
{kind=link}
一种通过文本挖掘发现实时定量聚合酶链式反应实验内参基因的方法研究*
引用本文
何琳, 何娟, 沈耕宇, 杨波, 黄水清. 一种通过文本挖掘发现实时定量聚合酶链式反应实验内参基因的方法研究* . 现代图书情报技术, 2012, 28(7): 109-114
He Lin, He Juan, Shen Gengyu, Yang Bo, Huang Shuiqing. An Approach to Discovery of Reference Control Gene for qRT-PCR Experiment Based on Texting Mining. 现代图书情报技术, 2012, 28(7): 109-114
Permissions
He Lin, He Juan, Shen Gengyu, Yang Bo, Huang Shuiqing. An Approach to Discovery of Reference Control Gene for qRT-PCR Experiment Based on Texting Mining. 现代图书情报技术, 2012, 28(7): 109-114
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
一种通过文本挖掘发现实时定量聚合酶链式反应实验内参基因的方法研究*
摘要
综合运用模式匹配、主题识别、信息抽取等多种信息处理技术,从基于文献的角度设计一种面向qRT-PCR实验的内参基因及实验环境的挖掘系统,为qRT-PCR实验提供有价值的内参基因推介参考,可以缩短内参基因筛选的时间,减少实验验证的成本,具有较高的识别正确率。初步的测试结果得到生物学领域专业人员的认可。
关键词:
实时定量聚合酶链式反应实验; 内参基因; 实验环境; 文本挖掘; 信息抽取
中图分类号:G25
An Approach to Discovery of Reference Control Gene for qRT-PCR Experiment Based on Texting Mining
Abstract
This paper presents a method for identifying candidate reference control gene based on text mining from PubMed database. It integrates several approaches such as pattern matching, subject recognition and information extraction to find candidate gene and its experiment environment for biology domain specialists. Experiment results show that the method not only has good performance on mining of candidate reference control gene and its environments, but also saves much time and reduces cost.
Keyword:
qRT-PCR; Reference control gene; Experiment environment; Text mining; Information extraction
1 引言
实时定量聚合酶链式反应实验(简称qRT-PCR实验)是一种新的核酸定量技术,具有定量准确、灵敏度高、重复性好、高通量等特点,它广泛应用于基因表达分析中。选择稳定的内参基因是qRT-PCR实验数据可用性的关键,然而选择合适的内参基因通常需要严格的生物实验加以验证,选择过程代价较大。文献作为科技成果展示形式具有很大的参考价值和使用价值。大量生物文献积累了关于内参基因选择的成果,设计一套行之有效的文献挖掘系统对相关文献进行分析,提取出各种实验环境下的内参基因,可以大大减少实验成本。本文从基于文献的视角设计出一种面向qRT-PCR实验内参基因挖掘模式和挖掘算法模型,能够对文献进行深度挖掘,从而为qRT-PCR实验提供有价值的推介参考,旨在对推动数据挖掘在面向特定生物实验应用方面提供一定的借鉴。
2 相关研究现状
内参基因必须根据实验情况具体选择,目前有关内参基因的选择除了利用领域经验之外,主要有基于基因芯片和EST数据库两种提取方法。
(1)基于基因表达芯片数据库发现内参基因
通过对大量的基因芯片数据进行分析,发现稳定表达的基因可以作为候选的内参基因。Czeochowski等[ 1]利用拟南芥全基因组芯片数据筛选出22个在不同发育时期、逆境胁迫、生物胁迫、激素、营养缺乏和不同光照下稳定表达的基因。Libault等[ 2]通过分析大豆已发表的基因芯片数据,发现了多达200个稳定性较好的基因,并对其中18个基因在不同发育时期、组织器官、逆境胁迫的130个样本进行了表达分析。
(2)基于EST数据库发现内参基因
EST数据库和cDNA文库相结合在内参基因选择方面也有很好应用[ 3]。Faccioli等[ 4]建立了一套从大麦EST数据库筛选新的内参基因的方法,从cDNA文库中寻找出现频率较高的EST序列,然后再结合不同实验条件筛选出一批稳定性好的内参基因。Coker等[ 5]统计分析了番茄EST数据库中127个基因在不同cDNA文库中的出现频率,最终得到5个稳定基因。借助EST数据库和cDNA文库筛选基因也是一个很好的途径,但是最后的结果仍然需要验证,主要原因还是因为筛选所依据的实验数据不是以筛选内参基因为目的的数据。
无论是在传统持家基因中选择内参基因,还是借助基因芯片数据选择内参基因以及借助EST数据库、cDNA文库选择内参基因,都脱离不了对候选内参基因的实验验证。作为生物实验尤其是PCR实验的重要要素,内参基因的选择问题必然以显式或隐式的方式大量存在于生物文献之中。利用信息抽取技术挖掘出存在于文献中的内参基因及其实验环境将会大大缩短内参基因筛选的时间、减少实验成本,同时可以保证筛选结果的正确性。
利用信息抽取技术从特定领域内进行信息获取已有不少相关的研究,典型的方法是模式匹配方法和机器学习方法等,如丁效等[ 6]从音乐领域中进行相关事件抽取,许旭阳等[ 7] 从新闻语料中进行突发事件元素的识别,郑家恒等[ 8]从农业领域中进行农作物品种的抽取,高文利[ 9]则从军事语料中进行军备情报的抽取等。虽然内参基因的抽取和上述研究相似,但仍存在以下的特点和差异:
①语义稀疏性:生物学文献中有关内参基因的选取的文字非常简洁,通常只有一句话,甚至仅以图表的文字说明形式存在;
②情境相关性:在一篇生物学文献中有时论述了几个不同的实验环境,所以要区分好每个实验描述文本的情境。
因此,基于文本的内参基因的挖掘需要针对生物文献的特点,综合多种技术来进行识别和挖掘。
本文的主要价值体现在两个方面:从生物学领域而言,有别于传统方法,提出了一种基于文献的方法进行内参基因的辅助推荐;从情报学领域而言,针对生物学文本的特点,设计并实现了内参基因的识别和发现方法。
3 总体设计
本文针对常规的qRT-PCR实验内参基因选择存在的问题,提出并设计了一套基于文献的内参基因挖掘系统,以期为qRT-PCR实验内参基因选择提供推介服务。综合考虑现有的信息抽取技术在不同领域的应用以及有关内参基因相关文本的特点,本文提出了一个融合模式抽取和机器学习的内参基因挖掘实验系统,该系统的体系结构如图1所示:
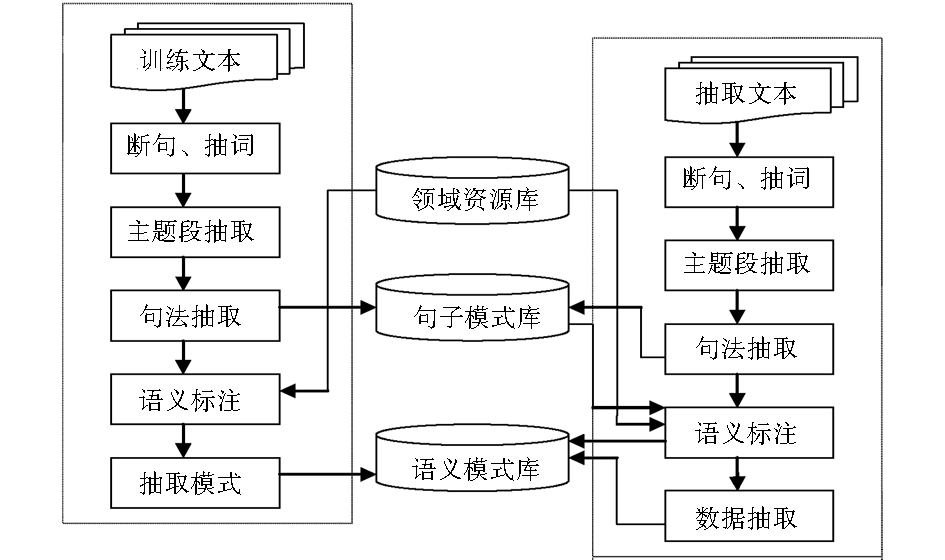 | 图1 面向qRT-PCR的内参基因抽取体系结构 |
(1)预处理:处理的文本主要是与基因相关的各类研究论文,主要为PDF和部分DOC格式文件,包括对文本进行格式转换、分词、词性标注、浅层句法分析等过程。由于处理的都是英文语料,所以利用现有的Stanford Parser[ 10]工具进行文本的预处理。
(2)主题段抽取:主题段落的抽取主要是把专门论述qRT-PCR实验细节的段落有针对性地抽取出来,减少信息抽取的工作量。
(3)抽取模式构建:抽取模式的构建主要是把内参基因、qRT-PCR实验对象以及反应条件所在句子的描述方式以及进一步的语义模式在训练的时候提取出来为信息抽取提供参照模板。
(4)相关元素抽取:成功抽取目标句子之后,利用命名实体识别以及正则表达式等策略把具体的模板元素抽取出来并填充到抽取模板中。
4 关键技术
4.1 领域资源库构建
(1)物种-基因领域词典
关于基因名称的写法,文本中存在多种格式,有些采用拉丁名称,有些则采用化学式的形式来描述。基因名称识别的正确与否是关系到内参基因能否被正确挖掘的直观因素。考虑到识别的正确率和工作量,本文利用GO本体[ 11]构建物种-基因领域词典。对GO文件进行解析,提取出物种-基因-同义词名称等概念关系存入词典。
(2)化学试剂名称库
包括各种分离试剂、酶和辅酶、培养基、缓冲试剂、染色剂、抗生素、核酸及其衍生物、氨基酸及蛋白质产品等。化学试剂名称库可以辅助实验环境主题段的识别。
(3)实验耗材库
主要收集各种培养皿、离心管、移液器、滤纸、滤膜、细胞培养耗材等相关词汇,建立实验处理识别的特征词。
(4)触发特征词库
qRT-PCR实验的操作都是由一些特殊的触发词引发的,例如“合成、扩增、拼接、退火、循环”等。本文根据训练数据的标注结果,从中抽取出能够引发qRT-PCR实验的一系列操作的特征触发词存入特征库中,为qRT-PCR各种实验条件的抽取提供依据。
4.2 主题段落划分
根据词共现模型理论,若某几个词经常在同一窗口单元中频繁共同出现,则它们在一定程度上能表达该类文档的语义信息,由此进一步构成作者表达的某个主题[ 12]。可见,这些词语属于一个共同的主题,因此逻辑上属于同一类别。通过对生物学相关文献的内容分析发现,含有qRT-PCR实验的研究论文有以下特征:
(1)qRT-PCR实验环境集中交代且基于一系列语义相关的特征词触发;
(2)同一篇文章中可能包含一个或多个qRT-PCR实验,且实验环境类似,仅数据不同。
为了能够有针对性地准确抽取不同qRT-PCR实验中的各自对应的实验条件,本文采用基于主题划分段落的方法先对文本进行处理,然后再进行模式抽取。对训练数据进行人工qRT-PCR实验环境主题段落划分,把划分出的主题段落进行关键词抽取,计算TF-IDF值,按照权值进行排序,设定阈值确定qRT-PCR实验环境的特征触发词。抽取实验环境的时候,以段落为单位构建段落向量与特征触发词向量进行相似度计算,从而确定qRT-PCR实验环境主题段落。
4.3 内参基因的挖掘
由于内参基因选取的句子相对有规律可循,因此本文利用了基于规则的方式进行内参基因的抽取。首先利用物种-基因领域词典结合命名实体识别技术识别出含有基因名称的句子,在句法抽取的基础上,标注出内参基因表示的触发动词,如校正、标准化、选定、选取、以…为等,在此基础上归纳句子模式,利用手工建立的抽取规则进一步筛选,以确定qRT-PCR实验所用的内参基因。利用训练数据构建的内参基因部分抽取规则如表1所示:
| 表1 内参基因抽取规则样例 |
4.4 qRT-PCR实验扩增对象的抽取
qRT-PCR实验扩增对象的抽取主要是抽取出实验快速扩增的特定基因(或DNA序列)。此特定基因(或DNA序列)的表达差异一定会在文本中以特定段落的文字进行分析,同时围绕该基因需要设计出相应的上下游引物,因此本文采取以下方法识别扩增对象:
(1)计算所有的基因名称(或DNA序列)在文本中出现的绝对频次F;
(2)对于F≥3的基因名称(或DNA序列)在划定的主题段落中搜索,若与“引物”的上下文距离不超过1个自然段落,则标注出其所在的句子;
(3)若句子中含有特定触发词,则为实验扩增对象,否则不是。特定触发词为“扩增、分析、Ct值、比对、重组”等与基因操作相关的特征词。
4.5 qRT-PCR反应条件的抽取
由于PCR实验是有固定步骤的,即含有某些固定的特征词,实验环境的抽取可以选用基于规则的模板抽取方式进行筛选。qRT-PCR反应条件的抽取模式为:
其中,triggerName是反应条件抽取的触发词,触发词根据训练文本的标注结果进行构建;AttributeList是指PCR反应条件中包含的系列反应参数;type是指抽取的参数的类型,如为实体或是数值;position是指抽取的内容位于触发词的相对位置。例如qRT-PCR产物检测方式的抽取模式为:<{产物|检测},{取}, {NS/Chemical},{1}>,其含义为产物检测方式的触发词为“产物或检测”,检测中含“取”,检测方式为化学名词,位于触发词的右侧。
5 实验
实验利用PubMed数据库中与水稻内参基因选取有关的共计558篇论文作为测试集。首先对PDF格式的论文进行解析,利用Stanford Parser进行分词、词性标注、句法分析等预处理,然后对文本进行主题域的划分,在划定了主题域后按照本文的流程进行内参基因相关模板元素(内参基因、PCR反应体系、循环参数及产物处理)的抽取实验。
5.1 抽取结果展示
(1)内参基因的抽取结果
内参基因的抽取利用句子模式匹配和正则表达式结合的方式进行抽取。部分抽取结果样例如下所示:
RUB2 is the ubiquitin gene, which is a reference for the amount of cDNA used for PCR.
The positions of 23- and 25-nucleotide (nt) RNAs are shown at left as a reference.
Gene expression level (arbitrary units) was normalized using actin (Os03g50890) as an internal reference.
(2)qRT-PCR扩增对象的抽取结果
qRT-PCR扩增对象的部分抽取结果如表2所示:
| 表2 qRT-PCR扩增对象的部分抽取结果 |
(3)qRT-PCR反应条件的抽取结果
qRT-PCR反应条件的抽取结果如表3所示:
| 表3 PCR反应条件抽取模板样例 |
5.2 抽取结果的评价
(1)数据测评
抽取结果的测评本文采用信息检索领域的正确率、召回率及F值进行衡量。其中,正确率为抽取出的正确信息数量占抽取出的信息总数;召回率为抽取出的正确信息数量占测试集中标注出的正确信息总数。qRT-PCR实验内参基因相关信息挖掘结果测评如表4所示:
| 表4 qRT-PCR实验内参基因相关信息挖掘结果测评 |
从测评的结果来看,本文设计的挖掘方法能较为准确地挖掘出有关qRT-PCR实验中涉及到的内参基因、扩增对象以及各实验条件,为生物学领域专业人员提供有益参考。分析抽取错误的数据,主要原因在于:
①基因表达名称的混乱书写方式。基因名称的表达存在多种方式,使得内参基因抽取的时候召回率下降,从而使得进一步的扩增条件和实验条件的识别受到影响。
②格式转化中带来的数据丢失。由于处理的文本多以PDF格式存在,转化为文本格式的时候,许多度量单位、化学试剂等识别错误给抽取工作带来了很大的干扰。
(2)实证评价
目前,在生物学领域,qRT-PCR实验中内参基因的选取,虽然有基于基因芯片和EST数据库挖掘内参基因的方法,但受到数据的限制这种方法具有偶然性,因此基本还是采用基于经验的方法,即研究者通常从大量的文献中找到选取某内参基因的论文作为依据。本文正是一种辅助方法将研究者从海量的文献查找中解放出来,将前人所用过的该物种的所有内参基因汇总,研究者在分析的基础上可大量减少生物实验的范围,因此抽取结果得到了生物学领域专家的认可。本文从PubMed数据库收录的研究论文中,共发现22种(使用频次大于3)水稻内参基因,比Jain等[ 13]比较的10种常用水稻内参基因种类要更加丰富,为研究者提供了更大的选择比对空间。水稻高频内参基因样例如表5所示:
| 表5 水稻高频内参基因样例 |
6 结语
本文尝试从基于文献的角度,综合运用多种技术从已报道文献中挖掘物种已使用过的内参基因,从分子生物学的角度来讲是一次方法的创新;从情报学的角度来看,是一次信息抽取与文本挖掘技术在新领域的应用。从系统的初步运行来看,挖掘结果得到了分子生物学领域部分专家的认可,为生物学专业人员进行内参基因的选择提供了有力的实证保障。然而从文本中挖掘的内参基因需要生物学家通过实验来进行验证,因为随着研究的不断深入和实验环境的改善,有些内参基因的稳定性受到了质疑,即便如此,本文构建的挖掘系统也在一定程度上把生物学专业人员从浩瀚的文献资源中解放出来,大大降低了实验验证的范围。从挖掘的精度来看,如何更加准确地分别识别出单文本中多个实验的实验环境是进一步需要完善的工作。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|