



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
AIMLBot智能机器人在实时虚拟参考咨询中的应用*
引用本文
李文江, 陈诗琴. AIMLBot智能机器人在实时虚拟参考咨询中的应用* . 现代图书情报技术, 2012, 28(7): 127-132
Li Wenjiang, Chen Shiqin. Application of AIMLBot Intelligent Robot in Real-time Virtual Reference Service. 现代图书情报技术, 2012, 28(7): 127-132
Permissions
Li Wenjiang, Chen Shiqin. Application of AIMLBot Intelligent Robot in Real-time Virtual Reference Service. 现代图书情报技术, 2012, 28(7): 127-132
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
AIMLBot智能机器人在实时虚拟参考咨询中的应用*
摘要
基于AIMLBot智能机器人软件,利用“海量智能分词”和Lucene.net对机器人的中文知识库进行分词和索引检索,运用《知网》对用户输入问句与知识库问句进行相似度计算,获取相似度最高的知识问句进行推理,从而实现机器人在图书馆实时虚拟参考咨询中的服务。
关键词:
实时虚拟参考咨询; AIMLBot; Lucene.net; 中文分词; 相似度计算
中图分类号:TP391.1
Application of AIMLBot Intelligent Robot in Real-time Virtual Reference Service
Abstract
Base on AIMLBot intelligent robot software, the massive intelligent segmentation and Lucene.net are used to implement word segmentation and index retrieval for Chinese knowledge base,while the questions similarity between the author submitting and from the knowledge base are computed by HowNet, which lead to a highest similarity question for reasoning. At last,robot in real-time virtual reference service of the library is implemented.
Keyword:
Real-time virtual reference service; AIMLBot; Lucene.net; Chinese word segmentation; Similarity computation
引言
虚拟参考咨询打破了传统参考咨询在时空上的局限性,使图书馆参考咨询工作产生质变。但虚拟参考咨询受图书馆人力资源限制,在有效服务时间、数量、质量上存在瓶颈。完善、深化实时虚拟参考咨询是提升参考咨询服务价值的一项重要工作。本文以图书馆聊天机器人为例,研究利用机器人实现实时虚拟参咨询的方法。
1 需求及技术思路
1.1 实时虚拟参考咨询服务现状及需求
实时虚拟参考咨询服务的开展得益于计算机和数字通信技术的发展,需要依托一定的网络平台。从现阶段图书馆使用的系统软件来看,主要有三类:
(1)图书馆专用系统。国外有QuestionPoint[ 1]和24/7 Reference[ 2]等,国内有国家科技图书文献中心[ 3]和CALIS
数字参考咨询软件CVRS[ 4]等。从使用情况来看,CVRS也仅限于在全国享有业务特长和地区影响力的图书馆,而真正惠及全国各高校图书馆还需较长的时间。
(2)免费即时通讯软件QQ、MSN等。免费即时通讯软件离不开参考馆员人工提供咨询服务。
(3)自主研发的软件。在自主研发的软件中有不少值得借鉴的经验,比如清华大学图书馆的虚拟咨询馆员“小图”[ 5],它将人工智能与虚拟参考服务相结合,把机器人作为虚拟参考咨询馆员。
目前,重庆文理学院图书馆的实时虚拟参考咨询服务开展得并不理想。从实时虚拟参考咨询服务方式来看,本校图书馆只采用即时通讯工具QQ在图书馆网站上提供咨询。该方式并不能完全满足咨询服务的需求。
2 机器人的设计
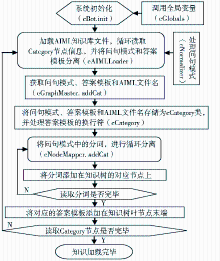
AIMLBot机器人在实时虚拟参考咨询中的实现过程如图1所示:
 | 图1 机器人聊天实现过程 |
主要分为三个过程:
(1)参考咨询知识库的建立过程。将图书馆参考咨询知识整理成包括知识问句和对应答案的数据,将问句和答案进行中文分词。这些知识数据按照AIMLBot知识库的规范[ 9, 10, 11]生成AIML知识库文件,再对其中的问句模式进行索引。
(2)咨询问句输入处理过程。将输入的问句进行中文分词,同时过滤停用词,获得输入问句的关键词。将这些关键词在索引文件中检索,获取检索结果的问句集合。再将输入问句与问句集合中每个问句进行相似度计算,并获取超过相似度阈值且阈值最高的问句。
(3)AIMLBot知识推理及答案输出过程。将获取的问句送入AIMLBot机器人中,进行问句规范化处理,与内存知识树中的问句模式进行匹配,寻找最佳匹配结果。找到后,读取对应的答案模板信息,模板中可能还包含进一步递推的AIML标记元素需要处理,继续在内存知识树中作推理,得到最终答案。
3 机器人的构建
本文以Microsoft Visual Studio 2008作为开发环境,在.NET 3.5框架下,采用VB.NET语言进行开发,并按照AIMLBot在实时虚拟参考咨询的实现过程,进行模块化设计,方便表现层对模块的调用。
3.1 AIMLBot在中文环境中的改进
(1)AIML知识库结构及改进
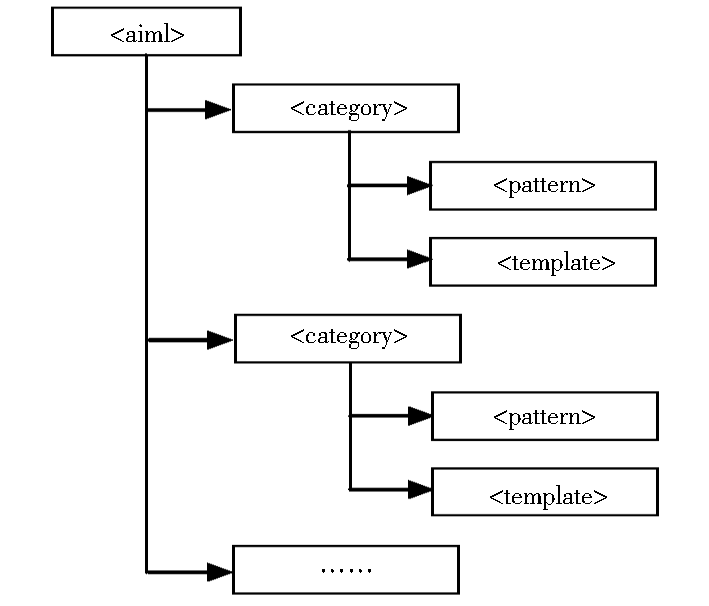
AIML是利用XML标准定义的一种服务于人工智能领域需要的特定语言。其基本结构如图2所示:
 | 图2 AIML知识库基本结构 |
AIML知识库基本结构由若干个知识单元分类
除了基本结构外,AIML还定义了许多模拟人类思维的重要标记[ 7], 使其具有语境分析、语义转换、判断分析、模糊查询、记忆思考等智能思维能力。
AIML知识库以词作为处理基本单位。在英语、法语、德语等语言中,词与词之间以空格作为分割标志,词的界限是明确的,偶尔出现一些单词缩写和特殊标点符号处理也比较简单。但在中文中,词与词之间没有明显的分割标志,因此,在中文中运用AIML则必须对AIML知识中的词进行分割,作中文分词处理[ 8]。
在建立AIML汉语知识库时,AIML文件的字符编码必须采用UTF-8或GB2312编码方式。同时,为了利用AIML智能思维能力,在添加知识的时候,需加入对应的标记字符,在对知识分词时,需要对其中的标记字符作保护处理,防止被分词工具拆分,避免推理机无法识别标记字符。
(2)AIMLBot推理机及改进
本文选择基于.NET框架开源软件AIMLBot,版本号为2.4.1。AIMLBot共有11个类,它们主要完成知识库的加载过程(见图3)和用户输入问句的推理过程(见图4)。
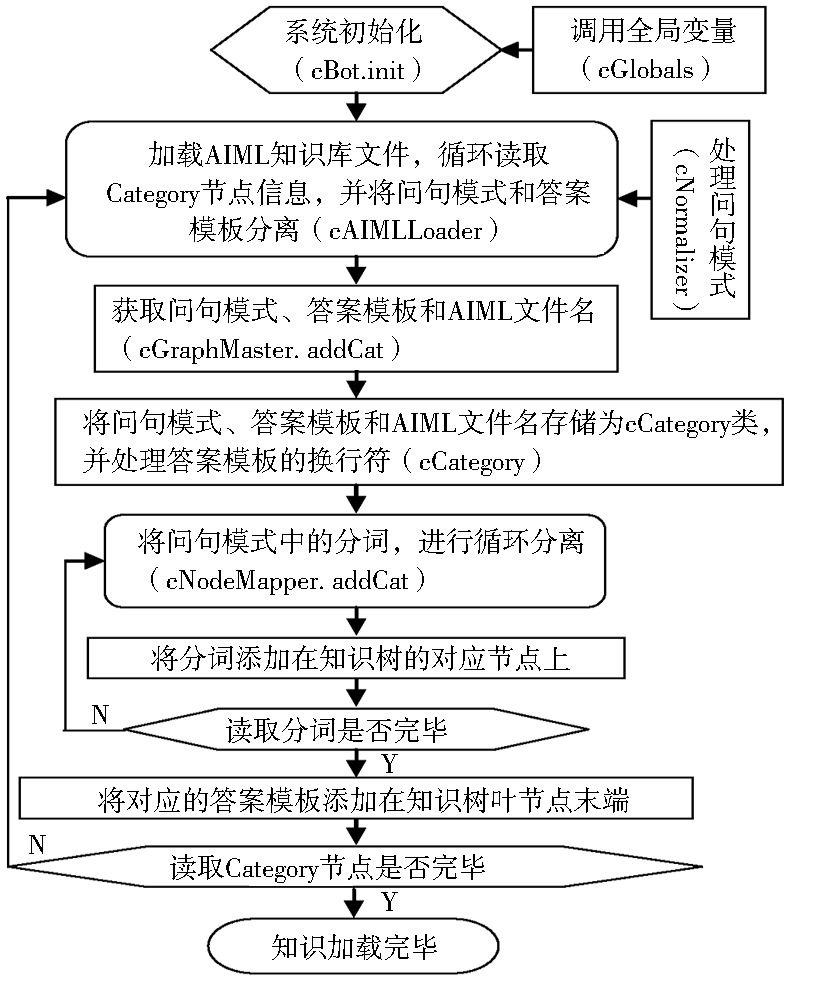 | 图3 AIMLBot初始化加载知识过程 |
 | 图4 AIMLBot知识推理过程 |
在加载AIML知识库和用户处理输入问句时,cNormalizer类的patternfit方法会过滤A-Z、a-z、0-9和空格对应的ASCII编码值范围以外的所有字符。在中文环境下,则需要修改该方法,在原有过滤条件上,增加中文字符对应的UTF-8编码值起止范围[4E00-9FA5](16进制),则可以使中文字符不再被过滤。
(3)AIMLBot问句输入方式改进
AIMLBot推理过程是一个允许有通配符(“*”,“_”)的严格匹配过程,相对于语序比较自由、虚词运用较多的中文来说并不合适,必须要进行改进。本文采用的方式是用户输入问句与知识库问句进行相似度计算,最终选择与输入问句相似度最高的知识库问句,作为推理机的输入信息。
具体而言,在AIML知识库中,提取问句模式内容,并建立索引文件。当用户输入问句后,对问句进行分词处理,提取其中关键词,同时对关键词作同义词扩展处理,形成用户输入问句扩展集合。将问句扩展集合在索引文件中循环检索,得到检索结果问句集合。再将用户输入问句与检索结果问句集合中每个索引问句,进行循环相似度计算,获取超过相似度阈值且阈值最高的索引问句,然后将获取的问句结果送入推理机进行递归匹配。整个处理流程如图5所示:
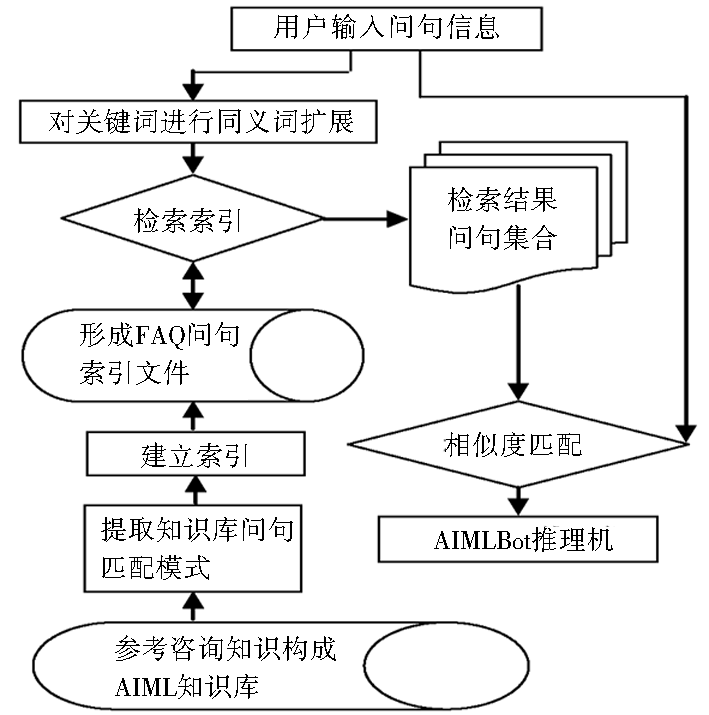 | 图5 问句输入处理流程 |
3.2 关键技术的实现
(1)中文分词工具
对多种开源分词程序进行分词实验,最终选择“海量智能分词研究版”[ 12]作为分词工具。工具包括HLSplitWord.dat词典文件、HLSSplit.dll分词组件和HLSSplit.lib库文件。HLSSplit.dll在.NET项目中不能直接引用,需利用DllImport属性类调用它,导出分词组件原有接口,重新构建HLSSplit类。
调用HLSSplit类的分词接口,建立分词方法,该方法有两个输入参数:输入字符串参数(input_str)和分词分割标记类型参数(fg_fag),返回分词后的字符串。其中fg_fag取值范围为0-2:
① “0”表示分词间用“ ”分割,在建立AIML知识库和用户输入问句时使用;
② “1”表示分词间用“|”分割,在AIML问句模式索引和检索时使用;
③ “2”表示分词间用“|+分词词性”分割,在利用《知网》[ 13]进行相似度计算时使用。
海量分词的词性标注集与《知网》的词性标注集不一致,所以需要按照表1把海量分词的词性标记符号转换为《知网》词性标记符号。
新建一个用户自定义词典,将
| 表1 海量分词与《知网》词性标记符号对应关系 |
(2)问句索引与检索
利用开源Lucene.net 2.9.2[ 14]索引检索工具和海量分词,建立中文分析器。分析器中建立三个继承Lucene.net的类[ 15],如表2所示:
| 表2 继承Lucene.net的三个 |
①索 引
为Document建立唯一个Field域,并命名为pattern_Node。该域需要进行分词、索引,并存储其内容。
从AIML知识库中循环读取问句模式
②检 索
在检索前,需要对用户输入的问句进行分词与词性标注处理;利用哈尔滨工业大学的《同义词林扩展版》[ 16]进行关键词的同义词查询,获取同义词候选集;利用《知网》计算关键词与同义词之间的相似度,选择相似度较高的词语,作为关键词的同义词扩展集[ 17]。
同义词扩展处理后的问句,经过QueryParser查询分析器分词处理,形成词流,再经过滤处理(如过滤停用词、进行大小写转换等),最终由IndexSearcher对象完成其搜索。搜索结果以TopScoreDocCollector对象返回,并按照默认相似度由高到低进行排列[ 18]。
(3)问句相似度计算
基于《知网》进行的问句语义相似度计算的整个过程分为两部分进行:句子中的词语相似度计算,实现方法主要参考文献[19]进行;句子间的相似度计算,实现方法主要参考文献[20]进行。将整个相似度计算过程,建立为一个类, 如表3所示:
| 表3 相似度计算方法类异 |
具体词与义原的相似度一律处理为一个比较小的常数(γ=0.2);具体词和具体词的相似度,如果两个词相同,则为1,否则为0;将任何义原(或具体词)与空值的相似度定义为一个比较小的常数(δ=0.2)。
4 应用效果
本校图书馆实现了基于AIMLBot实时虚拟参考咨询服务机器人化,提供了计算机Web版和手机WAP 2.0版两种方式。
目前,知识库中已收集了约2 000条知识,包括图书馆的常见问题(FAQ)、基本概况、书刊借阅流程、公共目录查询方法、电子信息服务、科技查新、馆际互借等相关知识。知识加入方式有两种:批量导入整理后的问题和答案生成AIML知识库;日常零星知识的逐条增加。这两种方式结合逐步丰富完善知识库,满足用户的日常需要。
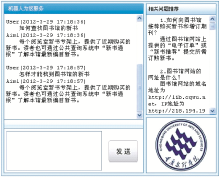
机器人的计算机Web版界面如图6所示:
 | 图6 聊天机器人 |
该界面仿照常用聊天工具的布局,更符合用户的常规操作习惯。界面上还提供一个相关问题推荐栏,根据用户输入问题中的关键字,检索出与之相关的问题,再根据相关度的高低倒序排列,这样既可以促使用户再次明确问题,加强提问的针对性,同时也可以展开类似问题,使用户的潜在问题也能得到满足,提高服务效率。
5 结语
虚拟参考咨询机器人为虚拟参考咨询服务提供了一种有效的实现方式。其全天候、个性化、快响应的服务表现改变了图书馆虚拟参考咨询长期低迷的服务状态。但虚拟参考咨询机器人在实际使用过程中也存在一些不足,仍需进一步改进,主要表现在两个方面:
(1)机器人的知识不够丰富,聊天内容也局限于图书馆相关问题,缺乏聊天乐趣。目前尚未发现大规模的免费AIML中文知识库,若单凭个人的力量很难建立一个丰富的中文知识库。针对这一问题,一方面需要已有的、成熟的中文知识库能提供开放获取;另一方面,需要提高机器人的“学习能力”,让用户对机器人进行“培训”,参与知识库的建设。
(2)机器人还不够“聪明”,偶尔会出现答非所问的情况。这需要对用户输入问题的处理方式进行改进,如同义词处理、中文句式变换和句子相似度计算等。
此外,对于该图书馆虚拟参考咨询机器人的完善,还需加入图书馆藏书书目和电子期刊检索结果的推送。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|