
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于REST架构的术语注册与服务研究实现*
引用本文
徐雷, 董慧. 基于REST架构的术语注册与服务研究实现* . 现代图书情报技术, 2012, 28(7): 59-65
Xu Lei, Dong Hui. Terminology Registries and Terminology Services Research and Implement Based on REST. 现代图书情报技术, 2012, 28(7): 59-65
Permissions
Xu Lei, Dong Hui. Terminology Registries and Terminology Services Research and Implement Based on REST. 现代图书情报技术, 2012, 28(7): 59-65
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
基于REST架构的术语注册与服务研究实现*
摘要
通过分析信息组织领域中术语访问存取的方式及其标准,提出基于REST架构的术语注册与服务体系结构,并使用相关工具构建一个实际的术语注册与服务平台。该平台提供术语批量转储、术语注册与访问、术语可视化以及面向用户的Web服务API。最后阐述该体系架构的特点及该平台的优势,并总结该领域的发展趋势。
关键词:
REST; 术语存取方式; 术语注册; 术语服务
中图分类号:G250.76
Terminology Registries and Terminology Services Research and Implement Based on REST
Abstract
On the basis of analysis of modes and standards to access terminology, this paper puts forward a system structure of the terminology registries and terminology services based on REST, and constructs an actual platform for terminology registries and terminology services. This platform provides such functions as terminology converting and storing in batch, terminology registering and accessing, terminology visualizing and Web services API for users. And then this paper discusses the characteristics of the system structure and the advantages of this platform. Finally,it summarizes the development trend of this field.
Keyword:
REST; Terminology; access; mode; Terminology; registries; Terminology; services
1 引言
在信息组织和知识组织领域,叙词表、分类词表、本体词汇、各种元数据等术语(此处指广义的词表,包括叙词表、分类词表、图书馆编目元数据以及其他各种组织形式的词表系统)系统越来越受到研究者的重视,这些术语或称为词表,可以应用在诸如信息检索、推荐服务、图书馆编目等诸多领域。目前,国际上有很多组织从事术语的注册与服务等相关研究工作,从研究的内容来看,主要包括相关标准与协议的制定、术语注册平台设计、术语存取方式的研究、术语服务客户端工具的开发等方面,文献[1]针对国内外相关的研究现状做了调研与总结,列举分析了诸如Taxonomy Warehouse、Luxurious Bank、FAO VEST Registry、Open Metadata Registry、OCLC术语服务等一些常见
的术语注册与服务项目,总结出目前国内外术语注册系统功能大致如下:词表的注册和上载、词表元数据的浏览和检索、词表内容的浏览和检索、词表的在线编辑修改、版本控制等[ 1]。
纵观这些术语服务,其中大部分采用基于Web服务的形式对外提供应用程序接口(API)。从术语访问存取的方式来看,目前使用的标准主要有Z39.50、CQL、SRU/SRW、REST等。Z39.50是一个标准的基于客户端服务器模式的信息检索协议,现已被广泛应用于图书馆领域,如个人书目引文软件、图书馆馆际互借等[ 2]。CQL(Contextual Query Language)是基于Z39.50语义进行设计的信息检索查询语言,支持诸如Web索引、分类书目等系统的查询,其设计目标是让用户容易读懂并能够写出这些查询语句。SRU(Search/Retrieval via URL)是一个基于Web URL的信息检索协议,在Z39.50基础上丢弃了其通信协议但保留了Z39.50的查询语法。SRW(Search-Retrieve Web service)是和SOAP协议绑定使用的,它和SRU的返回结果都是XML文档[ 3]。表征状态转移REST(REpresentational State Transfer)是Fielding[ 4]在其博士论文中提出来的一种软件架构风格,它从资源的角度来观察整个网络,资源由URI(Uniform Resource Identifier)来标识,而客户端的应用通过URI来获取资源的表征。获得这些表征致使这些应用程序转变其状态,随着不断获取资源的表征,客户端应用不断地在转变其状态,这就是所谓表征状态转移[ 5]。
作为一种新的Web服务方式,近几年,REST的相关研究呈逐年上升的趋势,涌现出许多使用REST的研究及应用[ 6, 7, 8, 9]。本文在分析已有术语注册与服务项目的基础上,提出了基于REST架构的术语注册与服务体系架构,通过相关工具予以实现,并对该术语注册平台进行评价。
2 基于REST架构的术语注册与服务模型
2.1 REST的特点及优势
REST有5个主要的特点:资源是由URI来表示;通过HTTP协议提供的GET、POST、PUT和DELETE方法(CRUD)来实现对资源的获取、创建、修改、删除等操作;对资源的操作是通过操作资源的表征来实现的,具体来讲就是一个个URI;资源的表现形式没有限制,可以是XML或HTML;连接协议具有无状态性。
REST的优点是显而易见的,采用URI来表示资源,使得资源的标识更为明确,这样对资源进行修改不会影响该资源的URI,用户对资源的访问存取也就不会受到影响;可使用多个层次来扩展,且连接协议具有无状态性,能够保证对不同服务器的并发访问,还能够利用缓存机制来提高响应速度;同时客户端还可以按需发送代码到服务器端执行。采用REST架构的Web服务,称为Restful Web Services,严格来讲,Restful Web Services并不是一个标准,只是一个架构或规范,但它可以使用Web服务的各种标准,不依赖具体的协议使REST软件的依赖性更小、更具兼容性。
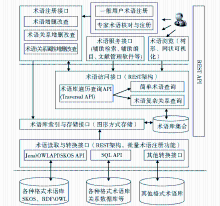
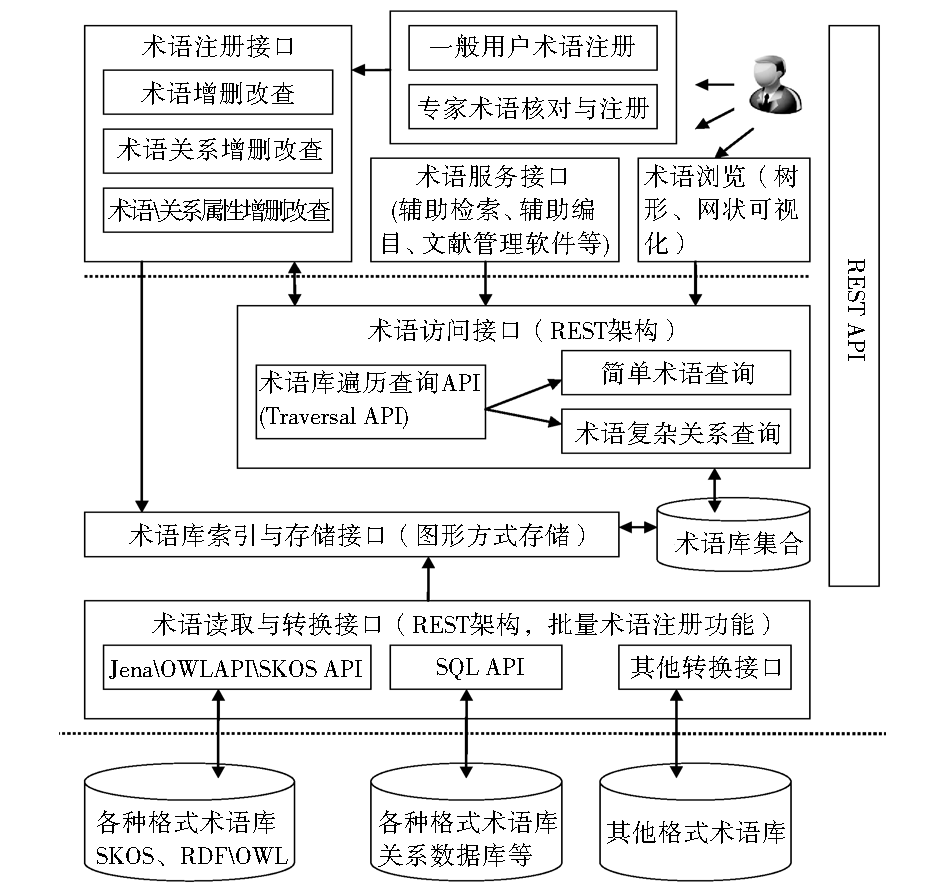
由于REST逐渐受到企业及科研人员的广泛关注和使用,本文在分析术语存取关键技术的基础上,提出了基于REST架构的术语注册与服务模型,如图1所示。并使用Neo4j[ 10]图形数据库来作为术语注册、存储、索引、发布、访问的服务器,开发了一个将OWL格式的术语表转储索引到该数据库的插件,实现了术语表的注册、浏览、检索、可视化等功能。
 | 图1 基于REST术语注册与服务系统体系架构 |
2.2 Neo4j图形数据库
Neo4j是当前发展迅猛的NoSQL的一个具体实现,是处理海量数据的一个解决方案。图形数据库使用图形网络来存储数据,具体来讲,它使用节点和关系(节点和关系通过URI来表示)来组织数据,节点和关系各有自己的属性,节点之间通过关系来连接。由于Neo4j采用图形这种一般的数据结构来组织数据,它能够以高可存取性来表现各种各样的数据,通过转换与映射规则,可以处理各种格式的数据,包括传统的关系数据库、XML、JSON、RDF\OWL等结构化数据,同时提供数据安全保护、一致性、集成等机制,使其具有很强的实用性[ 10]。Neo4j的这种数据组织形式很适合术语的存储与访问。
目前,Neo4j支持最大的数据量为:344亿节点、344亿关系、687亿属性,但其查询性能与数据量无关;同时支持分布式机制、7×24全天候不间断服务等性能;可以作为一个嵌入式的服务器使用在已有的系统中,而无需重新部署应用;同时提供了强大的图形遍历API及节点与关系的索引功能和批量处理功能,采用CQL(Cypher Query Language)查询语言来支持复杂查询,支持多语言的客户端;更重要的是它拥有强大的REST API和插件管理机制,本文开发的owl2neoPlugin插件就是依托其进行管理的。
2.3 基于REST的术语注册与服务体系架构
该体系结构分为三层:
(1)最底层资源层为各种术语资源,这种术语资源按各种格式进行组织,诸如SKOS、XML、MARC21、RDF\OWL等。
(2)中间层为模型的核心功能层,包含模型的核心接口,具体细分为:
①术语读取与转换接口,它针对不同的术语资源,采用不同的操作API,对其进行批量处理操作,将术语编码为相应的URI,并赋予其相关的属性内容及关系;
②术语库索引与存储接口通过使用Neo4j来对转换编码后的术语进行存储与索引,以便基于这些术语索引库进行查询应用;
③术语访问接口中使用Neo4j的REST API来实现术语的简单与复杂查询,可以是简单的URI访问,也可以利用REST的“按需代码”特性,向服务器POST一个复杂的CQL查询语句,实现术语关系、术语属性、术语上下位词、术语的同级术语等查询。
(3)最上层为应用层,包括用户术语注册接口、术语服务接口、术语的浏览接口。
为了保证术语的注册质量,该体系结构增加了一般用户与专家用户的不同注册方式,由专家对注册的术语库进行核对修改。
3 基于REST术语注册与服务平台的实现
本文构建了一个在线的术语注册与服务平台,使用Neo4j作为术语存储与索引服务器,并在其基础上构建了术语注册与查询模块、术语可视化模块,独立开发了owl2neoPlugin插件,实现了OWL本体格式的术语库的转储与索引,同时提供了简单的术语访问方式与复杂的术语访问方式的接口,向用户提供了访问术语的API。
借助该平台,本文选择NCI叙词表[ 11, 12]作为本实验中的术语资源层,来验证该体系架构的可行性。NCI叙词表(OWL格式)是美国国家癌症研究中心发布的基于描述逻辑的癌症叙词表,它比一般的医学词表更为复杂,术语之间的语义关系更为丰富,该词表描述了疾病、药物、化学药品、诊断、基因、治疗、解剖、有机体、蛋白质等主题,总共约由500 000个三元组构成。
3.1 术语转储索引
术语转储与索引位于架构的第二层,直接访问资源层的术语。为了便于应用与管理,本文使用Jena API,开发了处理RDF/XML格式的插件owl2neoPlugin,将RDF或OWL格式的术语经过解析并读取转储在Neo4j数据库中。具体来讲,将该OWL中的术语概念(Class)表示为Neo4j数据库中的节点Node,将概念的对象属性(Object Property)表示为Neo4j中的关系Relationship,将概念的数据属性(Datatype Property)以及概念的注解(Annotation)和对象属性的注解表示为Neo4j中节点或关系的属性。经过术语转储处理,目前系统中总共有41 615个NCI术语、268 471个属性(包括术语的属性及术语之间的关系的属性),60 831个术语之间的关系,关系类型有72个。插件的核心类代码如下:
public class GetAll extends ServerPlugin
{
private static Index
private static Index
@Name("owl_import")
@Description("对Neo4j进行扩展,实现对OWL本体的导入")
@PluginTarget(GraphDatabaseService.class)// 标注该插件的入口
public Iterable
{
Transaction tx = graphDb.beginTx();//启动事务
OntModel m = ModelFactory.createOntologyModel(OntModelSpec.OWL_MEM, null);//调用Jena OwlAPI
m.read("user.dir")+ "nci.owl");//读入NCI本体术语
for (StmtIterator i = m.listStatements(); i.hasNext();)
//遍历NCI本体库
{
……
Statement stmt = i.nextStatement();
Resource subject =stmt.getSubject();//获取三元组主语
RDFNode obiectNode = stmt.getObject();//获取三元组宾语
String predicate = stmt.getPredicate().getLocalName();
//获取三元组谓语
……
Node nciNode = nodeIndex.get("NCINODEID",subject.toString()).getSingle();
nciNode = graphDb.createNode();//创建术语
nciNode.setProperty("NCINODEID",subject.toString());
nodeIndex.add(nciNode, "NCINODEID",subject.toString()); //术语索引
if(object.isLiteral())//如果是数据属性则添加为该术语的属性
nciNode.setProperty(predicate, object);
else{//对象属性添加为术语的关系,关系名为该三元组的谓语
Relationship relationship= nciNode.createRelationshipTo(objectNode, RelTypes.valueOf(predicate));
relationship.setProperty("NCIRELID", stmt.getPredicate().toString());
relIndex.add(relationship, "NCIRELID", stmt.getPredicate().toString());//关系索引
}
……
tx.success();//关闭事务
return GlobalGraphOperations.at(graphDb).getAllNodes();
//导入操作完毕,返回所有术语,调用下面的方法
}
@Name("get_all_term")
@Description("获取所有的术语,直接使用Neo4j自带的方法")
@PluginTarget(GraphDatabaseService.class)
public Iterable
{
return GlobalGraphOperations.at(graphDb).getAllNodes ();
}
//获取所有术语之间的关系和获取所有术语的代码相似,在此省略
}
该插件对Neo4j的REST API进行扩展,本文按照插件开发规范,开发的工具类中继承了Neo4j的ServerPlugin类,封装了对节点、关系、路径等应用逻辑的操作,并提供了@PluginTarget注解来标注该插件的入口,这些插件会自动注册到服务器上去,用户在发送请求后,返回的结果JSON容器(Neo4j默认以JSON格式来请求和响应数据)中多了一个“extentions”,该属性就包含通过该插件可以进行的操作。这些操作具体来讲就是一个个URI,插件扩展后返回的结果如下:
"extensions_info" : "http://127.0.0.1:7474/db/data/ext",
"extensions" : {"GetAll" :
{"get_all_term": "http://127.0.0.1:7474/db/data/ext/GetAll/termdb/getAllNodes",
"get_all_rel" :"http://127.0.0.1:7474/db/data/ext/GetAll/termdb/getAllRels"}
}
可以通过
3.2 术语注册
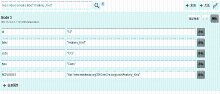
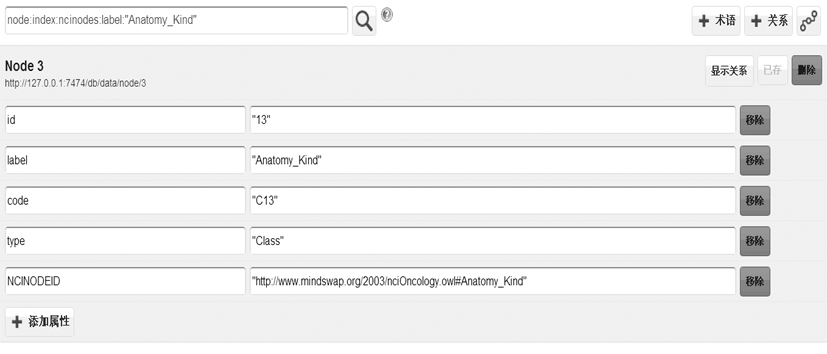
术语注册功能直接给应用层提供了操作接口,包括术语添加,已有术语属性的增加、删除、修改、查询,术语之间关系的操作,新关系及其属性的操作等,这些增删改查操作分别对应HTTP的POST、DELETE、PUT、GET方法;图2是对“Anatomy_Kind”术语进行注册的界面,通过“+术语”来进行该术语的添加,“+添加属性”进行该术语其他描述信息的添加,通过“移除”实现相应属性的删除。
 | 图2 术语注册示意图 |
这种术语注册功能是借助于Neo4j的REST API来实现的,本文使用Jersey(REST架构服务器客户端)作为Web服务的客户端。通过将术语节点生成URI,将术语及其属性包装到URI中,最终通过调用HTTP协议的方法,如POST、PUT等,将术语节点以JSON格式作为HTTP头的Payload Data(有效载荷数据),传送到数据库服务器,这个过程就是客户端发起的术语注册请求过程。
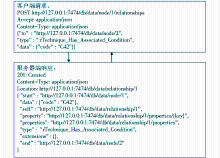
服务器接收到请求后进行相应的处理,即增删改查操作,如果没有异常出现,那么服务器将返回操作成功的状态码,如“201 Created”表示术语添加成功,返回的Location头参数代表新创建术语的URI。在图2中点击“+关系”用于向该术语添加新的关系,添加关系的过程同添加术语一样也是客户端和服务器端的交互过程,具体的技术实现细节和术语的添加过程相似,区别在于关系的JSON格式内容和术语的JSON格式内容不同。关系注册的交互过程如图3所示:
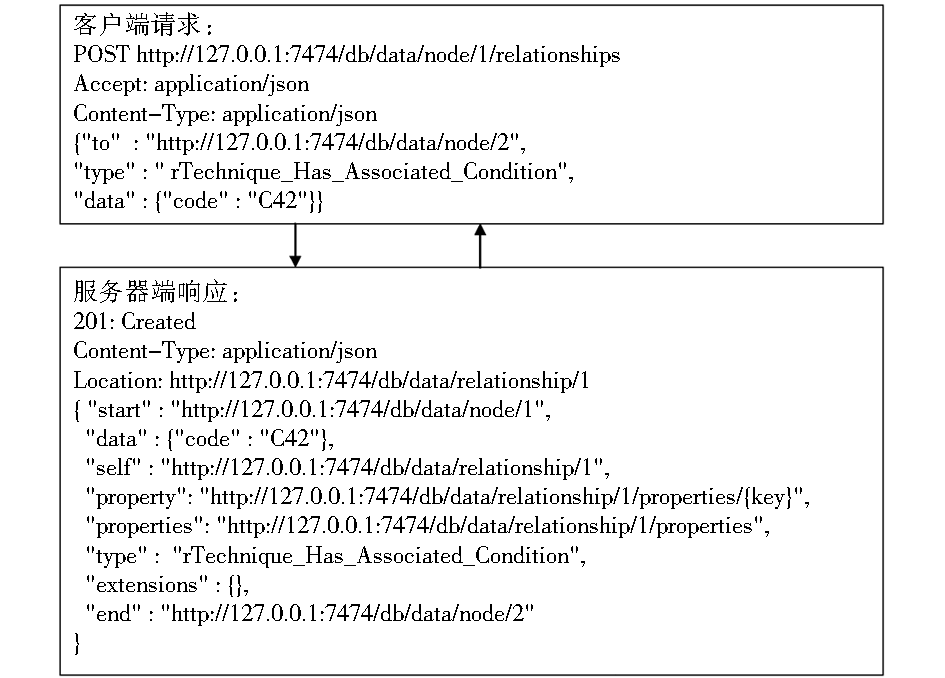 | 图3 关系注册交互过程 |
其中,“POST http://127.0.0.1:7474/db/data/node/1/relationships”表示使用HTTP的POST方法将术语(id=1)需要建立的新关系(关系类型为“rTechnique_Has_Associated_Condition”),连接到的术语
3.3 术语访问及可视化
术语访问及可视化模块位于架构的应用层,提供了术语查询与术语库遍历及结果可视化的功能,术语访问接口支持最简单的,诸如术语节点ID或关系ID的查询,同时还支持具有更强大功能的CQL复杂查询,这些查询语句都可以在图2所示的查询框中输入。CQL是一个描述性的图形查询语言,开发人员及用户都很容易理解。可以通过在CQL中添加该语言内置的查询原语,如shortestPath实现最短路径查询,collect实现结果的列表化,还可以使用正则表达式、过滤器等构造更复杂的查询语句以及顺序、循环、逻辑判断等结构化的逻辑查询。
图4是CQL查询的两个示例,通过HTTP的GET方法,并将CQL语句转换为JSON格式,如:{"query": "start n = node(1) match n -[r]-> n2 return type(r), n2.name?, n2.age?","params": {}}传入服务器,服务器端解析CQL语法,调用Neo4j的遍历接口,进行快速的查询,并返回结果。
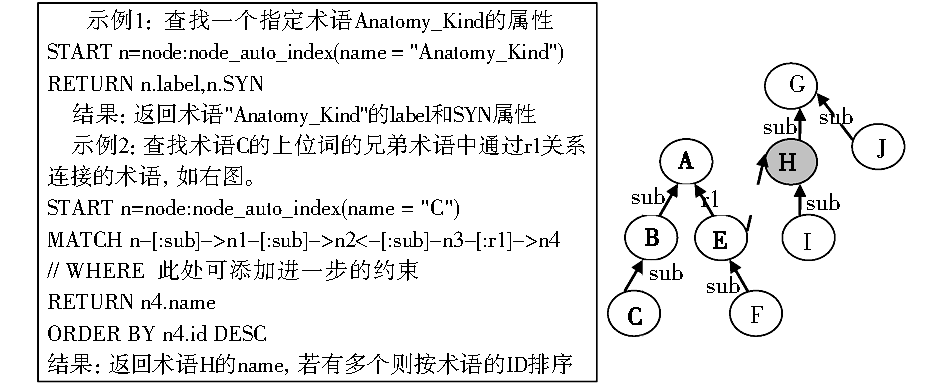 | 图4 CQL查询 |
Neo4j提供了强大的图形遍历API,但用户可以不直接接触这些接口,而通过类似如下的JSON参数进行相应的配置:{"order":"breadth_first","uniqueness":"none","return_filter":{"language":"builtin","name":"all"}},它表示采用广度优先遍历策略,节点可以多次访问的方式来进行图形的查询操作。通过GET方法将其发送到服务器,实现间接调用底层遍历接口的功能,这对开发人员来说是十分友好的。这个例子和图4中的CQL查询都可看作是REST的“按需代码”特性的体现。
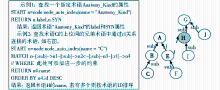
对于该平台的可视化结果,使用了Neo4j的可视化插件Graphviz来实现,可以通过单击术语节点实现术语的隐藏、扩展、拖动等功能。为了布局清晰,术语节点只显示了术语的名称,但可以通过设置,显示术语节点更多的属性信息,如术语“Dipyridamole”还有“Semantic_Type”属性值为“Pharmacologic Substance”、 “Synonym”属性值为“Persantine”等。
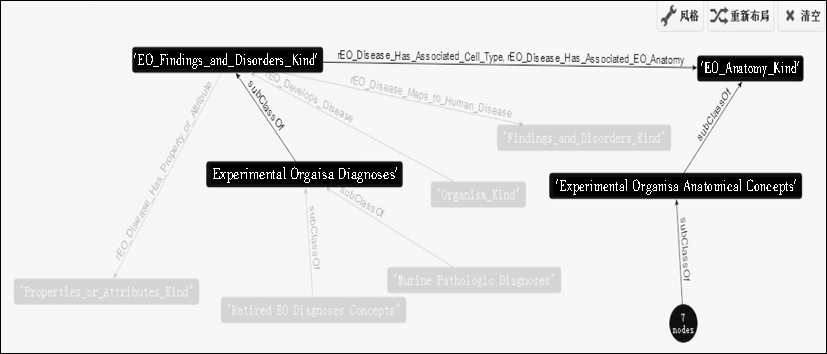 | 图5 NCI术语可视化示意图 |
图5中节点表示一个NCI术语,边表示术语之间的关系,其中“subClassof”关系来自本体中的子类关系,实质上即指术语的上下位关系,如“EO Anatomy Kind”的下位词是“Experimental Organism Anatomical Concepts”,除了术语间的上下位关系外,这些术语也有其他非常丰富的关系,如术语“Organism Kind”通过“rEO_Develops_Disease”关系和术语“EO Findings and Disorders Kind”联系。术语之间可以有多种关系,如“EO Findings and Disorders Kind”和“EO Anatomy Kind”之间就存在“rEO_Disease_Has_Associated_EO_Anatomy”、“ rEO_Disease_Has_Associated_Cell_Type”两种关系。
3.4 术语Web服务API
一个好的术语服务平台不仅应给用户提供术语的在线查询功能,还应提供相应的Web服务API,以便于用户开展个性化的术语服务应用。该平台对外提供了Restful Web服务API,可以方便用户在该服务平台的基础上开发自己的术语服务系统或向该平台注册新的术语。本文选用的是Jersey客户端,用户也可以根据需求选择其他的客户端。目前该客户端包含具体术语注册接口、术语关系注册接口、术语及关系的属性添加、术语及关系的修改与删除接口、强大的查询API等接口。其中除查询访问接口外,其他接口主要面向专家用户,由其对术语进行增删改操作,术语的查询接口则面向所有用户使用。目前术语查询API包含获取所有术语、获取所有术语关系、获取单个术语属性及关系、获取术语的上下位术语词汇、获取两个术语之间的路径等方法,这些方法都对外提供相应的操作URI以及辅助的CQL查询代码。用户以Jersey作为客户端使用这些API的核心流程如图6所示:
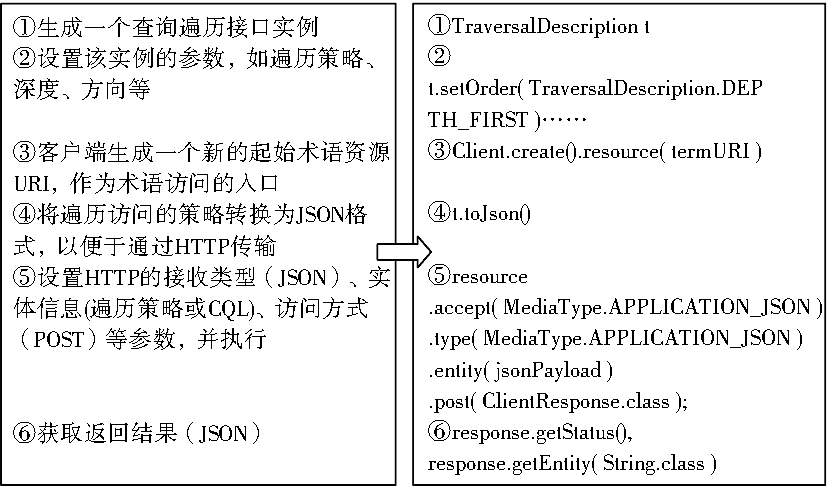 | 图6 术语Web服务API操作流程 |
4 平台优势及评价
该平台借助Neo4j的优异性能,支持客户端以多语言访问其发布的术语服务,其强大的图形遍历接口、索引和批处理机制保证了快速的查询响应速度以及对海量数据的存储与查询支持,同时采用插件机制便于功能扩展与管理,理论上能够开发出各种格式的术语转换插件,如marc2neoPlugin、xml2neoPlugin、sql2neoPlugin等,实现不同术语的集成共享。
本文的术语导入插件owl2neoPlugin由Neo4j的插件机制进行管理,其他各个模块的集成主要使用Neo4j的REST API,其流程较为一致,即都通过HTTP协议进行术语的各种操作,都会调用Neo4j服务器底层的图形操作接口,因此,该系统的模块之间借助于Neo4j服务器平台较好地融合为一体。
借助REST的优势,可以通过一次HTTP请求实现多次操作,显著改善了访问性能,这与传统的一次请求只处理一个操作的Web服务方式相比是一个很大的改进。另外,一般的Web服务器默认只支持HTTP1.1协议的POST和GET方法,如SRU\SRW只支持GET方法,Neo4j支持DELETE和PUT方法,这是对HTTP协议的完美应用,REST的使用也让HTTP协议的应用更加规范化。
笔者使用JMeter工具对该系统提供的术语服务进行连续10次的压力测试,测试环境如下:操作系统:WinServer2003;服务器:Neo4j内置的Jetty服务器;CPU:Intel(R) Xeon(R) 4CPUs 1.8GHz;内存:1GB。访问测试的结果如表1所示。
从表1可以看出,系统的整体响应速度很理想,随着用户的增加,服务器需要响应更多请求,并通过网络
| 表1 系统压力测试结果 |
传输更多数据,导致系统的响应速度会有所减慢,但仍在接受范围之内。同时,发现系统的内存使用量并不会因用户的增长而急剧增加,这是由于Neo4j采用基于磁盘形式的术语存储方式,使用REST架构的缓存机制,保证了服务器内存不会因为术语库较大而出现溢出情况,也满足了高效的处理能力。这对于解决SKOS 或大文档术语库不能直接加载到内存的问题是一个很好的解决方案。
目前该平台只使用了NCI术语库,对于通用的术语库,如各种主题词表,也可以使用该平台来提供术语注册与服务的应用。对于该平台提供的术语服务方式,除了术语的检索与可视化外,也可以运用在其他场合,诸如,可以使用该系统的图形遍历接口,计算两个术语之间的语义相似度;对搜索引擎中用户的检索项进行扩展辅助查询,达到更高的召回率等。
5 结语
本文总结了术语服务的应用和术语访问存取方式,详细介绍了基于REST架构的术语注册与服务的模型及具体实现,借助当前流行的NoSQL图形数据库Neo4j实现了该模型,开发了owl2neoPlugin插件,并利用REST API来进行术语的注册与检索。
该系统目前只实现了术语的批量转储、注册、可视化展示、查询功能,并提供了用户Web服务API,对于术语的其他在线浏览形式,或利用该术语系统提供其他的服务,不是本文的研究重点。通过该术语注册与服务平台,用户可以实现术语查询与复杂的检索功能。不过,该平台还有一些模块没有封装进去,如系统用户的注册管理、词表的上传下载等,这是后期需要完善的部分。
通过本文的研究,发现各种关于术语注册的协议、标准、技术正在进行融合或相互改进与借鉴,各术语之间的映射,术语注册与服务方式也正向着更为集成共享的模式发展,可以预见对于术语的组织形式、存取标准、服务方式的研究仍将继续深入。本文后续的研究包括:术语查询客户端的设计,提供术语关系的复杂检索入口,而不再直接编写CQL语句;多语言查询接口的设计;多格式术语版本的转换平台设计;以及依赖具体术语领域的各种术语服务的研究等。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|