



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
专利信息的技术功效与应用图挖掘研究*
引用本文
翟东升, 陈晨, 张杰, 黄鲁成, 阮平南. 专利信息的技术功效与应用图挖掘研究* . 现代图书情报技术, 2012, 28(7): 96-102
Zhai Dongsheng, Chen Chen, Zhang Jie, Huang Lucheng, Ruan Pingnan. The Mining Research of Technical Efficiency and Application Map of Patent Information. 现代图书情报技术, 2012, 28(7): 96-102
Permissions
Zhai Dongsheng, Chen Chen, Zhang Jie, Huang Lucheng, Ruan Pingnan. The Mining Research of Technical Efficiency and Application Map of Patent Information. 现代图书情报技术, 2012, 28(7): 96-102
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
专利信息的技术功效与应用图挖掘研究*
摘要
目前,专利技术功效图与技术应用图的构造方法主要通过专家或学者的主观判断来对技术、功效或应用进行分类,因此比较耗费人力,结果也不够全面。针对以上问题,提出一种基于文本挖掘的、相对客观的解决方案,首先对专利信息进行文本挖掘并从中提取专利文献中涉及的技术、应用和功效,再由专家对文本挖掘后的结果进行评估以确定较全面、准确的技术、功效、应用的特征,得到的特征将能直接用于统计其对应包含文献数量并最终构造技术功效图与技术应用图。实验结果表明,得到的技术功效等特征比专家预想的特征更全面、准确,技术功效图与技术应用图更加完整。
关键词:
专利信息; 文本挖掘; 技术功效矩阵图; 技术应用矩阵图
中图分类号:G255.53
The Mining Research of Technical Efficiency and Application Map of Patent Information
Abstract
Currently, the research of patent technology effect matrix and technology application map is primarily depend on the judgement of experts in classification of technology, effect and application terms, which requires many labors and the result seems to be not comprehensive. Therefore,the paper proposes a relatively objective solution based on text mining. This solution mainly focuses on the extraction of patent information about technology, effect and application terms, and then the experts make decisions based on the results of extraction to define the relatively comprehensive and accurate terms. With these terms, the maps by calculating the numbers of terms and the times of occurrences among them can be built. Experimental results show that the finally statistics are more comprehensive relative to experts’ ways.
Keyword:
Patent information; Text mining; Technical-efficiency matrix; Technology-application matrix
1 引言
Ernst提出了使用专利信息作为技术管理的一项创新度量的抽象性框架。专利是创造性过程的直接输出,而且由于一项发明生效必须由政府审核,所以专利是一种客观标准。基于专利方面的专利地图研究已经如火如荼,然而专利地图中专利技术功效图与技术应用图的研究少有涉足,大部分研究的重点在于专利管理地图和专利引证图分析[ 1]。而且专利技术功效图与技术应用图的分析方法过于单一,工作量庞大,效率低下,分析工具不多[ 2]。
将文本挖掘应用于庞大的非结构化的HTML格式的专利信息后如何提取出对应主题的特征成为当前亟需解决的问题。国外在文本挖掘方面的研究起步较早而且对专利信息分析有很高的重视[ 3],Jun等[ 4]通过文本挖掘做
过技术预测,他们构造的专利地图是通过聚类技术和管理问题构建的矩阵来实现技术预测,该矩阵与技术功效矩阵有相似点,但并没有详细介绍文本挖掘获取关键词的方法。Cheng[ 5]讲到了不依赖专家来建立技术功效矩阵,然而他构建的源于美国专利数据库的技术特征词并非通过文本挖掘得到,而只是通过国际专利分类号(International Patent Classification, IPC)的分类来粗略划分,这样无法定位到专利内容中涉及到的技术特征词,因此容易遗漏某些技术。Tseng等[ 6]较早着手将文本挖掘用于专利地图的分析,涉及更多更详细的文本挖掘的操作,如特征提取,并提出多项模型用于专利地图的分析,而且通过对技术、功效进行手动分类从而简单建立了技术功效矩阵。另外日本的Nanba等[ 7]提到了抽取专利文献中的技术及其功效,但其作为数据源的专利文献是半结构化的XML格式的,而且所用专利数据库并非世界范围内的,因此抽取十分方便。在国内,罗立国[ 8]利用专利地图画出了技术功效图,他对检索得到的30 件专利进行加工、整理和分类,根据4个技术主题、5个发明目的、按3年为一个时间跨度进行统计,得到技术功效图。后来潘雄锋等[ 9]研究的技术功效图仅统计了某个功效方面的专利件数,但没有把技术参考进去。
本文使用的专利数据是源于德温特专利数据库,该专利数据库经过人工整理后变得更加结构化,国内最近已经有人将该结构理论化,陈颖等[ 10]提出的技术功效词识别方法理论部分就是基于德温特专利数据库,并对摘要的结构做了较详细的分析,但并没有提出实际的操作方法和应用实效,而且算法并没有提供实际的工具或软件进行实证研究。从方法所使用的辅助软件或工具来看,本文使用的是IBM数据挖掘软件Clementine中的一个文本挖掘插件,该插件强大的分词功能使用户能自由配置语句中词语的构成,例如需要抽取形容词短语结构multi-technology automated reader,只需要在抽取前配置dynamic part-of-speech extraction patterns中加上apam,其中a表示形容词,p表示过去分词,m表示名词或词性不明的词语。显然这个功能对于抽取技术功效特征词具有巨大的支撑作用,再配合其文本链接分析(TLA)功能,就更能保证抽取的特征词全面而准确。理论方面,本文在专利组件识别方面,通过对文本挖掘得到的句式进行语义和语境层面上的分析,识别了大部分的应用特征词和功效词在句子中出现的位置,从而为更准确地获取特征词提供了保障。
以上国内外对技术功效图与技术应用图中的技术特征(如功效、应用等)的收集方法大多数采用的是专家或学者自己的主观经验分类,然后构建技术功效矩阵,因此比较主观。在数据量极大的时候对其进行整理分类将耗费大量时间和精力,而且还无法保证特征准确和全面。因此,本文提出通过文本挖掘的手段获取特征词,从而半自动地构建技术、应用、功效矩阵。
2 基于文本挖掘研究方案的设计
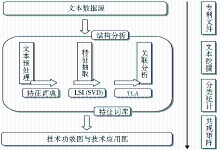
本文主要采取文本挖掘技术,不仅可以弥补专家主观分类过程中容易遗失专利中的某些技术特征的缺陷,同时还可以大量减少专家的数量及工作量。主要研究方案如图1所示:
 | 图1 研究方案的设计 |
3 文本特征数据源分析
本文选择基于HTML结构方式的抽取方法[ 11],即清洗和净化页面,去除无用内容,修正错误标签,规范格式,根据专利DOM节点位置和关键字信息制定抽取规则,因此首先需要对文本特征进行分析。
3.1 专利数据源内容结构分析
首先分析德温特专利数据库专利文献中用于文本挖掘的摘要信息结构。将部分检索结果直接导出用于程序抽取的HTML可得其结构如图2所示。
其中,“AB”部分表示摘要,是主要的非结构化的文本源,另外摘要内容中“USE”表示应用,“ADVANTAGE”表示功效,“TF”表示关键技术。本文将建立用
AB NOVELTY - The system has a service server (30) connected with a home multimedia center (HMC)……
USE - Web storage service system.
ADVANTAGE - The system reduces storage construction costs of a web service provider, and enables a client to use the web storage service at a low cost by utilizing home multimedia center (HMC) of a subscriber without installing the storage medium of a web storage service provider.……
TF TECHNOLOGY FOCUS - INDUSTRIAL STANDARDS - The personal video recorder provides a tuner, a MPEG encoder, a MPEG decoder, a hard disk drive, switching unit, an Internet protocol communication unit.
 | 图2 Derwent专利文本的形式 |
于存储某个专利号中技术、应用、功效三方面数据的关系数据表,再将该数据表导成Excel格式的数据源,用于后期的文本挖掘。
3.2 专利数据源网页结构分析AB NOVELTY - The method involves……. USE - Method ADVANTAGE - The method ensures…… TF TECHNOLOGY FOCUS - The communication system …… AB 开头,以表格标签TF 结尾,根据此特点即可利用PHP程序的正则表达式来建立数据的抽取规则。如抽取摘要(AB)特征文本的正则表达式如下:AB <\/B><\/td>\n (.*)\n<\/td>/",﹩patent,﹩ab);
在数据抽取过程中,明确了抽取什么样的数据后,就需要对数据的原始内容即网页结构进行分析,找出所需要的HTML文本结构,如下所示:
通过对以上HTML结构的文本进行分析可知,AB字段包括的文本主要由表格标签
preg_match("/
4 文本特征的获取与建模
早期的信息抽取(Information Extraction)主要采用自然语言处理库将句子中的不同词性的词语进行标注(Part of Speech)从而提取信息,最典型的是ClearForest提出的基于规则的声明性的语言(DIAL)[ 12]。本文使用文本链接分析将所有词通过模式分析进行更明确的词语类型标注。
4.1 基于文本链接分析的特征词提取
为了进一步准确获取特征词语,利用文本链接分析对词语间的关系进行抽取,并利用语境分析进行词语关系定位来协助关系的抽取。首先需要对所有抽取出来的词语进行文本分类,其中核心词典分类有以下几种:
#Core Library
Location=L,Location,0
Organization=O,Organization,0
Unknown=U,Unknown,1
分析部分摘要文本可知,关于“应用”类词语语句模式主要有以下几种:
A used for B
A used as B
Method for doing something
Method of something
而“应用”类词语与其他词语之间的联系主要为:such as A、e.g A/B/C等。
以上语句后的词语(A、B、C)基本上都是关于“应用”类的特征词,因此,只需要将描述的A与B用已经标记的文本分类(如U)代替并构造出检索模式语句即可抽取出所需要的文本特征词。利用文本链接分析模块,构造如图3所示的两种模式即可用于应用类的文本特征抽取,其中[pattern(0001)]与[pattern(0002)]即是抽取模式的最终表达式。
 | 图3 文本抽取模式 |
4.2 特征选择、抽取与建模
特征词在通过模式获取后需要将其导出用于技术功效与应用图的绘制。本文选择文档频率法(Document Frequency, DF)作为主要的特征选择与降维的方法,它是一种最为简单的特征选择算法,指的是在整个文本集中有多少文本包含这个词语。文档频率法基于假设:对一个类来说,出现次数过少的词语是没有意义的,它们的删除对分类结果不仅不会造成不利的影响,相反可能还会有所提高,特别是那些稀有的词语刚好是噪声词时。文档频率法最大的优点就是速度快,它的时间复杂度跟文档规模成线性关系,非常适合超大规模的文档集的特征选择。
在特征抽取方法选择中,潜在语义索引(Latent Semantic Index,LSI)是一种用于知识获取和展示的计算理论和方法,用于发现文本中的语义关系。在LSI模型中,一个文档库可以表示为一个m×n的词文档矩阵A。这里n表示文档库中的文档数,m表示文档库中包含的所有不同的词的个数,A表示为A=[aij][ 13],在此矩阵中,aij为非负值,表示第i个词在第j个文档中出现的频度。
本文先通过DF特征选择方法得到初步特征词后,即可将其导出到文件中,再设计简单的PHP程序,如下所示:
/**
*@param array() ﹩a 特征词
*@param array() ﹩b 原始文本
*@param array() ﹩c 原始文本﹩b中出现的任意特征词﹩a的次数
*/
for (﹩i=0; ﹩i foreach (﹩b as ﹩bk=>﹩bval) { if (strpos(﹩bval, ﹩a[﹩i])!==false) { ﹩c[﹩bk] [﹩i]=substr_count(﹩bval,﹩a[﹩i]); }else{ ﹩c[﹩bk] [﹩i]=0; } } } 由此统计出每一篇文档中某一个特征词出现的次数,即得到矩阵A。接下来便可以使用奇异值分解对特征矩阵A进行降维处理以去除不必要的特征。 数据导出建模主要依赖于数据挖掘的建模方法。通过以上模型将词库导出到Excel中,将已经获取的技术、应用、功效特征词与所得词库进行匹配,即可统计出每个特征词所对应的专利文献数量。
5 实验过程与分析
通过对专利分析来对本文提出的方法进行实现,数据处理语言是PHP,集成开发环境是Zend Studio8.0,文本挖掘软件采用Clementine12,在实验中,采用苹果手机为主题的德温特专利数据库中专利数据为测试数据(本文只适用于德温特专利数据库的专利网页文件)。实验的步骤为:数据准备;对专利文本信息进行词语抽取、句式分析;统计相关的技术特征并绘制技术功效图与技术应用图。
5.1 实验过程
(1)数据准备。首先依据研究目标,通过检索表达式从德温特专利数据库中检索出能匹配检索表达式需求的专利网页,得到1 121项专利,基于检索所得的专利列表页面,通过网站自带的数据导出功能,按每页500条记录导出为HTML网页文件,参照第3节提出的方法,利用PHP程序的正则表达式抽取各网页信息到本地专利数据库。
(2)文本特征抽取。为了得到更加完全的关键词词库以及确保信息的准确性,并减少后期概念关系抽取的冗余数据,提高概念抽取的精确度,需要对文本源进行文本预处理,为此需要对初始的这些专利数据进行再次筛选。本文通过建立同义词词典与停用词词典来完善领域应用词典。具体如下:
①同义词词典的构建。同义词词典参照普林斯顿大学设计的一种基于认知语言学的英语词典WordNet。
②停用词词典的构建。由于专利文本的摘要由通用词汇与专业领域词汇构成,对于之前抽取的概念有些并非是目标领域概念,如概念8%、54%、at、up、to、in等类似的单个词语,并没有实际的意义,将其归为停用词汇,并记录到停用词词典中。
经过合并同义词项、概念过滤处理后抽取的领域文本特征结果组成初始关键词词库,如图4所示:
 | 图4 初始关键词词库 |
可以看到,经过处理后抽取的特征项表述主要有三个指标:Global、Docs、Type。Global表示概念在所有文本中出现的词频,Docs表示出现词概念的文档数目,最右端的Type是针对领域概念的一个类型标注,可用于文本链接分析中模式的构建。有了较准确的关键词词库后需要对关键词的语义和语境进行分析,即参考4.1节提出的方法,结合关键词的含义及其在文本中上下文的关系进行分析,以确定比较固定的文本关系用于文本链接分析,并得到特征关键词词库。
(3)获取特征关键词词库后需要专家参与进行特征评估,筛选出合格的技术特征并剔除不相关的关键词。在专家评估实验得到的特征词之前,首先根据自身经验列出所有手机相关技术、应用和功效的特征关键词,如表1所示:
| 表1 专家列出的技术、应用和功效的特征词 |
对比本文得到的技术、应用、功效特征词,筛选出有实际意义的特征词,并删除无关特征词。
专家对所有技术特征进行归类筛选,如将所有有关“触摸(屏)”应用的特征词归为一类,所有提高效用的效用特征词归为一类等,以便于最后制作出来的技术功效矩阵能比较明确地展示技术的相关特征。
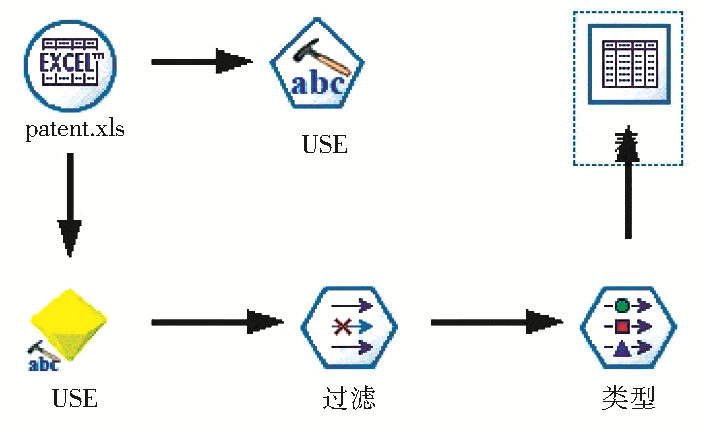 | 图5 文本挖掘关键词导出的数据流 |
(4)统计相关的技术特征并绘制技术功效图与技术应用图,利用数据处理流将筛选后的词库导出到Excel中(如图5所示),并直接用于统计包含各项技术、应用、功效的专利件数,再按照4.2节提出的方法得到功效及应用分类统计(如表2和表3所示),通过Zend Studio集成开发环境设计PHP程序统计特征词的共现次数,得到最终的技术功效矩阵和技术应用矩阵,如表4和表5所示:
| 表2 应用统计表 |
| 表3 功效统计表 |
5.2 实验结果分析
通过实验可以发现,不论是技术特征还是应用与功效特征,其种类分布都相对全面且准确,表2与表3中,甚至有更细的特征分类,比如传统的功效特征主要包括防水、节能等,而通过本文提出的方法得到的功效则更加全面,还包括提供反馈等改善用户体验的功效。总的来说分析如下:
(1)从所得技术功效矩阵的结构和内容来看,包含应用和功效特征词的专利总数分别在总专利数中占据1/2和2/3左右,还有许多可能包括特征词的专利未被已有的抽取模式抽取出来,因为本文只构建了两
| 表4 技术功效矩阵 |
| 表5 技术应用矩阵 |
个常见TLA模式,而其他模式在语境中体现的并不明显,因此可以忽略不计。
(2)从所得技术功效矩阵的现实意义出发,矩阵中标出的深色背景处显示,无线通信技术在提高效益的功效领域中专利申请偏少,而USB和蓝牙技术在人机交互中仍有欠缺;在技术应用矩阵中,无线通信技术和Wi-MAX通信协议很少应用在投影仪等设备中,而USB和蓝牙技术则与触摸的应用很少有挂钩的专利。
6 结语
本文以文本挖掘理论为研究基础,从德温特专利数据库中获取专利到本地数据库,基于本地数据库进行数据抽取,通过专家辅助参与,在进行文本预处理后由TLA方法获得了高质量的技术、应用、功效的特征关键词,并最终用于技术功效图和技术应用图的绘制,从而为技术创新或回避设计以及对自己开发的技术进行侵权判断提供有效支持。在今后的研究工作中,主要围绕如何处理其他异构专利数据库的数据源问题来构建技术功效图与技术应用图,并根据技术功效图的特点,发掘技术发展过程中的空白点,并定位具体的研发位置。本文的不足点在于专利数据的格式限制较严格,这也是出于获取更高精确度特征词的目的。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|