


{kind=link}
{kind=link}
{kind=link}
中文专利中本体关系获取研究
引用本文
谷俊, 许鑫. 中文专利中本体关系获取研究. 现代图书情报技术, 2013, 29(10): 73-78
Gu Jun, Xu Xin. Study on Ontology Relation Extraction in Chinese Patent Documents. New Technology of Library and Information Service, 2013, 29(10): 73-78
Permissions
Gu Jun, Xu Xin. Study on Ontology Relation Extraction in Chinese Patent Documents. New Technology of Library and Information Service, 2013, 29(10): 73-78
中文专利中本体关系获取研究
摘要
介绍从中文专利摘要文本中抽取本体非分类关系的方法。首先对摘要文本的句法格式进行分析, 按照“领域句式”、“特征句式”、“组件\工艺句式”和“效果句式”等构建子句抽取规则, 再利用B、I、E和O等标注符号对子句中的术语进行人工标注, 形成一定规模的训练语料集合, 并利用CRFs实现训练语料的学习和新语料的抽取。最后给出应用实例并进行分析, 验证方法的有效性。
关键词:
规则匹配; 条件随机场; 本体学习; 非分类关系抽取
Study on Ontology Relation Extraction in Chinese Patent Documents
Abstract
This paper promotes a method which collects the non-taxonomic relation from the Chinese patents’ texts. Firstly, it analyzes the syntax of abstract texts, then constructs the sub-sentences extraction rules by domain sentence, character sentence, module & craft sentence and effect sentence. Secondly, artificially labels the terms of sub-sentences by label symbols such as BIEO, creates a scale of training data set. Thirdly, learns the training data and extracts the new data by CRFs. Finally, analyzes the experiment results and verifies the validity of the method.
Keyword:
Rule matching; CRFs; Ontology learning; Non-taxonomic relation
1 引 言
专利文献作为技术信息最有效的载体, 囊括了全球90%以上的最新技术情报, 相比一般技术刊物所提供的信息早5-6年[ 1], 而且70%-80%发明创造只通过专利文献公开, 并不见诸于其他科技文献, 相对于其他文献形式, 专利更具有新颖、实用的特征。随着市场竞争的加剧, 越来越多的企业把目光投向了可以增加企业核心竞争力的专利文献, 一方面通过专利公开来保护自己的技术, 另一方面通过专利的检索、分析与学习, 不断提升自身的技术研发能力, 从而在激烈的市场竞争中占有一席之地。因此, 对于企业的情报部门来说, 从专利中抽取相应的知识, 构建基于专利文献的本体库, 为专利检索和专利分析提供帮助是一项非常有意义的工作。
专利摘要部分一般会概括性地描述专利的主要内容, 并且其撰写方法具有一定的规律性。国家知识产权局
明确规定, “说明书摘要文字部分应当写明发明或者实用新型的名称和所属的技术领域, 清楚反映所要解决的技术问题, 解决该问题的技术方案的要点及主要用途”[ 2]。因此, 可以得知专利文献的摘要内容中应当至少包括“技术领域”、“技术问题”、“技术方案”和“用途”等几个部分。而这几个部分, 则可以作为本体中“所在领域”、“解决问题”、“运用方案”和“用途”等关系的抽取对象, 实现对摘要文本中相关术语及关系的抽取。
2 相关研究
3 方法描述本体的关系获取也可以理解为基于关系的术语和知识的抽取, 因此本文就这方面进行了文献调研。目前本体关系抽取主要有基于规则的方法和基于统计的方法, 以这两种方法为基础, 国内外的专家学者基于不同类型文本的特点, 实现了一系列特定的关系抽取方法。Girju等[ 3]利用Hearst模式成功获取了术语间的因果关系, 虽然抽取的准确率较高, 但是其抽取模板需要人工制定, 比较费时费力;Byrd等[ 4]通过计算共现概念的互信息来标记关系, 具有一定的效果;Maedche等[ 5]利用关联规则进行术语间关系的抽取, 该方法虽然能够将关系较近的两个术语提取出来, 但是无法获取关系的具体名称。而国内在本体关系获取方面的研究较少, 谭力等[ 6]提出了一种基于数据挖掘的本体关系学习方法, 首先运用关联规则挖掘获取概念间的关系, 再利用聚类分析对概念关系类型进行区分;董丽丽等[ 7]通过关联规则提取概念对, 将概念对之间的高频动词作为候选的非分类关系标签, 最后利用VF*ICF 度量法来确定非分类关系标签, 以确定概念之间的非分类关系。于娟等[ 8]根据特定的语境将概念集合构造成特征词向量模型, 通过计算向量之间的相似度来确定概念之间是否存在非分类关系。在基于CRFs的术语抽取方面, Li等[ 9]在命名实体检测 (NED) 阶段利用CRFs实现了生物医学的命名实体抽取, 在命名实体分类 (NEC) 阶段确定实体的类型, 从而最终实现命名实体的识别;Peng等[ 10]提出了一种互信息与CRFs结合的术语抽取方法, 根据子词语在短语中的上下文标记特征, 完成术语的抽取;Chen等[ 11]对现有的几种术语抽取方法进行比对, 并以CRFs为例, 对电商网站上消费者的评论信息进行抽取;Esuli 等[ 12]在运用CRFs对实体进行抽取时, 引入了标注实体的位置信息, 并以放射诊断报告为例进行了测试。
基于规则的方法和基于统计的方法由于具有一定的局限性, 无法完全满足本体关系构建的需要, 因此本文尝试将上述两种方法结合起来, 以提高本体非分类关系抽取的准确率。
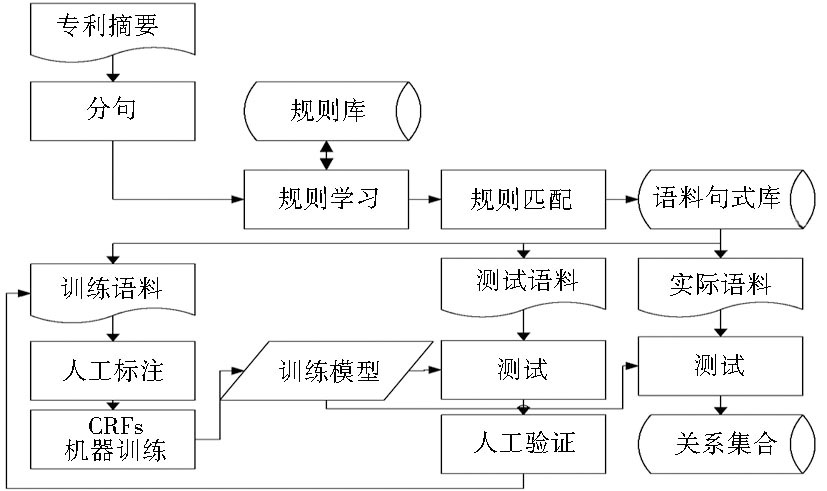
本文结合专利摘要描述的语言特点, 尝试先通过规则匹配的方式获取关系子句, 形成较为统一的语言描述规则, 再利用CRFs方法抽取出每个关系子句中的术语, 以降低人工标注的成本, 最终完成本体关系的构建。流程如图1所示:
抽取流程如下:
(1) 专利摘要语料首先经过句子拆分, 形成独立的具有完整含义的子句;
(2) 经过人工的规则学习, 形成规则库, 并运用规则对其他的语料进行匹配, 形成语料句式库;
(3) 对于已经形成的句式库, 由人工进行训练语料的标注, 并利用CRFs进行训练, 生成训练模型;
(4) 用训练模型对测试语料进行测试, 测试结果由人工验证其准确率和召回率, 并对训练语料进行调整和补充后重新训练, 直到准确率和召回率达到一定的阈值为止;
(5) 利用修正后的训练模型对实际语料进行识别, 结合规则匹配结果, 实现本体关系集合的构建。
3.1 基于规则的句式学习与抽取
(1) 专利文献句法特点分析
普通的论文摘要文本和新闻文本由于没有明确的规定, 写法比较口语化, 定制的抽取规则比较复杂。而专利文献由于是法律文献, 其摘要部分的写法在国家知识产权局的相关法规中有明确的规定, 即专利的摘要内容中必须含有“技术领域”、“技术问题”、“技术方案”和“用途”4个部分, 因此, 相对于其他文本来说, 利用规则的定义来区分专利摘要中的上述4种关系比较容易。这4部分可以理解为专利文献的4个属性, 基本上能够描述专利的主要内容, 如图2所示:
 | 图2 专利摘要样例 |
其中, “公开了一种大功率双向液压式开铁口机”表示技术的内容, 前缀为“公开了”; “属于炉前用开铁口机技术领域”表示技术领域, 前缀为“属于”;“其主要包括……和油气润滑系统”为技术方案, 特征词为“包括”;“使本装置具有更大的冲击功和频率”、“容易实现配到自动化操作”、“提高炉前作业功效”等是用途和效果, 特征句式为“使……具有”、“容易实现”和“提高”。因此, 可以利用每个属性的句法特征进行抽取。
此外, 专利文献为标准格式的文献, 为了规范专利摘要的内容, 国家知识产权局还要求在摘要信息中, 属性之间应当使用句号进行明显的分割[ 13]。撰写要求的规范化对于利用规则进行关系的抽取十分有利。
(2) 抽取规则
笔者通过阅读大量的专利文献, 分析专利摘要的句法特征, 发现其句法特征是有章可循的。例如, 描述技术领域的句式一般包含“涉及”、“属于”、“为解决”等词汇;设备类专利的技术方案句式中一般包含“组成”、“构成”等词汇, 化学成分类专利的技术方案句式中一般包含“组成”、“百分比”等词汇, 而工艺类专利技术方案句式中一般包括“步骤”、“规程”等词汇;对于专利效果, 一般会有“解决”、“提高”、“防止”等词汇。因此, 本文根据这些特征, 总结出当前语料库的句式触发规则138个, 样例如表1所示:
| 表1 句式触发规则片段 |
(3) 基于规则的子句抽取方法
利用规则进行的关系抽取需要经过规则学习和规则匹配两个阶段。
在规则学习阶段, 首先抽取部分专利摘要, 并将其按“。”进行子句拆分, 每个子句都是能够表达完整意义的句子;再利用中国科学院计算技术研究所ICTCLAS汉语分词系统[ 14]对每条子句进行分词, 形成最小语言单位;由人工对分词结果进行阅读和学习, 按照“领域句式”、“特征句式”、“组件\工艺句式”和“效果句式”分别进行抽取规则的标注;利用正则表达式匹配方法对学习结果进行验证, 并对错误结果进行调整, 最终完成当前记录规则的构建。
在规则匹配阶段, 运用人工提取的抽取规则, 对所有的专利摘要进行匹配, 最后由领域专家对匹配结果进行测试和验证, 并将结果反馈至规则学习部分, 为规则的修订提供依据。
经过几轮的迭代, 最终形成满足当前语料需求的规则库和句式库。规则的学习界面如图3所示:
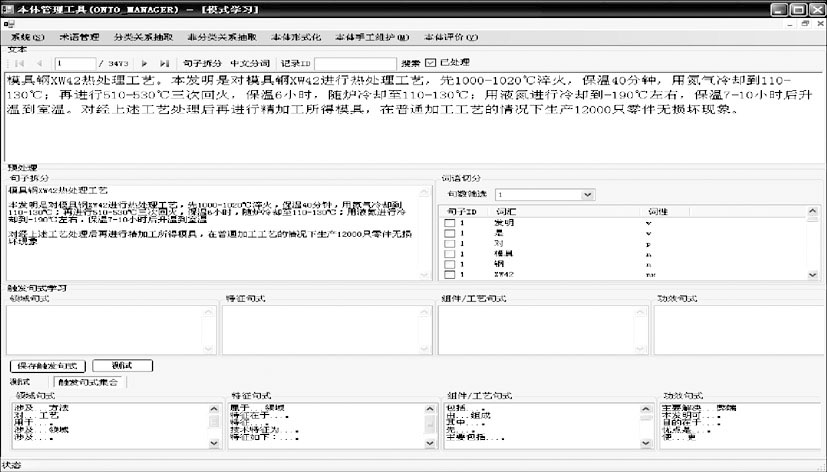 | 图3 规则学习界面 |
(4) 抽取结果
本文共进行了5轮规则的修订, 每次修订都是在前一轮规则匹配的结果上由专家确认后在已有规则的基础上进行修正, 确保语料中的关系子句能够正确抽出, 测试结果如表2所示:
| 表2 规则抽取测试结果 |
从表2可以看出, 经过了5轮的规则修订, 规则数量达到123条, 抽取准确率也达到了90%以上, 基本可以满足下一步术语抽取的需求。
3.2 基于条件随机场的术语子项抽取
经过规则匹配处理后, 得到了符合专利摘要中所描述的4种关系的关系句式集合。但是从表2可以看出, 经过5轮迭代, 关系子句的抽取准确率达到了较高的水平, 但是这仅为3 000余条专利的抽取结果。笔者邀请了三位专家进行了规则的制定, 耗时两周左右的时间, 而这仅是对子句进行抽取, 并未涉及到句子中术语的抽取。可以看出, 依据规则进行抽取的准确率虽然较高, 但是单纯依靠专家进行规则的制定比较费时费力, 面对大规模的语料有些力不从心。因此, 笔者认为可以依赖相对成熟和便捷的统计算法, 从相应的关系句式中进行术语的抽取, 形成带有“关系”属性的术语集合。在这里, 本文选择了基于条件随机场的抽取方法进行术语子项的抽取。
(1) CRFs模型简介
CRFs模型是由Lafferty等[ 15]于2001年提出的一种概率图模型, 对于给定长度为n的一组观察序列O={O1, O2, ……On}, S={S1, S2, ……Sn}为输出状态序列。对于参数为f的线性CRFs, 其状态序列的条件概率为:
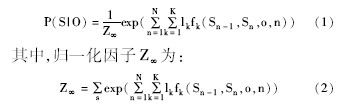
其中, fk (Sn-1, Sn, o, n) 是一个任意的特征函数;lk是特征函数fk (Sn-1, Sn, o, n) 的权重。给定一个输入序列D, 标注任务就是获取搜索概率最大的S*, 使得:
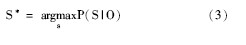
(2) 标注集合
本文采用B (Begin) 、I (Internal) 、E (End) 和O (Other) 等标注符号作为每个语义单元的表达方法, 其中B表示术语首部, I表示术语中部, E表示术语尾部, O表示其他。由于专利中只包含技术术语, 而其他类型的术语并没有体现, 因此不需要对标注集合再进行分类, 只需要按照BIEO方式进行标注即可。例如输入序列x={涉及\v, 一\m, 种\q, 钒\n, 钛\n, 铁水\n, 镁\n, 脱\v, 硫\n, 专用\vn, 调\v, 渣\ng, 剂\ng, \w属于\v, 钢铁, n, 冶金\n, 领域\n}, 可以标注为y={O, O, O, B, I, E, B, I, E, O, B, I, E, O, O, B, E, O}。
(3) 特征集合
特征的选择对于基于条件随机场的术语识别十分重要, 笔者对特征模板进行了细分, 包括上下文特征、词性特征。
①上下文特征。术语总是存在于特定的上下文语境中, 一旦术语上下文的分布存在一定的规律性, 那么便可以利用该规律抽取出术语。
②词性特征。实验证明, 仅凭上下文特征并不足以准确地完成术语抽取, 还需要辅助以上下文和术语所在词汇本身的词性特征, 词性信息对于术语的抽取具有启发作用。
③对于中文来说, 常常会出现术语前有若干个修饰词, 此外, 由于ICTCLAS分词系统本身的缺陷, 往往会把一些词汇误分成独立的词。例如:一\m, 种\q, 钒\n, 钛\n, 铁水\n, 镁\n, 脱\v, 硫\n, 专用\vn, 调\v, 渣\ng, 剂\ng, 其中一种、脱硫等词汇被拆成单个词。因此, 在上下文中, 仅仅依靠术语的前一个词和后一个词的特征并不能完全代表术语所存在的语境, 所以, 以前后两个词作为窗口进行特征集合的构建。
特征集合如表3所示:
| 表3 特征集合 |
(4) 基于CRFs的子项抽取方法
基于CRFs的子项抽取采用人工标注部分训练语料, 利用CRF++工具包[ 16]对已标注的语料进行训练, 生成训练模型, 使用训练模型对剩余语料进行测试, 最后由领域专家验证抽取结果。具体步骤为:
①按照“领域”、“特征”、“工艺\组件”和“功效”分类对规则抽取的结果进行筛选, 便于人工标注的结果按照上述4个分类生成不同的训练语料;
②对于分类中的单个句式, 先利用ICTCLAS分词系统进行分词, 对分词的结果利用BIEO方式进行人工标注, 并保存结果;
③对于标注的结果, 利用CRF++进行学习, 生成训练模型。CRF++是一款用于条件随机场序列标注的工具, 特别适用于命名实体识别、信息抽取和文本分块等自然语言处理。在CRF++中, 使用crf_learn命令进行训练语料的学习, 具体方式为:
crf_learn template_file train_file model_file
其中, template_file为模板文件, train_file为已标注的训练文件, model_file为训练的结果模型。
④CRF++工具包学习后, 会生成model_file模型文件。利用模型文件, 便可以对测试语料进行测试。CRF++使用crf_test命令进行语料测试, 具体方式为:
crf_test -m model_file test_files
其中, model_file表示训练模型, test_file为用于测试的语料文件。
⑤测试结果交由领域专家进行验证, 并根据验证结果不断对训练语料进行调整, 直到满足一定的条件停止。
4 实验结果及分析
本文从国家知识产权局的专利检索系统中随机下载了国际分类号为C21的专利数据3 000余条进行实验, 第一轮利用规则共计抽取18 891条子句, 按照“领域”、“特征”、“工艺\组件”和“效果”分别进行人工标注, 共计标注了8 000条训练语料, 其余随机挑选2 000条为测试语料。测试结果如表4所示:
| 表4 基于CRFs的术语子项抽取结果 |
从表4中可以看出, 抽取准确率相对较高, 特别是“工艺/组件”分类, 准确率达到92.6%, 而“效果”分类的准确率较低, 仅为64.8%。究其原因, 主要包括以下几点:
(1) 专利文摘具有特殊性, 相关法规要求专利摘要必须按照一定的规则撰写。经过前期的规则筛选后, 每个分类下的子句语言描述方式较为一致, 特别是“工艺/组件”类, 其描述方式基本为“包括:……”、“先……再……”等, 有利于术语的识别;
(2) 训练语料的规模较小。条件随机场模型对于训练语料的规模较为敏感, 由于人力资源的限制, 上述每个分类只抽取了2 000条进行训练, 规模并没有达到实际应用的要求;
(3) “效果”分类中的子句相对于其他分类, 语言描述形态各异, 自由度较大, 增加了识别的难度, 导致识别效果不佳。在以后的研究中, 需要通过增加训练语料的规模来提高识别的准确率。
由于关于钢铁冶金类专利术语抽取和关系构建的报道较少, 本文将抽取结果与笔者前期的成果[ 17]进行了简单对比, 结果如表5所示:
| 表5 抽取结果对比 |
可以看出, 本文提出的算法抽取准确率为82.10%, 低于串频最大匹配算法的术语抽取准确率, 而把“效果”分类从中排除后, 平均准确率则达到87.87%, 超过了串频最大匹配算法的术语抽取准确率, 这主要是因为“效果”分类的术语抽取准确率较低, 影响了总体效果。但是, 串频最大匹配算法仅仅可以抽取出文本中的术语, 无法抽取出相应的关系, 还需要在得到抽取结果后另行选择关系抽取方法, 影响了本体关系抽取的效率。因此, 笔者认为, 在解决了“效果”分类准确率低的问题后, 本文所提出的算法在本体关系抽取方面有更强的应用性。
5 结 语
随着竞争的日益加剧, 企业对于专利文献也愈发重视。本文从专利摘要入手, 通过对摘要部分的句法进行分析, 实现了利用规则先进行摘要子句拆分, 再利用CRFs对子句中的术语进行抽取, 最终完成本体非分类关系的构建。实验证明, 基于规则和CRFs结合的本体非分类关系抽取具有一定的效果。在未来的研究中, 将针对“效果”分类中抽取准确率较低的问题, 改进相应的抽取规则, 增加约束条件, 提高子句抽取的精度, 辅以增加训练语料规模, 从而提高最终关系抽取的准确率。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|