{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于关联数据的推荐系统综述
引用本文
田野, 祝忠明, 刘树栋. 基于关联数据的推荐系统综述. 现代图书情报技术, 2013, 29(9): 1-7
Tian Ye, Zhu Zhongming, Liu Shudong. Review of Recommendation System Based on Linked Data. New Technology of Library and Information Service, 2013, 29(9): 1-7
Permissions
Tian Ye, Zhu Zhongming, Liu Shudong. Review of Recommendation System Based on Linked Data. New Technology of Library and Information Service, 2013, 29(9): 1-7
基于关联数据的推荐系统综述
摘要
从基于关联数据的推荐系统的提出背景入手, 介绍关联数据在推荐系统中发挥的作用, 全面梳理基于关联数据的推荐系统与传统推荐系统的异同点, 帮助读者了解基于关联数据的推荐系统产生的原因及应用背景。按照推荐系统的一般分类方法, 以详细介绍具体应用实例的方式, 系统地分析与总结基于关联数据的推荐系统的主要方法。
关键词:
关联数据; 本体; 语义网; 推荐系统
Review of Recommendation System Based on Linked Data
Abstract
Firstly, this paper introduces the background and the effect of linked data in recommendation system, summarizes similarities and differences between the recommendation system based on linked data and the traditional recommendation system. This is to help readers understand the cause and application background of the recommendation system based on linked data. Secondly, this paper systematically analyses the main method of recommendation system based on linked data on basis of the general classification of recommendation system and detailed introduction of concrete application examples.
Keyword:
Linked data; Ontology; Semantic Web; Recommendation system
1 引 言
近年来, 伴随着网络技术和社会化媒体技术的飞速发展, 每个人既可以是信息的接收者也可以是信息的创造者, 从而产生了巨量的信息内容。这种过量的信息资源使得用户很难从中获取对自己有价值的部分, 导致“信息过载”问题, 反而降低了信息的使用效率。现有的多种网络应用, 比如门户网站、搜索引擎和专业数据索引是目前能够帮助用户实现信息过滤的有效手段。然而这些工具只能满足用户的一般需求, 而不能针对不同背景、不同目的、不同时期的个性化信息需求, 因此不能很好地解决信息过载问题。推荐系统作为个性化信息服务的重要方法, 当前被认为是解决信息过载问题的潜在有效方法之一。相比传统的搜索引擎, 推荐系统不需要用户提供用于搜索的关键词, 而是通过分析用户历史行为记录信息, 挖掘用户潜在兴趣, 进而对其进行推荐。
由于能够增强用户在信息查询及导航等方面的体验, 目前推荐系统已经被应用于众多领域, 例如Amazon、eBay等电子商务推荐, Netflix、MovieLens等电影推荐及Last.fm的音乐推荐等。在实际应用过程中, 这些推荐系统一般采用协同过滤算法、基于内容 (知识) 的推荐算法, 或者这几种方法混合推荐[ 1, 2]。这些方法在实际应用过程中往往都面临以下几点问题[ 3, 4, 5, 6, 7]:新用户或者新对象引起的冷启动问题;在大量数据集中较少的对象评分比例导致的数据稀疏性问题。
目前, 大多数方案是从推荐算法的设计角度出发, 采用矩阵分解[ 8, 9]、上下文感知[ 10, 11]等技术解决上述问题。从问题的根源上讲, 不完善的数据源是产生这些问题的根本原因。如果能从多个角度采集用户/项目数据, 那么这些问题就有可能得以解决。然而传统网络中不同数据源中的数据格式、结构等方面都存在较大的差异, 很难将其组织在一起。关联数据概念的出现, 特别是关联开放数据项目的发展, 为不同领域数据的融合提供一种有效的解决方法, 同时为推荐系统中的冷启动及数据稀疏性问题的解决提供了一种新的解决途径, 逐渐引起了广大研究者的关注[ 12, 13, 14, 15]。
关联数据 (Linked Data) 是由Berners-Lee[ 16]于2006年提出, 适用于语义网 (Semantic Web) 的数据存在形式。它定义了一种URI规范, 使得人们可以通过HTTP/URI机制直接获得数字资源。并且提出了发布关联数据需要遵循的4个原则:使用URIs作为任何事物的标识名称;使用HTTP/URI以便任何人都能参引 (Dereference) 这个全局唯一的名称;当人们查询一个URI时, 使用RDF、SPARQL标准来提供有用的信息;尽可能提供链接指向其他的URI, 以使人们发现更多的相关信息。随着关联开放数据源 (Linking Open Data, LOD)[ 17]的不断增大, 不但减轻了整合分布式异构数据源的复杂性, 同时也推动了基于关联数据的新Web应用。国内外许多学者围绕关联数据进行一系列的应用研究和项目开发。其中, 把关联数据应用在推荐系统的构建上, 实现对用户的跨领域语义推荐, 逐渐成为推荐系统及关联数据应用研究的热点方法之一。本文首先梳理基于关联数据的推荐系统与传统推荐系统的异同点, 帮助读者了解基于关联数据的推荐系统产生的原因及应用背景, 然后按照推荐系统的一般分类方法, 以详细介绍具体应用实例的方式, 系统地分析与总结基于关联数据的推荐系统的主流技术方法。
2 基于关联数据的推荐系统
2.1 与传统推荐系统的异同点
在传统协同过滤推荐系统中, 应用最广泛的相似度计算方法包括以下三种:余弦相似度公式[ 2]、Pearson相关系数计算公式[ 19]和修正的Pearson相关系数计算公式[ 19]。虽然这些相似度计算方法适用于基于关联数据的推荐系统, 但是需要进行复杂的数据转换。为了适应关联数据的特点, 结合语义网技术, 学者们提出了多种应用于基于关联数据的推荐系统的相似度计算方法, 其中主要包括本体语义距离的相似度计算方法和基于关联数据特征的相似度计算方法。例如文献[20]提出的基于个体本体之间关系的语义相似度量方法及文献[21-23]中语义距离相似度计算方法, 文献[24]通过对关联数据图中资源的特征及分区信息内容定义与分析, 提出一种混合式关联数据资源相似度计算方法。在文献[25]中, 分析关联数据中概念之间的分层链接和横向链接, 定义概念连接图结构中的层次距离函数和横向距离函数, 提出一种基于结构的相似度计算方法, 并为RDF图结构创建语义检索图, 以余弦相似度计算方法为基础, 提出一种基于结构的统计语义相似度计算方法, 计算两个项目 (如URI等) 在生成的语义检索图中的相似度。
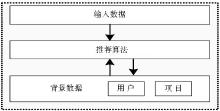
一个完整的推荐系统需要有三部分组成[ 1]:
(1) 背景数据:系统数据;
(2) 输入数据:有关待推荐用户的数据;
(3) 推荐算法:基于背景数据和输入数据的推荐生成策略。
不同的推荐系统, 其背景数据和输入数据也不相同。其中推荐候选对象、用户和推荐算法是推荐系统的核心三要素。在推荐应用系统中, 用户可以向推荐系统主动提供个体偏好信息及推荐请求, 或者用户不提供, 由推荐系统主动采集, 推荐系统根据用户偏好信息, 采取不同的推荐策略, 如将采集到的个性化信息和对象数据匹配对比得到推荐结果, 或者直接基于已建模的数据知识库进行推荐, 并最终把推荐结果推送给用户。
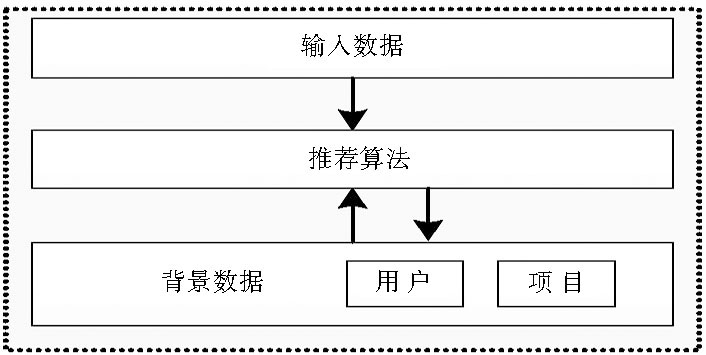 | 图1 传统推荐系统[ 14] |
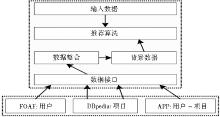
在传统的推荐应用系统中, 涉及的背景数据往往都只限于本地系统的内部数据, 不会涉及该应用系统之外的其他数据信息, 从而也不能实现跨平台、跨领域的推荐应用;基于关联数据的推荐系统是一种开放式系统[ 18], 如图2所示:
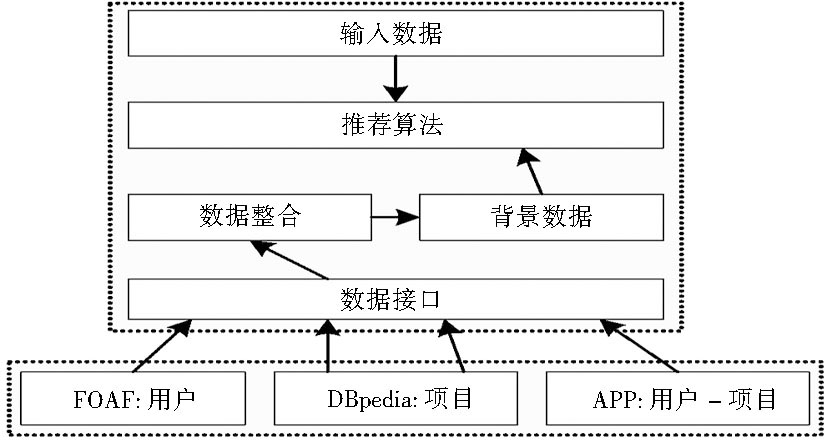 | 图2 关联数据驱动的推荐系统[ 14] |
在语义网中所有数据都遵循统一结构化的标准, 而且所有独立数据源相互关联, 这使得基于关联数据的推荐系统中的背景数据可以来自于多种不同的数据源, 可以进行频繁的数据互动与更新, 并能融合不同领域的数据, 实现跨平台、跨领域的推荐应用, 是一种应用于网络环境中的推荐系统。这是基于关联数据的推荐系统与传统推荐系统的重要区别。
推荐算法是整个推荐系统的核心和关键部分, 在很大程度上决定了推荐系统的类型和性能的优劣。目前根据推荐算法的不同, 不管是传统推荐系统还是基于关联数据的推荐系统, 主流的推荐方法都可以分成以下几类:基于内容的推荐、协同过滤推荐、基于知识的推荐和混合推荐。
传统推荐系统中算法核心思想仍然适用于基于关联数据的推荐系统, 但是在具体技术细节上存在一定的差异, 产生这种区别的根本原因在于背景数据结构的差异性。详细比较如表1所示:
| 表1 基于关联数据的推荐系统与传统推荐系统的对比分析 |
2.2 基于关联数据的推荐方法
推荐系统作为当前解决信息过载问题的有效手段之一, 已经被广泛应用于电子商务等应用系统中。它主要是通过收集与分析用户历史行为记录建立用户的个性化需求模型, 为用户主动推荐满足其个性化需求的服务信息。近年来, 伴随着LOD项目中数据量的扩大, 利用关联数据作为推荐系统的背景数据, 能够为用户提供更广泛的应用推荐服务, 这逐渐引起国内外众多学者的关注与研究, 并提出一些经典的推荐应用系统。下面介绍和分析几个典型实例。
(1) 基于内容的推荐
基于内容的推荐方法是指根据用户已选择的项目, 推荐其他类似属性的项目, 是一种基于项目间相似性推荐方法。系统基于用户所评价对象的特征, 学习用户兴趣模型, 从而考察用户资料与候选推荐项目之间的匹配度。此方法源于一般的信息检索方法, 项目内容特征的选取以项目的文字描述为主, 其中信息检索中经典的文本特征:词频-逆文档频率 (TF-IDF) , 是目前应用较为广泛的一种。例如在MORE[ 26]电影推荐系统中, 建立语义化的向量空间模型 (Vector Space Model, VSM) , 利用文本检索的方法处理所有电影间的RDF关联图, 并把整个RDF图表示成一个三维张量, 其中每一维都代表一种本体特征。已知一种特征条件下, 每一部电影被看作由文本的TF-IDF组成的特征向量, 此时电影之间的相似度可以用它们的特征向量的相关性 (例如余弦相似度等) 来表示, 最后根据用户喜欢的电影信息, 通过如下公式判断此用户是否喜欢一部新电影, 并由此在LOD数据集 (如DBpedia、LinkedMDB等) 上实现基于内容的电影推荐: 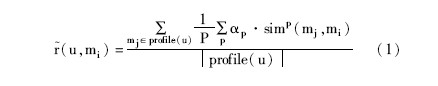
其中, profile (u) ={mj|ulikesmj}表示用户的特征模型, P为所有的特征总数, 且mi profile (u) 。对于一部新的电影, 此方法需要计算用户特征模型中其喜欢的电影与此电影的平均相似度, 并依此判断用户是否喜欢此电影。这是一种广泛应用于电子商务中的典型的基于项目 (电影) 内容的推荐方法, 只根据用户历史数据判断将来其可能喜欢的电影, 而不考虑其他因素 (如上下文信息及用户长、短期兴趣等) 对用户的电影偏好的影响。
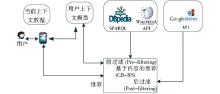
在移动环境中, 用户对项目 (电影) 的喜好不仅仅受个人偏好的影响, 而且会受到其所处的上下文环境的影响, 因此在为用户做预测推荐的时候, 必须二者兼顾。例如在文献[ 27]中, 利用Freebase平台中描述音乐家的数据集, 包括作品类型以及音乐家之间关系的元数据, 利用Lucene索引来构建基于内容的音乐家的推荐系统HORST。还有Ostuni等[ 28]利用DBpedia数据提出一种基于内容的上下文感知电影推荐系统Cinemappy。此系统中电影之间的相似度计算方法与MORE推荐系统中完全一样, 并在此基础上, 提出一种上下文感知的电影推荐框架如图3所示:
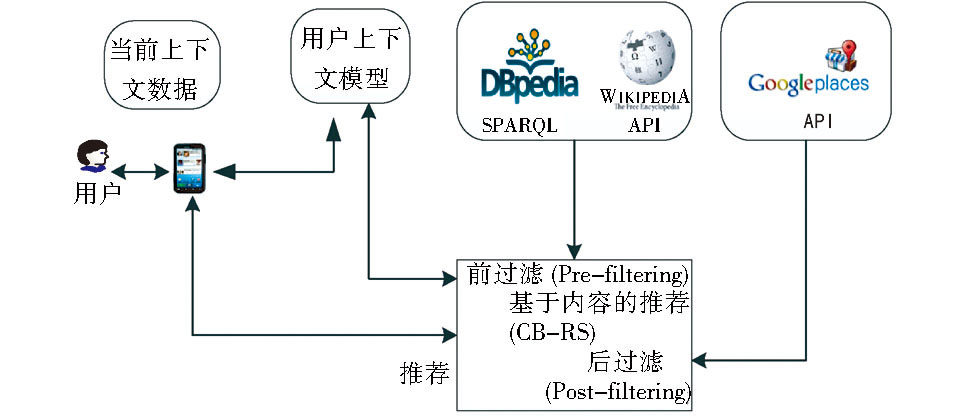 | 图3 Cinemappy 基于内容的上下文感知电影推荐框架[ 28] |
其具体实现方法是:首先根据用户当前的时间与地理位置因素, 考虑离此用户一定距离内的所有电影院在未来一段时间内的放映公告信息, 并判断与此用户模型的匹配情况, 在时间上实现对此用户的前过滤 (Pre-filtering) 推荐。其次, 还可以根据用户的观影同伴的特征信息, 实现对用户的直接前过滤推荐和基于内容的推荐: 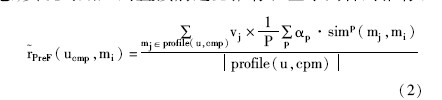
profile (u, cmp) ={
另外, 还可以根据各种上下文与用户当前状态的匹配程度, 实现对用户的后过滤 (Post-filtering) 推荐:: 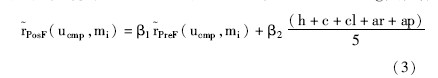
其中, β1+β2=1, h=1表示电影院与用户当前位置在同一个城市, 否则h=0;c=1表示电影院是复合式的, 否则c=0;cl=1表示电影院靠近其他景点 (POIs) , 否则cl=0;ap=1表示电影院靠近用户的家或者办公室, 否则ap=0。
公式 (2) 和公式 (3) 是在公式 (1) 的基础上, 分别考虑不同的上下文信息对用户喜欢电影的影响。公式 (2) 重点考虑用户的观影同伴的特征信息, 预测用户将来在相同观影同伴环境下可能喜欢的电影;公式 (3) 在公式 (2) 的基础上, 又考虑用户的地理位置与电影院的匹配情况, 从而能够预测用户在特定位置下、不同观影同伴时可能喜欢的电影。从而增强了推荐结果适应性, 提高了用户对推荐的满意度。
(2) 协同过滤推荐
相比基于内容的推荐方法, 协同过滤的推荐方法是从用户的角度出发, 根据相似用户间具有相似兴趣偏好的普适性假设, 在相似度用户选择的项目列表中, 为用户选择推荐候选项目, 是目前应用比较普遍的一种推荐预测方法。该方法需要建立用户-项目评分矩阵, 根据相似用户具有相似偏好的假设进行推荐。在用户评分信息充分的情况下, 可以有效地计算用户间的相似度, 并可以进行有效的推荐;但是在冷启动情况下, 即用户评分信息很少或者没有评分信息, 此方法不能有效计算用户间的相似度, 从而不能为用户产生任何推荐结果。因为在这种情况下, 此方法找不到与该用户有相似评分模型的用户, 也就不能基于“相似用户的偏好也相似”的假设进行推荐。在基于关联数据的推荐系统中, 由于可以把多种数据源融合在一起, 在很大程度上能够缓解由于背景数据不足造成的数据稀疏性及冷却问题, 大大提高了推荐系统的性能及其适应能力。
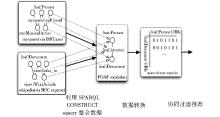
例如在文献[ 18]中, 详细阐述了如何利用关联数据构建开放式的协同过滤推荐系统:利用SPARQL CONSTRUCT, 实现多源数据的获取, 并利用关联数据内部语义关系, 把多数据源融合在一起;将数据的RDF关联图转化成用户-项目评分矩阵;以此矩阵作为背景数据, 实现协同过滤推荐算法, 如图4所示。并讨论了如何利用关联数据对新加入用户的推荐方法、新加入项目的处理方法及降低数据稀疏性对推荐系统性能的帮助。
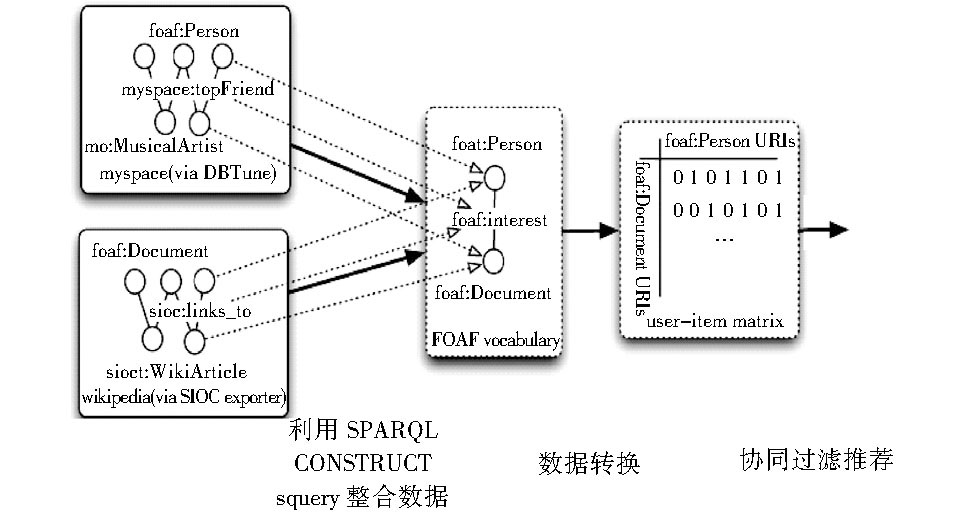 | 图4 基于关联数据的协同过滤推荐的实现过程[ 18] |
此方法在表面上看, 相比一般的协同过滤推荐方法没有太大的差异。但是此成果的重要意义在于以关联数据作为背景数据对缓解协同过滤推荐中的冷启动及数据稀疏性问题的积极作用, 并在文献[ 18]中以具体事例的方式重点讨论此方面的内容, 最后的实验结果表明, 相比单一数据源的协同过滤推荐方法, 多数据源融合的基于关联数据的协同过滤推荐方法无论在准确率还是在召回率方面都有较为明显的优势。这为其他应用领域中的基于关联数据的协同过滤推荐方法的推广与应用提供了重要的指导意义, 但是这其中的数据整合和数据转换将成为此方法在具体的推广应用过程中的一个技术难点。
此外Yang等[ 29]以字符串匹配的方式把MovieLens数据集与关联数据集DBtropes融合在一起, 然后定义关联数据中项目间的语义距离来判断它们之间的相似性, 并依此提出一种基于语义相似性预测评分方法, 最后将这种方法与传统Slope One协同过滤预测评分方法线性加权融合, 提高传统Slope One协同过滤推荐方法的性能和准确率。方法的具体过程如图5所示:
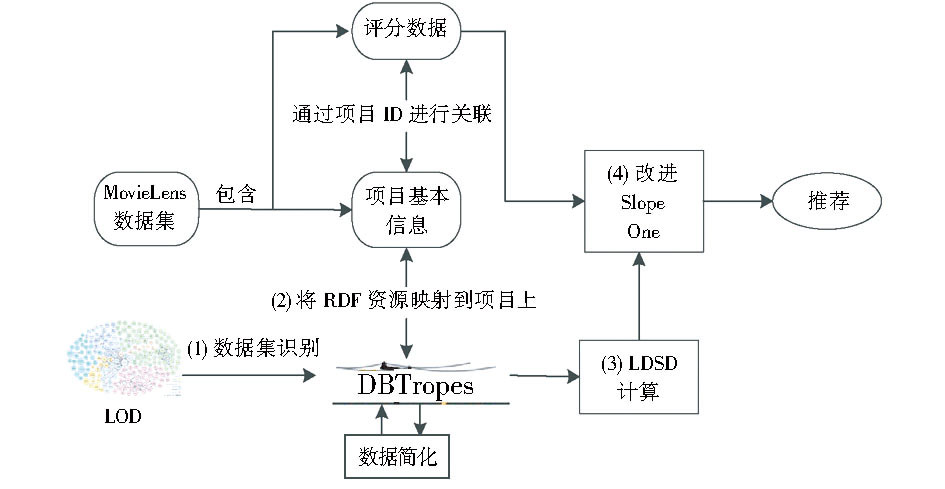 | 图5 基于关联数据的Slope One协同过滤[ 29] |
这是一个基于关联数据的协同过滤推荐方法的应用型实例, 其中加权Slope One协同过滤推荐方法是一种比较流行的工业推荐方法, 以MovieLens数据集为基础, 将外部关联数据集DBtropes与之融合作为最终的背景数据, 实现对用户的协同过滤电影推荐, 并讨论比较了多种基于语义距离的转换融合方案在推荐准确率及效率等方面的性能。相比一般的加权Slope One协同过滤推荐方法, 实验结果表明, 无论是线性转换融合方案还是非线性转换融合方案, 在推荐的准确率 (均方根误差、平均绝对误差) 及效率 (运行时间) 等方面都有一定程度的提高。
(3) 基于知识的推荐
基于知识的推荐在某种程度上可以看成是一种知识推理技术[ 30], 此方法不需要构建用户偏好模型, 而是利用某领域的规则来进行推理。利用关联数据内部固有的关联关系及领域本体语义知识信息, 能够实现跨领域的项目推荐策略。例如文献[31]利用关联数据库中涉及建筑领域和音乐领域的语义本体信息, 首先构建一个有向加权非循环图, 并基于此图, 利用两个领域中的不同语义实例及它们之间的关联关系, 构建一个跨领域语义网, 最后利用此网络中两个实例间的加权关联关系, 实现对目标用户的跨领域知识推理推荐。另外, 文献[32]提出的DiPRec数字存储推荐系统也是此类推荐系统中的一个典范, 如图6所示:
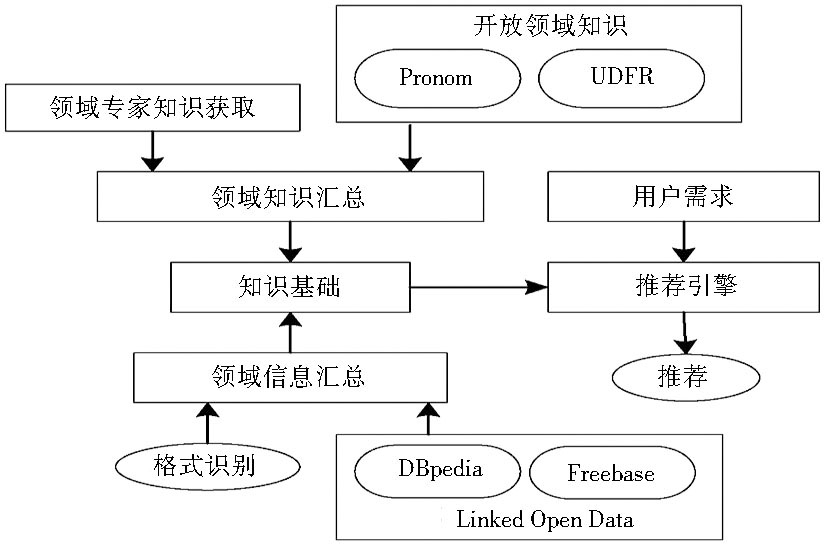 | 图6 DiPRec数字存储推荐系统[ 32] |
基于知识的推荐方法的核心内容主要包括领域知识的聚集和用户需求的获取。对于不同的应用领域, 领域知识的聚集规则及实例分类方法存在较大差异, 从而导致此类推荐实例不存在普遍的适用性, 只适用于特定的应用领域, 但是整体的设计流程基本上是一致的。在DiPRec数字存储推荐系统中, 首先设计领域知识聚集算法及用户需求提取算法, 分别从4个不同的信息源 (Pronom、DBpedia、Freebase和Wikipedia) 中收集领域知识, 并制定推荐推理准则, 根据用户需求为其推荐适宜的内容。
为了不同的实际应用场景, 上述三个实例从基于内容的推荐、协同过滤推荐和基于知识的推荐, 都将多源关联数据作为背景数据, 分别实现了基于关联数据的推荐系统, 充分体现了基于关联数据的推荐系统的特征。基于关联数据的推荐系统即在传统推荐系统的单一平台、单数据源的基础上, 充分利用关联数据的特点, 特别是关联公开数据平台的多源数据的关联特征, 扩展一般推荐算法, 设计与实现适用于跨平台、多数据源的推荐系统。在此过程中, 如何将以RDF形式关联的多源数据融合转换在一起, 或者进一步转换成能够使用一般推荐算法的数据格式 (例如文献[18]) ;或者设计行之有效的推荐算法 (例如文献[32]) , 是此类推荐系统的核心部分。
3 结 语
随着语义网技术的发展, 特别是LOD项目的启动及在线关联数据数量的逐渐增大, 如何应用这些关联数据, 为用户提供丰富多彩的网络服务成为当前研究的热点话题之一。推荐系统作为个性化服务的重要解决方案之一, 目前广泛应用于电子商务、社交网络及各种专业网络服务站点, 能够主动为用户提供个性化网络服务, 有效避免了用户在庞大的网络环境中搜索信息而面临的信息过载问题。将不同领域的关联数据作为推荐系统的背景数据源, 一方面可以为用户提供跨领域个性化推荐服务;另一方面可以有效缓解传统推荐系统中由于不充分的单一背景数据源而产生的数据稀疏性及冷启动问题。因此, 近年来基于关联数据的推荐系统逐渐引起了学者们的关注与研究。本文首先全面总结基于关联数据的推荐系统与传统推荐系统的异同点, 并系统地分析基于关联数据的推荐系统的主流技术方法。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|