文本分类中TF-IDF方法的改进研究
引用本文
覃世安, 李法运. 文本分类中TF-IDF方法的改进研究. 现代图书情报技术, 2013, 29(10): 27-30
Qin Shian, Li Fayun. Improved TF-IDF Method in Text Classification. New Technology of Library and Information Service, 2013, 29(10): 27-30
Permissions
Qin Shian, Li Fayun. Improved TF-IDF Method in Text Classification. New Technology of Library and Information Service, 2013, 29(10): 27-30
文本分类中TF-IDF方法的改进研究
摘要
针对TF-IDF在待分类文本类的数量分布不均时提取特征值效果差的问题, 提出使用特征值在类间出现的概率比代替特征值在类间出现的次数比以改进TF-IDF算法。实验证明利用改进后的TF-IDF方法提取网页文本特征值, 并配合简单累加求和的分类器, 使得网页文本分类的准确率有明显提高, 且分类速度加快。
关键词:
概率; TF-IDF; 网页; 文本分类
Improved TF-IDF Method in Text Classification
Abstract
When the count of one class is much more than another class’s, the result of IDF in TF-IDF goes the wrong way according to its design idea. This paper solves the problem by using probability to change TF-IDF algorithm. In the end, the experiment proves that the solution mentioned above is good at classifying webpage text through a simple way to cumulative sum the value of characteristic words and the speed is faster and the accuracy rate is promoted.
Keyword:
Probability; TF-IDF; Webpage; Text classification
1 引 言
目前有很多中小网站面临信息发布不及时、发布的信息缺乏时效性等问题。这多是因为网站实力不雄厚, 无法及时获得用户所关注领域的信息。针对这种情况, 网站设计者采用了使用网络爬虫爬取与本站关注领域相关信息的策略。然而面对互联网中海量的信息, 如何对网页文本正确地分类成为一个难题。文本分类是指对未知类别的文档进行自动处理, 根据文档内容判断其属于预定义类别集合中的哪一个或哪几个类别[ 1]。要进行网页文本分类首先要对网页进行预处理, 然后提取文本特征词。文本特征词提取运用最广泛的方法是TF-IDF。
2 国内外研究现状
TF-IDF最早应用在信息检索领域, 由于其计算方法简单实用, 在业界得到普遍的应用, 但是它也存在缺点, 国内外学者对其进行了大量的改进工作, 主要是围绕IDF计算方法的改进。
学者鲁松等[ 2]认为词语在文本集合中的分布比例量上的差异也是词语表达文本内容的一个重要因素, 而TF-IDF无法描述这个差异, 因此他们提出tf.idf.IG方法来解决这个问题。在tf.idf.IG中词语的信息增益作为一个文本表示的因子, 用来衡量词语在文本集合中分布的量上的差异, 通过实验证明tf.idf.IG的分类效果优于TF-IDF方法。罗欣等[ 3]将互信息量和信息增益两种思想同时用来改进TF-IDF的分类思想, 提出基于词频差异的特征选取 (WFDBFS) 方法。 实验结果表明基于词频差异的特征选取方法的分类效果优于单独应用互信息量的分类效果和单独应用信息增益的分类效果。张保富等[ 4]针对传统TF-IDF方法将文档集作为整体来处理并没有考虑到特征项在类间分布不均的情况, 提出一种结合信息熵的TF-IDF改进方法。该方法采用结合特征项在类间和类内信息分布熵来调整TF-IDF特征项的权重计算, 避免了那些对分类没有贡献的特征项被赋予较大权值的缺陷, 能更有效地计算文本特征项的权重。
国外学者Forman[ 5]用概率统计方法度量并比较关于类别分布的显著性, 提出用二元正态分隔 (Bi-Normal Separation) 计算方法替代TF-IDF中的IDF计算方法, 实验结果表明这种新的TF-IDF在文本特征词的选取中表现优异。Lan等[ 6]用相关性频率 (rf) 去重代替传统IDF计算方法, 给出rf=log (1+ni/ni-) 计算公式, 通过实验证明用TF-RF进行文本分类具有更好的区分能力。Oren[ 7]为了寻找出更好的TF-IDF计算方法, 利用遗传编码的方式并使用不同适应度函数去寻求一个新的TF-IDF。利用这种方法进行文本分类准确率有了相应的提高。
虽然还有一些学者用其他的方法改进TF-IDF的计算方法, 但在实际应用中应用最多的还是以上几种改进方法[ 5]。但对信息增益、互信息量、信息熵、二元正态分隔、相关性频率等计算量很大, 计算复杂度高。针对这种情况, 本文提出一种提取文本分类中特征词的简单高效的改进方法, 并通过实验证明了该改进方法的有效性。
3 TF-IDF及其改进
3.1 TF-IDF的思想及其存在的问题
以表1为例, 有C1, C2两个类, m1, m2 为两个特征值词。在C1, C2中包含m1, m2特征词的文档数分别为9篇、5篇、1篇、5篇。m1, m2在类C1中IDF值分别为IDF1, IDF2, 则IDF1=log (10/9+0.01) =0.0496, IDF2=log (10/5+0.01) =0.303。IDF1, IDF2的值表明m2比m1具有更好的分类效果。但是据实际观察m1分布不均匀而m2分布很均匀, 表明m1比m2具有更好的类别区分能力。
TF-IDF[ 8] (词频率-逆文档频率) 的主要思想是:特征词在文档中的权重为特征词在文档中出现的频数反比于包含该特征词的文档数目。TF表示特征词m在文档D中出现的频率, IDF表示所有文档中出现特征词m的文档数目。
常用的计算方法如下:

其中, N为总文档数, n为包含某项特征词的文档总数。
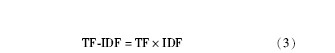
TF-IDF是信息检索领域常用的方法, 其涵义是如果一个特征词在某个文档中多次出现, 且其他的文档包含该特征词较少, 则该特征词能够很好地表示该文档。TF为某一特征值在文档中出现的频数, 反映文档的内部特征, IDF为某一特征值在整个文档集合中的分布情况, 反映文档间的特征。
TF-IDF将文档集作为整体处理, 特别是IDF的计算, 在文本分类中存在明显的缺陷:在公式 (2) 中令n=n1+n2, n1表示ci中包含特征词m的文档数目, n2表示其他类中包含特征词m的文档数目。当n1>>n2时, 在总的文档数N一定的情况下, IDF的值很小。然而实际情况是特征值m在类ci中出现的频率远远大于在其他类中出现的频率, 特征词m应该有很好的区分能力, 而这里却与期望的结果恰好相反。
| 表1 m1、m2的特征分布 |
3.2 TF-IDF方法的改进
现有待分文档类别的集合S={C1, C2, …, Cj}, 在Ci (Ci∈S) 中有文档集合D={d1, d2, d3, …, dn}, n为文档数目。特征词的集合为M={m1, m2, m3, …, mk}, k为Ci中所有出现的词语个数。针对3.1节提出的问题, 在计算IDF时可以用特征值在类间出现的概率比代替特征值在类间出现的次数比来解决。根据大数定律[ 9]的特性, 假定某类文档的作者在书写该类文档时用到哪些词组是一个随机事件, 因此可以用P (mk) 表示词组mk在类Ci中出现的概率, count (mk) 表示词组mk在Ci中出现的次数。则:
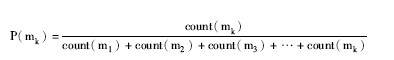
一个类的文档的特征词应该有很好的代表该类文档的特征信息, 用P (mk) 表示词组mk在类Ci中出现的概率, P (mk) ′表示词组mk在S中除了Ci以外的类中出现的概率之和。令:

根据公式 (4) 再次计算表1中特征值m1, m2的IDF。IDFm1c1=log (1+9/141/6) =0.552, IDFm2c1=log (1+5/145/6) =0.155, IDFm1c1>IDFm2c1, 表明词组m1的分类效果好于m2, 这与事实相符。
4 实验设计及结果分析
4.1 文本表示方法
用改进后的TF-IDF方法来提取训练文档集中每个类的特征词, 并把特征词按照所计算的TF-IDF值从大到小的顺序排列。从有序的特征词集合中选择前m个TF-IDF值较大的特征值词组成特征向量。对于每一个文档di, 先进行切词处理, 统计文档di中每个词组出现的次数。对照di所属的类ci的特征向量进行标记。如果di中的词组word1在特征向量中出现, 则标记为1, 没有出现则标记为0。
例如文档集合类ci的特征词组成的特征向量为{汽车、前窗、奥迪}, 文档di分词后的结果为:“汽车, 玻璃, 前窗, 汽车, 颜色, 轮胎”, 则文本文档di表示为“101100”的字符串。
4.2 文本分类方法
文本分类的方法很多, 分类器实现的复杂程度各不相同。为了追求计算的高效性并验证特征词提取的准确性, 本文使用文档与文档所属的类的相似度进行分类。文档di与类ck之间的相似度S (di, ck) 计算公式如下:
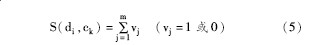
当文档di和类ck的相似度值大于di与其他类的相似度值时, 文档di被划分到类ck, 例如文本文档d1相对于文档类别c1, c2, c3的表示字符串向量依次为:c1:111001, c2:100100, c3:000100, 按照公式 (5) 就有:
S (d1, c1) =1+1+1+0+0+1=4
S (d1, c2) =1+0+0+1+0+0=2
S (d1, c3) =0+0+0+1+0+0=1
d1与c1的相似度最大, 证明它们的相似程度最高, 因此d1被划分到c1。
4.3 评价指标
对于文本分类系统的性能评估测试, 国际上有通用的评估指标, 包括查全率 (Recall) 、查准率 (Precision) 和 F1评估值三项[ 10]。本实验是为了测试改进的TF-IDF方法对文本分类精度影响, 因此, 采用查准率作为评价改进后的TF-IDF方法提取特征值好坏程度的指标。另外, 错误率为查准率的互补, 用来检验程序是否正常运行, 查准率和错误率之和等于1。
4.4 实验描述及结果分析
数据集来自自编爬虫下载的新闻网页, 首先去掉网页中标记, 然后按类别储存。数据集一共有6个文本类, 每类有4 000篇文章, 依次为汽车、文化、医药、军事、体育和经济。随机在每个类中挑取100篇文章作为测试集, 其他3 900篇文章作为训练集。采用的分词系统是中国科学院计算技术研究所的ICTCLAS[ 11]。实验采用Java自编程序实现, Java的JDK为JDK7, 运行硬件为装有XP系统、主频为3.3GHz、内存为4GB的联想台式机。经过多次实验测得, 选取每个类中使用改进后的TF-IDF方法所计算的特征值按从大到小排序后的前200个特征词组成该类的特征向量时, 分类效果最佳, 具体实验结果如表2所示:
| 表2 不同个数特征词对应的整体查准率 |
为了证明改进后的TF-IDF方法的有效性, 本文把对TF-IDF具有相似改进思想的文献[12]提出的方法用于该数据集, 实验结果如表3所示:
| 表3 改进TF-IDF实验结果和文献[12]方法实验结果对比 |
表3中颜色较深的行显示的是本文提出的改进IF-IDF方法的实验结果, 颜色较浅的行显示的是文献[12]提出方法的实验结果。结果表明用基于概率的TF-IDF方法在进行网页文本特征词提取后, 在进行汽车、军事文档分类时分类的准确率与文献[12]的方法相当, 在进行文化、医药、体育、经济类文档分类时分类准确性均优于文献[12]的方法。在对相同的600篇文档分类测试中, 本文提出的改进方法耗时较短。
5 结 语
本文根据大数定理修改了TF-IDF中IDF值的计算方法, 使得IDF的计算方法更符合其设计思想。并用实验证明这种改进是有效的且分类精度较高, 加之其运算过程简单快速, 因此适合企业网站采用。
TF-IDF方法的改进工作还需进一步完善:当两个类别相近时, 本文提出的改进方法的分类效果不好, 比如实验中容易将报道汽车的文章划分为报道经济的文章。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|