词汇相似度研究进展综述*
引用本文
刘萍, 陈烨. 词汇相似度研究进展综述* . 现代图书情报技术, 2012, 28(7): 82-89
Liu Ping, Chen Ye. Survey of the State of the Art in Word Similarity. 现代图书情报技术, 2012, 28(7): 82-89
Permissions
Liu Ping, Chen Ye. Survey of the State of the Art in Word Similarity. 现代图书情报技术, 2012, 28(7): 82-89
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
词汇相似度研究进展综述*
摘要
从有背景信息和没有背景信息两个角度对国内外词汇相似度研究现状进行深入分析和比较。没有背景的统计方法不能真正挖掘出词对间的语义关系,语义词典也存在覆盖词汇范围有限等局限性,而维基百科作为含有语义词典功能的大型语料库,成为新的词汇语义信息的重要来源。详细阐述维基游走法、内涵概念图法和时间语义分析法这三种最新的基于维基百科的词汇相似度算法,指出词汇相似度研究今后将有机融合维基百科和其他背景信息,使各种词汇语义信息来源优势互补。此外运用复杂网络的分析方法来挖掘词汇网络中词汇的相关性将是词汇相似度研究的又一发展方向。
关键词:
词汇相似度; 语义相关度; 相似度计算
中图分类号:TP391
Survey of the State of the Art in Word Similarity
Abstract
This paper provides a comprehensive review on word similarity measuring methods in two categories, with background knowledge and without background knowledge. The statistical method without background knowledge cannot reveal the semantic relations between words, and the thesaurus provides limited scope of words. Wikipedia, as a large corpus comprising semantic knowledgebase, becomes the new sources for measuring semantic similarity between words. Three new Wiki-based methods, WikiWalk, conceptual graph, and temporal semantic analysis are described in details. The future directions of this field continue to combine Wikipedia and other background information as complementary semantic resources. In addition, characterizing relatedness between words by performing a complex network analysis is also a future challenge.
Keyword:
Word; similarity; Semantic; relatedness; Similarity; measures
1 引言
在计算机技术飞速发展的今天,人们利用计算机进行各种数字化信息的组织、管理和利用。在对数字化信息进行组织、管理和利用的过程中,自然语言处理是一项极为重要的基础性工作。词汇是自然语言处理的最小词义单位,因而词汇语义的理解是自然语言处理中最为基础的研究。而词汇之间是相互关联而非独立存在的,所以要正确理解词汇的语义离不开词汇之间的关联强度,即词汇相似度的计算。词汇相似度研究作为自然语言处理中一项基础性研究,被广泛应用于机器翻译、文本智能检索、自动问答系统、文档分类和聚类等方面[ 1]。在基于实例的机器翻译中,词汇相似度用于衡量文本中词汇的可替代程度;在文本智能检索中,词汇相似度能更好地反映文本与用户查询在语义上的符合程度;在自动应答系统领域,词汇相似度用于计算用户问句与领域文本内容的相似
程度;在文本分类和聚类中,词汇相似度更是分类的依据和聚类的基础。
基于词汇相似度的重要性,研究者从不同角度提出了多种词汇相似度计算方法来揭示词汇间的语义关联,形成了丰富的研究成果。本文对当前的词汇相似度研究现状进行了深入的分析和总结,阐述了研究的最新进展,并指明了未来的发展方向。
2 词汇相似度计算
在讨论词汇相似度算法前,首先需要明确词汇距离、词汇相似度和词汇相关度之间的区别和联系。词汇距离与词汇相似度之间有着密切的联系,它们是词汇间相同关系特征的不同表示形式。从数学的角度看,两者成反比关系,词汇间距离越大,相似度越小。在很多情况下,直接计算词汇相似度比较困难,可以通过先计算词汇距离,再转化为词汇相似度[ 2]。而词汇相似度与词汇相关度既相互区别又紧密联系,词汇相关度的含义比词汇相似度更广泛,它是词汇间的包含关系、反义关系、功能关系和其他非典型关系的度量,但是由于本文中的词汇相关度主要反映的是词汇间的相似关系,故不对词汇相似度和词汇相关度作区分。
目前,词汇相似度计算方法大体可以分为没有背景信息和有背景信息的方法,这里的“背景信息”是指能够反映词汇语义的背景知识,主要包括语料库、语义词典和维基百科。
2.1 没有背景信息的方法
总结现有的词汇相似度计算方法,最简单的是基于词汇字面匹配的方法,如编辑距离法[ 3]、字符串匹配法[ 4]、压缩距离法[ 5]。其中,编辑距离法用两个字符串由一个转成另一个所需的最少编辑操作代价来衡量词汇相似度,这里的编辑操作包括替换、插入和删除。字符串匹配法以字符串字面匹配的程度来衡量词汇的相似度,例如单词“manage”和“management”前6个字母完全相同,即字面上相似,所以认为这两个词汇是相似的。压缩距离法将词汇用二进制编码表示,然后根据二进制编码的柯氏复杂度(Kolmogorov Complexity)计算词汇相似度。
基于词汇字面匹配的方法认为词汇之间相互独立,从词汇字面匹配的层面计算词汇相似度。但是,许多语义上相似的词汇在字面上并不相似,用基于词汇字面匹配的方法无法正确计算它们的相似度,例如“soccer”和“football”。所以,又有研究者在不利用任何背景信息的情况下,提出基于搜索引擎的词汇相似度算法[ 6, 7, 8]。基于搜索引擎的方法主要利用搜索引擎内部的匹配算法,将匹配的结果作为衡量词汇相似度的标准,实现了任意两个词的相似度计算。其中以标准化谷歌距离(Normalized Google Distance, NGD)[ 7]最为典型,如下所示:
NGD(x,y)= 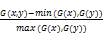
=
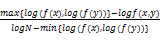 | (1) |
其中,f(x)、f(y)表示在Google中分别输入词汇x和y时返回的记录数;f(x,y)表示在Google中输入词组(x,y)(两个词的组配)时返回的记录数;N的任何取值只要大于f(x)都可以作为标准化因子,N可以取Google索引的网页数。
没有背景信息的方法虽然能在一定程度上反映词汇间的相似度,但缺乏背景信息的判断容易脱离词汇的含义而造成判断的偏离和不准确。于是,考虑到词汇之间是相互关联的,而非相互独立的,研究者假设:如果词汇的语义越相近,那么它们所在的上下文也应该越相似,进而提出借助语料库这一背景信息帮助计算词汇相似度的方法。
2.2 基于语料库的方法
语料库是人们针对某一特定领域收集和整理的该领域大量文档的集合。从事先建立的语料库中可以学习词汇在上下文中与其他词汇共现的信息,因为词汇之间是相互关联的,这些上下文中的词汇可以反映出词汇本身的含义,所以可以利用语料库来帮助计算词汇相似度。
在基于语料库的词汇相似度算法中,Salton等[ 9]提出的词包方法(Bag of Words)起了非常重要的作用。词包方法认为词汇的上下文中总是包含与该词汇语义相关的词,所以将词汇上下文中其他词汇的概率分布表示成词汇语境向量,然后计算两个向量的夹角余弦值作为词汇的相似度。但由于词汇的上下文中包含许多与该词汇没有语义关系的词汇,所以用单纯的统计方法构成的词汇语境向量比较稀疏。于是,研究者提出不同的降维方法改进词包方法[ 10, 11, 12, 13, 14]。其中,以Deerwester等[ 10]提出的潜在语义分析法(Latent Semantic Analysis,LSA)影响最为深远。LSA方法首先将词汇和文档表示成词汇-文档矩阵,然后通过对词汇-文档矩阵进行奇异值分解(Singular Value Decomposition,SVD)生成一个只包含若干正交因子的降秩空间。该空间与原始的词汇-文档矩阵所体现的语义信息是一致的,反映出文档集中的主要相关词汇信息,同时剔除了其中因具体用词变化带来的噪音。
词汇所在的上下文虽然能在一定程度上反映词汇的语义,但基于语料库的方法依赖于训练所用的语料库,且只能通过一定的方法减小部分系统系数和数据噪音的干扰,而无法完全消除,计算过程中仍会出现明显的错误。所以,研究者希望借助更加规范、更加专注于体现词汇语义的背景信息进行词汇相似度计算。
2.3 基于词典的方法
语义词典规范地描述了词汇之间的上下位关系、同义关系、反义关系,因此成为词汇相似度计算的重要依据。目前常用的英文语义词典有Roget’s同义词辞典[ 15]、WordNet[ 16]等,常用的中文语义词典有《同义词词林》[ 17]、《知网》(HowNet)[ 18]、《中文概念词典》[ 19]等。
基于词典的方法主要根据词典中词汇的上下位关系、同义关系和反义关系进行词汇相似度计算。在根据词汇的上下位关系进行计算时,将词汇组织成具有层级结构的树形图,然后根据树形图中的不同要素(如节点间的路径长度、局部网络密度、节点在树形图中的深度、节点包含的信息量)进行相应的计算。在根据词汇的同义关系、反义关系进行计算时,将词汇的反义词或同义词作为词汇的特征项来帮助计算词汇相似度。基于词典的方法进一步可分为三大类:基于路径的方法、基于信息量的方法和基于特征的方法。
(1)基于路径的方法:Rada等[ 20]、Wu等[ 21]、Hirst等[ 22]、Leacock等[ 23]、Resnik[ 24]根据最短路径、树形图的最大深度、最短路径改变方向的次数或最小公共父节点的深度提出了不同的词汇相似度算法。王斌[ 25]、刘群等[ 2]、Li 等[ 26]基于《知网》中根据义原上下位关系构成的层次树,提出各种基于路径的词汇相似度算法。
(2)基于信息量的方法:信息量是指树形图中两个概念的最小公共父节点出现的概率的对数的相反数(见公式2)。从词汇在树形图中包含的信息量出发,Resnik[ 27]、Jiang等[ 28]、Lin[ 29]提出不同的词汇相似度算法,并表现出较好的计算效果,成为基于词典的词汇相似度算法的主流方法。
IC(msc(c1,c2))=-log(P(msc(c1,c2)))(2)
其中,msc(c1,c2)表示概念(c1,c2)的最小公共父节点。
(3)基于特征的方法:从词汇的特征出发,荀恩东等[ 30]利用WordNet中的同义关系、Zhang等[ 31]利用概念节点的祖先节点的交集和并集、江敏等[ 32]利用《知网》中义原的深度信息和反义定义信息等计算词汇相似度。
语义词典提供了更加规范、专注的词汇语义信息,但是也存在更新速度慢、覆盖的词汇范围有限(不含专有名称、新词、俚语等)等局限性。由于语义词典的局限性,研究者将目光投向了一种全新的包含丰富词汇语义信息的知识库——维基百科。
2.4 基于维基百科的方法
维基百科[ 33]是一种基于Web2.0、由非专业志愿者协作完成的合作型知识库。维基百科中的每篇文章关于一个主题,主题用一个简明的短语(词条)表示,包含该词条丰富的语义解释;维基百科的文章之间通过内容中的超链接相互链接,构成词条关联网络;维基百科还对每篇文章进行分类,每篇文章至少属于一个维基类别,包含词条的上下位关系。可以把维基百科看作含有语义词典功能的大型语料库,基于上述特点,维基百科成为词汇相似度计算新的词汇语义信息的重要来源。
最早利用维基百科计算词汇相似度的是Strube等[ 34]提出的WikiRelate!方法。WikiRelate!方法主要将基于词典的方法移植到根据维基百科上下位关系构成的树形图中,虽然这种方法的计算效果一般,但它首次以维基百科为背景信息,为词汇相似度研究提供了新思路。随后,Gabrilovich等[ 35]提出了基于维基百科文章内容的显性语义分析法(Explicit Semantic Analysis,ESA)。ESA方法通过机器学习建立语义翻译器,将自然语言文本片段或词汇映射到一系列加权的维基百科概念上,即用加权的维基百科概念向量表示文本片段或词,然后计算向量的夹角余弦值得到词汇的相似度(见公式3),取得了较好的计算效果。
wi={ki1,ki2,……,kij} kij=tf(wi,cj)×log 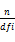
SrE&E(w1,w2)=
 | (3) |
其中,kij表示词汇wi在概念ci(词条ci)对应的文章中的权重, tf(wi,cj)表示词wi在概念cj对应的文章中出现的次数,dfi表示词wi出现过的文章数,n表示维基百科中所有的文章数。
由于ESA方法需要建立概念词汇映射,而维基百科中的文章数目庞大,工作量相对较大。于是,Milne等[ 36]提出只利用维基百科中链接结构的词汇相似度算法(Wikipedia Link Measure,WLM),WLM方法相对于ESA方法减少了计算量,但其计算效果不如ESA方法。
以ESA方法为代表的基于维基百科的词汇相似度算法在词汇相似度领域取得了迄今为止最精确的结果,成为了词汇相似度研究领域的主流方法,得到了极其广泛的应用[ 37, 38, 39, 40, 41, 42, 43, 44]。
笔者对没有背景信息和有背景信息的经典词汇相似度算法进行了总结,如表1所示:
| 表1 经典词汇相似度算法 |
近年来,许多研究者也提出了融合性的算法[ 45, 46, 47, 48, 49]。例如Li等[ 45]提出一种多元信息资源法,该方法融合WordNet和Brown Corpus,并以WordNet为主要语义信息来源,Brown Corpus为辅助语义信息来源,基于假设即最短路径、深度、密度相互独立,综合考虑词汇在层次树中的最短路径、深度、在语料库中的密度三大因素,以获得更优的计算效果。
为了对词汇相似度计算方法进行客观评价,研究者提出了不同的评价方法,主要有以下三种:
(1)从理论上检查一个方法是否具备完备的数学特征[ 22],比如检查它能否作为一个指标,指标是否是奇偶的,参数投影是否为平滑函数等。
(2)与人类的判断进行比较的方法,即通过设计心理语言学实验来对词汇相似度进行标注,获得词汇相似度的“黄金标准”,然后计算人类判断与相应词汇相似度算法的斯皮尔曼相关系数(Spearman Correlation Coefficient,CC)。目前的“黄金标准”主要包括数据集:Rubenstein and Goodenough(R&G)[ 50]、Miller and Charles(M&C)[ 51]和Word Similarity 353 Test Collection(WS)[ 52]。这种评价方法主要用于有背景信息的词汇相似度算法评价。
(3)根据在特定应用中的表现来评估各种方法,在相同条件下,比较不同算法的应用效果,如拼写错误纠正系统[ 53]。这种评价方法主要用于没有背景信息的计算方法。
由于使用第三种评价方法时,不同词汇相似度计算方法选择不同的特定应用,较难对这些评价进行统一的比较,所以本文主要对比以黄金标准为参照进行评价的计算效果,基于语料库、基于词典、基于维基百科以及融合方法的计算结果与黄金标准(M&C、R&G、WS)的相关系数如表2所示:
| 表2 有背景信息的词汇相似度算法与“黄金标准”的斯皮尔曼相关系数 |
相关系数越高,计算结果越好。从表2可以看出,在较小规模的标准数据集(M&C和R&G)中,基于词典的方法取得了较好的计算效果,总体效果比基于维基百科的方法好,特别是Leacock等[ 23]的基于信息量的方法;而在较大规模的标准数据集(WS)中,基于维基百科的方法取得了优于基于语料库和基于词典方法的实验效果,其中,以ESA方法的计算效果最为突出。此外,融合多元信息资源的方法与M&C的相关系数高于基于词典的方法。
以上总结的词汇相似度计算方法主要是针对英语词汇,绝大多数方法在中文词汇相似度计算中同样适用。在没有背景的计算方式中除了象形系的中文不利于进行字面词汇相似度的匹配之外,基于搜索引擎的方法同样适用于中文。而有背景的计算方法均可以获得相应的汉语背景信息,如现代汉语语料库、CCL语料库、知网(HowNet)、中文概念词典、中文维基百科、百度百科等,用于中文词汇相似度计算。
3 基于维基百科方法的研究进展
近年来,许多研究人员在基于维基百科的方法基础上,提出了不同的改进策略,获得了更好的测试效果。例如融合维基百科内各种语义信息的维基游走法、融合词典和维基百科的内涵概念图法、融合语料库和维基百科的时间语义分析法。
3.1 维基游走法
Yeh等[ 46]提出一种基于维基百科链接和文章内容的词汇相似度算法——WikiWalk(维基游走法)。该方法以维基百科中的词条为节点、文章间的链接为边从维基百科中抽取出网络图,然后用Personalized PageRank算法[ 47]分别构建两个词汇的转移向量(Teleport Vector),最后计算向量的夹角余弦值作为词汇相似度。
WikiWalk方法的关键在于网络图的抽取和词汇转移向量的构建。网络图的抽取主要利用维基百科中丰富的链接信息,将链接细化为Infobox Links、Categorical Links和Content Links,在抽取节点过程中可以根据含义的广泛程度剔除一部分词条以控制网络图的规模。而词汇转移向量是指Personalized PageRank时构成的与该词汇相关词汇的稳定分布(Stationary Distribution),转移向量构建的难点在于分布的初始化。文中提出了基于词典的初始化方法和基于ESA的初始化方法。其中,基于词典的初始化方法直接将文章主题或文章内容中的锚文本作为词汇的初始向量,而基于ESA的初始化方法建立在ESA方法基础上,且只取词汇概念向量中的前n个概念作为词汇的初始向量。
WikiWalk方法利用维基百科的文章内容和文章之间的链接获取能够反映词汇语义的相关词汇,并且在网络图的基础上,融合Personalized PageRank和TF-IDF计算权重,比只基于文章内容的ESA方法和只基于文章之间链接的WLM方法获取了更全面的词汇语义,在文档相似度计算的应用中实验效果(CC=0.772)优于ESA(CC=0.72),取得了基于维基百科词汇相似度算法的新发展。
3.2 内涵概念图法
何夏燕[ 48]提出一种基于中文内涵概念图的汉语词汇语义相似度算法。内涵概念图法从语义词典和网络资源中获取词汇的释义项,并将释义项表示为内涵概念图,然后计算内涵概念图的相似度作为词汇相似度。该方法主要分为三个步骤:
(1)内涵概念图标引。通过语义词典(知网)和网络资源(百度百科、维基词典)获取概念的释义项,然后人工对词汇本身和释义项进行分析,抽取显著的必要属性作为构建内涵概念图框架的元素。这里的内涵概念图由一系列表示属性值的节点以有向弧相连而成,属性名本身不作为内涵概念图的节点,只标注在有向弧上。
(2)生成词汇的内涵概念图。对于每个词汇,获取词汇的释义项后对其进行句法、语法分析,抽取出词汇的属性值,填充到内涵概念图框架中,构成词汇的内涵概念图。
(3)计算内涵概念图相似度。对于两个词汇w1,w2,分别得到它们的释义词汇集合Sw1,Sw2。释义词汇集合的构建是一个迭代的过程,对Sw1,Sw2中的每个词汇用词典释义展开,获得的新词汇加入到Sw1,Sw2中。迭代过程中引入义原进行考量,如果已经符合义原标准则不再展开,否则需要根据对应的释义项再次迭代展开。迭代完成后,将获得的词汇集合转化为相应的释义项集合Kw1,Kw2,集合中每个词构成向量V1,V2的一维,权值用TF-IDF来计算,TF是一个词与当前释义项的相关程度,IDF是对应于一个词在所有释义项中出现的次数,求两个向量之间的距离作为词汇相似度,如下所示:
Dis(Kw1,Kw2)=cos(Kw1,Kw2)=
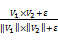 | (4) |
其中,ε为一个平滑参数。
内涵概念图法主要根据反映词汇内涵的释义项计算词汇相似度,虽然一句话中可以包含的含义有限,但具有概括性的释义项还是能在一定程度上反映词汇的语义,且将释义项表示成内涵概念图,然后计算内涵概念图相似度的方法为词汇相似度计算提供了新思路,实验结果也表明了内涵概念图法的有效性(与M&C的相关系数CC=0.68-0.71)。
3.3 时间语义分析法
Radinsky等[ 49]提出一种基于语料库和合作型世界知识库的词汇相似度算法——时间语义分析法(Temporal Semantic Analysis, TSA)。该方法基于假设:语义相关的词汇在时间上的表现(出现、使用或消失)是相似的,结合体现词汇随时间动态变化的语料库和体现词汇静态语义关联的世界知识进行词汇相似度计算。TSA方法主要包括三个步骤:
(1)将两个词汇分别表示成加权的概念向量。其中,概念的选取主要利用合作型世界知识库,如维基百科中的概念、Flickr中的图像标签和Delicious中的书签,而相应的权值计算主要基于TF-IDF算法。
(2)获取两个概念向量中每个概念的时间序列。概念的时间序列表示词汇在大型语料库中随时间产生、出现、消失的统计数据(见公式5),选取了《New York Times》从1863年到2004年间的文章摘要作为语料库。
T(c)=( 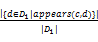
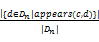
其中,d表示文档,这里指文章摘要;Di表示时间点i的文档集合,这里选取天作为时间点;|Di|表示Di中的文档数。
(3)将词汇的静态表示转化为动态表示,计算词汇的相似度。静态表示指词汇的概念向量,动态表示指概念的时间序列,所以词汇最终表示为加权的概念时间序列。然后计算两个词汇对应的概念时间序列的相似度,作为词汇相似度。时间序列相似度计算方法给出两种备选方法,即相关系数法(Cross Correlation)和动态时间规整法(Dynamic Time Warping, DTW),但在实验中主要使用的是相关系数法。相关系数法是一种计算两个随机数列相关性的方法(见公式6),用相关系数法可以计算出词汇的时间序列的相关性。
corr(X,Y)= 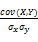
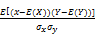
=
 | (6) |
TSA方法从语料库中挖掘反映词汇随时间变化的动态相似性,结合维基百科文章内容中反映的词汇静态相似性,试图从与以往词汇相似度算法不同的角度揭示词汇间的语义关系。通过实验表明,TSA方法取得了优于ESA方法的计算效果(与WS的相关系数CC=0.8),尤其是在计算同义词、词组的相似度时,TSA方法更加接近人类对词汇相关度的判断。
4 结语
词汇相似度研究作为自然语言处理中一项极为重要的基础性研究,被广泛地应用于情报学领域和计算机领域。从最初的基于词汇字面匹配的方法到利用各种背景信息,包括语料库、语义词典和维基百科来帮助进行词汇相似度计算,词汇相似度研究始终围绕着词汇相似度的本质——词汇语义相似度和如何更好地揭示词汇间的语义关系展开。
近几年,由于维基百科能够提供丰富的语义信息,使得大量的研究者围绕维基百科展开了各种词汇相似度计算方法的研究,从较新的基于维基百科的词汇相似度研究中可以看出:
(1)有机地融合维基百科和其他背景信息(如语料库、词典),能够使各种词汇语义信息来源优势互补,取得更好的实验效果。所以,通过融合的方法得到从不同的角度和层面充分揭示词汇间语义关系的背景信息将成为词汇相似度研究今后的发展趋势。
(2)从丰富的背景信息中抽取词汇之间的共词网络为词汇相似度计算提供新的角度,而现有的综合利用维基百科和共词网络的研究还较少,所以,运用复杂网络的分析方法来挖掘词汇网络中词汇的相关性将会是词汇相似度研究的又一发展方向。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|