
{kind=link}
{kind=link}
{kind=link}
{kind=link}
顶级本体统控的多本体语义标注实证研究
引用本文
米杨, 曹锦丹. 顶级本体统控的多本体语义标注实证研究. 现代图书情报技术, 2012, 28(9): 36-41
Mi Yang, Cao Jindan. A Case Study of Semantic Annotation with Multi-Ontology by Upper-level Ontology Unitive Control. 现代图书情报技术, 2012, 28(9): 36-41
Permissions
Mi Yang, Cao Jindan. A Case Study of Semantic Annotation with Multi-Ontology by Upper-level Ontology Unitive Control. 现代图书情报技术, 2012, 28(9): 36-41
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
顶级本体统控的多本体语义标注实证研究
摘要
以顶级本体作为本体工程的技术核心,通过顶级本体统控领域本体整合、整合本体语义标注等手段,利用Protégé、GATE等工具整合中文鼻部炎症疾病知识本体和国家基本药物知识本体,实现以整合本体标注电子病历信息资源,并保存为XML形式语义标注库。本研究实证顶级本体统控的整合本体语义标注模式,标注后的资源可在语义检索阶段匹配本体元素,进而实现知识发现等语义应用。
关键词:
顶级本体; 本体整合; 语义标注
中图分类号:G250
A Case Study of Semantic Annotation with Multi-Ontology by Upper-level Ontology Unitive Control
Abstract
The paper takes upper-level Ontology as the core technology, integrates domain Ontologies by upper-level Ontology unitive control, and annotates information semantically by integration Ontology with tools like Protégé and GATE for empirical research. It integrates the Nasal Inflammation Disease Ontology and National Essential Drugs Ontology as one Ontology to annotate the Electronic Medical Record information resources, and the semantic annotation library can be saved as XML format. This research provides empirical evidence for semantic annotation schema with integration Ontology using upper-level Ontology unitive control, and the annotated resources can match the Ontology element in semantic retrieval so as to realize the semantic applications like knowledge discovery.
Keyword:
Upper-level Ontology; Ontology integration; Semantic annotation
1 引言
以本体为代表的语义网技术在语义知识组织中具有良好的研究前景。从应用的角度来讲,伴随着网络信息资源的增加,特别是中文自由文本中知识量的迅猛增长,中文知识发现逐渐成为最有潜力的知识工程领域,而语义标注正是进行语义知识发现的基础,语义标注质量直接决定了语义应用的效果。从技术的角度来讲,本体及其相关语义网技术的研究正在日趋成熟,众多的本体项目已经广泛深入到领域应用中,然而多本体的语义异构现象也逐渐突显,在多本体集成研究仍未成熟的情况下,大量的领域本体由于缺乏统一的建模思想和语义约束形成的本体孤岛,正在影响本体技术的规模化应用。
本研究主要以顶级本体作为本体工程的技术核心,围绕顶级本体的语义特性,探索具有统一语义表达方式的
多本体集成的语义标注模式,并通过医学领域研究案例实证语义标注效果,以期研究并解决多本体环境下的知识发现基础性问题。
2 多本体语义标注研究现状
传统的语义标注方式以某个单一本体作为语义标注的本体资源,如AIFB研究所专责发布语义网技术相关研究与开发信息的门户[ 1]中近期出现的一种文档标注和检索工具GoNTogle[ 2]即属此类。
在以多本体为语义标注方式的研究中,英国谢菲尔德大学研发的文本工程通用框架GATE[ 3]可以作为本体标注平台使用,其标注过程虽然支持多个本体应用,但多本体之间没有建立映射关联,无法实现互联互通。此外,由美国国家生物医学本体中心(National Center for Biomedical Ontology, NCBO)研发的用于访问和共享生物医学本体的门户BioPortal[ 4],集成一种基于在线本体库的语义标注体系,主要依托网络本体资源门户聚集相关领域本体,再以多本体为基础进行语义标注,目前包括生物医学各领域本体318个。BioPortal标注器可以在线处理用户提交的文本,使用相应的本体术语进行标注后返回给用户,它支持UMLS语义网络中的百余种标注类型,其本体概念识别器可以匹配最长句或单词,调节最大标注树形类扩展层数,并进行术语映射,BioPortal标注器最多可以标注300个词的文本。其标注术语表包括标注位置、术语、所属本体等信息,标注标签云功能基于MGREP分析出热门词,最后产生的标注文档可以TXT、CSV、XML等形式保存。
近年来,国内基于桥本体互联的多本体语义标注研究也在增加[ 5]。综合来看,语义标注研究以对本体的利用为核心要素,在本体的利用形式上,仍然以单本体的应用为主,在为数不多的多本体匹配语义标注研究中,本体互联主要依据一定的本体映射算法,由于缺乏统一的指导,在领域本体不断增加和进化的背景下,原有本体映射方式的适用性逐渐受到制约,这使得顶级本体的主导作用得以凸显。另一方面,在利用顶级本体进行知识整合的研究中,往往关注的重点在于体系整合[ 6],利用顶级本体整合后的语义标注研究少有实证性成果出现。
3 顶级本体统控的语义标注模型框架
3.1 顶级本体与语义标注
顶级本体(Upper-level Ontology)[ 7]也被称为上层本体或顶层本体,是描述概念之间最普遍联系的知识体系,作为领域本体的参考依据,它揭示了领域知识在更高语义层次上的关系。语义标注[ 8]的重要手段是以形式化知识系统的本体为依托,为信息资源的各个部分标注概念类、概念属性和其他元数据的过程,是语义推理的基础。
利用顶级本体进行语义标注主要是利用顶级本体知识体系特点,指导标注本体库的本体间整合,进而形成具有以顶级本体语义结构形式为基础的统一本体资源,并以整合后的统一本体作为标注本体对语料库进行统一语义标注。
3.2 模型的提出
顶级本体支持多本体语义标注,尚缺乏明确而清晰的研究对其进行说明和阐述。例如,有学者提出基于顶级本体和领域本体的语义标注模型,但并未关注顶级本体和领域本体之间的相互作用机制[ 9]。
顶级本体统控的目的是利用顶级本体语义关系作为通用的知识指导,使顶级本体属性及关系在自顶向下的本体建模思想指导下,可以通过层次扩展的方式建立起具有统一属性框架的语义关系体系,结合概念类与实例的映射,可使多个领域本体整合为统一的整体,具有一致的知识表达方式。依据顶级本体统控的核心思想,可将多本体语义标注过程分为语义建模和语义标注两部分,如图1所示:
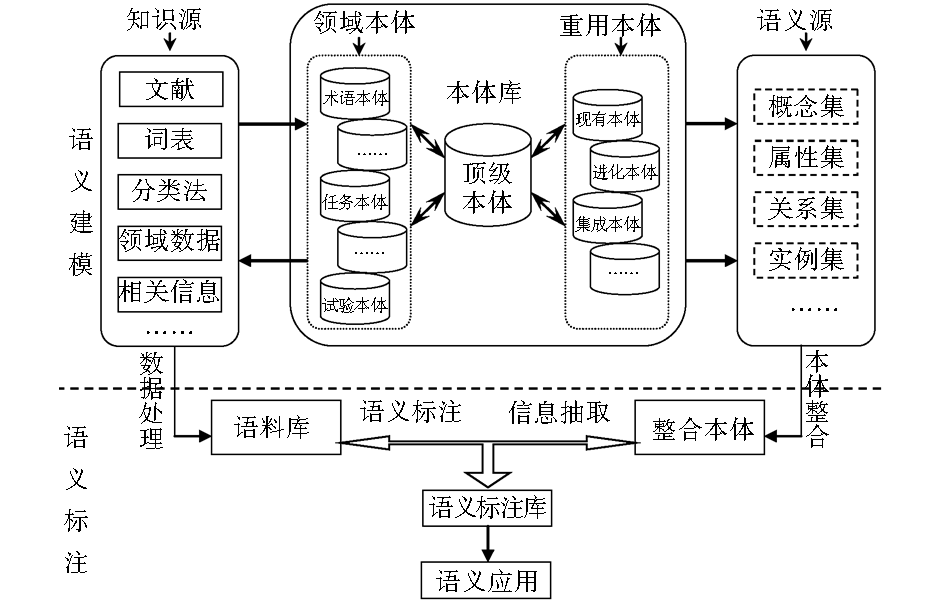 | 图1 顶级本体统控的多本体语义标注模型 |
(1)在语义建模阶段,主要从知识源中选取知识要素构建需要的各种领域本体,并考虑重用相关的现有本体,同时从知识源中采集相关新知识,对本体库中的本体进行进化更新。依据顶级本体的语义关系属性结构对本体库内本体进行必要的整合重构,以形成描述标准统一的语义源。
(2)在语义标注阶段,把需要标注的信息进行数据处理形成语料库,利用语义建模阶段形成的整合本体对语料库进行语义标注,同时将语料库中的知识元素通过信息抽取手段丰富到整合本体中,已标注资源存入语义标注库,以进行知识发现、语义检索等应用。
4 语义建模
4.1 本体库
本体库主要由顶级本体与领域本体构成:
(1)顶级本体选用医学领域应用广泛[ 10]的一体化医学语言系统(Unified Medical Language System,UMLS)中的UMLS语义网络(UMLS Semantic Network)。根据经典的七步法[ 11],重用西班牙海梅一世大学(Universitat Jaume I)TKBG研究组翻译的2007年版UMLS语义网络本体[ 12],同时,本研究依据新版的UMLS语义网络内容[ 13]对其进行版本进化后得到133种语义类型和54条语义关系,本体片断如下所示:
……
>Examples of Metathesaurus concepts: Animals, Laboratory; Animals, Newborn; Animals, Poisonous
>An organism with eukaryotic cells, and lacking stiff cell walls, plastids and photosynthetic pigments.
>Animal
……
(2)领域本体方面,针对信息资源特点,现有疾病本体(如人类疾病本体DOID[ 14])的信息粒度对于某个具体的任务领域而言仍显粗糙,而语义内涵揭示不足以影响语义标注深度;相关的中文本体较为缺乏,不利于中文资源的语义知识发现。综上,结合案例领域特点,本研究基于UMLS语义网络顶级本体的语义关系构建了中文鼻部炎症疾病知识本体和国家基本药物知识本体,作为语义标注实证的本体来源。
4.2 知识源与语义源
知识源是语料库的形成来源,其内容主要来自领域文献、领域词表、领域数据等相关信息资源。本研究选择具有半结构化信息形式的电子病历(即EMR)进行顶级本体统控的语义标注实证探索,资源来自某三级甲等医院随机抽取的若干耳鼻喉头颈外科住院电子病历,该电子病历可以进行有限的自由文本输入,是一种具有代表性的半结构化信息资源。
语义源在这里是由本体互操作得到的元素集,并以此为依据可在语义标注过程中形成整合本体。采用PROMPT组件[ 15]中的AnchorPROMPT功能进行本体映射工作,首先需要对领域本体进行格式调整,以适应PROMPT组件所在的Protégé3环境,再根据AnchorPROMPT的映射步骤[ 16],以鼻部炎症疾病本体作为源本体(即映射主体),国家基本药物本体作为目标本体(即映射对象)开始预映射。经过字符串匹配,共产生10组初始映射建议,撤销其中不符合要求的5组候选,分别是:Acute_Rhinitis和Rhinitis、Chronic_Rhinitis和Rhinitis、Allergic_Rhinitis和Rhinitis、Vasomotor_Rhinitis和Rhinitis、Other_Rhinitis和Rhinitis,将剩下的5组符合映射条件的候选作为锚点进行再处理。采取每次计算一组的方式经过锚遍历匹配后,共产生29组基于锚处理的新候选映射,然而候选映射中只有两组符合映射条件,即Disease和Disease _Type、Sinusitis和Nasosinusitis。最后确定这7组匹配的映射概念,如表1所示。
| 表1 源本体和目标本体映射组 |
5 语义标注
5.1 前期工作
(1)语料库的形成
语料库的形成是一个数据处理过程,主要进行内容的提取与筛选,把取得的信息资源转为可用于语义标注的格式。本研究案例所用的住院病历文件不支持可编辑文档的输出,只能以图片形式保存,因此,要将图像OCR提取为纯文本,提取后的住院病历文本经过错误修正,内容架构包括个人信息、病史、体格检查、专科检查、辅助检查及诊断部分,针对标注资源中患者患有鼻部疾病的特征,将体格检查部分除去,个人信息部分仅保留性别与年龄,其余部分作为语义标注对象。由于提取的资源仍然是以自由文本为主,如果需要借助规则和词典进行自动化标注,还要进行分词处理以便实体识别。此外在实践中,ANSI编码的纯文本可能影响中文词典制订,可以UTF-8或Unicode编码存档。
(2)顶级本体统控的本体整合
根据4.2节的映射结果,以鼻部炎症疾病本体为基础,首先整合已映射的概念类,对于is-a关系的概念,采取插入增项的方式整合到本体中以完善体系。最终,合并概念类33项,其中26项为增项。以概念类“鼻部炎症疾病”为例,其整合前后的父子类关系如图2所示:
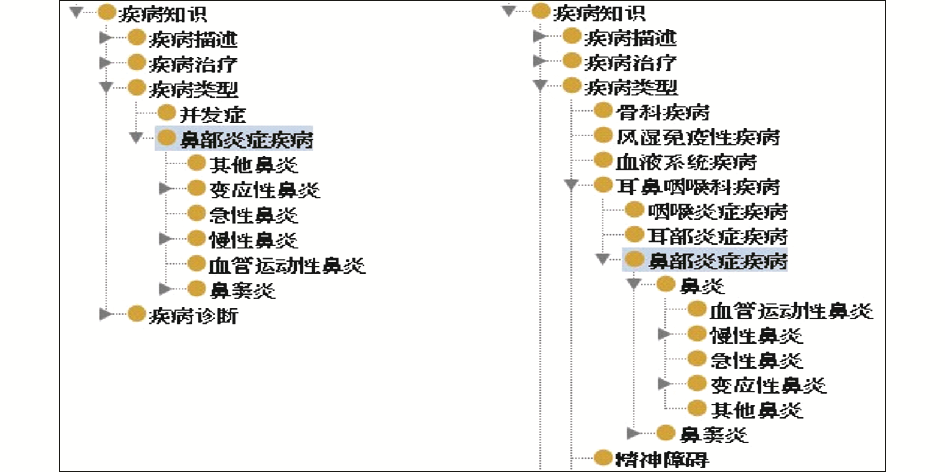 | 图2 整合前后“鼻部炎症疾病”类层次关系变化 |
本研究中,领域本体在构建时采用统一的UMLS语义网络本体的属性框架,因此在属性的整合上,只需合并对象属性即可,数值属性虽然没有统一框架,但由于数值属性本身作用域的限制,可在调整定义域和值域范围后合并到整合本体中,再将属性关联的限制类整合到本体中,最后合并概念所含实例及相关限制。为了保证语义关系完整,可把需要但未能映射的类及关系以新建方式合并到本体。
5.2 利用整合本体标注语料库
本案例标注资源较少,相对而言,自动化标注中的词典设置、规则编写等前期内容将占据标注的大部分工作量,而规则执行次数又难以体现其优势,从而导致标注效率降低。因此,本研究采取直接标注文本的方式对住院病历进行标注。根据得到的整合本体,对匹配概念类、实例、匿名类等元素进行语义标注,其流程如图3所示:
 | 图3 GATE平台本体直接标注文本流程 |
执行该流程,共为资源文本添加29种共45处语义标注,其中概念类标注25种,实例标注3种,匿名类标注2种,如表2所示:
| 表2 本体标注项目 |
本研究运用整合本体直接标注资源的优势在于其标注方式灵活,并且能够确保语义标注准确率,进而充分挖掘资源语义,增强语义标注效果。但随着资源样本的增加,准确率可能在利用规则进行自动化标注时有所下降。经上述过程完成的标注信息将以可视化方式显示在文本资源中,如图4所示:
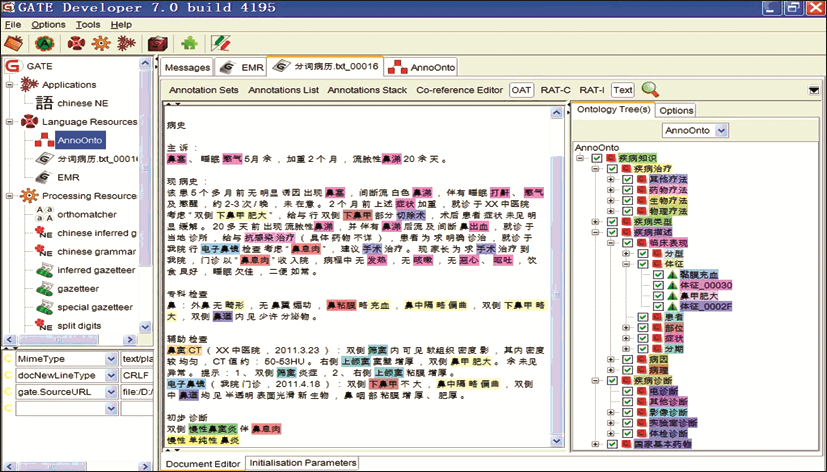 | 图4 基于整合本体的语义标注 |
在标注完成后,可将新的实例信息抽取到本体,即保存在本体类的实例信息中作为新的个体,在下次加载本体时应用,通过这种信息抽取也可以促进本体进化。本研究共实现实例抽取20种,含有语义标注信息的文本资源可以解析为XML文件格式存储,形成语义标注库,代码片段如下:
……
……
5.3 讨论分析
(1)整合本体的语义标注特点
采取映射本体合并的方式整合相关领域本体,其优势是整合本体的语义更加完善,本体对知识具有高度一致的表达,使语义标注具有标注精度高和标注过程灵活的特点。
在语义标注精度上,由于自然语言文本中可能出现各种未登录词,即使是具有一定规范的电子病历内容也不可避免,如“鼻甲肥大”、“鼻甲略大”、“双侧鼻甲肥大”都表示鼻甲肥大的意思,如果据此制订特定词典进行标注,难免出现遗漏,而且由于自由文本具有信息形式不固定的特点,这就对词典的更新和新实例术语的统计抽取提出了较高的要求,现阶段自动化标注技术仍然难以实现人工参与语义标注的高精度。
在语义标注过程中,直接标注方式可以自由选择标注的文本段落及标注形式,不受标注规则与词典内容的制约,标注过程直接面向文本进行基于本体的信息抽取,不必加载另外的规则条件。同时,基于GATE的本体语义标注模式可提供各种标注信息,包括无差别标注集、标注段落、标注列表、按本体元素区分标注、按本体元素隐藏标注等,可以直观地对语义标注结果进行分析与应用。
(2)尚需解决的问题
由于获取的医学领域标注资源数量有限,在语义标注过程中采取更为直接的标注方法,但这种方式不适用于进行大规模语义标注。此外,在GATE引入本体进行直接语义标注的操作过程中,系统对同一术语或短语重叠部分的多元素标注易出现覆盖现象,即后加入标签覆盖了原有标签说明,如文本信息“鼻粘膜略充血”,在标注本体中存在两种匹配:鼻粘膜(概念类)和粘膜充血(个体实例),需要添加两次标签进行二次标注,然而后加入标签经常覆盖了原有标签,使语义标注的完整性降低。
6 结语
本研究所采用的语义标注方法不同于传统的单一本体模型标注系统,并区别于单纯映射的多本体整合模式,采用基于医学领域顶级本体语义结构形式的整合本体标注策略,提出了以顶级本体为整合要素的多本体语义标注模式,并以此为依据进行了医学领域语义标注案例的实证,从而探索基于多本体的语义标注模式新思路,为本体实现语义应用提供参考。经过顶级本体整合的语义标注资源,可在检索应用中对整合本体进行匹配,从而推送更多有价值的知识资源,这是对本研究所做工作应用层次的完善和未来研究的重点。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|