



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
个性化新书通报推荐系统的设计与实现
[李高虎1  , 高嵩
, 高嵩1 , 唐小新2 , 曹红兵2 , 唐秋鸿3, 4 ]
, 高嵩|
|


基于图书馆业务系统中的借阅日志,构建数据仓储,采用SPSS数据挖掘中的聚类分析方法,挖掘读者与新书之间的分类相关度模式,通过个性化新书通报分类结果集,推荐读者感兴趣的新书。以笔者所在高校图书馆MELINETSⅡ系统中的读者借阅日志为例,设计并实现个性化新书通报推荐系统。
Based on circulation logs of library automation systems, the paper builds a data warehouse using the method of cluster analysis in SPSS data mining tools, and mines the classification modes between readers and books. By the classification result sets of new books personalized recommendations, new books are recommended to readers who are interested in. The paper also takes MELINETS II as an example, designs and achieves the application of the personalized recommendation system.
个性化服务是近几年兴起并被大家关注的新领域,其研究的主要目标是通过一定的信息技术,从现有的日志中,挖掘各种关联来进行个性化推荐[ 1]。新书通报是图书馆非常重要的一个功能,每个自动化系统都有这个功能,但都是在检索系统中统一发布。图书馆每天都有大量新书入库,如何让读者从大量的新书中找到自己感兴趣的图书、提升图书馆主动服务水平、提高读者对图书馆的利用率是个性化新书通报要解决的问题。
新书通报是指图书馆经过一段时间编目处理后可以流通的新书目录,一般按批次发布。新书通报在OPAC系统里都有显示。笔者调查了几所著名高校图书馆的公共检索系统的新书通报,基本都是按最近入库时间与分类进行发布,一般缺省最近一周[ 2]或一个月[ 3]入库的新书;同时可以分类浏览,一般是按学科进行分类浏览[ 4],也有按中图法26大类进行分类浏览[ 5]。国内主要OPAC系统新书通报基本都可以归为以上4类,都是针对新书进行分类分组,没有与读者关联。优点是读者无需登录即可查看新书通报,但缺点也很明显,所有人看到的新书通报都一样,没有任何区分,基本没有与借还日志关联的个性化新书通报。
个性化新书通报推荐是指通过读者类型和读者借阅日志等相关特征的属性来聚类读者感兴趣的图书分类,再依据读者感兴趣的分类与新书通报的分类进行匹配关联,进而向读者推荐同类型读者喜欢的新书。目前个性化推荐相关研究已经成为热点,利用个性化定制技术[ 6] 、RSS技术[ 7]、数据挖掘技术[ 8]等进行各种个性化推荐的应用研究,不断推动着个性化服务的发展和创新。然而,基于个性化新书通报的研究和实践较少,笔者从个性化新书通报的实际需求出发,基于K-means算法[ 9],采用SPSS数据挖掘工具,利用读者类型和图书分类的聚类属性,设计和实现了基于读者借阅日志的个性化新书通报。同时在聚类过程中采用二次聚类方法,得到不同层次分类结果集,以满足个性化推荐对图书分类详细程度的不同需要。
笔者对国内比较流行的OPAC系统新书通报发布功能进行分析,发现基本都是浏览式检索,而且新书通报数量较大,读者无法直接浏览查看自己最感兴趣的新书。因此,改变图书馆新书通报服务方式,提供个性化新书通报推荐很有必要。笔者从新书分类属性和读者借阅日志的图书分类属性入手,采用二次聚类方法,将新书与读者借阅兴趣自动关联,形成个性化新书通报,读者可以直接浏览自己最感兴趣的新书通报。本文设计的个性化新书通报推荐系统是建立在北京邮电大学图书馆信息管理系统MELINETS II的基础上,由MELINETS II系统提供接口,并分析读者借阅日志的行为数据,进而建立模型,挖掘出读者借阅个性化图书分类属性,同时根据新书通报目录,提供新书图书分类,根据读者借阅个性化图书分类属性,当有新书入馆的时候,会自动进行推荐,读者可以在“我的图书馆”查看,系统也可以进行邮件发送和短信推送[ 10]。
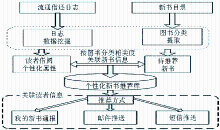
个性化新书通报推荐系统主要由流通借还日志采集、新书目录采集、日志数据挖掘、新书图书相关属性提取等功能模块构成,并根据读者借阅日志挖掘出图书属性,与待推荐的新书图书属性进行相关度关联处理,形成个性化新书推荐库。系统设计框架如图1所示:
 | 图1 个性化新书推荐设计框架 |
由图1可知,数据挖掘是实现个性化推荐的关键技术之一。数据挖掘的方法有很多种,本文主要采用聚类的方法对读者借阅日志进行挖掘。数据挖掘流程通常分为三个阶段,即数据准备、数据挖掘和数据应用验证。数据准备阶段包含数据选择获取、读者类型和图书分类的关联、关联数据的分类和排序;数据挖掘采用基于K-means算法的聚类分析方法。数据挖掘具体流程为:
(1)准备阶段:首先从MELINETS II数据库中选择图书信息和借阅日志,然后按读者类型对日志进行分组,关联图书分类,得到各种读者类型的图书分类借阅日志,再对该分类借阅日志按分类进行分组,得到不同分类借阅排行;
(2)数据挖掘阶段:通过K-means算法对分类日志进行聚类分析;
(3)数据应用验证阶段:通过分类分析、合并处理,获得个性化新书通报的分类[ 11]。
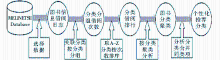
读者借阅日志的数据挖掘流程如图2所示:
 | 图2 读者借阅日志的数据挖掘流程 |
由图2可知,数据源来自MELINETSⅡ数据库,通过对MAIN_BIBLI书目信息、READR_TYPE读者类型、CIRCULLOG_A借阅日志表的关联,形成CIRCUL_LOG_CLASS_A数据库表,其中主要字段有读者类型、分类、借阅次数等。有关创建表语句和生成数据语句为:
CREATE TABLE "CUSLIB"."CIRCUL_LOG_CLASS_A" ("READER_TYPE" VARCHAR2(40) NOT NULL ,"CLASS_NO" VARCHAR2(40) NOT NULL, "CIRCUL_NUM" NUMBER(10) DEFAULT 0 NOT NULL) TABLESPACE "USERS" //创建数据库表
CIRCUL_LOG_CLASS_A;
生成数据库表CIRCUL_LOG_CLASS_A数据语句,从MAIN_BIBLI提取分类,从READER_TYPE提取读者类型,从CIRCULLOG_A提取借阅次数。本文为CIRCUL_LOG_CLASS_A提取CIRCULLOG_A流通日志的时间是2009-01-01至2011-01-20。
INSERT INTO "CUSLIB"."CIRCULOG_CLASSNO_A" ( “READER_TYPE”, "CLASS_NO", "CIRCUL_NUM" ) SELECT
"CUSLIB"."READER_TYPE"."READER_TYPENAME", "CUSLIB"."MAIN_BIBLI"."CLASS_NO_1", COUNT(CUSLIB."CIRCULOG_A"."BOOK_BARCODE") FROM "CUSLIB"."CIRCULOG_A", "CUSLIB"."MAIN_BIBLI" WHERE ( "CUSLIB"."MAIN_BIBLI"."REC_CTRL_ID" = "CUSLIB"."CIRCULOG_A"."REC_CTRL_ID" ) AND (“CUSLIB”.”READER_TYPE”.”READRTYPE_ID”= “CUSLIB”.”CIRCULOG_A”.”READERTYPE_ID” ) AND ( substr("CUSLIB"."MAIN_BIBLI"."CLASS_NO_1",1,1) >='A' AND substr("CUSLIB"."MAIN_BIBLI"."CLASS_NO_1",1,1) <='Z') GROUP BY “CUSLIB”.”READER_TYPE”.”READRTYPE_ID”, "CUSLIB"."MAIN_BIBLI"."CLASS_NO_1"
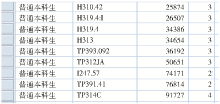
通过上述语句的处理,获得流通日志分类数据,经过清理选择汇总后的数据格式如图3所示[ 6]:
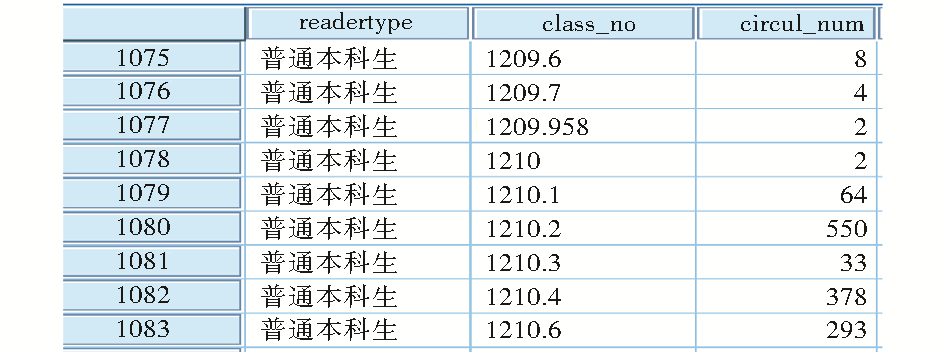 | 图3 CIRCUL_LOG_CLASS_A中的数据 |
其中,reader_type列是读者类型,class_no是分类,circul_num是借阅次数。
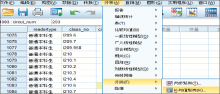
建立流通日志分类数据库后,进入数据挖掘阶段,图3给出了流通日志分类数据表的数据格式,采用SPSS数据挖掘工具对其进行数据挖掘,在挖掘过程中首先选定聚类分析方法,即“分析”菜单中选择“分类”,然后选定数据挖掘分析方法中的算法,即选择“K-均值聚类”,如图4所示:
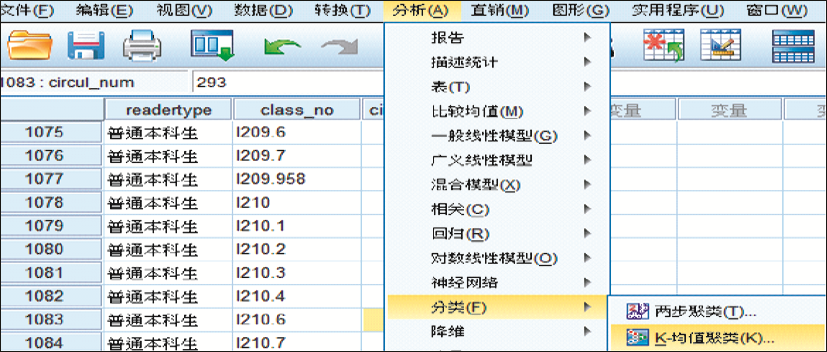 | 图4 SPSS分析方法和算法的选择 |
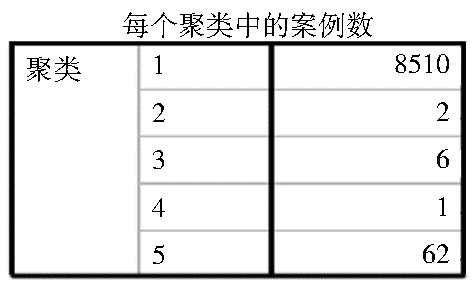
由图3和图4可知,选定聚类分析方法和K-means算法之后,加入聚类分析有关参数,如聚类数、聚类变量和聚类依据等。数据聚类数是聚类分析方法中的初始聚类中心的个数或最终聚类中心的个数,选取的聚类数为5;聚类变量是一组表示个体性质或特征的变量,聚类分析主要是根据借阅次数来进行分类,所以聚类变量选取借阅次数(CIRCUL_NUM);聚类依据选取分类(CLASS_NO),因为本文主要是通过借阅次数来聚类出借阅分类。通过数据聚类,可以得到的聚类结果如图5和图6所示:
 | 图5 聚类与借阅次数关系 |
 | 图6 聚类与分类关系 |
图5是得到的5种聚类结果编号和每个聚类中心值的借阅次数CIRCUL_NUM值,分别是1类为125,2类为75 493,3类是34 711,4类是91 727,5类是10 145;图6是聚类编号及其所对应的分类数。
综合图5和图6可知,主要聚类是中间的2、3、4类,其中聚类2所对应的两个分类是I247.57和TP391.41;聚类3所对应的6个分类分别是H310.42、H319.4:I、H319.4、H313、TP393.092、TP312JA;聚类4所对应的唯一分类是TP314C,如图7所示:
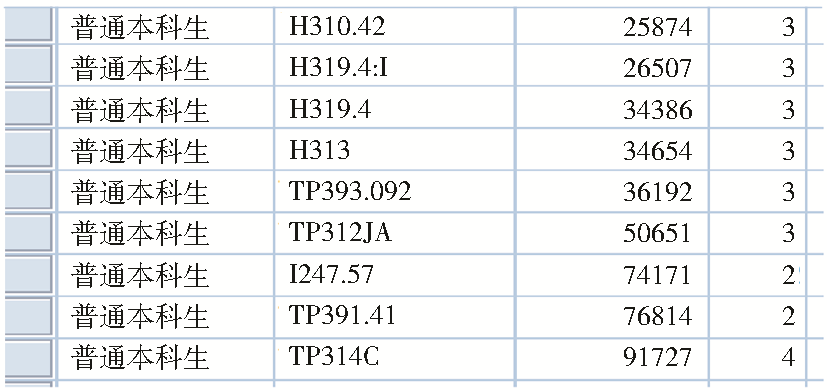 | 图7 聚类2,3,4对应分类 |
由图7可知,普通本科生聚类结果为I247.57、TP391.41、H310.42、H319.4:I、H319.4、H313、TP393.092、TP312JA、TP314C等9个分类,称之为聚类分类结果集1。在推荐过程中,考虑可用性和扩展性的需要,对部分聚类结果可截取前几位的分类,然后归类相同类别,如TP393.092和TP391.41可以归类TP39。需要指出的是,由于聚类1和聚类5对应分类太多,难以实现推荐出读者感兴趣的新书,如聚类1中就含有8 510个分类。为此可以进行再次聚类分析(本文采用截取分类的前4位),再次聚类结果为TN92、TP36、I267、TN91、TP31。最后通过合并相同分类,得到TN92、TP36、I267、TN91、TP31、H31、TP39等7个分类,称之为聚类分类结果集2。从应用实践来看,采用聚类1和聚类2相结合的方法符合学校专业特点。
根据聚类的应用实例及分析结果,设计并实现新书个性化推荐的流程(以本科生为例),如图8所示:
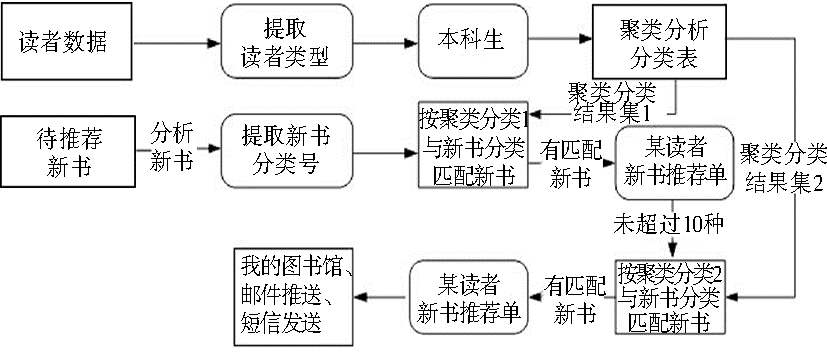 | 图8 新书推荐单数据流程 |
系统根据读者数据,获取读者类型和对应的聚类分类结果集;通过获取待推荐新书,分析新书分类属性,提取新书分类号。首先根据聚类分类结果集1,也就是详细分类进行推荐匹配,形成读者新书推荐单,如果没有推荐图书或者推荐图书过少(例如少于10种),则根据聚类结果集2与新书分类再次进行匹配,最终形成新书推荐单。
本文通过对读者借阅日志进行聚类分析,根据不同读者类型实行个性化的新书推荐,通过应用,获得比较好的新书推荐效果。在聚类分类中可以采用不同阈值进行聚类,以满足不同图书馆和读者的需求。应用同样的方法,也可以基于读者单位、读者专业等不同属性进行个性化推荐,甚至可以推广到针对每个读者的借阅日志进行个性化推荐。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|