获得好一些的效果。对于视觉特征来说,颜色和纹理相结合的效果最好。
③使用多关键帧来构造分类器比仅使用一个海报(Poster)的效果要好。显然,只用单独的帧来表征视频所含的丰富的视觉信息仍然是不足的。
④Base Collection的关键帧是Poster Collection的数百倍、是Storyboard Collection的数十倍,但是,实验结果表明,机器自动抽取与手工选择的关键帧之间差异不是很大,这也表明,人工选取的关键帧已经具有较好的代表性。
⑤在该组实验中,相对而言,Condition 2和Condition 3(见表6)取得了最好的效果。
(2)基于文本的视频分类
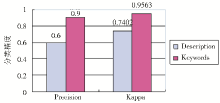
基于文本的视频分类显示了比较好的结果,如图2所示:
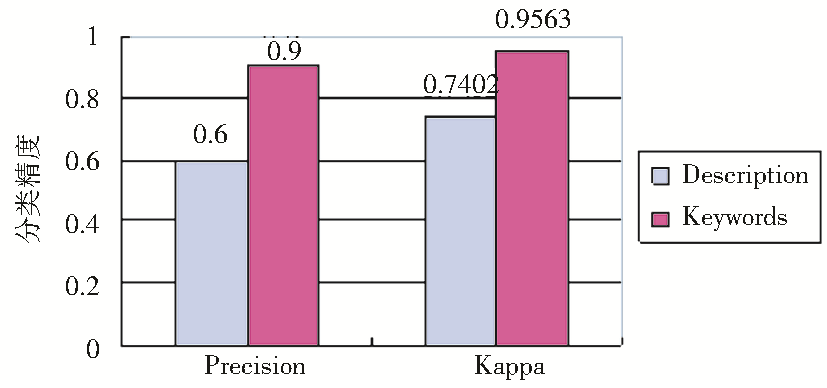 | 图2 基于文本的视频分类结果 |
进行基于文本的视频分类时,选择了Top 20词来表征视频;当然,也有例外,有时选择了超过20个词,这是因为最后的若干个词具有相同的TF*IDF值。
从图2可以看出:
①相对基于视觉特征的分类,基于文本的视频分类能够得到更好的结果。原因可能是视觉特征为低层特征,而文本特征是高层特征、常常表征语义和概念。
②Keywords的性能比Description要更好,无论是Precision还是Kappa系数都达到了很高的数值。笔者分析,原因在于:虽然Keywords和Description都由人工选择,但Keywords常常表达事物的核心概念,而Description则是关于视频的描述,有可能使用名词或者动词之外的其他不具有实际意义的词来保持句子的连贯性。因此,当使用严格的TF*IDF进行计算时,一些不相关的词就会影响分类效果。
(3)基于视觉和文本信息结合的视频分类
如前所述,在基于视觉特征的分类中,颜色和纹理的结合能够得到最好的效果;而在基于文本的视频分类中,基于关键词的效果最佳。笔者将把这两个条件结合起来。这里,测试集和训练集都将基于Storyboard Collection。即,下面的实验是Condition 2和Condition 5的结合。
除了Poster Collection外,视频通常由多个关键帧表征;而在基于文本的分类中,一个视频只通过一个向量来描述。当把它们结合在一起时,必须进行数据维数的一致性处理,具体的算法如下所示:
算法:使用视觉和文本特征进行视频分类
①根据视频ID对关键帧分组;
②计算颜色和纹理属性的均值和标准差,得到72维颜色均值、72维颜色标准差、8维纹理均值、8维纹理标准差。这样,视频将由一列包含颜色和纹理属性的均值和标准差的数值表征;
③结合视觉和文本特征数据,对视频进行分类。
分类结果如表8所示:
| 表8 基于视觉和文本特征的视频分类 |
可以看出,基于文本和视觉特征相结合的分类方案取得了最好的结果,无论是Precision还是Kappa值都非常高,并且是所有自动分类条件中结果最好的。这些都表明,视觉和文本特征相结合能够强化挖掘效果。
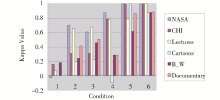
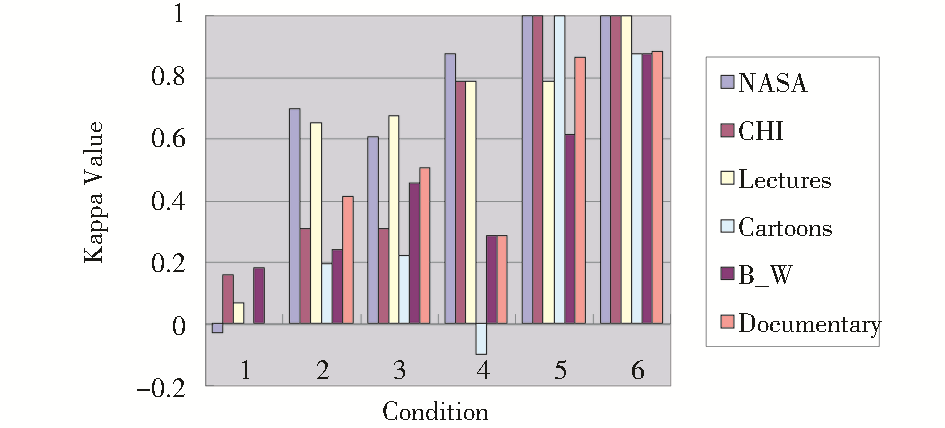 | 图3 单个类的分类效果(注:Condition: 1-Random Classification; 2-Storyboard Collection; 3-Base Collection; 4-Description; 5-Keywords; 6-Visual Features and Keywords together) |
(1)随机分类仍然取得了最差的结果;
(2)除了随机分类之外,其他所有的分类方式对于NASA和Lectures类都取得了比较好的效果,这意味着机器对这两个类有比较好的识别能力;
(3)Condition 6,即视觉和文本特征相结合的方式又一次取得了最佳效果;
(4)图3中的结果与前面所获得的结果是相一致的。以Condition 6为例,如果它不能够在几乎所有的6个类目上都取得最好的精确度,则它也不可能取得表8中所示的最佳的总体分类效果。
目前的视频分类挖掘实验,大部分研究首先使用一些特征抽取技术,然后基于训练集构建模式,最后将推断的模式应用到测试集上。各种方法的差别在于选取的特征、各种特征结合的方式以及分类器的选择的不同。本实验采用了类似的研究思路。实验中,超过80个分类器被训练、用来构建分类模式。
与以往的视频分类实验相比,本实验重点考察了不同类型的关键帧集合对于分类结果的影响,它们都基于Open Video项目的前期处理结果。拥有了这三个不同的关键帧集合,就可以考察不同的关键帧抽取方式、以及关键帧的不同数量对分类结果的影响。结果显示,增加多样的视觉信息能够得到更好的效果;然而,即使较小规模的视觉信息样本,也能够提供非常合理的结果;其中的平衡就是机器的计算量和人工的劳动量。
本实验全面比较了各种类型的特征及不同组合在分类中的贡献,主要包括三个部分:视觉特征、文本特征以及它们的综合。结果显示,针对单独的特征而言,文本(主要是关键词)能够取得最好的效果;对于特征组合而言,视觉特征和文本的结合能够取得最佳的分类结果。该实验的另一个重要结论是关键词和描述(相当于摘要)对挖掘效果的不同影响;现有的文献较少有关于这方面的探讨,本文的研究对于基于文本的视频挖掘中文本的来源选择具有借鉴意义。
此外,本实验也可以与用户分类结合起来,研究机器理解与人类认识事物之间的关联,从而促进两者的更好结合。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|