{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向知识发现的SKE关键技术及服务*
引用本文
宋文, 黄金霞, 刘毅, 汤怡洁. 面向知识发现的SKE关键技术及服务* . 现代图书情报技术, 2012, 28(7): 13-18
Song Wen, Huang Jinxia, Liu Yi, Tang Yijie. SKE Key Technologies and Services for Knowledge Discovery. 现代图书情报技术, 2012, 28(7): 13-18
Permissions
Song Wen, Huang Jinxia, Liu Yi, Tang Yijie. SKE Key Technologies and Services for Knowledge Discovery. 现代图书情报技术, 2012, 28(7): 13-18
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
面向知识发现的SKE关键技术及服务*
摘要
专业领域知识环境(SKE)工具支持用户建设嵌入科研工作流的知识环境和学术社区,是基于科研本体和主题本体的知识组织模型,应用语义网技术,结合推理规则的开发,实现特定学科领域内综合科技信息的管理、组织和知识发现,同时在本体、系统管理、数据内容上实现用户个性化定制。目前该工具在中国科学院范围被用来建设XKE平台,主要应用在领域知识环境建设、群组知识平台建设、项目信息环境建设、重大科研团体协作研究平台的建设中。
关键词:
知识发现; 知识管理; 专业领域知识环境; 本体
中图分类号:TP391
SKE Key Technologies and Services for Knowledge Discovery
Abstract
Subject Knowledge Environment(SKE) is a tool to build the knowledge environments and academic communities embedded in the user scientific workflows. Based on a research Ontology and a domain Ontology as the knowledge organization models, and the application on semantic Web technologies and reasoning rules, SKE has the functionalities on information management, knowledge organization and knowledge discovery, while realizes the user customizations on Ontology reusing, system management and data reusing. SKE is currently in the services on building the XKEs, mainly used in the constructions of specific subject knowledge environment, research community, project information environment and collaborative research platform of major research groups.
Keyword:
Knowledge discovery; Knowledge management; ubject knowledge environment; Ontology
1 引言
科学研究的信息环境和科研用户的信息行为正在发生巨大的变化。一个按照科研生命周期、充分支持各类数字化信息对象、支持多种网络化知识组织与传播形态、支持知识的创造、交流、分析、组织、保存全过程的综合数字科研信息环境正在迅速发展,并日益成为科研本身的基础环境[ 1, 2]。
如何有效地组织管理科学数据、科技文献、设施、种质资源、过程、机构、人员、政策等复杂数字科研对象,如何揭示这些科研对象本身具有的复杂的内在联系,如何将这些科研对象的发布、组织、集成利用嵌入到科研过程,使科研信息的创造、发布和利用成为科研的有机组成部分。面对信息环境和用户需求的巨大变化与挑战,研究型图书馆正在突破固有的服务模式局限,融入科研活动,支持嵌入科研过程的各类数字对象的组织、关联、智能发现,为用户提供增值的知识服务。
当前快速发展的语义网技术[ 3]和关联数据技术[ 4],为图书馆的知识服务提供了技术平台。国外的一些研究型大学图书馆,例如康奈尔大学图书馆、哈佛大学图书馆等都开始建设基于强语义的知识组织体系-本体来建设科学家网络,如VIVO[ 5]和ProfilesRNS[ 6]。中国科学院国家科学图书馆为科研一线提供综合信息服务,启动了专业领域知识环境的建设(Subject Knowledge Environment, SKE)。本文将从知识环境的技术框架、知识组织模型、知识库建设、知识环境的机制等角度探讨面向用户的知识环境的关键技术。
2 SKE的目标和定位
SKE将面向科研一线,构建支持科研过程中各类科技信息资源管理与利用的专业领域知识环境平台,支持虚拟科研环境下综合科技信息的采集、发布、交流与共享,支持对领域综合科技信息资源一站式的集成发现和深度挖掘,支持对领域综合科技信息资源的快速便捷获取,提高科学研究的效率,促进科技创新。
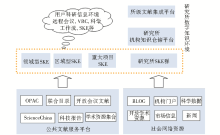
SKE一方面与远程会议系统、科学数据管理系统、科学工作流系统等共同构成科研用户信息平台,支持科研过程中的信息采集、信息发布和信息交流;另一方面,通过集成和个性化定制数字图书馆公共文献服务体系资源,通过搜索、采集、遴选、集成社会网络中的相关资源,形成面向研究所、课题组、研究领域的个性化知识环境,与研究所文献集成平台、机构知识仓储共同构成了研究所
数字知识环境。其在数字图书馆中的定位如图1所示:
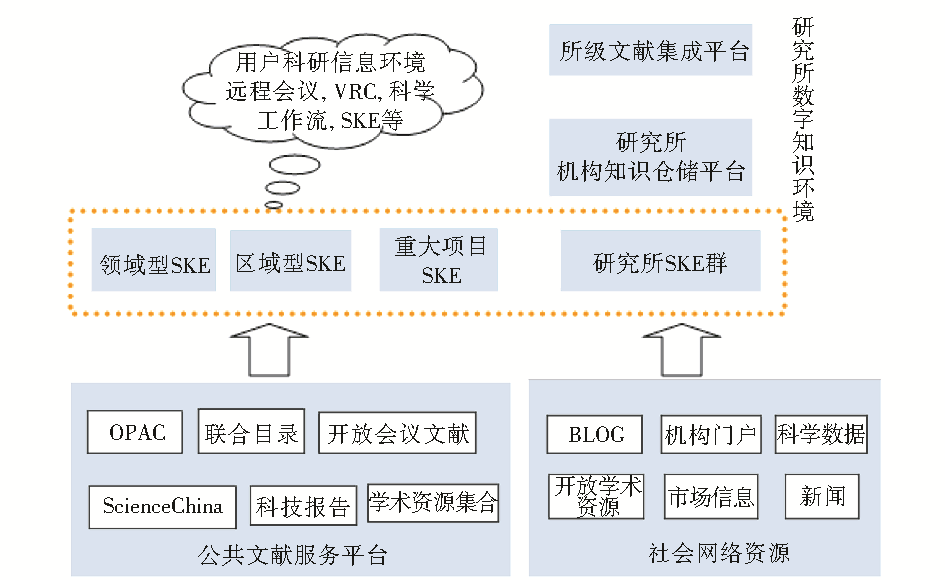 | 图1 SKE在数字图书馆模型中的定位 |
3 SKE的关键技术
3.1 基于VIVO的平台体系框架
VIVO是康奈尔大学、印第安纳大学、佛罗里达大学等联合开发的科学家网络,支持跨学科科学对象(人、机构等)的发现、交流和共享。VIVO系统采用语义网技术,基于本体和关联数据技术构建科研对象关系模型,VIVO系统支持科研本体构建、支持科研对象的创建、唯一标识和关联。
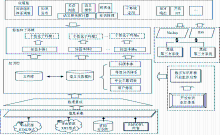
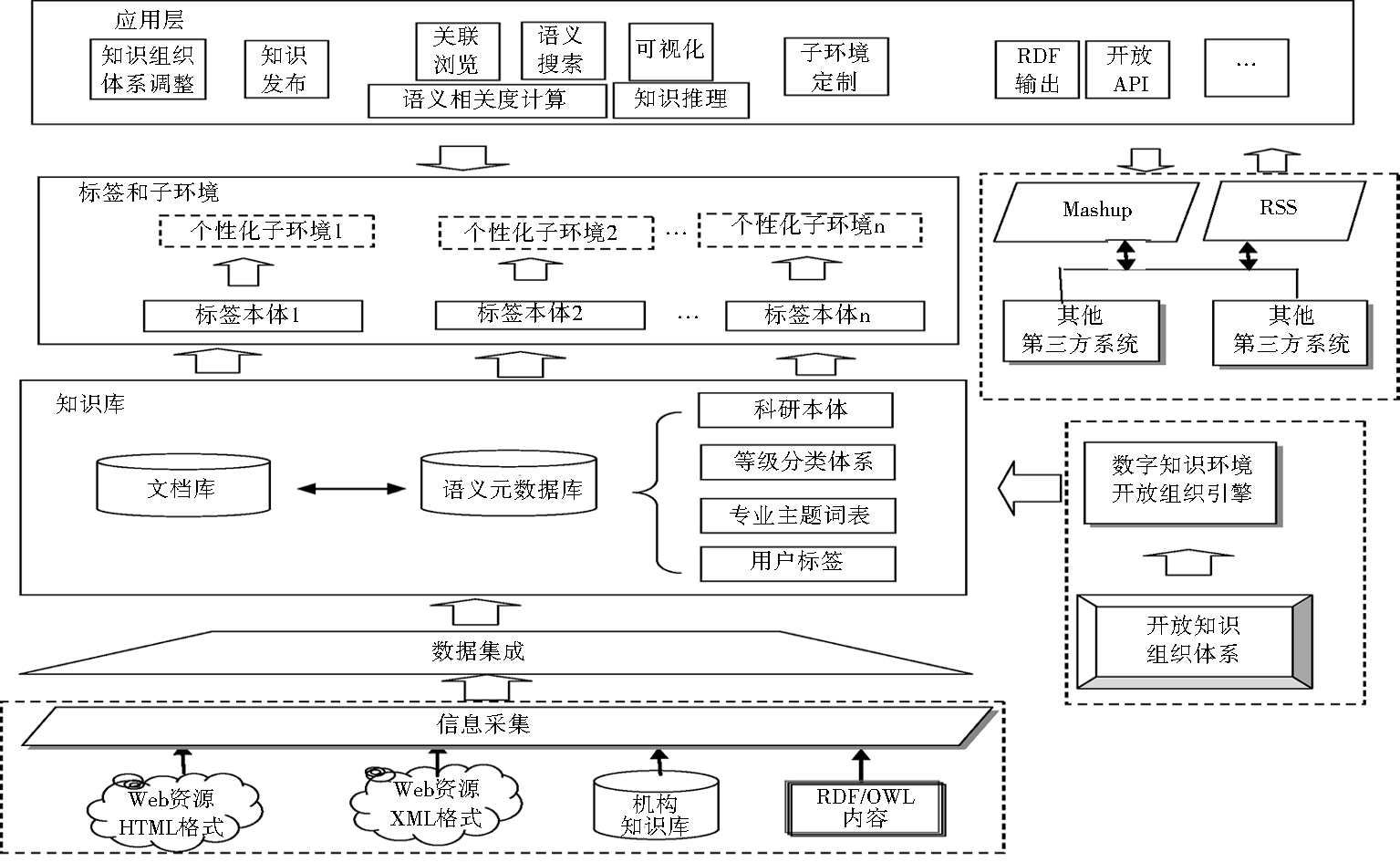
由于VIVO系统采用了当前主流的技术框架和标准,所以SKE平台选用VIVO平台作为原型系统,并根据中国科学院的环境和用户需求进行二次开发。SKE平台的体系框架如图2所示:
 | 图2 专业领域知识环境体系框架 |
SKE平台由以下模块组成:
(1)知识库:SKE平台的核心是知识库,知识库存储数字对象的元数据、相关文档和组织关联这些数字对象的知识组织体系,包括科研本体、学科分类体系、主题词表等。
(2)标签和子环境:SKE平台可以包含多个虚拟的个性化子环境,标签和子环境用于配置用户个性化知识环境,每个子环境有一个标签本体配置其个性化的环境样式。标签本体向下关联知识库中的本体和实例,向上成为个性化知识环境的结构化知识导航界面。通过标签本体,将知识库内容与个性化环境连接起来,实现了在一个SKE平台上,既具有统一的科研本体和集中存储的知识库,又有逻辑上分离的虚拟知识环境。
(3)应用层:基于Web浏览器的应用,提供用户通过浏览器按对象知识关系发现、浏览、创建知识对象。应用层也提供API接口供其他系统定制知识环境内容。
(4)开放组织引擎:开放组织引擎是外部的服务系统。SKE环境知识对象组织除了科研本体外,还引入了学科分类体系、叙词表、用户标签(关键词)来对资源的主题内容和特征进行揭示和组织。为此,在系统框架中考虑与开放知识组织引擎的接口,SKE平台可以动态调用开放知识组织引擎来对知识进行标引,也可以从开放知识组织引擎个性化定制知识组织体系到SKE平台中。
(5)数据集成:SKE平台设计有数据集成模块,通过数据集成工具来抽取和集成各种格式、各种类型的数字对象,按SKE的科研本体数据模型和描述元数据格式将对象元数据信息集成到SKE知识库中。
(6)第三方接口:SKE平台提供接口和工具与第三方系统进行交互。SKE的API接口供第三方系统定制、抽取SKE知识库数据,SKE平台也通过RSS和Mashup等技术动态集成第三方系统的信息。
上述的功能模块和各种应用工具和接口使得SKE系统成为一个可以组织多类型数字对象、开放和个性化的知识组织工具,提供科研人员方便灵活地应用这个平台来创建、发布、发现多类型科研信息。
3.2 知识环境的机制设计
知识环境是一个共享的、开放的信息交流和知识发现平台,同时又能满足科研团队内部的学术交流需要,在这样一个内外部交流并存、多种应用目标的需求驱动下,设计知识环境的机制并固化到系统中是非常重要的。SKE共设计了5类用户、3类对象、3类许可。5类用户包括平台管理员、本体管理员、子环境管理员、注册用户和公共用户,分别承担或有权负责SKE平台的管理、知识库中科研本体和主题本体的构建和演化管理、个性化知识环境的构建和子环境用户管理、子环境中发布信息,浏览子环境内部信息和阅读内部交流文档、访问公共阅读平台和各子环境公开的信息。3类对象指知识环境的资源对象,包括本体、实例和全文文档。3类许可包括阅读许可、更新许可、新增许可。
SKE平台通过对用户、对象、许可三个维度的组合配置,使得每个SKE应用可以设置符合个性化知识环境需求的服务和管理机制。例如:一个SKE应用可以设置一个实例允许被公共用户阅读;也可以限制在个性化社区,仅可被社区用户阅读;也可以设置一个实例允许注册用户修改,或只能由子环境管理员更新维护。
3.3 以本体为信息组织模型
SKE关键技术的核心是基于本体的体系架构。本体技术贯穿于SKE的体系框架、存储结构、内容管理、知识发布、知识组织、知识发现等全过程。
本体(Ontology)是共享概念模型的明确的形式化规范说明,近年来在知识工程、人工智能、语义网等领域得到了广泛关注,被应用于解决通信、异构环境互操作和系统工程中。目前在国内外数字图书馆建设和e-Science虚拟科研环境建设中,本体作为一种更加结构化的知识组织体系,在知识检索、信息抽取、知识发现等方面也得到广泛应用[ 7]。
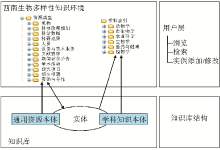
建设SKE信息组织模型,主要是利用本体的知识关联方式,为专业领域信息资源的组织和发现提供解决方案。SKE的科研本体描述了学科领域科研生命周期中所涉及到的综合科技信息资源类型,如人员、机构、项目、成果、科学数据、文献资源、仪器设备等,以及符合学科特点的领域知识组织方式。所以,SKE的科研本体从科研活动规律出发揭示对象及对象之间的关系,主题本体则揭示对象的学科主题特性,通过学科主题之间的关联模型,从主题内在关联关系角度揭示对象之间的关系。SKE两个本体在系统中的作用和彼此的关联[ 8]如图3所示:
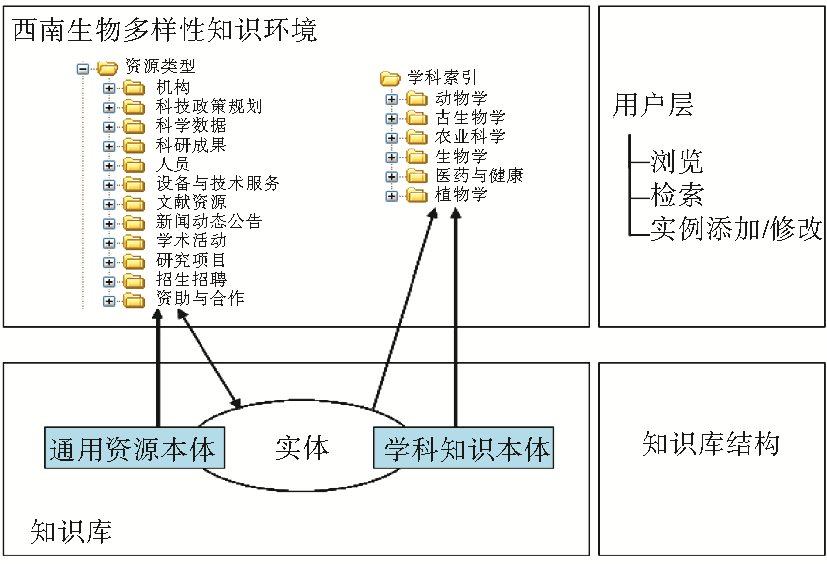 | 图3 SKE知识组织体系 |
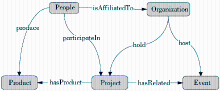
当前SKE中提供的科研本体共包括16个一级类,87个二级类,146个数值属性和120个对象属性。16个一级类为人员、研究机构、研究项目、学术活动、科研成果、科学数据、设备与工具、文献资源、科技政策与规划、资助与合作、招生招聘、新闻动态公告等。主要类目的关系如图4所示:
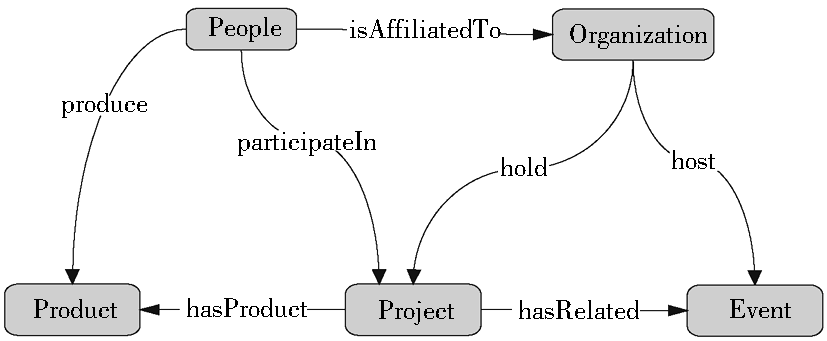 | 图4 科研本体模型 |
3.4 基于科研本体的推理设计
SKE平台实现了基于本体的知识推理和知识发现。本体的本质在于其公理系统和推理能力,能够从显性知识发现隐性知识。本文在SKE系统中对科研人员、科研机构、研究项目和学术活动等本体类的知识关系进行分析,设计关于这些类的近50条推理规则。例如关于科研人员的属性中,虽然没有科研人员参与哪些学术活动,哪些新闻报道与该科研人员有关,科研人员是哪些学术团体的成员等信息,但根据定义的推理规则,可以推导出知识库中并不实质存在的信息。用户在SKE环境浏览实例时,系统不仅显示实例描述中明确表达的信息,也显示自动推理的信息,发挥了本体的知识发现能力。
SKE系统用W3C的语义网规则描述语言(A Semantic Web Rule Language Combining OWL and RuleML, SWRL)[ 9]描述推理规则,通过标准的规则语言,实现对推理能力的管理和配置。例如:
(1)关于科研人员信息的推理
①IF T(?Event, ?hasReporter,?People),Then T(?People,?takePartIn, ?Event)
②IF T(?Organization, ?hasMemberOfScholarCommittee, ?People),THEN T(?People, ?isScholarMemberOf, ?Organization)
③IF T(?People, ?writerOf, ?Publication), (?Publication, publicationOfProject, ?Project), Then (?People, ?ParticipateIn, ?Project)
(2)关于科研机构信息的推理
①IF T(?Organizaiton1,?hasParentBody,?Organization2),THEN T(?Organization2,?childBody,?Organization1)
②IF T(?People,?specialistType, “院士、百人计划、杰出青年”),THEN T(?Organizaion,hasOutstandingSpecialist,?People)
SKE平台中的推理规则应用在两个方面:对象属性推理和科研合作网络推理。
对象属性推理使得能够对一个对象仅做简单的描述而实现丰富的表示和关联。例如在科研人员信息中,可以推理得出该科研人员参加了哪些研究项目、参与了哪些科研活动、是哪些社团的成员等。
科研合作网络计算科研人员的合作关系。在SKE科研合作网络设计中,科研合作关系包括同论文、同科研项目、同课题组、同专利发明人等关系,每种关系赋予一定的权重,SKE推理模块在知识库中进行挖掘和计算,并用可视化方式显示科研合作网络。
4 SKE功能特色
基于本体的知识组织模型,SKE在系统建设中考虑系统的功能性、易用性、实用性,开发了多用户管理、平台信息安全管理机制、多门户共享、合作者网络、关联地图、数据关联、扩展检索等平台功能。SKE体现出三个功能特色:个性化平台的定制、多途径的信息导航、多方式的知识发现。
4.1 个性化信息环境的创建
个性化信息环境体现在知识组织体系的个性化、平台设置的个性化、内容的个性化。
(1)SKE以三种方式为用户实现个性化环境所需要的本体:直接采用SKE系统提供的核心科研本体;用户在科研本体基础上创建局部本体,实现与核心本体的互操作;通过添加资源描述框架(Resource Description Framework,RDF)的方式把外部获取的本体摄入SKE中,生成新的本体。
(2)在SKE平台的设置上,用户可以灵活设置多级的栏目、栏目与底层本体类的关联(一个栏目下可以设置多个类,或者一个类可以关联到不同的栏目下),用户也可以通过设置实例所在的本体类而把实例放置到不同的栏目下。
(3)在SKE内容的个性化创建上,提供了不同用户权限下的数据添加、修改,同时针对特定领域大量数据的摄入开发了数据摄取工具。面向本体的数据导入,由于本体中对象属性值的存在,往往1 000条数据导入后会生成几千条有关联的数据[ 10],例如一条论文数据导入后生成一条论文实例、三个作者(人员)实例、一个机构实例、一个期刊的实例,这些实例互为对象属性的值。另外,SKE提供的公共平台+子环境平台的系统架构,实现了不同平台数据的共享和个性化,可以在其他平台上定制数据后在用户的SKE平台的相应栏目下呈现,也可以把用户平台上的实例共享到其他平台。
4.2 导航式的知识关联
当前基于RDF的海量数据的出现,让关联数据技术的研究和应用成为热点,其中,对技术人员和用户最具有吸引力的是不同数据集的平滑整合[ 11],即数据间的“无障碍”关联。当前很多基于本体的系统中的数据,都被放到了LOD云中,如FOAF Profile、VIVO。SKE数据用RDF来描述,发布的实例都是基于本体的关联数据。
目前SKE实现了不同方式的内容导航,便于用户快速定位到寻找的知识,如图5所示:
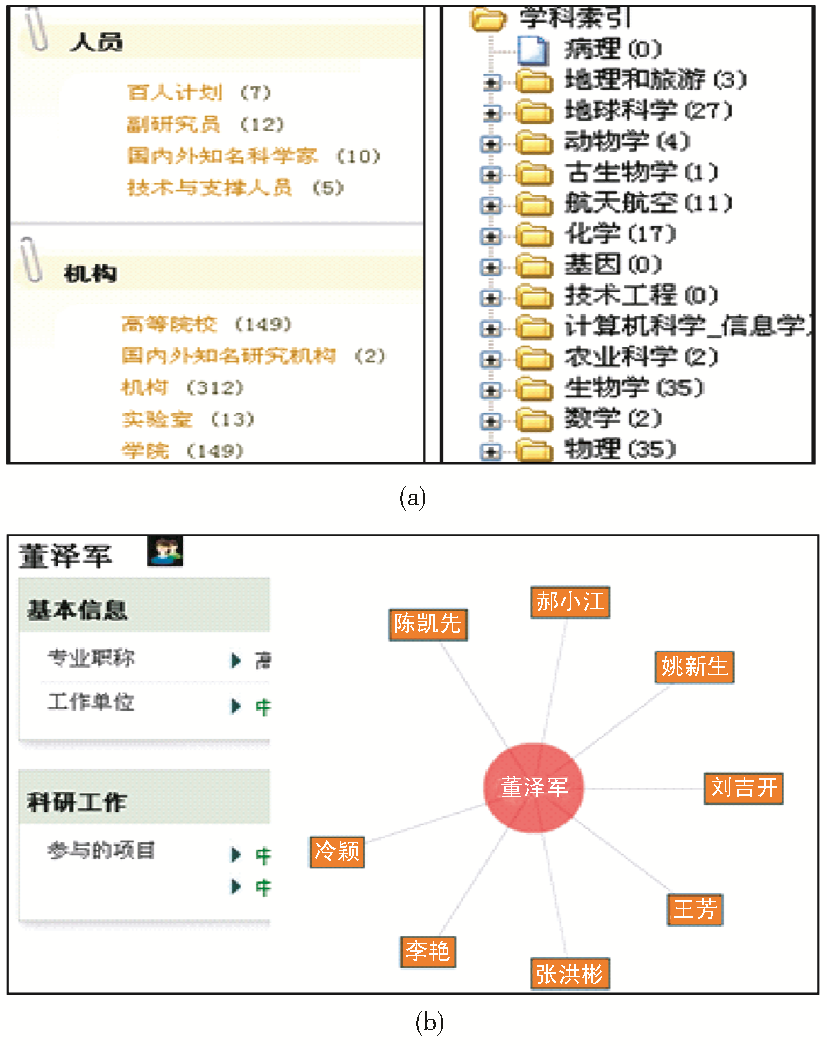 | 图5 SKE多种方式的知识关联 |
(1)不同信息资源的栏目分类浏览,实例存储于不同的本体类下,按照类与栏目的关联而显示在不同的栏目下。
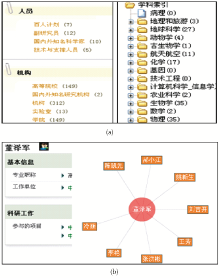
(2)提供索引,实现内容按照本体类目结构的资源类型索引(由科研本体支持)和学科领域信息索引(由主题本体支持),见图5(a)。
(3)基于本体关系的内容关联,实现不同类型实例之间的“链接”,例如某一论文(文献)-作者(人员)-研究项目(项目)-学术会议(学术活动),直接实现用户知识点/面的扩展。
(4)通过设计围绕人员的推理规则,实现了科研人员的合作者网络,见图5(b)。
4.3 多种路径的知识发现
SKE所实现的知识发现能力包含基于数据库的知识发现和数据挖掘,以帮助科研人员快速发现所需的知识内容。
(1)检索结果按照科研本体的类(即不同的资源类型)或学科主题本体的类(即专业领域知识点)分类呈现。
(2)推理规则(主要围绕人员和机构)的设计,实现平台上隐性知识的发现。
(3)支持SPARQL查询,可以从RDF数据中找到所需的数据,这个功能将来会应用在语义检索中。
4.4 第三方内容的动态集成
为了满足用户实时更新信息的需求,SKE平台上提供了“新闻聚合”(Really Simple Syndication,RSS)嵌入和“网页嵌套”,用户可以配置RSS信息源和定制来源嵌套网页,实现实时的第三方信息内容的集成和第三方工具的集成。
5 结语
在中国科学院院所协同的群组知识环境可持续能力建设项目中,SKE作为一种工具已经在中国科学院的部分研究所课题组中进行应用,主要的应用模式有4种:面向特定学科领域的知识平台建设、面向研究群组的知识平台建设、面向研究项目的信息发布平台建设以及面向研究团体或重大科研项目的协作平台建设。
通过SKE平台的应用和服务可以发现,科研用户对科研信息的综合利用与服务的需求很强烈。作为研究型图书馆,应该具有识别和判断用户潜在需求,引导用户增强信息利用意识和能力的职责。SKE平台不失为一个促进图书馆为用户提供个性化信息服务的工具和平台,是一个促进研究型图书馆转型的桥梁。
不同于以往的图书馆系统,SKE平台提供了一个从科研信息创建者到科研信息使用者的、从用户到用户的信息流,平台的管理者从图书馆员转变为用户。贴近用户需求、切入科研过程是SKE平台的重要目标。在未来SKE平台发展中,除了继续完善SKE框架中未全部实施的部分(主要是在数据集成、与第三方系统交互和开放知识组织引擎的应用这三个方面)外,更重要的是根据用户的应用需求,来发展平台框架和开发新的服务能力,使SKE平台真正成为用户的信息发现和利用工具。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|