{kind=link}
{kind=link}
{kind=link}
一种提高中英文混编文本标引准确性的方法
[赵衍1  , 陈恒
, 陈恒2, 3 ]
, 陈恒|
|


分析生命科学领域中英文混编文本的内在特点,基于控制论原理,提出一种旨在提高中英文混编文本的信息自动标引准确性的整合新方法。该方法包含三个相对独立而又相互联系的部分,即前馈控制、中期控制和反馈控制。实验表明,该新方法可以被成功应用在乙肝专题文献知识数据库的标引中,并能大幅度提高信息标引的准确性。
This paper elaborates the inherent characteristics of the Chinese-English mixed text in the field of life sciences. On basis of the cybernetic principle, a new integrated indexing control method, which is conducted to improve the accuracy of automatic indexing for Chinese-English mixed text, is proposed in this paper. The method includes three relatively independent and interdependent parts, which are feed-forward control, in-progress control, and feed-back control. Subsequently, the three parts and their integrated application effectiveness for improving the indexing accuracy are introduced in detail. Experimental results show that the proposed new method is successfully applied in indexing of the literature and knowledge database for Hepatitis B subject and the information indexing accuracy is greatly improved.
随着社会的发展,不同语种人群之间的交流越来越频繁,并催生了大量的多语种混编文本。大量的文本需要经过加工后才可以为人们所用。在文献加工中,信息标引是非常重要的一项工作。可是,不同语种在语法规则和组词方式上的巨大差异影响了信息标引的准确性,进而直接影响到文本的深加工质量。因此,研究多语种混编文本的信息标引准确性问题具有重要的理论意义和实践价值。
信息标引是用已知的规则对文档加上标注和索引,将文献特征标识出来,使得孤立的文档与已有的概念体系建立关联,便于文献的存储与使用[ 1]。按照不同的分类方式,有赋词标引和抽词标引,手工标引和自动标引等[ 2]。
由于控制词和目标文献存在多变性、复杂性、歧义性等特征,信息标引的准确性很难把握。特别是对一些不同语种混编的文本,语法规则和组词规则差异很大,因此更难控制其信息标引的准确性。
为了提高计算机赋词标引的准确性,学者们研究出多种方法。归纳起来,这些方法可分为两大类:标引前预处理法和标引中控制法。
这种方法在计算机赋词标引开始前,对控制词表和目标文献进行预处理,以减少标引中可能出现的错误。
(1)对控制词表的预处理
控制词表是进行信息标引的依据,控制词表的科学、规范与否直接影响标引结果的准确性。对控制词表的处理主要包括控制词表的完整性、规范化、同义词收录等。对于中英文混编的控制词表,需将全英文控制词、全中文控制词和中英文混编控制词进行分组,对不同的组采用不同的标引算法。此外,还需对控制词的先后顺序进行必要的调整。由于每个控制词中所含的字符数目不等,有时,“交集型歧义字段”[ 3]之间有包含关系,为保证目标文献中“长词”不被控制词表中的“短词”抢先标引,可将控制词按字符数由长到短排序,标引时也按照此顺序进行标引。
(2)对目标文献的预处理
对目标文献的预处理主要是对目标文献进行规范化,去除不必要的空格、连接符等,规范字符编码和标点符号。对于中英文混编文本,特别要注意英文字符、数字和连接符的全角和半角的设置问题。
(3)设置停用词表
通过设置停用词表,将文献中词频很高或很低的词做特殊标记,在标引过程中,直接忽略这些词,既可以提高标引的效率,又可以减少错误分词的情况。在英文文献中,一些语法结构词常常被设置为停用词,如冠词、连词、介词或助动词等。据统计,这类词在英语中有1 000多个,其中最常用的有150多个,如果去除这150多个通用词,将减少英文文本60%-70%的原始词数量[ 4]。停用词也可以包括数字、号码、标点符号等,视情况需要而定。中文文献中可作为停用词的数量也很大,主要是一些对主题意义影响不大的代词和虚词,如“关于”、“这是”、“能够”、“自己”、“的”等词。
(4)设置冻结词表
通过设置冻结词表,将一些特殊词予以保护,防止这些词在标引过程中被错误切分或部分标引。如一些特定的专门术语、人名、机构名和地名等。此外,一些可以与其他字组合成专有名词的虚字也可以纳入“冻结词表”予以保护。
前馈控制法作为中期控制的预备阶段,能在一定程度上预防标引错误的发生。
这种方法主要通过基于词典的分词方法和匹配规则实现。
(1)分词技术
分词技术是将连续的字所构成的句子切分成不同的具有一定意义的词的技术,它是中文信息处理的关键技术。影响分词技术发展的瓶颈是切分歧义,可分为交集型切分歧义和组合型切分歧义[ 5]。
(2)匹配规则
标引中控制法还可以通过应用程序和控制词表的结合,在标引的过程中对标引对象进行判断,尽量减少错误的出现,这种方法主要依靠匹配规则的设定。
根据匹配方向的不同,可分为正向匹配法和逆向匹配法;根据匹配字符长度的不同,有最大匹配法和最小匹配法等。从实际应用来看,主要有正向最大匹配分词(FMM)和反向最大匹配分词(BMM)两种[ 6]。根据梁南元[ 7]的统计,正向最大匹配分词的词汇错误切分率为1/169,反向最大匹配分词的错误率为1/245。如果结合两种匹配分词法可得到“双向最大匹配法”。Sun等[ 8]对大样本的汉语文献分别进行FMM和BMM的切分,统计结果发现,约90%的句子在两种方法下的切分结果是完全一致且正确的;约9%的句子虽然在两种切分方法下得到的分词结果不同,但其中必有一个是正确的;只有不到1%的句子在两种切分方法下得到的分词结果都是错的。即便如此,对于海量信息的文献标引来说,采用“双向最大匹配法”所产生的1%的标引错误从绝对数量上来看还是很大,依然无法彻底解决赋词标引的准确性问题。
到目前为止,上述两种方法都无法从根本上解决计算机自动赋词标引的准确性问题。
准确性一直是计算机自动赋词标引工作所面临的一个难题。多年来,很多学者对此进行了深入的研究,取得了大量的成果。但这些成果都局限于对单一语言的信息标引的研究,如中国学者的研究成果一般只局限于中文的信息标引,美国学者的研究成果一般只局限于英文的信息标引。对多语种混编文本信息标引的专门研究较少。在当今社会,多语种混编,特别是中英文混编,已经成为普遍现象。因此,对多语种混编文本的信息标引进行专门研究具有重要的理论意义和现实意义。
影响中英文混编文本信息标引准确性的原因主要在于中英文不同的语法格式和组词方式,主要有:
(1)单字和单词独立表达信息的能力
汉语的书写单位是字,但真正有意义的却是词,因为词是“最小的能独立运用的语言单位”[ 9],而计算机却只能识别单个的汉字而非词,因此,计算机对文本进行赋词标引时,只能机械地匹配字,而无法识别有意义的词;对英文的标引更是如此:计算机只能识别毫无意义的字母,而无法独立识别具有真正含义的单词。
(2)字符之间连接符的使用
在汉语中,字与字之间、词与词之间不需通过连接符连接;而在英语中,单词之间连接符的使用却很常见。但是,英文中连接符的使用比较随意,特别是在一些可用也可不用连接符的情况下,由于事先无法判断目标文本中是否采用了连接符,或者采用了什么样的连接符,因而也难以设置控制词表,影响了信息标引的准确性。
(3)词的截断方式
汉语中,虽然句与句之间通过标点符号截断,但是词与词之间却没有明确的分隔标志,很容易造成错误分词和词的错误截断;而在英语中,词与词之间通过空格自然分隔,错误分词的概率相对于汉语会小一些。
(4)词型和词性转换
汉语中,词型和词性的转换相对简单,如形容词只需在原词的后面加上虚词“地”即可转化为副词;但在英语中,词型和词性转换需要改变原词形式,这样,如果词型和词性发生转换,则控制词就无法匹配目标文献,也会导致信息标引的错误。
(5)词之间的包含关系
在汉语中,有一些词之间存在包含关系,即使将其拆开,拆开的部分依然能够独立表达主题,如“计算机网络”就包含“计算机”和“网络”两个词,如果把这两个词单独取出来,仍然可以表述其独立的意义;但在英语里面,即使能将存在包含关系的单词拆开,被拆出来的词也失去了其实际意义,如“Internet”,即使将“net”拆出来,也没有任何意义,因为该词在原文中并无独立意义。
(6)多义词
在英语和汉语中,都存在多义词问题。统计资料显示,53.43%的汉字具有两个或两个以上的义项[ 10]。由于控制词表的建设往往落后于信息的采集,因此,控制词表常常无法覆盖“一义多词”和“一词多义”的情况,造成漏标和误标。
以上的这些原因及它们的综合作用,降低了赋词标引的准确性;如果对中英文文本不做区分,而是采用相同处理方法和标引算法,标引的准确性将会受到更大的影响。
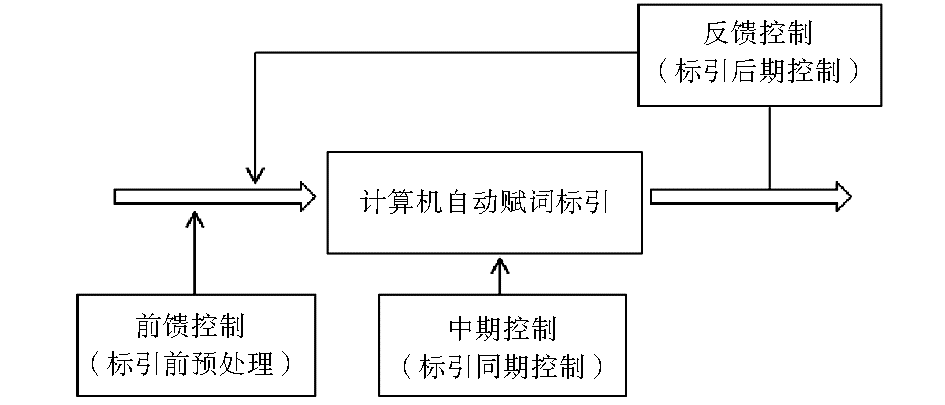
自1948年美国数学家诺伯特·维纳提出控制论以来,控制论的思想和方法几乎渗透到所有的自然科学和社会科学领域。从广义上来看,控制论是研究动态系统在变化的环境下如何达到平衡和稳定状态的一门科学。从控制手段起作用的节点来看,有前馈控制、中期控制和反馈控制三种,其中以反馈控制最为重要[ 11]。
从控制论角度来看,标引过程即为受控过程,提高标引准确性的规则即为控制条件,可将本文所述的标引前预处理法视为前馈控制,将标引中控制法视为中期控制,此外,为进一步提高标引的准确性,还需加入反馈控制[ 1]。
在反馈控制阶段,主要是人机结合的控制方法。先通过人工的方法对标引的错误结果进行统计归类,对同一类错误制定排错规则,然后利用计算机编程,将该错误结果反馈给目标文献库,遍历并改正所有同类的错误标引结果。由于通过这种方法来发现错误是通过人工方式实现的,因此,无法保证所有的标引错误都能够被发现。但该方法对于改正已被发现的同类标引错误非常有效。如果选取大样本的标引结果进行查错并对整个目标文献的标引错误进行修改,则可以将标引的错误率降低到可接受的范围之内。
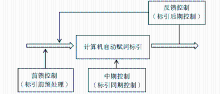
在实际工作中,由于中英文混编文本的编排情况复杂,如果仅采用其中的一种控制方法,标引的准确性是无法令人满意的。在条件允许的情况下,将这三种方法结合起来使用的效果会更好,即在标引前对控制词表和目标文献库进行预处理,在标引过程中进行标引的同期控制,在标引结束后根据实际需要,对标引结果进行抽样检查,并将错误的标引结果及原因反馈给标引系统,利用计算机程序进行全库的类似错误的反馈控制及修正。控制思想如图1所示:
 | 图1 提高中英文混编文本标引的准确性的综合方法 |
三种方法的结合使用不是功能上的简单叠加,而是可以互相促进,发挥协同工作的效果的过程,可以进一步提高信息标引的准确性,并提高信息标引的效率。如在反馈控制阶段,可以根据反馈信息,对冻结词表进一步修改和完善,以保证在前馈控制阶段有更精确的控制结果;前馈阶段控制得好,也减少了反馈控制的工作量,可以提高反馈控制的效果。
乙肝专题文献知识数据库由中国科学院上海生命科学信息中心和上海外国语大学共同研发。该数据库涵盖11个研究领域的乙肝相关文献,具有文献检索和知识挖掘功能。数据库中的知识挖掘工具能帮助用户在文献中发掘出蛋白质,通过该蛋白质链接到EBI-UniProt数据库和上海生物信息技术研究中心的乙肝病毒数据库,可以直接获取相关科学数据,为研究人员提供方便[ 12]。
为了提高信息源的质量,从美国NCBI的Medline中人工抽取出8 368条与乙肝相关的英文文献;从CNKI中人工抽取出3 953条中文文献,整个乙肝专题文献知识库共有文摘信息12 321条。
从EBI-UniProt数据库的蛋白质及基因名的索引文件中抽取了17 799条英文控制词,并将其全部翻译为中文,即共有35 598条控制词。
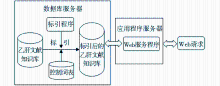
系统采用了B/S架构,数据库和Web应用程序部署在两台独立的IBM服务器上,操作系统采用Linux Ubuntu9.04,服务器软件采用Nginx0.87,脚本软件采用PHP5.2.10,数据库软件采用MySQL5.0.75。系统结构和工作原理如图2所示:
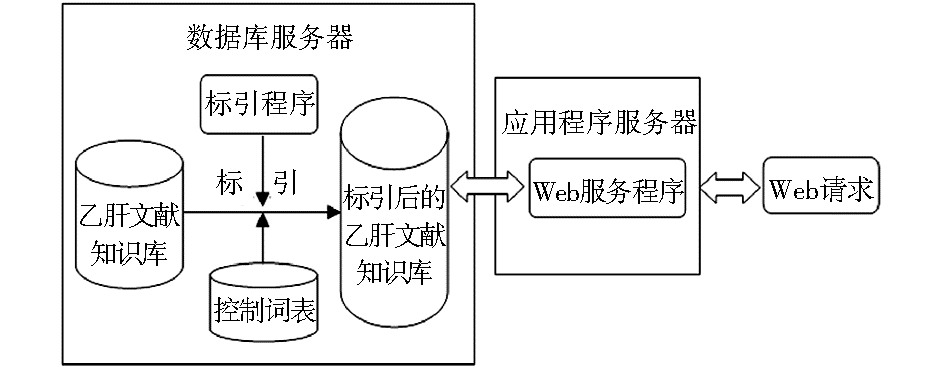 | 图2 乙肝专题文献知识库的标引和信息服务系统架构 |
从标引后的文献中随机抽取了2 000条记录进行统计。发现标引项总计8 913个,错误标引项1 021个,漏标213个。由此得出该信息标引系统的标引精度和召回率:
标引精度=(8913-1021)/8913×100%=88.54%
召回率=(8913-1021)/(8913-1021+213)×100%=97.37%
影响标引精度和召回率的主要原因有:
(1)误 标
误标即标引错误,即把不该标引的标引了或者是把本该标引为a的标引成b。主要有以下几种情况:
①控制词部分标记。主要是由于控制词表中的一些控制词是另一些控制词的一个部分,如有控制词“a”和“ab”对目标文本“abc”进行标引,如果控制词“a”先行对“abc”进行了标引,则当“ab”再对文献进行标引时会直接跳过已被“ab”标引的“abc”,形成误标,如“胰蛋白酶”被误标为“蛋白酶”。
②单词部分标记。由于生命科学领域有众多的缩写词和特义词,这些词经常恰巧是一些单词的某个部分,在标引时会被误标,如SARS被误标为“ARS”。
(2)漏 标
漏标即为本该标引的信息未被标引,主要原因有:
①书写格式不规范。有些英文控制词由多个单词和数字组成,这些单词和数字间有的有空格,有的则是用“-”、“_”等连接符连接,有的则没有任何分隔标志,情况比较复杂。
②一义多词。在生命科学领域,对于同一术语会有多种表述,对旧词的新表述也与日俱增。但控制词表无法及时收录所有的表述,由此造成漏标。如“海因酶(HDT)”,虽然标出“海因酶”,但简称“HDT”却被漏标。
(3)标引效率问题
标引过程持续的时间较长,近9个小时,其原因主要有:
①控制词表规模较大,且超过10个字符的控制词占到控制词表的一半以上。
②由于在标引时没有区分中英文控制词和中英文文献,造成大量的无效匹配。
③算法和编程工具问题。出于编程简单考虑,本系统采用暴力算法,利用PHP编写标引程序对数据库直接操作,影响处理速度。
乙肝文摘数据库蛋白质信息标引结果的召回率为97.37%,尚可接受,但标引精度只有88.54%,远达不到系统的实用要求,需要进行改进。
改进的总体思路:运用控制论原理,在标引前和标引中两个环节设置改进方案,消除系统性错误;特别增加反馈控制环节,最大限度减少偶然性错误。通过在标引的“前-中-后”三个环节设立全面的标引控制体系,提高标引准确性。
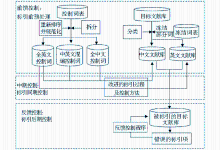
具体实施过程如图 3 所示:
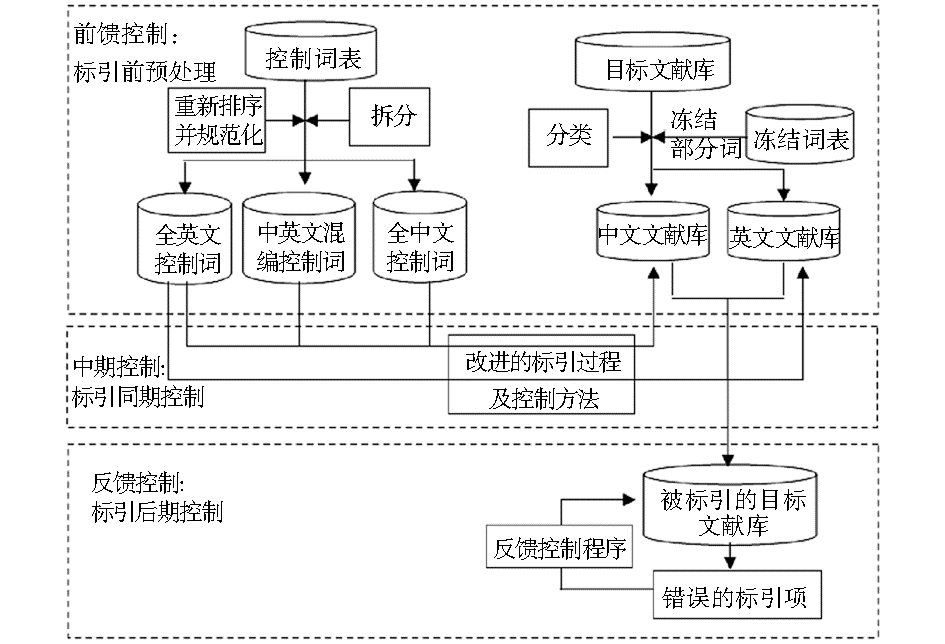 | 图3 改进后的标引过程控制系统 |
(1)前馈控制
在标引工作开始前,笔者对控制词表和目标文献库分别进行了预处理。
①对控制词表进行预处理
1)将本来为中英文混合在一起的控制词表拆分为三个表,即中文控制词表、英文控制词表和中英文混编控制词表。中文控制词表收录全为中文字符组成的控制词,英文控制词表收录全为英文字符及希腊文和阿拉伯数字组成的控制词,其余的全部归入中英文混编控制词表。
2)将一些不规范的控制词进行规范化处理,并适当增加了由不同连接符连接的同义词。
3)将三个控制词表均按照控制词的字符数进行降序排列,防止出现部分匹配的错误。
②对乙肝专题文献知识库进行了预处理
1)对文献中的不规范的书写进行规范化处理,如对全角英文、全角数字等做了纠正。在早期文献中,全角英文和全角数字等错误较多,主要原因是早期的中文输入系统在中文状态下只能输入全角字符,从而造成英文字母和数字书写不规范;后来,中文输入法进行了改进,因此,在近些年的文献中,这种错误较少。
2)将乙肝专题文献知识库拆分为中文文献库和英文文献库,以便分别进行处理。
③设立了冻结词表。由于英文的单词部分标记现象特别明显,而中文则基本未见部分标记,因此,只设立了英文冻结词表,将一些常用英文单词设为冻结词,并将文献中的这些词做冻结标记。
(2)中期控制
中期控制主要是改进算法和采用Hash表:
①针对中英文文本特点,改进模式匹配算法,新算法用类自然语言表示如下:
1)开始,i=1,j=1,k=1,q=0,L=控制词表的总记录条数
2)提取控制词表中第i条记录,计算其长度为n
3)读取控制词表所有长度为n的控制词,共mk个记录,建立临时表Temp_Table_n
4)选取目标文献第j条记录
5)读取第j条记录的第1个字符
6)顺次读取后n个字符,如遇冻结词标志则放弃,跳过该冻结词,从冻结词结束标志处重新开始读取;如遇断句、段落标志,也放弃,从标志后开始重新读取
7)将读到的长度为n的字符与临时表Temp_Table_n中的控制词一一匹配,如匹配成功,则进入步骤8)
8)检查目标字符串的字符类型,如为全英文和数字,则判断字符串头的前一个字符和字符串尾的后一个字符是否为空格、中文、冻结词标志或标点符号,如是,则匹配成功;如字符串中至少有一个中文字符,则无需判断,直接匹配成功。否则,匹配不成功
9)读取当前字符串尾的后一个非空、非标点符号和非冻结词标志字符,返回步骤6)重新开始
10)j=j+1,返回步骤4)重新开始
11)所有长度为n的控制词对目标文献的匹配结束,释放临时表Temp_Table_n
12)q=q+ mk,i= q+1,n=0,j=1,k=k+1,返回步骤2)重新开始
13)所有控制词对所有目标文献的标引完成,结束
②采用C++编写算法程序,将目标文献和控制词表分别取出建立哈希表,让两个哈希表进行匹配,加快匹配速度。
(3)反馈控制
前馈控制和中期控制无法杜绝所有标引错误的产生,因此,本文设计了反馈控制系统。反馈控制由错误发现和纠错两部分组成。本文随机抽取20%的标引结果,即400条记录进行逐一检查,如发现标引错误,则将该错误的情况反馈给反馈控制系统,通过查错程序找出乙肝专题文献知识库中所有类似错误,并通过程序自动改正。
为了提高效率,将控制词表和目标文献进行有区别的匹配:英文文献只由英文控制词表匹配;中文文献由三个控制词表分别匹配,顺序为英文-中英文混编-中文。这样排序的原因在于:中文文献中的英文控制词多为专有名词,数量不多,可以先处理;中英文混编次之,因为中英文混编的控制词中的中文部分往往其本身也是控制词,如“X蛋白”;最后再对全中文的控制词进行标引。
采用新的标引方法对上文选取的2 000条记录进行重新标引,共有标引项8 303个,其中误标241个,另有43个漏标,得出:
标引精度=(8303-241)/8303×100%=97.10%
召回率=(8303-241)/(8303-241+43)×100%=99.47%
数据显示,综合运用“前馈”、“中期”和“反馈”三种方法,基本消除了标引的系统性错误,标引精度由88.54%提高到97.10%,召回率也由97.37%提高到99.47%。
虽然在标引中期控制时增加了许多判断,但是,由于在标引开始前进行了控制词表和目标文献的分类,采用Hash表预先将控制词和目标文本存储于系统内存,并采用C++进行处理,因此,标引的效率非但没有下降,反而有了明显提高。整个标引过程只持续了约2个小时。标引方法改进前后的比较如表1所示:
| 表1 标引方法改进前后的参数比较 |
本文参考控制论原理,设计了一种旨在提高中英文混编文本赋词标引准确性的综合控制方法。该方法对中英文不同的语法结构和行文规范既进行了明确的区分,又进行了有机的整合,在对中英文混编文本进行自动赋词标引的前、中、后期都进行了控制,从而将标引准确率提升到令人满意的水平。这种标引控制方法具有一定的通用性,具有较为广泛的应用价值。
本文设计的标引控制系统虽然较为全面,但也比较复杂繁琐;整个标引控制过程仍需要大量的人工介入;为了便于实现,采用了简单的暴力算法,在一定程度上降低了标引的效率。因此,在如何同时提高信息标引准确率与效率方面,还有待进一步研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|