
{kind=link}
{kind=link}
{kind=link}
{kind=link}
同行评议专家遴选系统研究与实现
[李振清1 , 刘建毅2  , 王枞
, 王枞3 , 吴旭3, 4 ]
, 王枞|
|


设计并实现一个科技项目同行评议专家智能遴选系统,以专家信息和专家档案库为基础,采用基于统计的术语抽取技术解决未登录词问题,利用向量空间检索计算待评审项目和评审专家的相关性,根据相关性大小遴选出最合适的评审专家。
The paper designs and implements a peer-review expert selection system for technology projects. Based on experts’ information and archives, the system uses statistics-based term extraction technology to solve the unknown words problem, and uses vector space retrieval to calculate the similarity between the project and peer-review experts.Finally,it selects the most appropriate peer-review experts according to the similarity.
同行评议是国内外科技项目评审采用的主要方法,是由从事该领域或接近该领域的专家来评定一项研究工作的学术水平或重要性的一种方法[ 1, 2, 3]。评议专家是项目评审的主体,其评审结果与专家的个人水平相联系,因此正确选择同行评议专家在科技评价中至关重要。
本文设计并实现针对机械行业的科技项目同行评议专家智能遴选系统,以科技成果库和评审专家库为基础,根据项目申请书的项目名称、项目关键词、项目摘要和项目创新点查询,与评审专家近年发表的论文和研究项目进行语义匹配,检索出最适合、研究领域最相关的项目评审专家。
目前,专家检索技术的研究主要集中于对组织机构(或企业)内的专家检索的研究。所谓组织机构内的专家检索,就是利用组织内外能够表征专家专长的各种文档和资源(包括网站网页、数据库、电子邮件、报告等),根据给定的查询主题(领域),构建专家识别与检索模型;并根据所计算的专家在给定查询主题的专长(相关性)程度,按程度高低排序并输出排序后的相关专家结果列表[ 4]。
专家检索技术主要有基于专家描述的方法和基于社会网络的方法。基于专家描述的方法利用信息检索技术来查找专家,该方法首先在网络上抓取候选专家的所有信息(如论文、项目、论著等),以此构建专家的个人描述信息,然后利用信息检索技术对专家描述文档集进行索引和检索,实现专家检索。2005年TREC在Enterprise Track中加入了Expert Search 的任务,正式搭建了专家搜索的公用平台,格拉斯哥大学、亚洲微软研究院等世界多家著名研究机构参加了评测,大大推动了专家检索的发展[ 5, 6]。目前,TREC 的企业专家检索已经举办了5届,期间出现了很多可用的模型与方法,如基于文档集排序的方法/基于主题的模型、基于专家描述的方法/基于专家的模型、基于主题与专家关联的方法等[ 7]。
基于社会网络的方法利用专家和专家之间的关系来查找专家,该方法根据特定的语料,将专家之间的某种联系或关系构建成社会网络,然后利用网络关系及社会网络分析技术,来提高专家检索的效率与精度[ 7]。研究人员最早利用专家邮件来识别具有共同兴趣的团体,如富羽鹏等[ 8]利用电子邮件网络中接收者与发送者的收发关系,通过邮件分析来解决专家检索问题。Zhang等[ 9]通过研究分析在线论坛、聊天日志等社区中各参与者所形成的网络来进行社区中的专家查找。
近几年来,国内学者也开始同行评议系统方面的研究和建设。张晨等[ 10]基于二维语义证据推理实现了基金项目的同行评议系统;贺颖等[ 11]采用科学知识图谱实现了交叉学科的评议专家遴选的方法;刘一星等[ 12]采用文本分类方法实现评议专家的遴选。目前,国内很多科技管理部门已经建设了专家检索引擎,并拥有一定规模的专家库,如科学技术部建立了国家科技计划专家库,采取随机抽取的方式选取专家。这些系统在实际应用中的不足集中表现为:
(1)目前的专家遴选系统多采用数据库搜索为主,根据申请书的领域与专家的研究领域进行匹配,然而遴选系统中的学科分类体系是固定的,且颗粒度较粗,很难精确反应专家的研究专长。本文采用向量空间检索技术,计算专家的研究成果(包括论文、专利、项目等信息)与申请书的相似度,再根据相似度大小遴选专家。
(2)评议专家的学术资料中存在大量的科研术语,这些都是未登录词,在数据库搜索时会影响搜索的精确度,可能返回一些不相关的专家。本文采用术语抽取技术从申请书库语料中自动抽取术语。
针对中国机械工业联合会的科研项目评审需求,本文设计实现了同行评议专家遴选系统。该系统依托检索领域,采用基于统计的术语抽取技术解决未登录词问题,利用向量空间检索计算待评审项目和评审专家的相关性,实现对专家信息的精确查找。
同行评议专家智能遴选系统采用C/S模式,可运行在Windows或Linux操作系统上,使用Tomcat5.5以上的Web服务器和MySQL5.0以上的数据库,支持PDF、DOC、HTML、XML、TXT等多格式资料。
同行评议专家智能遴选系统分为三个层次,自上而下分别是:表现层、应用层、数据层。上层是下层的客户,下层是上层的服务提供者,如图1所示:
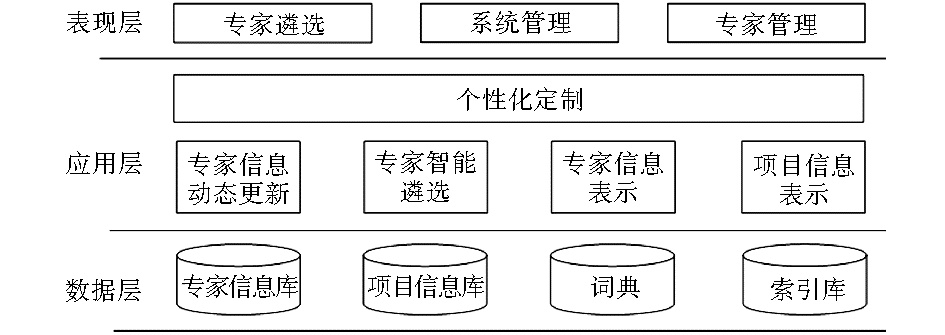 | 图1 同行评议专家智能遴选系统的体系结构 |
(1)表现层包括项目管理、专家管理、专家遴选及相关数据展示等主要功能模块。模块之间相互独立,根据用户使用特点和角色的不同,形成个性化的应用界面,并通过对事件和消息的处理传输构成一个完整的申请书评审流程。
(2)应用层包括专家信息动态更新、专家智能遴选、专家信息表示、项目信息表示等功能模块,提供个性化定制模块,帮助用户表示、管理、组织和查询相关的信息。
(3)数据层包括专家信息、项目信息、分词词典、信息索引库等,数据的获取可以通过手工录入,也可以利用元搜索实现自动采集。
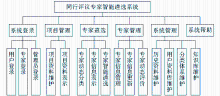
同行评议专家智能遴选系统的功能如图2所示:
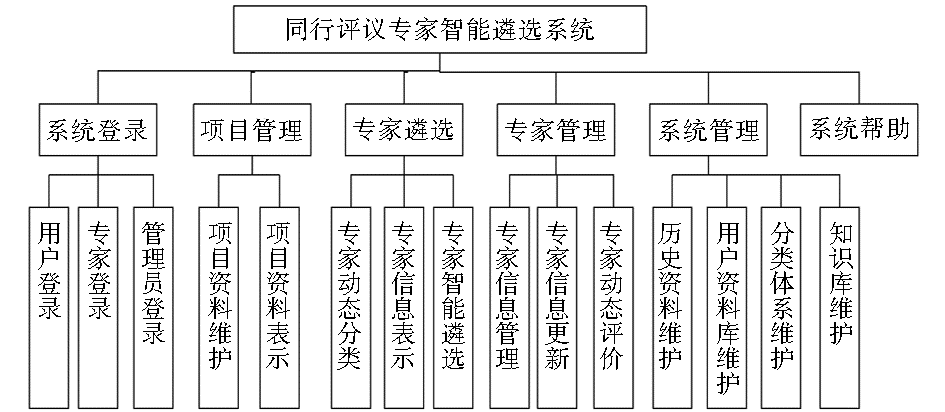 | 图2 同行评议专家智能遴选系统的功能结构 |
(1)专家管理:支持结构化、非结构化(主要指专家的论文获奖情况等) 专家信息的录入、删除、修改等。目前中国机械工业联合会的同行评议专家智能遴选系统已建立了光机电一体化技术、电子与信息技术、新能源与高效节能技术、新材料技术、资源与环境、高分子等技术领域专家信息。
(2)专家遴选:支持结构化信息与非结构化信息的综合检索,基于待评审申请书内容与专家非结构化信息的向量空间检索,可以精确查找专家信息。
(3)系统管理:维护科技项目行业分类信息,包括行业分类信息的录入、删除、修改等,行业分类信息的统计与查询。目前中国机械工业联合会的同行评议专家智能遴选系统已涉及纺织机械、测试设备、轻工行业设备、包装机械、机床、印刷机械、通用机械、矿山机械、工程机械、自动化、塑料机械、农业机械、印刷机械等行业。
(4)项目管理:维护申请书信息,包括项目申请书信息的录入、删除、修改等,通过抽取术语、关键词等进行项目申请书信息的统计与查询。
专家信息库中的专家信息由结构化数据和非结构化数据组成。结构化数据涉及专家的基本信息,包含28个字段,即编号、姓名、性别、身份证、年龄、学历、学位、职务、职称、单位性质、单位名称、通讯地址、邮编、主管部门、所在省市、办公电话、传真、电子信箱、移动电话、专家类别、上网能力、简历、社会兼职、单位意见、技术领域等。非结构化数据涉及专家学术成果信息,包含专家的研究方向(与所属领域不同)、发表论文的标题和摘要、参加项目等,以XML的格式存储。本系统中专家遴选主要依据非结构化数据(包括已发表的论文、项目摘要等)与项目申请书的相关度。
项目信息库保存项目申请书,在申请书库的基础上,对申请书构建统计模型,即通过计算检索申请书中的各个检索词在整个申请书中出现的概率,为申请书中的每一个检索词分配权重,进而表示项目申请书。
一个项目申请书由很多词(Term)组成,不同的Term对于项目申请书的重要性不同,越重要的词权重越大,对项目申请书语义的贡献也越大。词的权重利用tf*idf方法衡量[ 13]:
wt,d=tft,d*log(N/dft)
其中,wt,d是词t在文档d中的权重,tft,d是词t在文档d中的出现频率,N是文档集中的总文档数,dft是文档集中包含词t的文档数。
这样,一篇项目申请书可以表示为一个向量:
Document Vector = {weight1, weight2, …… ,weightN}
其中,weighti为词i在项目申请书中的权重。
类似地,专家也可以表示为一个向量:
Expert Vector = {weight1, weight2, …… ,weightN}
其中,weighti为词i在专家描述文档中的权重。
专家信息与科研项目申请书的相似度计算的有效性,决定着是否能遴选出合适的专家,同时也需兼顾系统的速度。本系统利用向量空间检索实现相似度计算。
向量空间检索模块首先将项目申请书和评审专家分别构建为一个向量,通过项目申请书向量q与评审专家信息向量d之间的相似度大小,得到与项目申请书最为相似的专家列表。相似度计算公式为[ 14]:
Sim(q,d)= 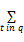
·lengthNorm(t.field in d)
其中,q为项目申请书,t为q中的一个关键词,tf为项目申请书中出现t的频率,idf为t在倒排文档中出现的频率,boost为域的加权因子,它的值在索引过程中进行设置,lengthNorm为域的标准化值,即在某一域中所有项的个数,本系统只设定三个域,即科研项目申请书的标题、关键词、摘要,其默认权值依次递减,也可由用户指定。
专家信息和项目申请书中通常涉及大量专有领域的学术名词,而通用的分词程序并不能正确地识别这些术语名词。在通过关键词匹配计算相似度的检索系统中,分词错误将极大地影响到专家与项目申请书的相关度,最终导致系统准确率的下降。因此,在本系统中应用术语抽取技术十分必要。
本系统主要参考贺敏等[ 15]的方法,并在此基础上增加了候选术语串互信息的计算,在申请书库语料的基础上实现术语抽取。对申请书语料经过粗分词后,采用后缀数组抽取重复串,对于频次大于阈值的重复串作为候选术语,通过统计算法计算互信息、左右邻信息、成词概率来过滤垃圾串,生成术语。
术语是由多个词或者字组合生成的字符串,所以首先需要将频繁共现的字符串抽取出来作为候选术语,本文采用后缀数组统计字符串的频率,抽取重复串作为候选术语。对于抽取的候选术语,大部分是垃圾串,经过分析发现主要有两类:
(1)术语中的子串:如“氨基”、“丙二”、“传动”;
(2)频繁共现的非术语:如“这是”、 “对环境”。
针对垃圾串,本文采用的处理算法如下:
(1)计算候选串的互信息。互信息可以衡量词语间的相互依赖程度,也可用来衡量词语的组合和搭配关系,本文将互信息用来衡量候选串的内部稳定度。计算公式如下[ 16]:
MI(w1,w2,w3)=log 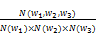
其中,wi为候选串中的词,N为在语料库中出现的次数,如果候选串的互信息太低,即认为该候选串不是术语而过滤掉。
(2)计算候选串的左右邻信息。候选串能够成为新词除了要内部稳定,还要外部松散,即该候选串的上文和下文环境都满足一定的多样性,本文采用左邻和右邻集合来描述,计算公式如下[ 15]:
Pleft(S)=|Vl(S)|, Pright(S)=|Vr(S)|
其中,S为候选串,Vl(S)、Vr(S)分别为S在语料库中的左邻集合和右邻集合,即出现S左边或右边的字、词等语言单位,Pleft(S)、Pright(S)分别为左邻集合和右邻集合中的元素个数。如果Pleft(S)或Pright(S)太低,说明该字串是术语中的字串,可以过滤掉。
(3)计算位置成词概率。汉语中的每个汉字有特有的构词法,并非所有汉字都可以出现在词首、词中或词尾。本文采用位置成词概率来描述这一特点,计算公式如下[ 15]:
Pword(c,pos)= 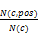
其中,c为汉字,pos为汉字在候选串中的位置(取值为0、1,表示词首和词尾),N为在语料库中的出现次数。若某个字的位置成词概率太低,认为该汉字不能作为词首或词尾出现,即可作为第二类垃圾串过滤掉。
该算法对申请书语料库进行术语抽取,得到的抽取性能如表1所示:
| 表1 术语抽取效果 |
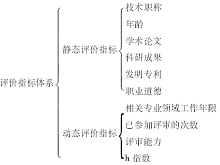
专家遴选除了考虑与项目申请书的相似度,还需要考虑专家自身的合适度,因此需要对专家进行评价。在实际应用中,对专家的评估涉及到诸多因素,除上述的成果及基本信息限制外,本系统通过问卷调查和总结中国机械工业联合会组织项目评审过程中的经验积累,建立了专家评价指标体系,如图3所示:
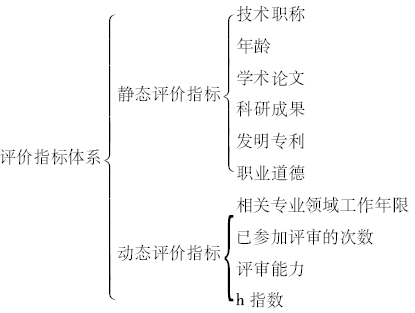 | 图3 专家评价指标体系 |
其中,静态评价指标中职业道德一票否决;学术论文、科研成果、发明专利按领域、数量、等级等进行归一化处理。
评审能力是指专家在过往评审记录中,该专家的意见同项目最终评审意见的一致程度。假设专家曾评审过n个项目,则其评审能力AC为:
AC= 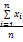

h指数是指在一定期间内一名科研人员发表的论文至少有h篇的被引频次不低于h次。为了保证专家发表论文和引用论文的质量,本系统只取SCI、EI、SSCI、CSSCI 等大型引文索引数据库可以收集到同行评议专家发表的所有文章及这些文章的被引次数,且只取近5年内发表的论文。
同行评议专家的评价可表述为根据评价指标的计算值,对同行评议专家进行排序。评价问题中的关键是:评价指标的权重w=(w1,w2,…,wn)T和评价矩阵X=|xij|。这里,wi为评价指标Ci的权重,xij为同行评专家ei针对指标Cj的评价值。本文中的指标权重wi采用层次分析法计算得到。
(1)计算指标权重值。根据层次分析法的判别标准,首先由中国机械工业联合会给出不同指标的重要性程度,然后构造两两比较矩阵,最后得到指标的权重值wi。具体步骤参考文献[17]和文献[18]。
(2)归一化处理。为了便于计算和比较,将指标评价值归一化为:xij = xij /∑xij。
(3)计算同行评议专家的评价值。根据评价矩阵和权重,本文采用加权计算法得出同行评议专家的评价值v=w*XT。
(4)按照评价值对被选专家进行排序,并标示在本次评审中已选中的次数。
结合申请书相似度和专家评价指标综合得出的专家检索结果示例(其中灰色部分是由于涉及到专家个人信息,故此隐去),如图4所示:
 | 专家检索结果示例 |
同行评议专家智能遴选系统在运行期间积累了1 200名机械行业专家的信息,从项目信息库中随机选取了200项申请书测试本系统的专家遴选效果。在测试数据中,首先由人工为200项申请书分配了评审专家,作为评测的标准答案。
评价指标采用R-Precision和P@10,其中R-Precision是检索出与申请书相关的专家的准确率,即系统检索出的专家与人工分配的专家的匹配度;P@10是系统返回的前10个专家的准确率,P@10常常能有效地反映系统在真实应用环境下所表现的性能。
中国机械工业联合会之前采用的专家遴选系统是以数据库搜索为主,即根据科研项目申请书的学科领域与专家的研究领域的匹配度进行遴选。为了对比本系统的性能,将原专家遴选系统(简称“原系统”)作为基线,并将测试数据分为5组。本系统与原系统的P@10比较和 R-Precision比较如表2和表3所示:
| 表2 本系统比原系统的5组数据P@10比较 |
| 表3 本系统比原系统的5组数据R-Precision比较 |
同行评议是目前科技项目评审最常用的方法,虽然国内外对科技项目立项同行评议中的专家评价的理论研究较多,但是对专家的评价都没有建立一个完整的体系,只对某一部分进行分析,如何高质量抽取评价专家的问题仍然没有解决。本文设计和实现了一个科技项目同行评议专家智能遴选系统,以专家信息和专家档案库为基础,采用基于统计的术语抽取技术解决未登录词问题,利用向量空间检索计算待评审项目和评审专家的相关性,根据相关性大小遴选出最合适的评审专家。
在以后的工作中,还可以从以下几个方面对系统进行改进:进一步研究专家的评价指标体系和相关评价方法,提高评价的公正性;引入分布式检索架构,提高系统的性能;开发专用的专家搜索引擎。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|