{kind=link}
{kind=link}
复杂网络理论在中文文本特征选择中的应用研究
引用本文
赵辉, 刘怀亮, 范云杰. 复杂网络理论在中文文本特征选择中的应用研究. 现代图书情报技术, 2012, 28(9): 23-28
Zhao Hui, Liu Huailiang, Fan Yunjie. Study on the Application of Complex Network Theory in Chinese Text Feature Selection. 现代图书情报技术, 2012, 28(9): 23-28
Permissions
Zhao Hui, Liu Huailiang, Fan Yunjie. Study on the Application of Complex Network Theory in Chinese Text Feature Selection. 现代图书情报技术, 2012, 28(9): 23-28
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
复杂网络理论在中文文本特征选择中的应用研究
摘要
提出一种基于复杂网络的特征选择方法,通过构建文本加权复杂网络来表示词语间的语义关系及结构信息,综合考虑节点加权度、加权聚集系数、节点介数计算节点特性,利用节点综合特性提取反映文本主题的关键词作为文本的特征词。给出基于复杂网络的中文文本特征选择算法,并对其进行实验验证。结果表明,该特征选择方法较传统方法在文本分类性能上有所提高。
关键词:
复杂网络; 语义相关关系; 节点综合特性; 特征选择
中图分类号:TP391.1
Study on the Application of Complex Network Theory in Chinese Text Feature Selection
Abstract
This paper proposes a feature selection method based on complex network. The weighted complex network of text is built to represent the semantic relations between words and text structure. The weighted degree, weighted clustering coefficient and betweenness are considered in the characteristics calculation of network nodes, the key words which can reflect the theme of the text are selected by the synthetic characteristics of network nodes. A Chinese text feature selection algorithm based on complex network is proposed and verified. The results of experiments show that the method proposed in this paper can get a better effect on the performance of text classification.
Keyword:
Complex network; Semantic relevance relation; Synthetic characteristics of nodes; Feature selection
1 引言
随着互联网信息的快速增长,方便用户快速、准确定位所需信息的文本自动分类技术变得越来越重要。而特征选择作为文本分类的关键环节,其性能直接影响文本分类的效果。
传统的基于向量空间模型的中文文本分类过程中,由于训练集文本数量较多,加之其假设特征词之间是相互独立的,所以容易造成特征空间的高维性和稀疏性,因而影响文本分类的精度和效率。特征选择作为一种主要的降维方法,不仅可以降低特征维数,同时还可以消除特征噪音,从而提高分类处理效率。但是,目前常用的特征选择方法,如文档频率方法(DF)[ 1]、信息增益方法(IG)[ 2]、互信息方法[ 3]、期望交叉熵[ 4]、文本证据权[ 5]、优势率[ 6]
等方法都是基于词频信息或词语与类别间关系的统计信息,忽略了特征项间的语义相关关系[ 1, 2, 3, 4, 5, 6],使得选取的特征词不能完整地表达文本的主题及类别特征,从而造成文本的语义信息缺失,影响特征选择的效果。
自从人们发现自然语言中存在小世界特性以后,越来越多的学者开始研究将复杂网络引入到文本关键词提取中。Huang等[ 7]以词语的句法关系为基础建立文本复杂网络来进行关键词抽取。Liu等[ 8]利用基于知网的词语语义相似度构建中文文本网络进行关键词提取。赵鹏等[ 9]综合考虑文本语言网络中的节点度与聚集系数进行关键词抽取,但是未考虑节点对全局网络的影响。谢凤宏等[ 10]综合考虑加权聚集系数和节点介数进行文本关键词提取,但是忽略了节点度的重要性。韩艳[ 11]将点度中心度与中间中心度线性结合进行关键短语提取,这些利用复杂网络小世界特性进行关键词提取的思想为特征选择提供了新的思路。
此外,也有学者利用复杂网络社区结构特性进行文本特征选择,如Jia[ 12]和郑碎潘[ 13]分别利用复杂网络的社区发现算法来进行特征选择。
本文研究将复杂网络小世界特性理论应用到中文文本特征选择过程中,提出一种新的特征选择算法,与文献[7]和文献[8]有所不同,本文以词语的词共现关系为基础构建文本加权复杂网络,以反映文本中词语间的语义相关关系及词语的上下文结构信息,综合考虑节点度、加权聚集系数、节点介数计算节点特性,以弥补文献[9-11]对节点特性的考虑不足,利用节点综合特性提取反映文本主题的关键词作为文本的特征词,在尽量减少文本语义信息损失的前提下达到有效的特征降维。实验表明,该特征选择方法相较于文档频率、信息增益、互信息等传统特征选择方法能够有效提高文本分类效果。
2 相关理论
2.1 特征选择
特征选择是指在文本预处理之后,在最大程度保留文本信息的基础上,为提高文本类别的区分度和删除噪音的一种降维过程[ 14]。因此特征选择应该选取那些包含语义信息较多、对文本主题内容表示较强的词汇作为文本的特征词,以便提高特征选择的精度。
2.2 加权语言复杂网络及其特性
由于人类语言是一个典型的具有小世界特性的复杂网络[ 15],因此可以利用复杂网络的特性研究语言结构,语言网络通常以字或词作为节点,以它们之间的关系作为连接边,相应的连接关系包括共现关系、概念同义、句法关系等[ 16]。如果将词语间关系的强弱表示为边的权重,此时的网络转变为加权复杂网络,下面给出其重要的统计特性:
(1)加权度[ 17]
节点的度表示该节点与其他节点的连接数目。将其连接边赋予权重后,节点的加权度WDi则可以表示为:
WDi= 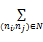
wij表示节点ni与其连接节点nj的边的权值。节点加权度反映了该节点与其他节点的连接强度,体现出节点的中心性。
(2)加权聚集系数[ 17]
在加权复杂网络中,用加权聚集系数可以更加准确地描述节点的聚集情况,节点的加权聚集系数WCi可表示为:
WCi=
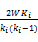 | (2) |
其中,WKi为节点ni邻接节点间边的权重和,称为节点ni的加权聚集度,ki表示节点ni的度数。加权聚集系数可以反映节点的连接强度和密度。
(3)介数[ 18]
节点介数Pi可以反映节点ni在网络全局的影响力,即网络中用来衡量任意两节点间最短路径通过该节点的比例,它可以定量表示为:
Pi=
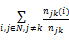 | (3) |
njk表示连接任意节点的最短路径的数量,njk(i)表示最短路径经过节点ni的数量。
3 基于复杂网络的中文文本特征选择
3.1 基本思想
由于文本中的词语之间不是随意组合的,离散的字、词语正是通过一定的语义相关关系组合在一起,才得以形成文本。特别在中文中,丰富的词语语义关系组成了语义丰富的句子、段落、文本等,进而通过文本传递信息。传统的特征选择方法大多基于词频、文档频率等统计信息,而忽略了文本中重要的词语间的语义相关关系。本文提出的基于复杂网络的特征选择方法与传统的特征选择方法最大的不同在于,它在特征选择过程中考虑词语间语义相关关系及上下文结构因素。本文以词语间的词同现关系为基础构建文本加权复杂网络,结合文本网络的小世界特性,利用节点的综合特性进行文本特征选择。首先构建以文本特征词为节点,以特征词间语义相关关系为边,边的权重用相关关系强弱来表示的文本加权复杂网络。为了准确、全面地衡量节点的特性及其对文本主题内容的影响,本文构建了针对中文文本复杂网络的特征评估函数来衡量节点综合特性,然后利用节点综合特性提取反映文本主题的关键词作为文本的特征词。
3.2 中文文本复杂网络模型构建
在进行基于复杂网络的中文文本特征选择之前,需要将文本表示成复杂网络的形式。首先对中文文本进行分词、去停用词等预处理后,得到原始特征集合。
输入:文本集合D={d1,d2,…,dn}。
输出:原始特征项集合T={T1,T2,…,Ti,…,Tn},Ti是文本di被表示成特征词的集合,即Ti={t1i,t2i,…,tmi}。
将原始特征集合转化为复杂网络的形式,本文中的文本复杂网络被表示为加权无向图的形式,将其形式化表示为G=(N,E,W),它们分别对应网络的节点、连接边、边的权重。
输入:文本di对应的特征集合Ti={t1i,t2i,…,tmi},以及对应特征词的词频统计信息。
输出:文本复杂网络Gi={[n1,n2,e12,w12],[n1,n3,e13,w13],…,[ni,nj,eij,wij],…}。
由此可以得到以特征词为节点,以特征词间相关关系为连接边,以其关系强弱为权重的文本加权复杂网络表示模型。
具体的构建方法如下:
(1)在文本预处理的过程中进行句子识别,即以标点符号作为语句的间隔,同时统计相应的词频信息,本文规定共现窗口单元为句子。
(2)为了保留文本的结构信息,同时减少无关干扰信息,本文中特征词在共现窗口的跨度最大值设为2[ 19]。对于文本d对应的特征集合T={t1,t2,…,tm}中的任意两个特征词ti,tj,如果它们同时出现在一个句子中且跨度不大于2,则将其用边连接起来,将对应特征词对转化成[ni,nj,eij,wij]。
(3)本文中节点连接边表示特征词间的语义相关关系,为了衡量其语义相关程度,受共现度[ 20]计算方法启示,将wij定义为如下形式:
wij=
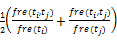 | (4) |
其中,fre(ti,tj)表示特征词ti和tj在文本di同一句子中跨度不大于2时共现的次数,fre(ti)、fre(tj)则表示特征词ti和tj在文本di中出现的总次数。连接边权重wij越大,则特征词间的语义相关关系越密切。
3.3 基于复杂网络的特征选择算法
本文提出的基于复杂网络的中文文本特征选择算法首先通过构建文本加权复杂网络,将文本转化为加权无向图的形式,然后对文本网络中的节点特性进行分析,寻找网络中关键词节点及对文本主题类别贡献大的节点。在加权文本网络的节点特性中,节点的加权度不仅反映出该特征词的连接状况,还可以反映出该词与其他词的连接强度。加权聚集系数反映了特征词在局部的连接密度,体现了其在局部文本中的中心作用。节点介数在一定程度反映了节点在全局的枢纽作用,体现出特征词在整个文本中的连接重要性。为了衡量特征词的综合特性,本文通过构造评估函数来综合考虑加权度、加权聚集系数、节点介数等因素,并选取具有较大函数值的关键词节点作为文本的特征词。
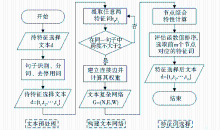
基于复杂网络的特征选择算法流程如图1所示:
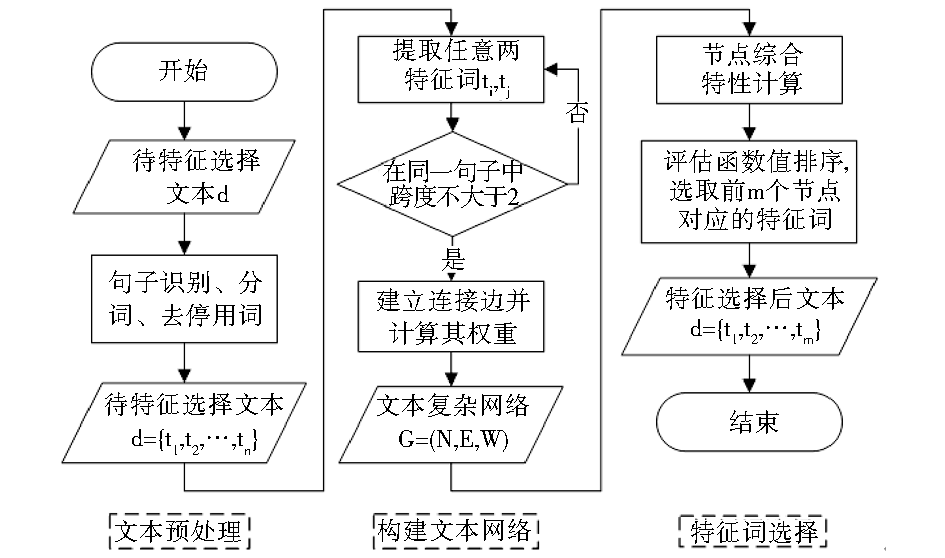 | 图1 基于复杂网络的中文文本特征选择算法流程 |
具体的步骤如下:
(1)对待特征选择的文档d进行预处理,包括句子识别、分词、去停用词等。
对于中文文本,文本预处理是特征选择的基础,经过分词、去停用词可以得到原始的特征集合,但是自然语言的不断变化,尤其是中文不断有新词涌现,分词软件有限的词库使得未登录词大量出现[ 21],为此,本文将维基百科中的词条加入词库,使切分结果更加准确。
(2)将原始特征集合转化为文本加权复杂网络的形式,以特征词为节点、将每个句子中跨度为1、2的词语对作为节点对建立连接边,在遍历各个语句的同时,合并相同节点和连接边,并利用公式(4)计算连接边的权重,去掉网络中的孤立节点。
(3)计算节点的综合特性值以反映特征词的重要性及对主题类别的贡献率,本文构造评估函数CF,以此来衡量节点ni综合特性:
CFi=β1WDi+β2WCi+β3Pi (5)
其中,WDi、WCi、Pi分别为节点ni的加权度、加权聚集系数及节点介数,在计算CFi之前,先分别进行归一化处理,β1+β2+β3=1,βi(1≤i≤3)是可调节的参数,表示相应部分的权重。
(4)利用评估函数对文本复杂网络中的节点进行计算后,可以得到每个特征词对应的函数值。按照函数值大小,将评估函数值CFi进行排序,根据需要,选取CFi值较大的前m个节点对应的特征词作为特征选择的结果。
4 实验
4.1 实验评价标准
由于特征选择的效果直接影响文本分类的效果,所以通过对文本分类的效果进行评价来验证本文提出的特征选择方法,使用宏平均F1值[ 22]来评价分类效果。
4.2 实验及结果分析
本文的实验语料全部来自新华网、凤凰网等抓取的新闻,包括财经类、娱乐类、教育类、体育类、科技类、军事类各500篇,实验中采用5折交叉验证法,将3 000篇文本平均分为5份,1份为测试集,4份为训练集,每份轮流作为测试集循环测试,共5次,取平均值为测试结果。具体的实验过程如下:
实验共分为4组,4组中的特征选择算法分别采用本文提出的基于复杂网络的方法、信息增益法(IG)、文档频率法(DF)及开方检验法(CHI)。每组实验过程中,首先使用中国科学院计算技术研究所的ICTCLAS进行分词,并将维基百科中的词条加入词库,然后进行去停用词处理。
在第一组基于复杂网络的特征选择方法中,利用3.2节所述的方法将文本表示成复杂网络的形式,之后用本文提出的特征选择算法进行特征选择,由于公式(5)中的βi(1≤i≤3)在实验初始时无法确定,因此需要给定初值,通过反复实验才能够确定实验效果较好的参数取值。通过多次实验对比发现,公式(5)中β1取0.4,β2取0.3,β3取0.3时分类效果较好。其他三组分别采用信息增益法、文档频率法及开方检验法进行特征选择。特征选择后,将文本表示成向量的形式。
本文统一采用KNN分类算法进行分类,其中文本相似度计算采用夹角余弦法[ 23]。为了得到最佳的实验效果, 经过反复实验,KNN分类算法中的K取15。实验结果如表1所示:
| 表1 文本分类结果对比 |
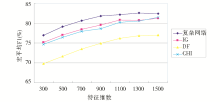
将对比结果绘制成折线图,如图2所示:
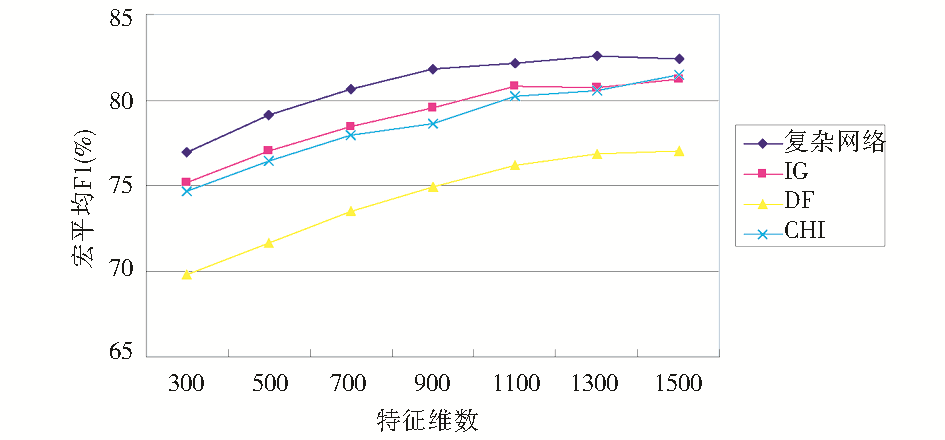 | 图2 不同维数文本分类效果对比 |
由表1、图2可知,本文提出的基于复杂网络的中文文本特征选择算法在分类性能上比传统的信息增益、文档频率及开方检验有所提高。且在特征维数小于1 100时,分类效果随特征维数增大而增长较快,当特征维数大于1 100时,分类效果增长较慢,甚至会随着特征维数的增大,分类效果可能略有下降,这是由于随着特征维数的增大,有更多的噪音及干扰项存在的缘故。
此外βi(1≤i≤3)的确定虽然是多次实验取得的经验数值,其确定有一定的局限性,但是βi全都不为0,表明综合考虑节点加权度、加权聚集系数、节点介数计算节点特性,利用节点综合特性提取反映文本主题的关键词作为文本的特征词可以得到更好的效果。
5 结语
本文针对文档频率方法、信息增益方法、互信息方法等传统特征选择方法忽略词语间语义相关关系的问题,提出一种基于复杂网络的文本特征选择方法,并详细阐述了基于复杂网络的中文文本特征选择的理论基础、基本思想和具体实现算法。该方法通过构建加权文本复杂网络来保留文本结构及词语间的语义相关信息,通过结合复杂网络的小世界特性,利用节点综合特性提取反映文本主题的关键词作为文本的特征词。实验表明,与传统特征选择方法相比,本文提出的方法可有效提高特征选择的效果。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|