
{kind=link}
融合语义分类的企业竞争力影响因素分析研究*
引用本文
张玉峰, 何超, 王志芳, 周磊. 融合语义分类的企业竞争力影响因素分析研究* . 现代图书情报技术, 2012, 28(9): 56-61
Zhang Yufeng, He Chao, Wang Zhifang, Zhou Lei. Research on Enterprise Competitiveness Factor Analysis Combining Semantic Classification. 现代图书情报技术, 2012, 28(9): 56-61
Permissions
Zhang Yufeng, He Chao, Wang Zhifang, Zhou Lei. Research on Enterprise Competitiveness Factor Analysis Combining Semantic Classification. 现代图书情报技术, 2012, 28(9): 56-61
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
融合语义分类的企业竞争力影响因素分析研究*
摘要
将分类分析融入企业竞争力影响因素的获取与优化之中,依据本课题组构建的软件企业领域本体,设计基于领域本体的企业竞争力影响因素分类分析框架,提出基于语义的分类分析方法Onto-TC。该方法利用领域本体和通用本体,实现多维语义的分类分析。同时有机结合聚类与分类分析的工作与结果,分析与挖掘深层次的主要影响因素,实现企业竞争力影响因素指标体系的构建和优化。
关键词:
语义分类; 因素分析; 企业竞争力
中图分类号:G350
Research on Enterprise Competitiveness Factor Analysis Combining Semantic Classification
Abstract
This paper integrates classification analysis into the acquisition and optimization of enterprise competitiveness factors, designs an analysis frame of enterprise competitiveness factors based on domain Ontology according to the software enterprise domain Ontology constructed by the research team and proposes a semantic classification method Onto-TC. This method combines domain Ontology and general Ontology to achieve classification analysis at multi-semantic level. This paper analyzes and mines the deep major factors of competitiveness according to the clustering and classification results, implements the construction and optimization of enterprise competitiveness factor indices system.
Keyword:
Semantic classification; Factor analysis; Enterprise competitiveness
1 基于语义的分类分析
当前,分类分析方法的缺陷主要体现在缺乏语义支持和自动学习过程中需大量标注。为解决这些问题,国内外学者利用本体进行分类分析研究,尤其是基于通用本体WordNet、HowNet的研究比较成熟,其研究思路可概括为三个方面:利用领域本体概念之间的相互关系构建概念向量空间模型,如Camous等[ 1]提出利用MeSH本体扩展文本表示模型进行生物信息领域文本分类分析;利用领域本体构建类别向量,通过计算待分类数据与类别之间的相似度进行分类分析,如杨喜权等[ 2, 3]提出基于领域本体的文本分类分析框架;利用领域本体作为分类分析器,如Janik等[ 4, 5]通过将文本表示成实体主题图,借助Wikipedia构建的领域本体对主题图中的实体进行本体分类。
本文在上述研究基础上做了进一步深入探讨,利用课题组构建的软件企业领域本体提供先验知识,承接和优
化前期聚类分析的工作与结果,实现软件企业竞争力影响因素的分类分析。
2 企业竞争力影响因素语义分类分析
基于语义的企业竞争力影响因素分类分析充分利用课题组构建的软件企业领域本体,结合本体与分类技术构建基于领域本体的企业竞争力影响因素分类分析框架,设计和验证基于语义的分类分析方法Onto-TC,分析和构建语义层面的软件企业竞争力影响因素指标体系。
2.1 语义分类分析框架
企业竞争力影响因素分类分析的研究思路是:综合应用通用本体和课题组构建的领域本体语义知识,研制基于语义的Onto-TC算法,将前期聚类分析发现的软件企业竞争力影响因素作为其指标体系的一级指标,将其中的8个大类作为参照目标类别,运用Onto-TC算法,从软件领域的开源信息中分析和挖掘深层次的企业竞争力影响因素的二级和三级指标,实现企业竞争力影响因素分类分析任务的框架,包括语义元素识别与抽取、语义特征向量和类别概念向量构造、语义相似度计算、分类分析与类别确定等,如图1所示:
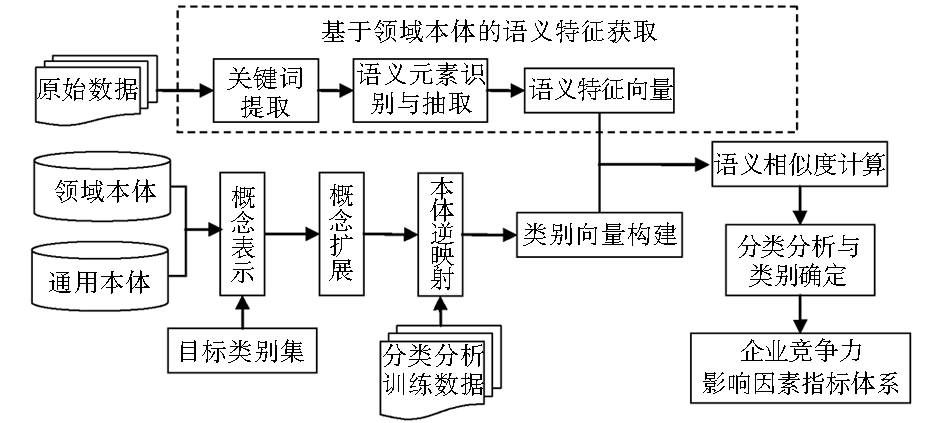 | 图1 基于领域本体的企业竞争力影响因素语义分类分析框架 |
分类分析的主要处理包括:
(1)将软件企业领域本体应用于数据预处理任务中,应用其丰富的概念及层次体系进行本体概念映射、语义元素识别与抽取,构建语义特征向量空间模型;
(2)融合领域本体与通用本体构建目标类别向量,实现语义特征信息的分类分析任务;
(3)应用本文设计的Onto-TC算法计算目标类别向量和语义特征向量的相似度,实现企业竞争力影响因素的语义分类分析。
2.2 融合领域本体与通用本体的类别向量构建
设待分类分析的数据集D={d1, d2, … , dD},经预处理后形成语义特征向量空间V={v1, v2, … , vV},其中vs ={STs1, STs2, … , STsS}为语义特征向量,分类分析的目标类别集C={c1, c2, … , cC},领域本体H,通用本体O,则融合领域本体与通用本体的类别向量构建的主要步骤包括:
(1)对每个类别ci,类别名称即为一个术语,需要一些概念及概念的属性来刻画该类别,因而首先判断该类别是否领域相关,如果该类别领域强相关,则自上而下遍历领域本体H,获取描述该类别名称的主要概念集合{Coni1, Coni2, … , Conin};如果该类别领域相关度较低,利用相同的方法遍历通用本体O,获取对应概念集合;
(2)对概念集合{Coni1, Coni2, … , Conin}中的每个元素,解析领域本体或通用本体,获取每个元素对应的所有直接或间接子类概念{Coni11, Coni12, … , Coni1m}和各个类或子类的属性集合{Proi1, Proi2, … , Proik},由于本体中子类继承父类的所有属性,因此该属性集合包括类{Coni1, Coni2, … , Conin}中每个元素的所有属性与每个元素对应的子类的属性;
(3)为类别ci构建类别向量,其分量集合为{Coni1, Coni2, … , Conin, Coni11, Coni12, … , Coni1m , Proi1, Proi2, … , Proik }。本文将分类类别对应的概念、子概念及其属性全部纳入向量分量中,描述该类别的目的在于尽可能地利用多种信息、多角度刻画该类别的特征,而本体能够提供相关领域内共享的概念集合,能够从不同层次的形式化模式上给出这些概念及概念之间的相互关系,通过该步骤实现以类别在本体中对应的概念层次及其属性为描述特征构建分类类别ci的向量模型;
(4)利用分类分析训练数据集确定类别向量中各分量的权重。确定类别向量中各分量的权重时,首先获取该概念特征对应于整个数据集中的词语特征,即本体逆映射,通过搜索整个数据集的词语特征集,查找与该分量(类概念或属性)意义最接近的词语特征获得类别向量分量对应的词语特征集,通过利用词语特征在已标注类别的训练数据集中的频率信息确定与该特征对应的概念分量在类别向量中的权重取值。具体实现方法为:设当前已标注类别的训练样本集为T,确保T中的训练样本均匀地分布于目标类别集C中的各个类别中;设类别ci的第j个概念特征分量(Con/Pro)对应于文本集中的词语特征word,则其权值计算公式如下:
wij(Con/Pro)= 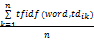
其中,tdik表示属于类别ci的第k个训练数据,n表示属于类别ci的训练数,tfidf(word, tdik)表示word在dik中的tfidf权重值, 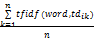
2.3 语义特征与类别的相似度计算
分类分析的主要任务可简要描述为:分别计算语义特征向量vs与目标类别集C中的每个类别向量ci的相似度,然后将vs划分到与其相似度最高的类别c*中。因此,语义特征与类别之间的相似度计算是影响分类分析效果的一个重要因素。
计算语义特征向量与类别向量之间的相似度最简单直观的方法是计算其余弦相似度,但这种方法在实际运用中存在较大的偏差。本文采用基于语义的计算方法获取语义特征向量与类别向量之间的相似度。设维度为m的语义特征向量vs ={STs1, STs2, … , STsm},维度为n的类别ci={Coni1, Coni2, … , Conin},通常情况下,语义特征向量与类别向量的维度不同,需进行维度转换后进行相似度计算,本文采用如下转换策略获取具有相同向量分析的空间模型NV:
(1)初始化向量NV为空,保留vs与ci中相同的分量{NV1, NV2, … , NVt},将该分量集合添加到新向量NV中;
(2)从vs与ci中去除步骤(1)中共有的向量分量,剩余的分量V*={STs1, STs2, … , STsl}与C*={Coni1, Coni2, … , Conir}处理如下:由于两个向量中的各分量均是存在于本体中的概念,对于V*中的每个分量STsl,利用Wu等[ 6]的公式,计算它与C*中每个分量Conij之间的概念相似度sim(STsl, Conij),对于与STsl相似度值最高的分量Conit在本体中查找STsl与Conit的直接父概念Par,标记该概念直至C*或V*中所有向量均处理完毕,获取父概念集合{Par1, Par2, …, Parmin imize(l, r)},将该父概念集合加入新向量NV中;
(3)综合步骤(1)与(2),新的向量空间表示为NV={NV1, NV2, … , NVt, Par1, Par2, … , Parmin imize(l, r)},利用该向量重新表示vs与类别ci,对于NV中的每个分量,其在vs与类别ci中的权重值规定如下:分量{NV1, NV2, … , NVt}的权重保持不变,而{Par1, Par2, … , Parmin imize(l, r)}中各分量的权重值则取各分量在原数据或类别中对应的各子类概念的权重值;
(4)通过上述处理后,利用语义核函数进行vs与ci的相似度计算,公式为[ 7]:
sim(vs,ci)= 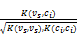
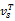
其中,P表示向量空间NV中各分量之间的相似度矩阵,PT为P的转置矩阵。最终将vs划分到与其具有最大相似度值的类c*中。
3 实验结果与分析
本文的实验主要包括三部分:应用已有的训练数据集验证本文提出的基于语义的分类分析算法Onto-TC的有效性;应用该算法挖掘影响企业竞争力的主要因素及其特征;将前期聚类分析结果作为一级指标(为参照目标),递归利用Onto-TC算法进行深层次的多维语义分析,从开源数据源中获取企业竞争力影响因素的二级和三级指标,优化和构建软件企业竞争力影响因素指标体系。
3.1 验证Onto-TC算法的有效性
(1)数据采集与标注。本文主要是对“融合语义聚类的企业竞争力影响因素分析研究”中的聚类分析结果进行细化和完善,所以在相同的数据集上进行算法验证和深层次挖掘,所不同的是需要预先进行数据标记,本文设计的分类分析算法的优越性是无需大量数据标注,然而为有效进行算法有效性检验及与常用算法分析结果的对比,有必要对所要分析的全部样本进行类别标注。
(2)实验环境及测评指标。本文实验基于WEKA进行Onto-TC分类分析算法的设计与编码,同时调用其自带的Naïve Bayes算法作为基准进行实验对比,进行5次10折交叉验证,5次实验结果的平均值作为算法的最终运行结果。测评指标采用统一的Precision、Recall、F1值对上述两种分类算法的分析结果进行评价,同时根据分类分析结果的样本分布情况确定主要竞争力因素及其重要性程度。
(3)实验过程及结果。为对比Onto-TC与Naïve Bayes两种算法的分析性能,利用已有的9类数据集作为训练数据集。设定实验前提条件为:在相同样本总量(17 170条数据)的相同概念空间(具有200维度)进行实验,结果如表1所示:
| 表1 Onto-TC与Naïve Bayes在9类训练数据集上的分类分析效果对比 |
(4)实验结果分析。根据表1可以看出, Onto-TC分类分析算法在这9类训练数据集上的分类分析效果略优于Naïve Bayes分类器,在“产品”、“技术”、“市场”、“战略”、“组织”、“环境”7类训练数据集上的F1值高于Naïve Bayes, 而在“服务”、“资源”、“活动”训练数据集上,F1值则要略低于Naïve Bayes的分类分析效果;Onto-TC的宏观查全率、宏观查准率和宏观F1值略高于Naïve Bayes。总的来说,Onto-TC分类器能够在利用少量训练样本的情况下取得和传统朴素贝叶斯分类器相当甚至更好的效果,验证了这种新的分类分析方法的有效性。
3.2 挖掘深层次的企业竞争力主要因素及其特征
由于选取样本的偏差导致分布于西北及华中地区的软件企业极少,不具有代表性,因此,本文只对华北、华东、华南、西南、东北地区的企业竞争力影响因素进行分析,通过计算分布于各个地区内的每个企业所包含的语义特征向量与前文聚类分析所得到的8个类别向量之间的相似度进行竞争力影响因素的判定与排序,实验结果如表2所示:
| 表2 不同区域的软件企业竞争力影响因素 |
从表2可以看出,8个全局竞争力影响因素除“企业财务实力及业务管理能力”外,其余因素基本上都有所涉及,从影响各个区域竞争力的主要因素及其排名可以看出,除“软件产品与服务”是共有的影响企业竞争力的首要因素外,其他要素的影响力度各有不同:
(1)华东与华北地区的情况较为相似。其区别在于:相对于华东地区而言,影响华北地区(主要是北京)的企业竞争力的主要因素是“企业信息化”。这是因为北京信息化发展综合水平在国内居领先地位,因此较其他地区而言,由信息化带动的软件产业发展更强劲。
(2)华南地区不同于华北及华东地区的特点在于:“人力资源、成功案例及支持服务竞争力”是一个较为重要的指标因素。主要原因在于:
①中小软件企业在华南地区尤其是在深圳软件产业中占有相当大的比重,50%以上的软件企业人数在50人以下,40%左右的企业人数在50-200人之间,因此,“人力资源”是企业极为重要的竞争力因素,同时中小企业规模较小,业务流程较为单一,导致人才流动性极大,企业很大的竞争力在于挖掘及留住优秀人才;
②中小型企业的品牌知名度和影响力往往较一般,企业获取竞争力的因素在于其成功实施案例的质量、数量以及支持服务是否到位、客户对其服务的满意度认可情况。
(3)影响西南地区(以四川成都、重庆为代表)的软件企业竞争力因素集中在“企业信息化”与“产业扶持”上,其原因在于西南地区近年来加大对软件园区的建设与投资,政府对软件产业的扶持力度较大,同时与北京信息化发展较成熟所不同的是,西南地区企业信息化建设处于提速发展且全面展开阶段,在一定程度上也影响着整个软件产业的发展。
(4)东北地区(以大连、沈阳为代表)由于其地理位置及其他因素的影响,软件企业大多集中在软件技术服务、外包服务及系统集成服务上,因此其竞争力影响因素“软件产品与服务”依托日企进驻中国及伴随的对日外包与集成服务。
3.3 构建软件企业竞争力影响因素指标体系
在对Onto-TC算法效果验证的基础上,将聚类分析结果作为分类分析的一级指标,利用该算法进行多维语义分类分析,获取软件企业竞争力影响因素的二级指标,进而递归运用该算法获取三级指标,从而构建影响软件企业竞争力的主要因素指标体系,如表3所示。
4 结语
本文针对传统分类分析方法存在的问题和不足,提出了一种基于语义的分类分析方法Onto-TC,该方法融合通用本体和领域本体语义知识,实现企业竞争力影响因素深层次的多维语义分析。并且有机结合聚类分析和分类分析的功能与结果,从不同语义维度挖掘影响我国软件企业竞争力的主要因素及其特性,构建了企业竞争力影响因素的指标体系。实验结果表明,Onto-TC算法取得了较理想的预期效果,提供了从海量数据中分析和获取语义知识的有效途径,为探索和创建领域知识获取、分析、应用与创新的一体化语义分析机制奠定基础。
| 表3 影响软件企业竞争力的因素指标体系 |
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|