
{kind=link}
{kind=link}
{kind=link}
{kind=link}
P2P用户兴趣社区形成研究
引用本文
赵捧未, 马琳, 秦春秀. P2P用户兴趣社区形成研究. 现代图书情报技术, 2013, 29(10): 53-58
Zhao Pengwei, Ma Lin, Qin Chunxiu. Formation of Interest-based Peer-to-Peer Community. New Technology of Library and Information Service, 2013, 29(10): 53-58
Permissions
Zhao Pengwei, Ma Lin, Qin Chunxiu. Formation of Interest-based Peer-to-Peer Community. New Technology of Library and Information Service, 2013, 29(10): 53-58
P2P用户兴趣社区形成研究
摘要
基于共同的兴趣和需求, 对等网中的节点用户很容易形成虚拟社区。在简要总结已有的P2P社区形成研究工作的基础上, 分析P2P社区的形式化定义及结构, 描述节点用户兴趣的表示方法, 选取对等节点之间的兴趣相关度计算方法, 进而借助层次聚类法和K-means聚类法探讨P2P社区的形成过程, 以期为进一步研究P2P社区提供参考。
关键词:
用户兴趣; P2P社区; 层次聚类法; K-means
Formation of Interest-based Peer-to-Peer Community
Abstract
Based on common interest and purpose, a virtual community in P2P networks is formed easily by a set of peers. Based on the brief summary of the existing research of P2P communities formation, this paper analyzes its formalization definition and structure, describes the representing method of user interests, selects the calculation method of the interest correlation between peer nodes, and then by means of hierarchical clustering method and K-means clustering method to study the P2P community formation process, so as to provide reference for further research of P2P communities.
Keyword:
User interest; P2P community; Hierarchical clustering method; K-means
1 引 言
在这个互联网风起云涌的时代里, 国外社区型网站如Myspace、Facebook、YouTube、Twitter等均已兴起。当然, 中国的互联网也已经历了多次蜕变, 从老三家的“新浪、网易、搜狐”到新三家的“腾讯、阿里巴巴、百度”都在向社区化转型。互联网已经进入了一个用户之间互动的时代, 社区化是必然的趋势[ 1]。网络社区形成的意义是通过形成一个个的“圈子”, 制造出良好的用户体验, 比如促进网民文化交流、共享资源, 提供企业内容管理、信息管理, 进行竞争情报舆情分析、决策支持分析等, 同时为进一步营造健康有趣的互联网氛围贡献力量。另一方面, 依托“圈子”的力量增加用户粘度, 提高用户的活跃性, 从而反作用于“圈子”, 形成良性的循环式发展。
随着互联网与人们生活的联系日益紧密和深入, P2P(Peer-to-Peer) 技术与传统客户端/服务器(Client/Server, C/S) 模式相比较, 得到了更多关注和发展, 以其去中心化、可扩展性、健壮性、高性价比、平等开放、负载均衡等优点, 广泛应用于文件共享与交换、分布式存储、即时通信、信息检索、流媒体等多个领域[ 2]。此外, 研究发现P2P网络中也存在着社区结构, 即具有相同或相似兴趣的节点聚集成多个社区, 表现为社区内部节点连接较密集、社区间节点连接较松散[ 3]。社区作为P2P 网络的一个特性, 能够提高信息资源发现和共享的效率。为此, 本文拟研究P2P社区的形式化定义及结构, 描述节点用户兴趣的表示方法, 通过对对等节点之间兴趣相关度的计算和研究, 得出兴趣相关度高的节点聚集在一起, 从而形成P2P社区。根据用户兴趣自发形成的P2P 社区不仅能够解决信息过载的问题, 而且可以充分挖掘节点间的相互关系, 以实现更准确有效的资源共享。
2 国内外相关研究
由于对等网的自组织特点, 类比现实社会的一句俗语“物以类聚, 人以群分”, 拥有共同兴趣的节点以共享和需求为目的, 很容易形成虚拟社区。在对等网环境下, 国内外学者对用户兴趣构建社区的研究, 多以节点间所拥有的相同文件数作为相似度的衡量标准, 最早由Khambatti等[ 4]研究了如何形成和发现P2P社区的方法, 他们为避免模糊性匹配而预先建立一个属性集的公共词表, 每个用户的公开兴趣和个人兴趣都利用属性集来描述, 如果节点间的公开兴趣有公共集, 则判定其属于同一社区。张亮等[ 5]根据每个用户拥有的共享文件来确定用户的用户模式树, 利用两个分类树节点之间的相似度以及文档之间的相似度问题来研究两个用户模式树之间的相似度问题, 进而将用户兴趣相似的节点聚类以形成社区。周晓波等[ 6]采用树形结构层次化表达自己的资源兴趣, 同时产生一个二进制序列的社区, 每个社区对应唯一ID, 这样, 具有相近ID的节点能聚集成一个社区。牛尔力等[ 3]考虑到相似度与节点所拥有的总文件数相关, 可能造成随机性伪相似等问题, 设计了一种新的节点兴趣相似度计算方法, 使得每个节点依次联接其相似节点, 从而在Gnutella中构建兴趣网络并采用随机游走的方法发现社区结构。Wang等[ 7]给出了P2P语义社区的定义与结构, 根据基于用户兴趣分析社区的形成和节点信任度的变化, 研究了社区动态变化问题。
从以上的相关研究发现, 虽然基于用户兴趣构建对等网社区的研究已经有了一定成果, 但用户兴趣的挖掘和表示只是浅层次地利用对等网中的资源信息的语义, 而没有考虑语义实现中重要的语义推理机制和语义关系。为此, 赵捧未等[ 8]提出了一种新的研究思路, 即从知识地图的角度来表示节点资源以挖掘用户兴趣, 从而构建具有语义的P2P社区。知识地图(Knowledge Map) 是关于知识的知识表示, 通过对应用领域中知识表达的内容以及结构的联系可以快速检测知识资源[ 8]。同时, 随着语义网技术(OWL和WordNet) 的应用, 表示节点资源的知识地图可以有效反映节点的全局知识结构。此外, 无论是显性资源还是隐性资源, 知识地图不仅指向资源类别, 而且揭示资源之间的关系, 为节点用户的兴趣抽取提供了稳定的资源组织结构。通过对本地知识地图用户资源进行有效分组, 从而快速地从知识地图的框架结构中抽取并描述潜在用户兴趣, 并提供具有语义关系的用户兴趣模型。该研究虽利用知识地图构建了用户兴趣模型, 完成了用户兴趣特征的语义实现, 但对用户节点的兴趣相关度计算以及后期的社区定义、结构与形成并没有进行深入探讨。所以, 本文在其基础上进一步研究用户兴趣相关度的计算以及社区形成的过程。
3 P2P社区的定义与结构
P2P社区的形式化定义是研究P2P社区形成的理论基础和前提, 本文总结归纳前人对P2P社区模型的已有研究[ 7, 9], 对P2P社区进行如下定义:
对等网社区(Peer-to-Peer Virtual Community, PVC) :是一个6元组结构PVC =(CID, P, CP, CDi, θ, IT) 。
其中, 每个社区都由唯一一个CID(Community ID) 进行标识, 社区兴趣主题为IT(Interest Topic) ;P(Peers) ={ni, i=1, 2, …, m}, (m=|P|) , 表示P2P网络中的用户节点;CP(Community Peers) ={ni, i=1, 2, …, k}, (k=|CP|) , 表示某个社区内的节点, 节点间的兴趣相关度均大于θ;CDi(Correlation Degree for interest) =
社区结构:根据PVC定义得知对等网社区是在对等网环境下一组有着相同或相似兴趣的用户节点集合, 其社区结构如图1所示:
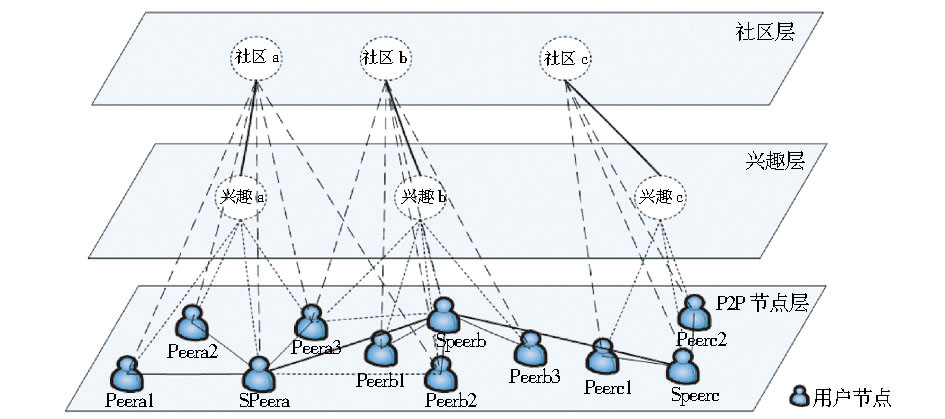 | 图1 P2P社区结构 |
需要说明的是:因为对等网环境下高度自治的节点自身共享的资源和资源需求经常发生变化, 所以节点的兴趣也在不断变化, 所以, 基于用户兴趣的P2P社区形成也是一个动态的过程。同时, 每个用户节点基于不同的兴趣会对应多个不同的兴趣社区, 例如图1中Peera3既属于社区a, 也属于社区b。
4 基于用户兴趣的P2P社区形成
4.1 用户兴趣表示
在对等网平台下, 本地知识地图是知识实体及其相互关联的集合, 知识实体是指挖掘出的知识资源的概念、类型、事实等。每个知识实体都包括挖掘出的知识唯一的身份信息标识以及它的属性及描述信息。同时, 知识地图清楚地揭示了相关知识的类型、特征及知识之间的相互关系[ 8]。本文在知识地图中抽取知识实体概念并对其向量化表示, 作为用户兴趣特征训练集。训练样本集S表示为:
S=((T1, WT1) , …, (Tn, WTn) )
其中, Tn为从知识地图中提取的用户兴趣向量特征词, WTn为该用户兴趣向量特征对于用户的重要程度, 即Tn所占权重, 使用特征项频率分布的离散度计算得出。
利用机器学习法中的支持向量机(SVM) 分类原理, 构造分类器, 集中挖掘用户兴趣, 并创建兴趣描述文件统一管理本地节点的兴趣。其中, 用户兴趣描述文件(User Profile) 表示为:
D={
UIn(UserInterestn) 为知识地图中抽取出的反映用户兴趣的主题词集合, ILn(InterestLeveln) 为对应的用户兴趣等级, 它不仅体现UserInterestn的兴趣浓度还兼顾了子类兴趣与父类兴趣的层次等级关系, 从而全面反映用户兴趣对用户的重要程度, 其计算公式为:
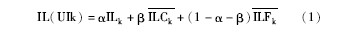
其中, ILCk表示用户兴趣UIk子类兴趣集合UIC中的兴趣等级平均值, ILFk表示兴趣UIk父类兴趣集合UIF中兴趣等级平均值, α、β为系统权重比例系数, 须说明的是只有兴趣等级大于系统限定阈值的才会被收集到用户兴趣描述文件中。
4.2 用户兴趣相关度计算
由前所述, 用户节点的兴趣相关度表达式CDi=
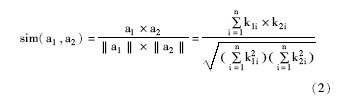
节点间的交互程度ID(Interaction Degree) 的计算公式为:
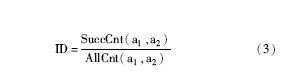
其中, SuccCnt(a1, a2) 表示节点1在节点2处得到满意结果的次数, AllCnt(a1, a2) 表示节点1向节点2发出请求的总次数。
最后计算节点用户的兴趣相关度CDi, 计算公式为:
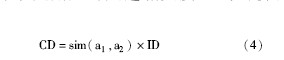
由公式(4) 可知, 节点间的兴趣关联度是双向的, 兴趣关联度越高说明节点间关系越密切, 节点的兴趣也就越相似。
4.3 基于用户兴趣的社区形成
P2P社区的形成是一个无监督、自组织的节点聚类过程, 社区形成的目标是要求同一社区内节点的兴趣相关度尽可能大, 不同社区之间的节点兴趣相关度尽可能小。目前关于聚类的方法有很多, 包括层次分析法、自组织神经网络算法、K-means、贝叶斯聚类算法和K-最近邻参照聚类算法等[ 10]。其中层次分析法系统、简洁、清晰, 但定性成分多、不易令人信服;自组织神经网络算法具有自学习、自适应等优点, 但存在样本依赖性、网络预测能力和训练能力的矛盾等问题;贝叶斯聚类算法是一种最小化误差的最优解决算法, 理论上完美, 但实际中并不能直接利用;K-means算法虽然有较理想聚类结果但是它必须先确定聚类参数k, 而且聚类结果要受到聚类中心初始值的影响。综合上述分析, 本文选择层次聚类法和K-means相结合来研究P2P社区的形成过程。研究过程分两步, 首先利用层次聚类法确定聚类中心和k值(聚类中心的个数) , 然后用K-means算法进行聚类分析。
根据P2P社区的形式化定义, 可知当节点间的兴趣相关度达到θ时, 它们才属于同一P2P社区, 而兴趣相关度CDi又是由用户节点兴趣和节点间交互情况决定, 对于给定的节点集合P(Peers) ={ni, i=1, 2, …, m}和节点间的兴趣相关度CDi, 社区形成的具体算法为:
(1) 将P中的每个节点ni看作是一个具有单独成员的社区Ci={ni}, 这些社区构成了P的一个聚类C={Ci, i=1, 2, …, m};
(2) 计算C中每对类(Cp, Cq) 之间的兴趣相关度CD(p, q) ;
(3) 当CD(p, q) ≥θ时, 有Cp=Cp∪nq, Cq=Cq∪np。根据C1, C2, C3, …, Cm的模对C1, C2, …, Cm进行排序, 为叙述方便, 假设|C1| >|C2| >…|Cm|。根据参数k的设定原则(对某个节点, 与其相关度大于θ的节点数目越多, 该节点越有可能选为初始聚类中心节点) , 选取C[k]={C1, C2, …, Ck}, 所对应的V[k]={n1, n2, …, nk}作为初始聚类中心节点[ 11];
(4) 将层次聚类法得到的初始聚类中心作为K-means聚类的种子S={Sj, j=1, 2, …, k};
(5) 依次计算P中的每个节点ni与每个种子Sj的兴趣相关度CD(ni, Sj) ;
(6) 选取具有最大兴趣相关度的种子MAX(CD(ni, Sj) ) , 将ni归入以Sj为聚类中心的社区Cj;
(7) 重复步骤(4) -(6) , 最后得到较稳定的聚类社区结果C={Cj, i=1, 2, …, k}。
5 实例分析
5.1 实例过程研究
在之前的实例研究中, 笔者从某大学建立的资源共享平台BT网站上随机选取50个节点作为实验节点, 以其中的10个节点作为分析样本, 通过对这10个节点上分享的资源进行语义标注和语义推理, 将生成的所有标注信息存放到OWL文件中。
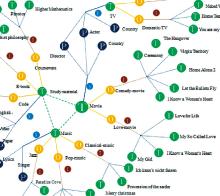
采用网状显示与树结构显示相结合的方法来表示节点本地知识地图, 如图2所示, 其中符号“T”、“P”、“A”、“I”、“R”和“O”分别表示知识实体、关联实体、关系类型、具体实例、角色和资源类型[ 8]。
 | 图2 知识地图的可视化表示 |
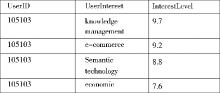
图3所示的用户兴趣描述文件部分内容中列出了用户105103的相关兴趣, 数据被整理成如下格式:D={<105103>:
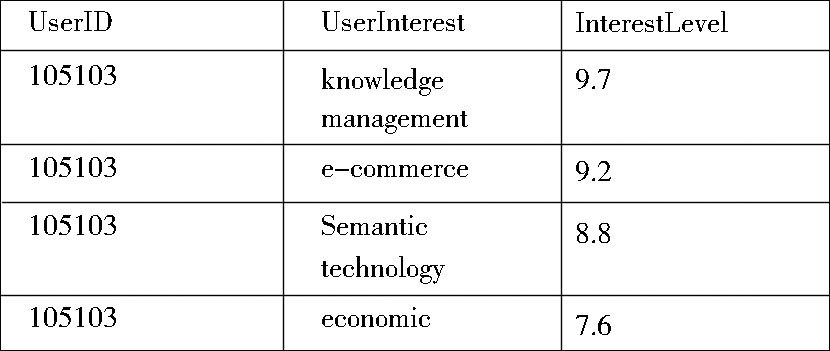 | 图3 用户兴趣描述文件部分内容 |
在此基础上, 利用Excel计算10个样本节点的兴趣相关度, 其结果如表1所示:
| 表1 兴趣相关度计算 |
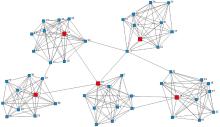
然后, 利用Java编程把50个节点兴趣相关度信息处理为0-1结构的矩阵(相关度大于0.68时取值为1) , 使用UCINET 软件将0-1格式的矩阵转换成UCINET 格式的数据, 然后利用UCINET 中的NetDraw工具将P2P 网络中的基于用户兴趣的社区结构形态呈现出来, 如图4所示:
 | 图4 基于用户兴趣的P2P社区结构 |
5.2 实例结果分析
图4清晰展示了P2P网络中的基于用户兴趣的社区结构, 图中形状大的节点表示聚类中心节点。在知识地图构建用户兴趣模型的基础上, 采用层次聚类法和K-means相结合研究P2P社区的形成过程, 总结有以下几点优越性。
(1) 本研究利用语义标注和推理机制形成的知识地图, 清晰展示了节点资源间的关系结构, 有效提高了节点资源的组织与管理, 挖掘了隐性节点知识以及之间潜在的关系, 方便查询知识实体的关联及具体内容。同时, 能够适应用户需求的不断变化, 使用户能充分利用网络上的资源[ 8]。
(2) 根据兴趣语义相关度聚类形成的社区, 不仅能够解决信息过载的问题, 而且能够充分挖掘节点间的相互关系, 以实现更准确有效的资源共享。此外, 在进行检索时可以直接先确定节点所属社区进行检索, 从而缩短查询路径, 提高查询效率。
6 结 语
研究对等网环境下的社区形成问题, 不仅顺应了互联网社区化的发展趋势, 而且通过了解社区形式化定义、结构以及形成机制, 可以对社区进行有效管理, 使得社区能够更好地应用于网络文化交流、电子商务、资源共享等方面。
本文介绍了一种基于知识地图构建的用户兴趣表示方法, 研究并提出了一种基于用户兴趣的P2P社区的形成机制。随着节点资源的动态变化以及节点间资源交互次数的增加, 节点用户的兴趣也会相应变化和更新, 最终兴趣相关度高的节点会聚集在一起, 从而形成了网络中的社区结构。实例验证, 利用节点间的兴趣相关度聚类形成P2P 社区是一种可行的方法。在互联网上应用用户兴趣社区可以有效加强用户检索的力度, 但是在对等网环境中, 基于社区的信息检索方法还没有被成熟应用。所以在未来研究中, 如何利用P2P社区来有效提高对等网中的信息检索效率是需要进一步深入研究的问题。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|