{kind=link}
{kind=link}
中文生物医学文献主题标引中副主题词自动组配机制探讨
[李军莲 , 李丹亚, 孙海霞, 冀玉静, 李芳]
, 李丹亚, 孙海霞, 冀玉静, 李芳]
, 李丹亚, 孙海霞, 冀玉静, 李芳]
|
|


简要介绍当前国内外副主题词自动组配的研究现状,提出适用于中文生物医学文献处理的基于拼图-统计学习相结合的副主题词自动组配实现方法,详细阐述分析该混合策略方法的实现机制及实现效果,并指出后续的改进建议。
This paper briefly introduces the current research status of automatic MeSH subheading attachment both home and abroad. After systematic research, a “Jigsaw puzzle”-statistical method combined approach is proposed, which is suitable for dealing with Chinese biomedical literature. Moreover, the realization mechanism of this integrated method is analyzed in details and the corresponding results are evaluated. In addition, suggestions expected to improve the practical value of main heading/subheading pair recommendation are further raised.
副主题词是用于对主题概念进行限定的一类词汇,强调主题概念的某些专指方面。主题标引中,通过副主题词与主题词组配,不仅可以提高揭示文献的专指性,而且能清晰反映主题概念间的关系,全面提升检索系统的准确率。
副主题词组配是生物医学文献主题标引中最常见的形式,约90%的文献在标引时应考虑组配合适的副主题词[ 1]。2002年,中国医学科学院医学信息研究所研制的中文生物医学文献主题标引系统投入实际应用后,极大地提高了中国生物医学文献数据库(CBM)入库文献的标引效率和标引质量[ 2]。但该系统目前仅推荐游离主题词和副主题词,副主题词组配标引基本采用人工方式进行,很难满足中文生物医学文献快速增长的需要,是制约主题标引工作效率提高的瓶颈之一。
美国国立医学图书馆(NLM)一直走在此项研究的前列,其自动标引项目于2007年前后将副主题词自动组配研究提上日程[ 3],阶段研究成果已在其数据创建和管理系统(DCMS)中得到初步应用。通过向标引员提供副主题词组配推荐,在一定程度上提升了文献标引效率,促进了Medline/PubMed数据库的发展。
NLM的医学文本标引工具(MTI)尝试采用多种方法实现副主题词自动组配,包括拼图法(Jigsaw Method)、基于规则的方法(Rule-based Method)和PubMed相关文献方法(PubMed Related Citations,PRC)。经反复实验表明[ 5, 6],上述三类方法不仅实现难易程度不同,在处理效果上也各有优劣,而综合使用两种以上的方法,无论是准确率(Precision)还是召回率(Recall),均优于单纯使用某一种方法。
鉴于此,在全面解析MTI副主题词自动组配方法的实现机制和实现效果[ 4]的基础上,结合中文生物医学文献主题标引的特点,本文提出了多种副主题词自动组配实现方案:拼图法、统计学习法、UMLS语义规则法及拼图-统计学习相结合的混合策略方法,并从实用可行角度对各方法进行了初步实现与评估,最终结果表明混合策略方法较好。本文基于拼图-统计学习相结合的混合策略对中文生物医学文献副主题词自动组配实现机制及实现效果进行详细介绍。
副主题词自动组配实现机制
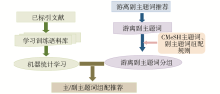
混合策略综合吸纳了MTI拼图法和PRC的思想,基本思路为:首先根据各类映射表,推荐游离主题词、游离副主题词和既定主题词/副主题词,再依据《中文医学主题词表》(CMeSH)标引规则将游离副主题词按照可组配的主题词进行分组,最后基于构建好的专题语料进行统计学习,实现游离主题词与副主题词的组配推荐,如图1所示:
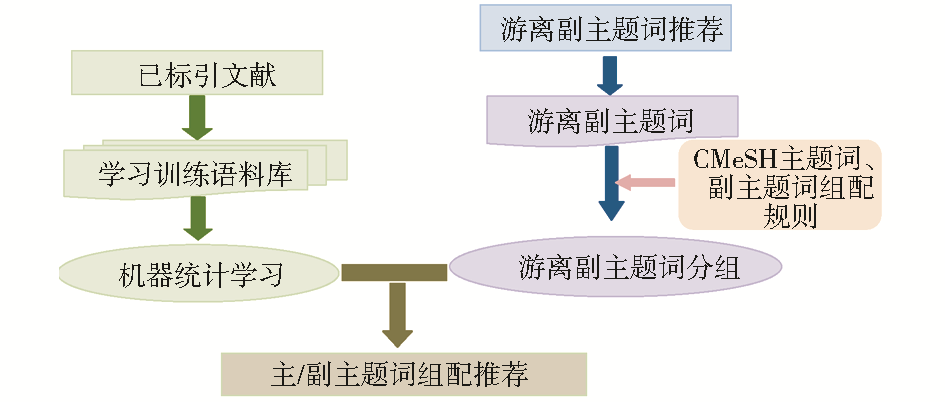 | 图1 基于混合策略的副主题词自动组配实现思路 |
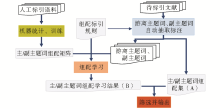
基于混合策略的副主题词自动组配方案实现流程主要包括4个步骤:语料统计训练、待标引文献主题初步提取、主/副主题词组配学习、结果筛选与输出,如图2所示:
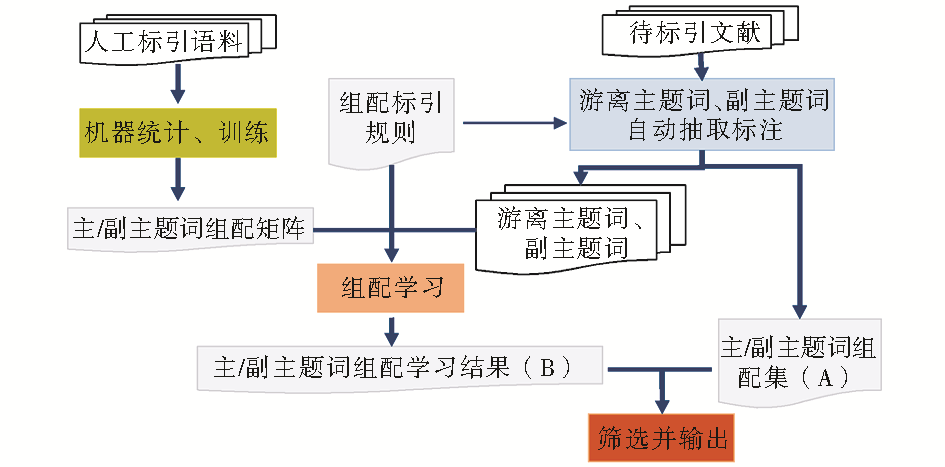 | 图2 基于拼图法和统计的混合方法实现流程 |
(1)语料统计、训练
基于构建好的人工标引语料进行主题词与副主题词组配情况统计、训练。统计结果存储于二维矩阵中,行为94个副主题词,列为语料中出现的主题词,值为副主题词与主题词在语料中的组配频次。
(2)待标引文献主题初步提取标注
根据CMeSH标引规则及长期积累的医学关键词语料、关键词-主题词映射表、关键词-副主题词映射表、关键词-特征词映射表,通过分词、加权等技术,自动抽取、标注体现文献内容的游离主题词、游离副主题词和既定主/副主题词组配。
如文献“豚鼠前庭椭圆囊器官在庆大霉素损伤后离体培养的细胞增殖”经主题初步提取标注后,可得到如下处理结果(其中“*”标明该主题是文献讨论的重点内容):
游离推荐主题词:*庆大霉素类; *球囊和椭圆囊; *创伤和损伤; *溴脱氧尿苷;前庭, 迷路; 毛细胞, 听觉; 细胞, 培养的; 细胞增殖
游离推荐副主题词:/损伤; /细胞学; /方法; /解剖学和组织学; /教育
(3)游离副主题词与主题词组配学习
①根据CMeSH标引规则,以主题词为单位,对游离副主题词进行分组。一个副主题词可以与多个主题词组配,所以一个副主题词可以属于多个组。以主题词H为例,其对应的副主题词组SH中为当前文献中所有可与H组配的游离副主题词。
②对每个主题词可组配的副主题词进行学习。同样以主题词H为例,学习过程为:首先依次判定SH中的游离副主题词是否出现在主/副主题词二维矩阵中主题词H对应的副主题词集合中;如出现,再判定是否满足其他权值条件,满足则存于主/副主题词组配集合B中。如SH中的所有游离副主题词都未出现,取矩阵中最高频次的副主题词与H组配,存于B中。
(4)结果筛选与输出
对既定主/副主题词组配抽取标注结果与B中的学习结果进行融和,按既定过滤规则进行筛选、输出。
实现效果分析
为进一步验证该思路与方法的科学性与可行性,笔者开展了如下实验:按照设计思路初步实现中文生物医学文献副主题词的自动组配,并对随机抽取的部分实现结果进行分析,从副主题词标准率(Precision)和标全率(Recall)两方面对实现效果进行评价。
本实验主要分为两个阶段:基于原有的中文生物医学文献主题标引系统实现“中文生物医学文献副主题词的自动组配”,对实现结果进行分析评价。为方便后期分析评价的进行,拟从“标引训练集”中抽取部分数据进行“副主题词自动组配”实现,将处理结果与相应的人工标引结果进行比较分析。
本实验涉及两种数据,标引训练集和实验结果分析数据集。
(1)标引训练集
标引训练集用于统计学习主题词与副主题词的组配规律,其标引质量高低、学科覆盖全面与否直接影响统计学习训练的效果。根据CBM数据库的标引要求,最终遴选出标引深度较深、标引质量较好、涵盖学科较全的45 160篇文献作为标引训练集,具体如下:
①期刊分布:以中华系列、中国系列期刊为主,同时选取了部分大学学报及高质量交叉学科期刊。
②领域分布:以医学综合、临床综合为主,尽量涵盖医学各研究领域,具体分布详见表1。
③年代分布:2003年3 141篇;2006年15 789篇;2008年25 742篇。
(2)实验分析数据集
| 表1 标引训练集学科领域分布 |
选取标引训练集中的前2万篇文献进行“副主题词自动组配”效果测试,从中随机抽取150篇文献作为实验分析数据集进行副主题词自动组配效果分析。
对于自动标注效果的评价主要有两个指标:标准率和标全率。本实验拟借用这两个指标,将副主题词自动组配结果与人工标引结果及副主题词游离推荐结果进行对比分析,从而评估其科学性和可行性。
副主题词的标准率用于反映自动推荐出来的主副组配的准确程度,而标全率则用于评价自动推荐出来的主副组配结果与人工标引的吻合程度,二者的计算公式如下:
标准率= 
标全率= 
考虑到与现有中文生物医学文献主题标引系统的兼容性与可整合性,本实验通过C++编程来实现主题词和副主题词的自动组配。对测试集2万篇文献完成“副主题词自动组配”处理后,从中随机抽取150篇文献作为实验分析数据,如表2所示:
| 表2 测试结果示例 |
进行副主题词自动组配效果的判定分析,具体如下:
(1)本研究提出的基于混合策略的中文生物医学文献副主题词自动组配方法不仅能覆盖现有的94个副主题词,而且具有较好的标全率和标准率(标全率为61.5%,标准率为48.3%),如表3所示:
| 表3 副主题词自动组配推荐效果分析 |
(2)与原有自动标引系统游离副主题词推荐效果(标全率为43%,标准率为24.7%,见表4)相比,标全率和标准率均有比较明显的提升。
| 表4 原有自动标引系统游离副主题词推荐效果分析 |
(3)组配推荐效果基本达到了美国国立医学图书馆MTI文本标引工具副主题词自动组配的实现水平[ 5, 6]。与西文的各种处理方法相比,标准率虽低于“后处理规则法”,但却高于其他几种方法,包括综合法,如表5所示:
| 表5 中、西文文献副主题词自动组配实现效果对比 |
副主题词组配标引不仅可以提高揭示文献的专指性,而且能清晰反映主题概念间的关系,全面提升检索系统的准确率。实验初步表明,本研究提出的基于混合策略的中文生物医学文献副主题词自动组配方法具备一定的科学性、可行性。该方法不仅能全面覆盖现有的副主题词,而且具有较好的标全率和标准率,通过进一步优化完善可逐步投入实际应用。
同时,通过分析自动主副组配误推、漏推的原因,今后还需从如下方面予以提高:
(1)开展医学文献标引专题语料构建模型研究,最大限度提高组配学习效果。
统计训练、学习人工标引结果是基于混合策略的副主题词自动组配方法的主要思想之一,故标引训练集构建的科学与否至关重要,直接影响到主副组配训练学习的效果。在本研究中,虽然也从标引深度、标引质量、涵盖学科三方面考虑构建标引训练集,但并没有从量上进行有效控制,譬如在目前的训练集中,近3/4为医学综合、临床综合方面的文献,中医中药、药学、兽医学等方面的文献均不足5%(见表1),这也正是实验结果中医药方面副主题词自动组配效果不好的主要原因。在后续的研究中建议分领域构建标引训练集,有效控制语料规模和质量,最大限度提高主副组配训练学习效果。
(2)进一步解析系统现有标引机制,全面提高各环节实现效果。
本研究最初设计是基于现有主题标引系统副主题词游离推荐功能来探讨副主题词的自动组配机制,故实现过程中不可避免要受到游离主题词、游离副主题词推荐准确全面与否的影响。尽管在实验之前已经对“副主题词游离推荐”的思路进行了优化,但由于缺少进一步验证,在实验中仅用到扩充优化后的“关键词-副主题词映射表”,基于“主题词-副主题词”规则库的副主题词推荐方法暂时没有考虑。由此可见,要最终提升主副自动组配的效果,必须全面考虑主题标引的各个环节,仅仅停留在“组配”机制的探讨上是远远不够的。
(3)继续考虑发挥“规则”在主副自动组配中的作用。
鉴于高级、完备规则建立的复杂性,本研究最终提出的基于混合策略的副主题词自动组配方法将重点放在统计学习法和拼图法上,暂时弱化了基于“UMLS语义关系”的规则法的应用。虽然也得到了较好的实验效果,但错误推荐、无效推荐仍占相当比例,这无疑为标引人员带来了负担。在后续研究中,还应考虑发挥“规则”在主副自动组配中的作用,通过简单、有效的规则控制,切实提高主副组配的准确性,减少错误推荐和无效推荐。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|