{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
分阶段融合的文本语义相似度计算方法
引用本文
马军红. 分阶段融合的文本语义相似度计算方法. 现代图书情报技术, 2013, 29(10): 20-26
Ma Junhong. A Staged and Integrated Semantic Similarity Algorithm of Text. New Technology of Library and Information Service, 2013, 29(10): 20-26
Permissions
Ma Junhong. A Staged and Integrated Semantic Similarity Algorithm of Text. New Technology of Library and Information Service, 2013, 29(10): 20-26
分阶段融合的文本语义相似度计算方法
摘要
面向中文文本的信息检索, 提出一种从句子、段落到文本整体分阶段进行的文本相似度计算方法。该方法结合文档的主题与应用范围, 用语义加强的权重计算方法对特征词赋予相应的权重, 并根据每个计算阶段的特点, 分别融入对文本语义的计算因素, 力求使中文文本的相似度计算结果更为准确。最后建立文本相似度计算系统, 通过与传统算法的实验结果进行对比, 证明改进后的算法可以取得更好的效果。
关键词:
文本相似度; 信息检索; 语义相似度; 权重
A Staged and Integrated Semantic Similarity Algorithm of Text
Abstract
For Chinese text information retrieval, a staged and integrated similarity algorithm of text is proposed, which processes sentences, paragraphs and the whole document stage by stage. The algorithm combines the topic and application ranges of document, and the corresponding weight is given to the feature words via the weighted calculation method with the semantic enhancement. Moreover, these weights are integrated into the calculated factors of the text semantic with the characteristics of each calculation phase, respectively to reach the aim of finding a more accurate similarity calculation results for Chinese text similarity calculation. Finally, a text similarity computing system is built and the improved algorithm of the system achieves better experimental results comparing with the traditional algorithms.
Keyword:
Texts similarity; Information retrieval; Semantic similarity; Term weight
1 引 言
如今, 各行各业的人们都能通过网络平台自由发布和下载信息, 使得信息量不断增加, 其中有大量重复和无用的信息。如何提高效率, 轻松快捷地在这些信息中提取真正需要的东西, 是信息处理领域的热点和难点。文本相似度的有效计算可以应用到文本分类、文本聚类、信息检索、问答系统、网页去重等很多领域。
文本信息是一种非结构化或半结构化的信息, 它是现实生活中能获取的大部分信息的存在形式。就目前来说, 尽管图像、视频等多媒体信息资源飞速增加, 文本信息仍然占有相当大的比例, 几乎达到70%以上[ 1]。然而, 在文本相似度计算领域仍然存在不少问题需要人们解决, 尤其是对中文文本相似度的研究。利用计算机来实现自然语言理解, 中文比英文更加困难。中文不像英文那样词与词之间有明显的分隔标记, 它用多个连续的字词一起表达一个意思, 根据上下文语境的不同, 还容易引起歧义。缺乏坚实的理论依据和不能完全拟合文本的特性, 是现有的文本相似度计算模型的弱点, 如何改进中文文本的相似度计算方法, 提高相关应用的效率, 值得进一步研究和讨论。
2 文本相似度计算的特点及分析
2.1 文本相似度研究综述
文本相似度计算的核心是比较两个给定的文本 (可以是字节流等) 之间的差异, 通常用[0, 1]之间的一个数值来度量[ 2]。在不同领域, 国内外学者已经提出了很多相似度计算方法并应用于实践。如向量空间模型 (Vector Space Model, VSM) 、布尔模型、隐含语义标引等统计模型、字符串匹配模型、基于语义理解的模型等。其中, VSM是借鉴了统计学理论的向量概念而提出的。其核心思想是用向量来表示文本, 将一个文本映射到n维的向量空间, 可用TF-IDF方法来计算权重, 建立文本的数学模型, 这样文本间的相似度就可以用向量之间的关系来计算, 最常用的是余弦距离计算方法[ 3]。字符串匹配模型是用字符串来代表文本的基本组成单位, 如LD算法 (Levenshtein Distance) , 又称为编辑距离算法 (Edit Distance)[ 4]。这种算法是将字符串A通过插入字符、删除字符、替换字符变成另一个字符串B, 那么操作过程的次数就表示两个字符串的差异。基于语义理解的模型在进行相似度计算时, 更多考虑的是文本的语义距离、语义相关性, 希望深层次地挖掘文本含义, HowNet知网与WordNet体系就是基于这种思想建立的[ 4]。但现在这类研究大多注重在词语和句子层面, 取得的成果不多。
具体的说, 文本相似度的计算在应用系统开发方面效果显著。主要有基于内容的搜索引擎, 代表性的系统有北京大学天网、百度、慧聪等搜索引擎[ 5]。还有信息自动分类、自动摘要、信息过滤等文本级应用, 如上海交通大学纳讯公司的自动摘要、复旦大学的文本分类、中国科学院计算技术研究所基于聚类粒度原理VSM 的智多星中文文本分类器等[ 6]。可以看出, 在信息处理各个领域, 文本相似度的计算是无处不在的。
2.2 文本相似度的定义
相似度被应用于不同的领域, 它所代表的意义也不一样。比如基于实例的机器翻译, 一个词语将会用几个意思相同或相近的词语进行解释, 这就侧重于考量词语之间的相似度;在FAQ自动问答系统中, 用户查询的问句需要能迅速地在数据库中找到匹配问句的答案, 这考量的是句子与句子之间的相似度, 其中还要包含一定的语义相似度;在文本查重、版权维护与剽窃检测系统中, 相似度则用段落与段落之间的相似度来度量[ 7];在信息检索中, 为了使检索结果更迅速、准确, 需要对数据库中的文本集合进行分类、聚类、排序等操作, 这就需要分析计算文本与文本之间的相似程度。
目前的研究主要关注查询词与文本的相似性, 较少涉及文本与文本的相似性。本文主要研究的是整篇文本之间的相似度, 如论文、申报书等。对于中文文本, 在计算相似度时不应该单纯依靠词语的相近或者句子、段落的相似来判断, 还应包含语义的理解, 因此做如下定义:
文本相似度是指对于给定的两个或多个完整的文本, 通过语句、段落的层层计算而得到它们之间的整体相似程度, 同时包含了一定语义上的相似程度。
2.3 文本相似度计算的实现过程
计算中文文本的相似度, 一般需要包括文本预处理、文本特征表示、特征选择和相似度计算几个过程。首先对输入的文本D进行文本预处理, 在此基础上进行文本特征表示, 然后经过特征选择抽取有用的特征, 最后进行相似度计算, 得到相似百分比[ 8]。将这个相似度计算结果与提前确定好的相似度阈值Simmin进行对比, 从而检测出相似的文档。
(1) 文本预处理:是建立文本表示模型的基础, 目的是将非结构的文本信息表示成结构化的形式。本文研究的是中文的文本相似度计算, 这一部分的主要工作是中文自动分词和停用词处理。
(2) 文本特征表示:一般是基于词的方法, 即选取文本中意义较大的实词来表示, 以双字词为主, 也有三字词和四字词等多字词。除此之外还有Shingling算法, 它是将相邻的两个或两个以上的词语以一个整体作为特征项。
(3) 文本特征选择:在计算相似度时, 希望待比较的意义不大的特征项能够减少, 需要进行特征抽取和降维处理。因此, 文本特征选择成为文本相似性计算不可或缺的步骤。目前, 文本特征选择可以使用权重的计算方法, 或者定义某一个随机数。常用方法主要是:文档频率法 (Document Frequency, DF) 、信息增益法 (Information Gain, IG) 、互信息法 (Mutual Information, MI) 、χ2统计法 (CHI) 等[ 9]。其中IG和CHI、MI等属于有监督的特征选择算法, DF属于无监督的算法, 可以直接应用于聚类。
3 分阶段融合的语义相似度计算方法
本算法的基本思想是:分层次划分文本, 将文本划分为段落, 段落划分为句子, 句子划分为词语;进行文本特征选择;分阶段计算词语、句子、段落的相似度, 融合后计算出文本的相似度。在每个阶段融合语义相似度计算, 完成局部到整体的结合。由于特征词的选择是非常重要的一个环节, 为了提高最终的计算效率, 本文先对传统特征词的权重算法进行改进。
3.1 语义加强的权重计算
在向量空间模型VSM中, 文本被表示为由特征项组成的向量, 而特征项的权重就是文本向量空间的坐标值[ 5]。特征词的权重对于文本的表示起着非常重要的作用, 它的取值也影响着文本间相似度的计算结果。TF-IDF权重计算方法是目前基于VSM使用最多的计算方法。但这种方法是基于词频的方法, 如果一个词在文本预处理阶段被选择作为特征词, 那么在计算词频的时候和其余被选择的词将不加区别同等对待。这种计算过于片面, 没有考虑到特征词与文档内容相关性、上下文语境或者应用领域等其他因素。
因此, 本文提出一种新的语义加强的权重计算方法, 在前期文本预处理阶段计算词频时, 可以结合文档的主题、范围、应用等, 对所选中的特征词赋予相应的权重f。
借助上述思想, 本文将TF-IDF算法进行改进:
首先使用传统的TF-IDF公式来计算权重wij:
设L为文本集合文本总数, w代表权重, IDF被定义为:

这里引入了两个参数β1和β2, 用传统公式计算的权重wij仍然占较大的比重, 但需要结合语义影响的因素进行调整。β1和β2两个参数之和为1, 其中β1表示的是用基于词频统计的方法计算出来的权重值对最终权重值所占的比重。引入这个参数是由于基于词频统计的权重计算方法虽然有一定的科学性, 但其提取的特征词不能完全表达出文本语义信息, 例如“算法”与“方法”, 一般同类别的科技性文章, 通常都包含这两个词语, 由于它们在整篇文章中可能出现的次数较多, 会被优先选择为特征词条, 而这些应该属于文本区分度较低的词语, 不能简单因为出现的次数多而被设置为特征词。因此β1的取值范围应在0.6-0.9之间。β2表示的是语义理解因素所占的比重, 对应β1的取值范围在0.4-0.1之间。这样可以根据文本的语义特征来计算权重, 选取的特征词比简单依靠词频统计的方法所包含的信息量要高。而fi的取值将根据特征词本身的属性来设置。一般文章的特征词分为三类:专业领域术语、非领域术语和一般词语。对于专业领域术语, 其对于整篇文档的影响较大, 因此fi的取值为1。非领域术语与一般词语的影响逐渐减低, 其fi值可设置为小于1的数。在具体实验时需要结合检测文本的类别、主题或关键词, 在对应范围中取不同的参数值进行交叉对比。
综上, 改进的权重计算方法加强了语义方面的考虑, 更能体现特征项在文档中的影响程度。另外, 新的计算公式中引入了三个参数, 在计算时可根据需要具体设置, 方法灵活实用。
3.2 文本语义相似度计算
通过分词系统将句子划分为若干词语, 经过去除停用词等文本预处理操作, 然后使用上述改进的TF-IDF算法提取特征词, 接下来即可以分阶段地进行相似度计算。
(1) 词语相似度计算
借助知网的知识结构, 在义原相似度计算时考虑其在义原分类树相对位置, 利用如下公式[ 11]来计算:
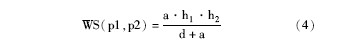
其中, pl、p2表示两个义原, 它们的语义距离为d, 代表p1和p2的路径长度, a是一个可调节参数, 它的值代表相似度为0.5时的路径长度。pl、p2在义原树中的深度, 记作h1、h2, 代表它们在分类树上的相对位置, 作为影响因素也考虑进去。
(2) 句子相似度计算
经过词语划分、特征抽取, 句子L (含n个特征词) 和R (含m个特征词) 表示为以下向量形式:

即取矩阵中每行元素的最大值作为L的特征词Li与R的相似度值, 将这n个最大值相加, 取平均值就得到了L与R的相似度。
为了能准确地得到这两个句子的相似度, 本文采取的方法是利用公式 (5) 计算S (L, R) 与S (R, L) , 然后取两者的平均值, 从而确保了计算结果的唯一性。
(3) 段落相似度计算
将段落看作是句子的集合, 求其对应句子相似度的最大值。
设有两个段落X、Y, X被分为t个句子, Y被分为d个句子, 则相似度计算公式如下:
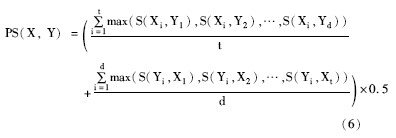
在算法设计时, 对于段落中已经计算过相似度的句子组合, 句子中已经计算过相似度的词语组合, 均不再进行计算, 直接赋予前值, 以提高效率。
(4) 文本相似度计算
前面的计算使用的是取最大值相加再平均的方法, 将段落中出现的词语、句子同等对待。这样对基于段落相似的文本整体相似度计算阶段来说过于简单和片面。本文考虑到根据段落所处文本的位置不同, 其重要程度也就是对文章的影响也不同, 应赋予不同的权重。如果关键段落相似, 则整篇文本的相似度也随之提高。
设D1, D2为两个待比较的文本, D1有m个段落, D2有n个段落, 为了方便起见, 统一用X表示D1中的某个段落, 用Y表示D2中的某个段落。则根据公式 (6) 计算出来的段落相似度记为:PS1 (X1, Yj) , PS2 (X2, Yj) , …, PSm (Xm, Yj) , j=1, 2, …, n。用SSi (X, Y) 表示新的段落相似度值, 则有:
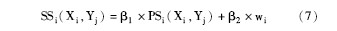
其中, β1+ β2的值为1, wi为段落的权重, 具体取值均可根据需要设置。本文取β1 为0.8, β2为0.2, 关键段落的权重w1为1, 普通段落的权重w2为0.9。
则D1和D2的相似度计算公式如下:
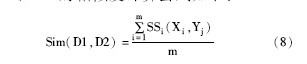
在实际的应用过程中, 考虑到长文本通常段落比较多, 很多较低的相似度对整篇文本影响几乎为零, 可以预先设置一个相似度阈值, 低于整个阈值的段落不再加入后面的权重计算, 从而降低系统的开销, 进一步提高效率。
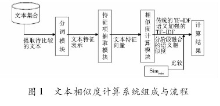
4 文本相似度计算系统的组成与实现
4.1 系统的组成模块
系统包括了文本预处理 (中文自动分词) 、文本特征向量的表示、特征向量的选择和相似度的计算等步骤, 主要由以下几个模块组成:
(1) 文本库模块:用于存放要进行相似度计算的中文文本;
(2) 分词词典模块:管理和维护作为中文分词依据的词典;
(3) 中文分词模块:对给定的中文文本进行分词处理并进行歧义校正;
(4) 特征词抽取模块:根据分词结果和词频统计分析, 提取出代表待比较文本的特征向量及其中包含各词条对应的权值;
(5) 相似度计算模块:计算文本特征向量的相似度。
4.2 系统的工作流程
(1) 从文本库中取出要进行相似度计算的两个文本;
(2) 使用中文分词器IK Analyzer3.2进行分词处理;
(3) 抽取文本特征向量并确定权值;
(4) 根据不同的相似度算法步骤计算文本之间的相似度。
文本相似度计算系统组成与流程如图1所示:
 | 图1 文本相似度计算系统组成与流程 |
5 实验与结果分析
5.1 实验数据集
本实验采用某研究单位的测试数据集, 使用MySQL数据库。从中选取了210篇计算机、汉语语言文学、经济管理方向的文本, 根据不同的篇幅分为三组, 使用三种相似度计算方法分别进行测试, 即:
(1) 传统TF-IDF方法:传统TF-IDF方法是基于VSM的, 利用余弦函数计算相似度;
(2) 语义加强的TF-IDF方法;
(3) 分阶段融合的语义相似度计算方法。
为了更好地验证本文提出的改进算法, 先将传统的TF-IDF权重计算方法和改进后的TF-IDF方法进行实验对比, 然后再使用上述三种方法进行完整的相似度计算实验。
实验选取的文本篇幅分布情况如表1所示:
| 表1 实验文本篇幅分布 |
评估相似度计算的效果一般使用的评估指标是F-measure值, 简称F值。F值是准确率 (Precision, P) 与召回率 (Recall, R) 的协调均匀数。F值的计算公式如下


如果F值与1越接近, 说明Precision和Recall均衡得越好。相反, 如果F值与0越接近, 则表示两个参数均衡性越差。
5.2 实验结果与分析
(1) 传统TF-IDF权重算法与语义加强的TF-IDF算法
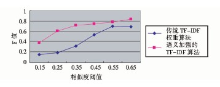
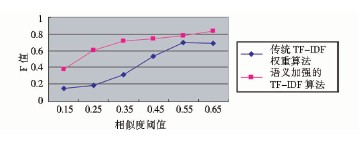
在这两种算法中, 均使用不同的相似度阈值进行实验对比, 大于等于此阈值的被视为相似文本[ 7]。实验对比结果如图2所示:
 | 图2 两种算法F值对比 |
从图2可以看出, 语义加强的TF-IDF算法的效果总体比传统的TF-IDF权重计算方法效果要好。对于0.25-0.55之间的相似度阈值, 其取得了比较稳定的F值变化, 可靠性较强, 而这个阈值范围正是在检测相似度的时候最常用的范围。而基于TF-IDF算法的F值显示其均衡性较差, 最高值也没有达到0.7, 尤其在阈值为0.15-0.55之间结果很不稳定。这主要是因为传统的统计算法使得一部分低区分度的词成为了特征词, 算法的准确率不高。而添加了语义因素的算法, 考虑了文本的属性、类别等影响, 更能体现文本的特性, 计算的结果也较为准确。
(2) 不同相似度计算方法对比
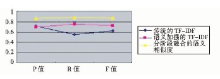
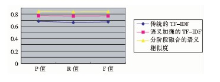
经过上述实验比较, 可以得出添加语义因素的算法是可行的。本文将分阶段融合的语义方法与前两种方法应用于相似度计算中。由于实验数据较多, 现取相似度阈值为0.3为例。第1组实验结果如表2与图3所示:
| 表2 相似度计算方法的对比1 |
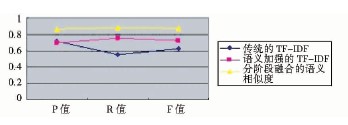 | 图3 相似度计算方法的对比1 |
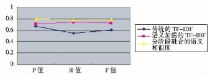
| 表3 相似度计算方法的对比2 |
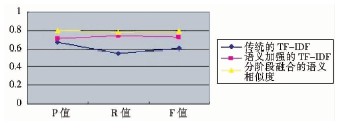 | 图4 相似度计算方法的对比2 |
| 表4 相似度计算方法的对比3 |
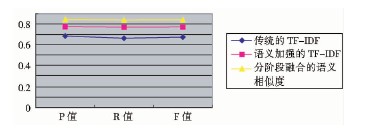 | 图5 相似度计算方法的对比3 |
根据准确率和召回率的含义分析可知, 当准确率很高但是召回率很低时, 说明该系统查找相似文本的命中率很高, 也就是误判的数量少, 但是查找不全面, 即还存在许多相似文本没有找出;相反, 如果召回率较高而准确率不高, 就是把许多非相似的文本看成是相似的, 即引起了很多误判, 但是实际存在的相似文本大部分都已找出[ 12]。这两种情况皆是不理想的, 只有二者相当, 才能说明找出来的相似文本确实相似, 并且把实际存在的相似文本已经基本上都找出来。通过F值调和平均, 可以对相似度计算方法的效果进行均衡评估。从上述三组实验数据可以看出, 本文的分阶段融合的语义相似度计算方法的准确率和召回率基本相当, F值显示这两个参数的平衡性也较好, 比其他方法的相似度计算准确性得到了提高。其中语义加强的TF-IDF方法也取得了较好的效果, 传统基于VSM的TF-IDF方法运行不太稳定, 效率较低。这个结果体现出对于中文文本的相似度计算, 语义理解的方法要比单纯的统计计算方法更适合。
6 结 语
目前, 越来越多的专家学者研究文本相似度计算, 这是因为文本相似度的有效计算可以起到提高检索效率、避免文章剽窃、节省存储空间等作用。而中文的文本相似度计算处理非常复杂, 在具体应用中还有很多不确定性。本文从语义理解的角度出发, 对传统算法做进一步的改进, 使得中文文本相似度计算的效率有所提高。在后续的实验中还可以采用其他方法进行对比, 并加大实验数据规模和实验次数, 更准确地分析和发现本方法的优缺点, 使之运行更加稳定。另一方面, 如何建立一个更好的语义理解模型, 把它应用到更多的具体领域进行验证, 比如文本检索、信息查询、文本聚类等, 也是下一步研究的重点。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|