
{kind=link}
融合语义聚类的企业竞争力影响因素分析研究*
引用本文
张玉峰, 何超, 王志芳, 周磊. 融合语义聚类的企业竞争力影响因素分析研究* . 现代图书情报技术, 2012, 28(9): 49-55
Zhang Yufeng, He Chao, Wang Zhifang, Zhou Lei. Research on Enterprise Competitiveness Factor Analysis Combining Semantic Clustering. 现代图书情报技术, 2012, 28(9): 49-55
Permissions
Zhang Yufeng, He Chao, Wang Zhifang, Zhou Lei. Research on Enterprise Competitiveness Factor Analysis Combining Semantic Clustering. 现代图书情报技术, 2012, 28(9): 49-55
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
融合语义聚类的企业竞争力影响因素分析研究*
摘要
将聚类分析融入企业竞争力影响因素挖掘与发现之中,依据本课题组构建的软件企业领域本体,提出基于语义的综合层次聚类分析方法。该方法融合本体与聚类技术创新基于领域本体的聚类分析算法Onto-kmeans,实现语义层面的企业竞争力影响因素分析与获取。实验结果表明,该方法能够显著提高聚类分析的准确率和效率,有效地挖掘与获取影响企业竞争力的全局因素,识别与验证影响企业竞争力的主要因素。
关键词:
语义聚类; 因素分析; 企业竞争力
中图分类号:G350
Research on Enterprise Competitiveness Factor Analysis Combining Semantic Clustering
Abstract
This paper integrates clustering into the exploration and discovery of enterprise competitiveness factors,then proposes a semantic-based comprehensive hierarchical clustering analysis method according to the software enterprise domain Ontology constructed by the research team. This method fuses Ontology and clustering technologies, brings forth new ideas for the clustering analysis method based on domain Ontology,that is Onto-kmeans, and achieves the analysis and acquisition of enterprise competitiveness factors at semantic level. The experimental results indicate that this method can significantly improve the accuracy and efficiency of clustering analysis,effectively mine and obtain global factors influencing the competitiveness of software enterprise, identify and verify the major factors.
Keyword:
Semantic clustering; Factor analysis; Enterprise competitiveness
1 基于语义的聚类分析
随着自然语言处理、本体技术的逐步成熟以及领域信息聚类需求的增大,针对特定领域的聚类分析越来越离不开领域本体的支持,基于通用本体的聚类分析方法虽然能够取得相对理想的聚类效果,但在具体领域应用中此种方法存在问题,原因在于通用本体往往具有较广的泛在性与一定的抽象性,缺乏领域相关背景知识,提取的语义知识往往由于缺乏领域相关性而在语义内容、语义关联等多个维度上出现误差,在深层的语义推理和知识挖掘
上会因误差的累积而出现更大的偏差[ 1, 2, 3, 4]。因此,近年来国内外学者开始关注利用领域本体指导领域聚类分析,基于领域本体的聚类分析研究主要集中在三个方面:
(1)利用领域本体计算领域文本之间的语义相似度,在此基础上实现基于语义相似度的聚类分析。如Zhu等[ 5]利用MeSH本体将文本的语义相似度与内容相似度结合起来构建文本之间的集成相似度矩阵,基于该相似度矩阵进行谱聚类算法实验。
(2)利用领域本体进行关键特征的概念映射,通过构建概念空间模型实现不同概念层次的聚类分析。如Hotho等[ 6]利用自然语言处理技术将文本关键特征映射为概念特征,借助领域本体实现自上而下的概念聚合,在此基础上调用 K-means算法进行概念聚类分析;Kong等[ 7]利用领域本体实现主题选择和主题聚类分析;朱恒民等[ 8]利用领域本体的概念层次关系,采用SOM算法实现逐层聚类分析;Yoo等[ 9]利用MeSH本体解决聚类分析过程中的同义词、下位词及上位词问题,并且在构建的概念向量空间上比较多种聚类算法的优劣性。
(3)利用领域本体进行领域概念聚类分析。如Dong等[ 10]通过扩展标引特征获取领域概念,采用信任力传播聚类算法将概念分成多个小簇,通过领域本体的概念层次关系实现概念的精确聚类。
这些研究在一定程度上提高了聚类分析的准确率和效率,但也存在一定的问题:基于领域本体的聚类分析仍停留在传统的聚类分析框架中,领域本体只作为辅助工具进行特征扩展、概念泛化或语义相似度计算的背景知识,尚没有全面地利用领域本体丰富的概念体系和层次结构作为聚类的主线,领域本体发挥的作用较小;领域本体、聚类分析和企业竞争情报分析相结合的研究成果较少,多数研究集中在聚类分析算法的改进及验证,忽略了理论研究与实际应用的结合。
针对上述存在的问题,本文构建软件企业领域本体,为实现软件企业领域知识的组织、共享及其竞争力分析提供语义知识。其贡献主要体现在:研究了如何利用领域本体知识解决针对聚类分析方法K-means存在的主要问题,并设计了一种基于领域本体的语义聚类分析方法与算法Onto-kmeans;在此基础上研究语义层面的企业竞争力影响因素聚类分析,探索和挖掘影响软件企业竞争力的主要因素,从而为企业竞争或战略决策提供指导,也可为软件产业发展乃至国家制定相关政策提供参考。
2 企业竞争力影响因素语义聚类分析
目前,聚类分析应用主要采用基于划分聚类的K-means方法来实现,其原因在于该方法思想简单,运算速度快,适合从海量数据中快速获取影响企业竞争力的决定因素[ 11]。但由于该方法在运行过程中,对于簇数目k的设定、初始k个聚类中心的选取、迭代过程中聚类中心的确定、数据对象间相似度的计算等方面的处理没有可利用的语义信息,导致聚类分析效果不理想。为此,本文以K-means方法为基础,依据本课题组构建的软件企业领域本体,提出了一种基于语义的综合层次聚类分析方法,研制了语义聚类分析算法,以提高聚类分析的准确率和效率,实现语义层面的企业竞争力影响因素的挖掘与获取。
2.1 簇数目k的设定
K-means方法需用户预设对聚类分析结果影响较大的簇数目k,如果用户对数据结构和数据分布无任何先验知识,很难确定理想的目标簇数目[ 12]。本文提出应用领域本体先验知识较有效地解决了该问题。这是因为本文的主要目标是分析和挖掘影响软件企业竞争力的主要因素,聚类分析结果的簇数目即为主要竞争力因素的数目,而本课题组构建的软件企业领域本体正是基于软件企业生产活动中所涉及的主要业务要素,这些要素在很大程度上决定了软件企业的主要竞争力因素,领域本体的核心概念类别个数λ即可作为聚类分析的目标簇数目k的参照,具体的k取值可在λ的一定范围ε内进行浮动,即λ-ε≤k≤λ+ε,ε为簇数浮动因子,可根据实际数据集的大小及分布情况来确定。
2.2 初始k个聚类中心的选取
K-means方法从数据对象中随机抽样产生初始k个聚类中心,实际上k个初始聚类中心的选取对聚类分析结果影响极大:如果所选择的k个数据对象部分或全部属于同簇或少数m个簇(m
(1)设待聚类分析的总数为n,为取得数据聚类结果的平衡,对初始数据集D进行随机取样m次,则每次取样的样本总数为n/m,m值可根据经验取值或进行多次试验选定;
(2)利用凝聚的层次聚类法分别对每次取样的文本数据进行聚类,生成各个取样的k个划分,即共生成m×k个不同簇;
(3)分别计算m次取样生成的k个簇的聚类中心,共获得m×k个聚类中心;对这m×k个聚类中心,构建聚类中心相似度矩阵M,其中Mij表示第i个聚类中心与第j个聚类中心之间的相似度(i=j时Mij=1);
(4)观察相似度矩阵,每次从矩阵中选择相似度最大的m个不同聚类中心组成新簇,将已选择的矩阵元素排除,进行下一轮的选择,直至组成k个新簇,分别计算k个新簇的聚类中心,将其作为初始聚类中心。
2.3 迭代过程中聚类中心的确定
聚类中心的选择直接影响到聚类分析的最终质量,K-means方法采用簇中样本数据的平均值作为该簇的聚类中心参照点,其分析结果对噪音和异常点极为敏感。为避免分析算法受到孤立点的影响,利用课题组构建的软件企业领域本体所提供的先验知识对每次获取的新簇ki,计算簇中各点di与dj之间的距离dis(di, dj),然后对每一个点di,计算该点与其他点的距离和,剔除簇中距离和大于阈值ε的点,其中ε=α×(n-1)×max dis(di, dj)(α可通过试验或经验取得,0<α<1);计算簇中剩余点的平均值即为聚类中心或簇质心。
2.4 数据对象间相似度的计算
dis(di,dj)= 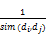
K-means方法采用欧几里得距离或余弦相似度来衡量数据对象之间的相似度,这两种相似度的计算方法均基于向量空间模型,仅仅考虑特征概念在文本中的出现频率等信息,忽略了特征概念间的语义关系[ 14]。因此,相似度的计算应综合考虑特征的频率信息和特征间的语义关系信息。在基于领域本体的预处理过程中,通过将文本特征映射且聚合到领域本体中的相同概念层次,实现文本特征的相似度转化为文本特征所对应概念之间的相似度,领域本体作为领域内共享概念模型的形式化规范说明为领域内概念间语义相似度的测度提供了充分的理论依据。基于此,本文提出一种基于领域本体的语义相似度测度算法,具体思想为:经过预处理后的文本数据集D=(d1, d2, … , dn)的概念向量空间表示为V=(c1, c2, … , cm),文本di表示为di={(c1, wi1), … , (ci, wij), … , (cm, wim)},其中wij表示概念cj在文本di中的权重。设具有根节点Root的领域本体为H,计算文本之间的相似度首先需计算概念向量空间中概念之间的语义相似度。本文采用Wu等[ 15]提出的基于网络距离的测度算法,其计算公式为:
simwup(c1,c2)=
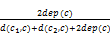 | (1) |
其中,概念c为概念c1与c2在H中最近的公共祖先节点,dep(c)表示概念c到根节点Root的路径长度,d(c1, c)与d(c2, c)则表示概念c1与c2到c的路径长度,该算法综合考虑概念与概念之间的距离及概念在本体类层次结构中的深度。由于语义核函数能够较好地集成概念之间的语义相似度,实现语义层面的相似度计算[ 16],因此本文融合语义核函数进行相似度的计算:
k(di,dj)= 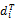
其中,P表示概念向量空间中概念之间的相似度矩阵,PT即为P的转置矩阵,为消除文本数据大小对核函数取值的影响,进行归一化处理和语义距离计算:
sim(di,dj)=
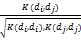 | (3) |
3 语义聚类算法与实验
3.1 语义聚类算法
基于语义聚类分析方法,充分利用领域本体的语义概念和语义关联层次结构知识,研制了基于领域本体的聚类分析算法Onto-kmeans,详细描述如下:
输入:具有概念向量V=(c1, c2, … , cm)的数据集D=(d1, d2, … , dn);领域本体H;聚类簇数目浮动因子ε;数据集随机取样次数m
输出:聚类分析结果C=(c1, c2, …, ck)
(1)根据领域本体H的核心概念类别个数λ确定聚类簇数目k,λ-ε≤k≤λ+ε;
(2)利用凝聚的层次聚类法确定初始k个聚类种子文本;
①对数据集D进行m次随机取样,每次取样样本总数为n/m,形成m个样本集S=(S1, S2, … , Sm);
②对于样本集中的每个样本Si,将凝聚的聚类算法应用于Si,获得该样本的k个划分:
1)对于每个簇cj,利用文本距离计算方法求出簇中各文本两两之间的距离;
2)对于簇中每个文本,计算该文本与其他文本的距离和;
3)剔除簇中距离和大于某设定阈值δ的文本,其中δ=α×(n/m-1) max dis, max dis表示簇中文本之间的最大距离,α为可调参数因子;
4)计算簇中剩余文本的平均值作为簇质心或聚类中心;
③对生成的m×k个簇的聚类中心O=(o1, o2, … , om*k),构建聚类中心相似度矩阵Mij, Mij表示第i个聚类中心与第j个聚类中心之间的相似度;
④每次从该相似度矩阵中选取相似度最大的m个不同的聚类中心组成新簇,去除已选择的矩阵元素,进行下一轮选择,直至组成k个新簇;
⑤分别计算k个新簇的聚类中心,将其作为K-means的初始聚类种子文本;
(3)重复以下步骤直到各簇的聚类中心不再发生变化:
①利用本文提出的文本距离算法(核函数)计算文本集中各个文本与种子之间的距离,将其分配到距离其最近的种子文本所代表的簇中;
②重新计算所获新簇的聚类中心。
3.2 实验结果与分析
本文的实验目的主要包括两个方面:验证本文创新的聚类分析算法Onto-kmeans相对于传统K-means算法的有效性;利用Onto-kmeans算法探索和挖掘影响软件企业竞争力的主要因素。
(1)数据采集
利用网络爬虫采集国内软件100强企业的官方网站和主流媒体门户网站新浪、雅虎、搜狐的科技或IT频道提取实验数据。将抓取的网页经过数据清洗存入文本文档中,以公司名为组织单位,建立每个公司的文本集合。经过数据清洗与选择,共获得25 717个有效文本,即平均每个公司抽取约260个文本,总体数据大小为1.07GB。
(2)实验环境及测评指标
本实验基于WEKA进行Onto-kmeans聚类分析算法的设计与编码,同时调用其自带的K-means算法作为基准进行实验对比。由于未对数据集进行标注,对聚类结果的簇个数及每个数据样本的正确分类均未知。因此一些外部度量指标如聚类熵、纯度、查准率及F-measure等都无法应用,只能依靠数据集自身的特征采用内部度量指标进行评价。Onto-kmeans算法是对K-means的创新与优化,两者都需事先确定聚类簇数目k,聚类结果均由k个聚类中心来表达,所以本实验采用直观的簇内方差即误差平方和最小方差标准(Within Cluster Sum of Squared Errors)进行两种聚类分析算法的结果评价。
(3)实验过程及结果
为对比Onto-kmeans与K-means两种算法的分析性能,设定实验前提条件:在相同样本总量(17 170个文本)的相同特征空间(具有200维度的概念特征空间)及相同目标簇数目上应用两种算法。目标簇数目k的选择依据如下:软件企业管理与运营一般要涉及到软件产品、软件服务、市场、技术等9个方面,而所获取的数据集均是表达有关软件企业的相关信息,因此可以预设数据集的聚类结果也为9簇,且领域知识在一定程度上能够避免由于人为随机选择所带来的误差。在这样的假设下,分别取k=8,k=9,k=10三种不同情况下的聚类结果进行对比,实验结果如表1至表3所示:
| 表1 k=9 Onto-kmeans与K-means算法结果对比 |
| 表2 k=8 Onto-kmeans与K-means算法结果对比 |
| 表3 k=10 Onto-kmeans与K-means算法结果对比 |
(4)实验结果分析
①Onto-kmeans算法和K-means算法均在k=9时簇内方差Vc取得最小值,由此可知9个类簇是较为理想的目标簇数目;
②针对不同的k值,Onto-kmeans算法与K-means算法相比都能取得较低的簇内方差,同时Onto-kmeans算法首先利用凝聚的层次聚类法优化初始聚类中心的选择,因此能够在一定程度上降低达到最佳聚类划分的迭代次数t。这是因为K-means算法进行聚类分析时容易陷入不同的局部极值,因此需要通过多次运行K-means,选取不同的随机种子生成初始聚类中心样本,最终找出误差最小值;而Onto-kmeans虽利用凝聚层次聚类法获取初始聚类中心会增加整个算法的运算复杂度,但同时降低了多次运行K-means选择最优解的时间成本。由此可以得出本文提出的Onto-kmeans算法较传统的K-means算法在聚类分析性能上有较大的优化。
利用Onto-kmeans对数据集进行聚类分析,获得9个类簇的可视化结果如图1所示:
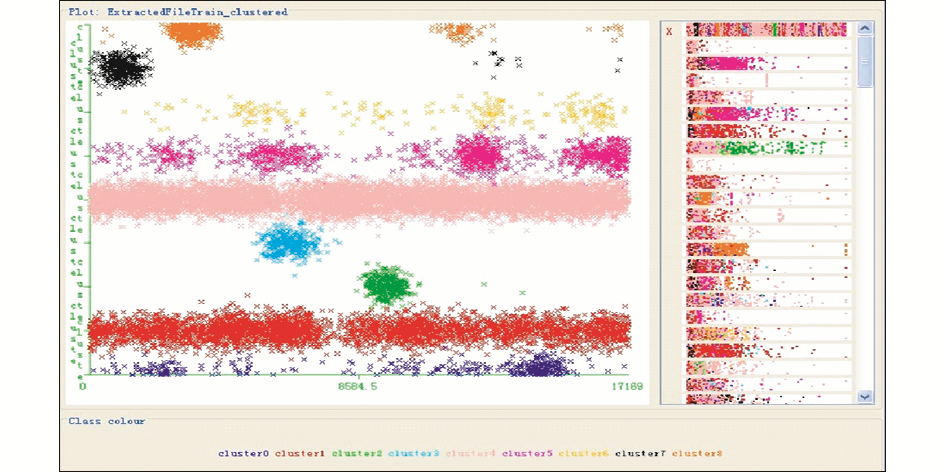 | 图1 Onto-kmeans聚类分析结果可视化(k=9) |
聚类结果中,各个类簇内样本的分布情况如表4所示:
| 表4 聚类分析结果——各个类簇内样本分布情况 |
结合图1与表4可以看出,类簇Cluster4包含了超过一半的样本,类簇Cluster1包含的样本所占比例也较大,除此之外,剩余样本较为均匀地分配到其他7个簇中,可见样本整体分布较为倾斜,局部类簇样本分布较均匀。
为了获取各类簇所反映的主题信息,必须对聚类分析结果簇进行类标签提取来概括各类簇中文本所表达的主要内容。本文采用聚类中心的特征词集Rk来表示类簇Ck,其中Rk中特征词ti的权重是包含在Ck内的所有文本在该特征上权重取值的均值,通过依次提取每个簇的特征词集Rk中权重较大的前几个特征作为类标签。利用此方法获取的9个簇的类标签如表5所示:
| 表5 聚类分析结果簇标注 |
通过对表5的类标签进行分析发现,Cluster2与Cluster6所关注的主题是相同的,因此需合并这两个簇的聚类结果以获取更精炼的描述聚类所反映的主题内容;此外Cluster5的主题是关于软件产品及相关服务的安全性,可归入Cluster4所反应主题的特性中,合并这两个类簇将使聚类结果更加合理。综合上述聚类分析结果发现,影响软件企业竞争力的因素主要包括:
①企业提供的软件产品与相关软件服务。由表4样本的分布(簇Cluster4包含的样本占样本总量的59%)可以看出软件产品与软件服务是决定软件企业竞争力的最重要因素。另外,随着Internet及Intranet的深入应用,各种软件或硬件产品及实施服务的安全性越来越被企业所重视,软件产品是否具有较高安全性、能否为企业提供切实可靠的安全管理机制直接影响到企业是否会采购及实施该软件,因此安全性作为软件产品的重要特性是影响竞争力的重要因子。
②企业提供的解决方案。解决方案是否全面、优质,是否有典型案例支撑是影响企业竞争力的另一个重要方面,从样本分布比重(22%)也可得出该结论。但根据软件企业本体中的先验知识,解决方案也可归入到软件产品与服务中,因此该因素可与①进行合并。
③企业人才招聘及员工培训发展。从聚类分析结果提取的簇标签特征“招聘”及对招募人才的“项目”、“开发经验”等要求中可以看出企业对人才选拔的重视,该因素可进一步归纳概括为“人力资源管理”。
④行业/企业信息化建设及业务流程管理。结合近几年中国企业的发展来看,国内各行业各领域的企业信息化及业务流程重组正逐步展开且全面实施,政府也在大力推广信息化工程,这一发展趋势在很大程度上带动了整个软件产业的蓬勃发展,尤其是管理软件市场。
⑤企业的财务实力及业务管理能力。该因素是较为明显的竞争力因素,也与预期相吻合,直观而言,有较大资金支持、财务雄厚的企业往往能够投入更多人力、物力来研发产品,在市场上的竞争力也较大。此外,企业如果想在市场上取得长足发展,多样化的业务经营管理往往能够取得较大优势。
⑥软件企业所承担和实施过的成功案例及与之相关的支持服务、服务体系的完备性。一般企业或个人在选择软件产品时注重考察市场上企业的品牌形象、已有口碑,但更常见的是,甲方企业往往会衡量乙方企业是否在自己同行业内、同领域内实施过成功案例以及成功案例有多少,成功案例中知名企业、行业内的领头企业占多大比例,这些因素直接影响到甲方企业是否考虑由乙方企业来开发所需软件及实施相关服务。在实施过程中,乙方企业所提供的相关服务支持是否到位,服务体系是否完善、优效是甲方企业重点考量的方面,因为在实际项目中,软件交付后运行是否正常、乙方企业能否及时有效地提供甲方所需服务使软硬件能够按预期高效地运行直接影响到甲方的客户满意度,因此也是影响企业竞争力的重要因素。
⑦软件企业的技术或科技因素。从上述9个簇标签可以发现,技术(或科技)在多个簇标签中虽然权重值不是最高,但频繁出现于各个簇较为重要的特征词行列,由此可见技术或科技因素也是一个影响软件企业乃至整个软件行业的重要竞争力因素。从大处来讲,技术的先进性、实用性及科技更新从根本上改变着整个软件产业的发展进程及方向;从小处而言,企业是否采用通用性较强、平台支持性能强大、具有前瞻力的技术架构是决定其是否能够适应各种市场需求的重要基石。更深层次、更根本地,软件企业中技术人才的比重、结构也是影响软件企业实力的重要方面。
⑧公司新闻、市场信息虽不能直接构成竞争力因素,但可以这样解释Cluster0的分析结果:“公司新闻”、“市场信息”、“产业发展”三个特征权重较高,说明被挖掘文本中有较大一部分主题在反映这方面的内容,从另一角度来讲,这反映了企业看重什么、企业想要展示给客户什么样的信息。公司新闻更多反映企业在长期或短期内发生的事件,一般从企业网站获取的大多数是正面的事件与评论;而市场信息反映的是某个软件领域或是整个软件行业正在经历的事件及有关市场的反馈信息,这些信息或直接影响到企业战略布局的调整,或影响到企业市场地位的转变,客户/用户透过这些信息也能够透视并了解整个企业;“产业发展”、“软件园区”等可看作是影响企业竞争力的外部因素。
4 结语
本文针对传统聚类分析方法存在的问题和不足,依据软件企业领域本体,提出了一种基于语义的聚类分析方法Onto-kmeans。该方法利用领域本体指导类簇数k的产生,利用凝聚的层次聚类法获取初始k个聚类中心,融合语义核函数进行语义相似度的计算。同时,应用该聚类方法,从海量信息中分析和挖掘影响软件企业竞争力的主要因素。实验结果表明,Onto-kmeans方法能够比K-means取得更有效的聚类分析效果,挖掘发现影响软件企业竞争力的全局因素主要包括软件产品与服务、人力资源管理、企业财务实力和业务管理能力、成功案例和支持服务竞争力、技术竞争力、市场竞争力、行业/企业信息化、产业扶持等8个方面。但是,通过聚类分析挖掘和发现的软件企业竞争力影响因素还比较笼统,未来将利用分类分析方法对这些影响因素进行优化。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|