



{kind=link}
{kind=link}
{kind=link}
混合动力思想下的图书检索系统研究*
引用本文
李智锋, 张李义. 混合动力思想下的图书检索系统研究* . 现代图书情报技术, 2012, 28(7): 54-58
Li Zhifeng, Zhang Liyi. Research of Books Retrieval System Under Thinking of Hybrid System. 现代图书情报技术, 2012, 28(7): 54-58
Permissions
Li Zhifeng, Zhang Liyi. Research of Books Retrieval System Under Thinking of Hybrid System. 现代图书情报技术, 2012, 28(7): 54-58
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
混合动力思想下的图书检索系统研究*
摘要
针对现有图书检索中忽略读者信息的不足,提出基于混合动力检索思想的新的检索模型。该模型根据图书的检索频率将书籍分为“冷、热”书籍两类,使图书检索从一个单向检索变为双向检索,再结合读者的特点使用Apriori和K-means算法建立数学模型,为读者检索最合适的书籍提供方便。提出模型具体的实现步骤并进行实验,将新旧检索结果进行对比评测。实验证明,新模型的检索准确性和效率有明显的提升。
关键词:
“冷热”图书; 图书检索; 混合动力
中图分类号:F203
Research of Books Retrieval System Under Thinking of Hybrid System
Abstract
Considering the ignorance of readers’ information in the book retrieval of library, the paper proposes the hybrid retrieval ideas based on hybrid thinking and creates a new retrieval model. According to the retrieval frequency of the books, the new retrieval model divides the books into “cold or hot” categories, which turns the one-way retrieval into two-way retrieval. Combined with the characteristics of the readers and the use of Apriori and K-means algorithm, it builds a mathematical model and provides readers with the most appropriate books. In accordance with the new ideas, experimental data is used in the comparative evaluation of new search and the old search,and the experiments show that the retrieval accuracy and efficiency of the new models are improved significantly.
Keyword:
“Hot or cold”books; Book retrieval; Hybrid system
1 研究背景
现行的图书检索,一般使用图书的特征进行检索,如检索关键字:ISSBN、年份、书名、作者或文章名称等,但在相同检索条件下检索得出的图书数量仍然很大,影响检索的准度和精度。传统关键字的检索虽比传统非信息化的检索效率好,但对于读者来说,这些检索的关键字覆盖度还远远不够。那么需要将关键字转化为系统编码,这是对读者的检索随机过程进行量化的过程。读者在这个过程中希望找到符合自己阅读习惯和性格特征的书,并希望图书馆的检索按照这种方式进行。本文从影响图书的检索关键因子出发,通过数据挖掘方法,利用借阅情景和读者两个本体形成智能型的检索系统,提出一种双向条件的检索。
关于现代图书的检索,前人已做了很多研究,也有不少研究集中在图书特征的检索上,如郭伟德[ 1]提到从年
份上检索图书;近年来,在网络检索领域许多学者也提出新的想法和建议,如王增红[ 2]提出图书馆的信息服务要有特色,才能在竞争激烈的网络环境中彰显自身独特的价值;赵英等[ 3]提出将PDF中的图片和文字分开检索。混合动力的起源是混合动力汽车[ 4]。最有突破性的混合动力研究是混合动力数字控制系统[ 5],而由Jo等[ 6]在混合动力的思想基础上提出信息数据以冷热数据进行划分,奠定了信息混合动力存储的概念基础,这种划分已经应用到当今固态硬盘和传统硬盘的混合读取中。在客户信息推荐上,Adomavicius等[ 7]提出了下一代的推荐算法在各个领域是无孔不入的。
在信息存储的另外一个领域,用混合动力的方法把固态硬盘和传统硬盘的优点进行互补的思想[ 6]已经非常成熟。由于图书馆业务也是信息存储的一种形式,与硬盘的检索方式类似。本文以混合动力思想[ 5]为建模思想,提出“冷热图书”的概念及其界定方法,使图书检索从一个单向检索变为双向检索,再结合读者的特点使用Apriori和K-means算法建立数学模型,为读者检索最合适的书籍提供方便,开发者也可以使用WEKA+J2EE的组合进行相关图书检索系统的后续开发。
2 基于“冷热”图书及属性的混合动力检索模型
2.1 书籍的“冷热”界定
现代汽车动力学的混合动力理论认为,低速的时候称为冷速度;高速的时候称为热速度。冷速度使用电力动力,热速度使用汽油动力[ 4]。而对于硬盘来说,冷数据使用HDD传统硬盘;热数据使用读取速度较快的固态硬盘。图书馆的书籍较多,仿照这个冷热理论划分,有些书有很多读者借阅,这种书籍的借阅流量较大,称为“热”书籍;相反则称为“冷”书籍。
本文使用数据结构中折半查找的方法划分“冷”图书和“热”图书[ 11]。“冷”图书指的是借阅频次不高的书籍,“热”图书是借阅频次较高的书籍,根据本图书馆的借书情况进行动态设置。
2.2 Apriori算法和K-means算法的结合检索
K-means聚类是系统根据图书馆提供的历史数据进行挖掘。聚类除了将现代图书馆一般的影响因子如:书名、出版年、检索号、作者等作为检索的关键字外,还必须要加上其他属性的影响因子如作者的研究方向、图书的理论基础、作者年龄等进行K次均值聚类。对于不同的书籍,提供按照不同的借阅次数进行聚类,聚类的结果成为“冷热”图书的特征划分结果。聚类降维后作为Apriori函数的配对参数。
Apriori算法是寻找图书聚类元组和读者特征关联性的主要方法,该算法可以让本来不相关的元组成员进行归类。本文采用Apriori算法对书籍进行推送。如表1所示,Apriori算法存在几个特征度量[ 11]:
| 表1 Apriori算法中的度量 |
设一条关联规则属性L(书籍)->属性R(读者)
(1)Support为支持度,用于估计在一个读者借阅过程中同时存在属性L和属性R的概率。
(2)Convince为关联规则,置信度是估计购物过程出现L时也会出现R的条件概率P(R|L)。关联规则的目标一般是产生较高的规则。
(3)由几个类似的度量代替置信度来衡量规则的关联程度,分别是Lift(提升度)=P(L,R)/(P(L)P(R)),Lift=1时表示属性L和属性R独立。Lift数越大,越表明属性L和属性R存在于一个借书过程中不是偶然现象。
(4)Leverage平衡度=0时独立,Leverage越大表示属性L和属性R的关系越密切。
(5)Conviction确信度=P(L)P(!R)/P(L,!R),(!R表示R没有发生)。Conviction用来衡量属性L和属性R的独立性。从它和Lift的关系可以看出,这个值越大越好。
支持度(Support)和置信度(Confidence)用来衡量关联的重要性。当书籍A和读者B中各属性相关度非常高的时候,系统依据以上5个判据可以将A和B判断为频繁项集。
2.3 “冷热”图书检索建模
本搜索系统分为三个阶段,如图1所示:
 | 图1 冷热图书随机过程的分析图 |
(1)“冷热”书籍的分类处理。系统将借阅频数较高的书籍进行排序。
(2)将“冷热”图书进行聚类。这种数据挖掘方法是先找出图书特征形成类的自然中心,根据每个元素对中心的距离不断递归出新的类中心[ 10]。聚类可以将多本“热”书籍自然收敛成几种主要的类别。
(3)图书与读者进行匹配。完成K-means聚类[ 10]后,系统利用Apriori算法[ 8]对聚类结果和读者属性进行相关算法分析。
此图书检索模型具有能将检索者信息与检索信息联系起来的优势,同时,在检索方法上也优于传统方法,能够增加检索维度,降低检索时间和成本,提高检索准度和精度。
3 “冷热”图书及属性混合动力检索实验
3.1 数据采集
数据集是在广东培正学院图书馆随机抽样53本有关电子商务的书籍,这些书籍的选用条件是在一年当中至少有一次被借阅。53本电子商务书籍形成小样本数据集,这些书籍较为常用,96名读者曾在2010年5月-2011年4月借阅这些书籍。将读者的属性中的信息作为一次平均值,利用这些样本数据进行实验。
3.2 实验参数构造
对书籍的特征进行聚类降维后得到图书复合影响因子,再以图书影响因子作为第一类特征、读者的影响因子作为第二类特征进行关联分析。书名关键字是图书名字的关键字,关键字表示书籍的分类体系;出版年份指书籍出版的年份;出版作者的学历背景,这项是目前图书馆的检索式中所没有的;作者的年龄表示作者所处的年代;读者年龄表示读者所处年代;职业背景是指从事与某种知识相关的职业;学历是指中专、大专、本科、研究生等不同的学历层次。图书对应分析参数如表2所示:
| 表2 图书对应分析参数 |
3.3 图书检索实验
本系统基于欧几里德距离的K-means聚类,建立数学模型:
X1n:作者的文化层次;X2n:借阅这类书籍的次数;X3n:作者的年龄;X4n:对书的出版时间要求;X5n:对书籍理论化要求;n:统计总样本容量。
K-means结果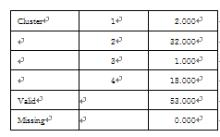
图2是利用SPSS工具根据表2所示的参数对书籍样本进行K-means聚类分析,得出读者群体的多项聚类。这个聚类可以将多维的读者信息进行K-means分析,可以看出第2类读者借阅的多属于热书籍,这说明检索作者年龄较小、学历层次较高、背景较好;第3类聚类显示书龄较长和借阅量较少的书籍是冷书籍;第1聚类显示次冷书籍,表示书龄不大,作者的文化层次不高;第4类聚类显示次热书籍,表示书龄不大,作者年龄偏大,但作者背景较好。
聚类之后,将热书籍和冷书籍作为情景对读者进行关联运算。分析后系统寻找到4条关联结果(Rules):Rule1的置信度是0.85,表示同时出现年龄大的读者和旧书的比率是85%。与此同时,出现年龄大的读者和出现书龄均数是30.5,占出现旧书的总数的80%。这说明冷书籍和次冷书籍受年纪较大读者关注。提升度P(L,R)/(P(L)P(R))=3.5,Lift=1表明这两个条件独立,这里Lift是3.5(远大于1),Leverage=0.17(大于0)也表示这不是一个偶然现象。 对比R1和R2,由于R2=2.45的置信度比R1=1.86高,所以选择R2。说明专业为历史的读者比较倾向于电子商务的发展的书籍。Rule3和Rule4表明理论性的书籍和低年级的学生的相关性比较高,并且这种组合的购买率比较高。这是一组唯一与选阅率有关的推理项,Confidence=1表明这是一个非常可信的元组,可信度达到100%。Lift是3.2(远大于1),这是一个强关系的频繁项。
3.4 混合动力检索与现有检索结果的比较
笔者利用广东培正学院的图书检索系统进行实验。当搜索关键字为“电子商务”和“信息化”时,所得检索结果如图3所示:
可知,读者需阅读完所有的检索结果之后才能得到所需要的书籍,这种传统的检索方式耗时长、成本高、准度和精度较低。
图4为按照混合动力检索模型检索得出的结果,检索关键字同样为“电子商务”和“信息化”,但新模型的检索关键字可加上读者的年龄(如22岁)、学历(如本科)、专业(如计算机科学与技术)。
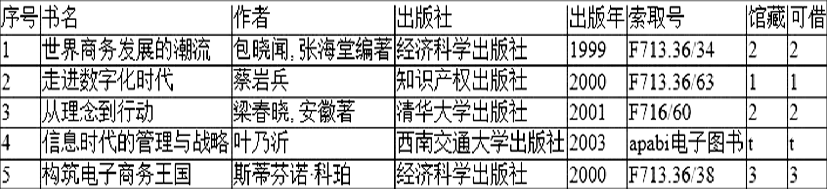
将图3和图4进行比较可知,图4比图3更符合读者需求的检索结果。由于读者比较年轻,呈现出来的结果是近期借阅频次较高的书籍和对读者而言是较为实用的书籍。如果读者需要一本《走进数字化时代》的书籍,在现有的检索系统中要翻到6页才能找到,而经过混合动力推送则在第一页就可检索到。
4 结语
笔者吸收前人在图书馆检索功能方面的研究成果,提出新的图书检索模型。在读者使用图书馆检索功能时,首先以现代硬盘的混合动力思想进行“冷热”图书的分类,通过模仿引擎中的环境因素对冷热数据进行随机分析,然后采用离散的处理方法进行K次聚类和Apriori算法的分析,从而为读者提供个性化智能服务,最大限度地满足读者的检索需求。冷热图书及属性的混合动力检索模型使图书检索从一个单向检索变为双向检索,考虑到了读者各个方面的属性,在增加检索效率的同时也增加了检索的准确性。通过实验数据的验证,检索结果有明显提高。
混合动力检索为读者提供了一个交互式检索环境,但基于混合动力检索只是一个双向检索的开始,对随机过程中影响因子的提取还不足,未来在图书馆检索模型中需要利用更多的影响因子、算法以及思想对检索进一步的改进。此后的研究可以关注书籍内容文本与读者属性特征之间的关联。此外,本检索模型还可以推广到图书馆电子书籍借阅和电子商务网站的智能销售当中。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|