{kind=link}
{kind=link}
{kind=link}
{kind=link}
Drupal的混搭技术在图书馆的应用
引用本文
李丹, 闫晓第, 魏青山. Drupal的混搭技术在图书馆的应用. 现代图书情报技术, 2013, 29(10): 79-84
Li Dan, Yan Xiaodi, Wei Qingshan. Application of Mashup in Library Based on Drupal. New Technology of Library and Information Service, 2013, 29(10): 79-84
Permissions
Li Dan, Yan Xiaodi, Wei Qingshan. Application of Mashup in Library Based on Drupal. New Technology of Library and Information Service, 2013, 29(10): 79-84
Drupal的混搭技术在图书馆的应用
摘要
图书馆异构数字信息资源整合是目前图书馆资源整合中的一个主要问题。以开源软件Drupal及其扩展模块为基本框架, 提出低开销、高效能、单点注册的多站点间信息共享方法, 给出调用、配置不同模块按需收集信息的混搭模式, 实现Web2.0 下新一代混搭平台 (Multi-Sites Drupal Mashup, MS Drupal-Mashup) , 及时发布来自异构系统的数据源, 实现互联网云端、图书馆内资源信息、读者信息跨平台共享及读者信息交互, 利用混搭提升图书馆信息化服务水平。
关键词:
Drupal; 资源共享; 混搭
Application of Mashup in Library Based on Drupal
Abstract
Heterogeneous digital information resource integration is a major problem in library currently. Taking Drupal and its expansion module as the basic framework, this paper proposes a novel information sharing approach in multi-sites with low-overhead, high-efficiency and single sign on features, presents the way of gathering information in need using modules-Mashup, and implements a prototype of new generation Mashup platform (Multi-Sites Drupal Mashup) upon Web2.0, which can show data source from heterogeneous system and realize cross-platform sharing among internet cloud, library resources, reader information and interaction with reader information. Library information service ability is improved using Mashup.
Keyword:
Drupal; Information resources sharing; Mashup
1 引 言
近年来, 国内外图书馆都购买或自建了大量的格式各异、来源不同的数字资源, 同时图书馆还研发了特色数字资源库、信息管理系统、远程登录系统、期刊导航系统等各类方便读者使用的数字资源平台。但是, 在图书馆信息化服务能力提升的同时出现了一些问题, 即异构系统间信息孤岛与系统内信息超载的问题。图书馆具有大量丰富的信息源, 各种信息种类繁多, 在一定程度上, 信息量越大, 用户负担往往就越重, 因此, 如何使图书馆各种资源有序重构、各种开放式数据源相互混合、不同系统间有效地融合、大量的馆藏数字资源如何通过系统平台提供给读者整合的信息服务, 是图书馆界关注的主要问题。
混搭 (Mashup) 是指通过软件应用, 把不同的独立应用程序接口 (APIs) 和数字资源整合到一个集成接口[ 1], 利用来自多个数据源的内容创建一个单独的新服务, 并且在一个单独的图形界面显示[ 2]。混搭不仅需要开放数据源的支持, 同时需要访问或查询数据源的方法如API接口、RSS聚合等, 最终还需要创建混搭的工作者和使用者。
图书馆丰富的开放式信息源非常适合混搭环境的创建, 通过使用开源软件Drupal将混搭应用于图书馆数字资源整合是近年来国内外图书馆大量采用的混搭方式[ 3], 通过第三方插件 (模块) 使用Web应用API接口、信息聚合 (RSS) 输出数据或者数据库信息等作为内容源, 处理加工后, 把Web应用 (或者其数据) 整合到Drupal 架构中, 可以解决图书馆异构系统整合、资源共享问题, 为读者提供一个聚合馆藏资源、读者信息、地图可视化的服务界面。
2 国内外应用现状
国内外利用开源软件Drupal进行混搭, 主要应用在以下几个方面:
(1) 谷歌地图混搭, 这种方式主要是通过API Amazon EC2、GeoNames、 Google Maps、LibraryThing创建地图混搭, 实现在谷歌地图上混搭图书馆藏信息, 方便读者通过浏览谷歌地图查询附近图书馆藏情况, 也可以实现图书的文献传递、快递服务等。北德克萨斯大学使用谷歌图书预览 (Google Books Preview) 、亚马逊API增强OPAC系统的功能[ 2]。
(2) 图书馆门户网站混搭[ 4], 通过搭建图书馆门户, 整合各类数字资源, 读者通过图书馆统一认证就可以使用图书馆数字资源, 将图书馆远程访问系统 (VPN) 、读者认证系统与图书馆数字资源整合平台整合, 提供给认证读者网络数据访问权限。国外使用Drupal混搭建立图书馆门户网站的主要有亚利桑那州立大学图书馆 (Arizona State University Library) 、北爱荷华大学 (University of Northern Lowa) 罗德图书馆 (Rod Library)[ 5, 6], 纽约州Genesee Valley BOCES地区学校图书馆开发创建了下一代图书馆门户系统Fish4Info[ 7];国内北京大学图书馆、澳门科技大学图书馆也使用Drupal混搭建立图书馆主页。
(3) 下一代图书馆OPAC系统混搭, 这种类型的混搭是通过模块组合, 导入MARC数据, 通过API接口, 从亚马逊、当当等网站获取图书相应信息, 建立馆藏书目综合信息, 读者可以通过交互平台对图书进行评价, 馆员可以通过混搭平台了解读者需求。这类系统主要有美国密歇根州安阿伯图书馆 (Ann Arbor Library) 基于Drupal 混搭开发的SOPAC (Social OPAC)[ 8, 9]。
相比国外, Drupal在国内的推广和应用还不够普及, 技术上跟国外还有较大差距。
3 Drupal在西安交通大学图书馆的应用
3.1 相关建设需求
西安交通大学图书馆购买和自建了共40多个数字资源系统提供网络服务, 这些系统平台各异, 数据形式和获取方式不同, 各系统平台彼此信息孤立, 缺乏共享。读者信息方面, 本校读者使用图书馆提供的各类数字资源服务时, 需要分别登录并认证才能合理使用, 比如读者登录图书馆无线网络、VPN系统, 需要通过一卡通信息认证;登录图书馆购买的数据库需要通过学校IP认证才能正常使用。无线网络和VPN系统用户需要管理员审核并且限制每天使用流量;馆藏资源方面, 图书馆集成管理系统提供传统OPAC功能, 主要基于MARC数据展现, 目前添加了网络下载图书封面功能, 与下一代馆藏OPAC相比, 无法实现信息交互和Google电子图书、亚马逊图书评论等信息加载[ 10];图书馆购买的电子资源来自不同供应商, 系统平台异构程度很大, 读者需要访问不同的数据库或者期刊才能访问到需要的数字资源。近年来, 图书馆通过引入资源发现平台Summon和中文超星数据整合平台部分解决了数字资源整合和发现问题, 但是对于读者认证, 馆藏OPAC显示还没有很好的方法。另外, 国内高校图书馆的混搭平台大多基于运营商创建, 其要求读者必须在该运营商网站上注册, 比较繁琐, 不方便管理员进行管理和设置, 不能进行深一步的功能开发, 局限性较大。开源软件Drupal作为可扩展性良好的、支持目前混搭技术所需接口的开源内容管理系统[ 11], 优越性显而易见。
新一代混搭平台 (MS Drupal-Mashup) 采用基于Drupal及其扩展模块、Web2.0下API接口和混搭技术, 根据平台建设需求, 设置用户角色, 选择主题, 调用并配置不同的模块, 实现不同的功能, 将独立于各云端的信息资源与西安交通大学图书馆现有资源整合, 实现图书馆混搭平台MS Drupal-Mashup。读者通过单点注册共享多站点间读者信息, 图书馆内不同系统间资源信息共享融合, 管理、升级便捷。另外通过模块扩展功能, 按需收集资源信息, 实现新闻信息、馆藏资源、外部搜索引擎谷歌定制搜索混搭等功能。该平台使各系统用户与图书馆个人借阅系统中的读者信息实现同步且共享各子站点间读者信息;共享数据库, 避免各类应用系统数据库之间信息的手动导入、导出及逐条更新, 减少系统管理员审核用户身份的工作量。
3.2 MS Drupal-Mashup设计与实现
(1) MS Drupal-Mashup设计
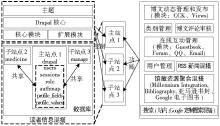
以Drupal及其扩展插件为基本框架, 使用同一个Drupal核心搭建了三个站点, 每个站点之间共享数据库中的读者信息、共享核心模块、扩展模块以及主题文件, 但每个站点的控制和管理功能是独立的, 故呈现在读者面前的是具有不同配置和功能、不同界面设计风格和主题显示的子站点。MS Drupal-Mashup通过共享与用户相关的数据表来实现单点注册登录, 共享多站点间读者信息混搭, 具体架构如图1所示:
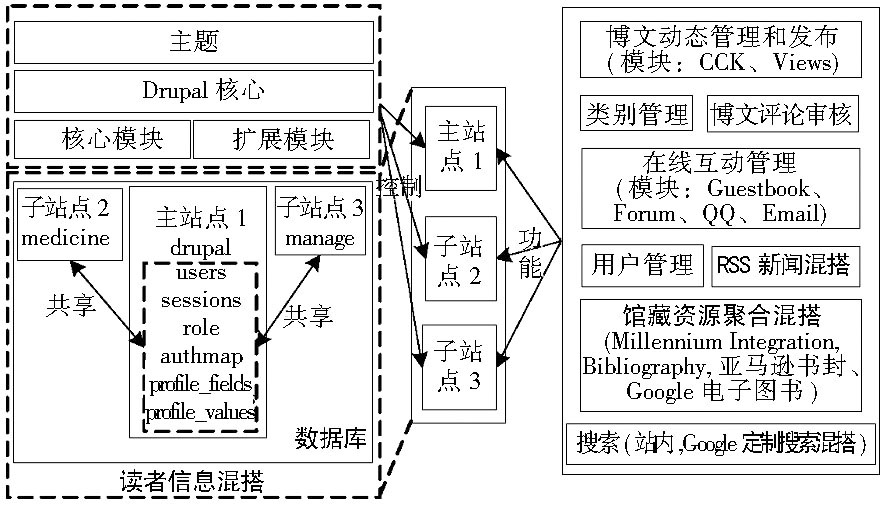 | 图1 MS Drupal-Mashup架构 |
在搭建站点时, 充分考虑平台的定位需求以及要实现的功能, 选择合适的模块, 并不是所有的模块都与系统兼容, 各站点建立好后, MS Drupal-Mashup混搭架构提供了以下功能:
①信息发布、管理及评论审核, 通过CCK和Views模块管理信息显示, 实现图书馆各种新服务、重要通知、信息资源的发布, 并通过权限模块设置信息审核;
②论坛、馆员和读者交互管理, 通过Guestbook留言簿、Forum论坛模块、QQ、Email实现馆员与读者的实时互动, 解决读者遇到的问题;
③用户管理;
④MS Drupal-Mashup各种信息收集混搭, 主要有新闻、馆藏资源混搭以及谷歌定制搜索混搭;
⑤站点运行、优化管理。
其中关于信息收集混搭包括:
①新闻混搭, MS Drupal-Mashup基于RSS, 以西安交通大学图书馆内各种服务及重要新闻作为新闻源, 在平台中通过混搭、分类各种新闻, 并实时地发布符合读者兴趣的个性化新闻, 推送有用资源;
②馆藏资源聚合混搭, 利用Millennium Integration模块或Bibliography 模块向读者推荐馆内图书资源;
③批量、定时、自动或手动从图书馆馆藏资源Millennium WebOpac系统中抓取、显示书目信息, 引入书封、书评, 提供自由标签、谷歌电子图书;
④除了具有站内搜索功能外还实现了外部搜索引擎谷歌定制搜索混搭, 读者不仅可以获取本馆的资源信息, 而且可以获取来自不同信息源的整理好的分类资源, 实现信息多方共享, 同时, 站内搜索支持搜索范围限定如内容类型、分类, 同时支持条件查询。
(2) 混搭模块的具体实现
①多站点搭建, 读者信息混搭
该平台 (见图1) 实现读者信息混搭, 站点间共享用户信息, 即在子站点注册的新用户, 可以在主站点使用同样的用户名和密码登录。这样大大提高了用户使用所有网站资源的便捷性。
利用Drupal搭建多站点可以采用几种方法, 如基于不同Drupal核心分别多次搭建站点, 每个Drupal站点对应不同的数据库, 缺点是每个站点完全独立, 没有信息共享。目前MS Drupal-Mashup采用基于同一Drupal核心在虚拟主机上搭建多个站点的方法, 已搭建三个站点。所有的站点都由一个Drupal驱动运行, 便利了站点更新工作, 只需要更新一次即可完成多个站点的更新, 如表1所示:
| 表1 MS Drupal-Mashup站点数据库信息 |
搭建好的MS Drupal-Mashup支持5种用户角色:匿名用户、注册用户、信息管理员、信息发布员和系统管理员。其中匿名用户可以浏览信息, 发起论坛讨论主题, 发表留言, 发表评论但需要审核;信息管理员可以发布信息, 管理所有信息, 负责评论的审核;信息发布员发布信息, 编辑自己发布的信息, 但是无权修改其他发布员发布的信息;系统管理员负责MS Drupal-Mashup的搭建与维护, 注册用户身份审核。用户权限贯穿于所有模块设置中, 管理员可以根据用户的不同角色设置不同的权限。
MS Drupal-Mashup除了支持系统管理员开设账户外, 也支持读者在线注册, 由于构建了多站点间用户信息共享, 故用户不管在哪个站点注册, 一旦审核通过后即可在任意一个站点登录, 而无需重复注册。同时, 关于注册用户与图书馆个人借阅系统中的读者信息实现同步问题, 目前采用把西安交通大学图书馆个人借阅系统中的读者信息批量导入到MS Drupal-Mashup数据库中的方法, 减少用户的注册次数。平台支持邮件自动发送, 实现管理员和读者之间身份审核工作的交互。如果需要考虑安全问题, 平台可限制只具有学校邮箱的用户进行注册。
②馆藏资源聚合混搭
西安交通大学图书馆采用美国Innovative公司提供的图书馆集成管理系统Millennium, 它与Millennium Integration[ 12]模块完全兼容, 同时支持MARC数据导入导出, 使Drupal 平台上各类收割模块获取馆藏资源成为可能。
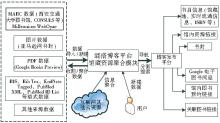
为进一步增强图书馆资源和馆外资源的混搭, 为读者提供一站式资源获取服务, MS Drupal-Mashup实现了馆藏资源聚合混搭, 如图2所示, 该平台通过批量数据导入、新建、收割和聚合MARC数据、图片数据、PDF数据以及其他格式数据, 分类处理后存储于后台数据库中, 可通过搜索引擎进行分面搜索和导航, 以一定的格式发布、展示给读者。
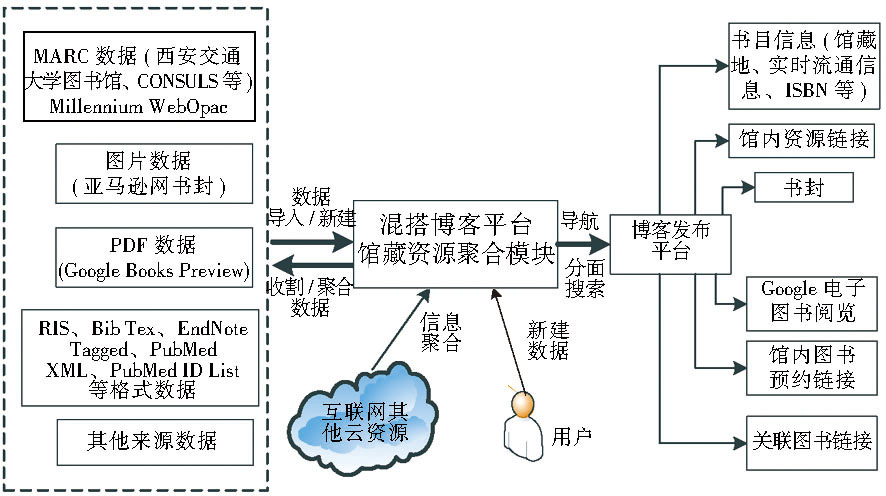 | 图2 馆藏资源聚合混搭 |
平台支持多种数据格式导入, 通过Millennium Integration模块批量、定时自动或手动从西安交通大学图书馆以及其他大学图书馆馆藏资源Millennium WebOpac系统中抓取书目MARC信息如馆藏地、实时流通信息、作者、标题、ISBN号、书目描述等, 把MARC字段映射到分类词汇表来进行导航和RSS信息聚合, 待充分映射和处理数据后, 生成对应类型的Drupal节点, 显示给读者;很多主要网络服务提供商如雅虎、谷歌、亚马逊等已经提供相关API接口, 对公共开放部分数字资源, 为混搭提供丰富的数据来源。平台利用自编超级文本预处理语言PHP程序调用相关API接口, 挖掘相关网页信息, 实现自动下载来自亚马逊网站上的图片数据书封;使用谷歌图书预览 (Google Books Preview) 显示对应的谷歌PDF格式电子图书;同时利用Bibliography[ 13]模块使图书馆原有系统各种标准数据和Drupal交互, 实现RIS、Bib Tex、EndNote Tagged、MARC、PubMed XML、PubMed ID List等文件格式的导入, 可以RTF、Tagged、XML、 Bib Tex类型导出书目信息。
处理后的资源以一定的服务展示给读者, 通过URL方式显示馆内资源链接、书目实时流通信息、馆内图书预约链接等, 其中Bibliography模块以列表的形式显示书目信息, 实现分面浏览、分面搜索、谷歌学术搜索链接, 检索结果实现相关度排序、内容增强、结果聚类, 且支持按照作者、标题、类型、出版年等排序和过滤。
③谷歌定制搜索混搭
图书馆的搜索引擎局限于馆藏信息、期刊和数据库搜索, 而读者对互联网上大量信息资源的分类需求越来越强烈, 故在设计方面, 平台利用谷歌自定义搜索工具实现定制资源的呈现, 把各种资源搜集、分类、整理、推送给读者, 完善用户体验, 在定位资源的同时引导读者去发现感兴趣的信息资源, 充分实现了搜索混搭。
平台利用谷歌提供的自定义搜索工具, 生成相关文件, 如上下文文件、批注集合等。按照图书馆需要, 手动修改文件源码, 主要修改上下文文件和批注文件, 填入需要搜索的链接。MS Drupal-Mashup使用谷歌链接自定义搜索后把需要修改的文件放置到本地服务器上, 谷歌搜索时会自动搜索到本地相关文件。
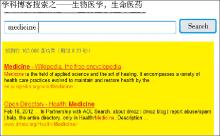
如以“医学学科”搜索为例, 把Medicine 作为关键字实现谷歌定制搜索, 总共搜索到163 000条记录 (见图3) 。
首先使用谷歌提供的工具生成相关文件如上下文文件、批注集合, 同时还生成一定的代码段;然后在上下文文件和批注文件中填入想要搜索的链接, DMOZ人工编辑开放目录网站中有关医学的资源链接如http://www.dmoz.org/Health/Medicine、上海交通大学生命医药学科信息服务博客中的资源链接、维基百科中含有关键词Medicine的页面链接以及谷歌搜索Medicine关键词的搜索结果中排名前100条记录的链接, 配置好相关文件后将其放置在本地服务器中;最后在Drupal中创建区块, 在区块代码中引入谷歌自定义搜索生成的代码段, 进行修改, 并加入JavaScript、CSS后, 在MS Drupal-Mashup页面中的适当位置显示搜索框, 点击搜索按钮后同页显示搜索结果, 搜索框和搜索结果如图3所示:
 | 图3 谷歌定制搜索 |
4 MS Drupal-Mashup的构建过程
4.1 运行环境和开源软件包
MS Drupal-Mashup服务器所在的网络环境为西安交通大学图书馆局域网, 服务器选用VMware虚拟中心提供的虚拟机, 其配置了两个虚拟CPU, 2GB内存, 一块虚拟网卡;MS Drupal-Mashup操作系统为Windows Server 2003;利用XAMPP 1.7.3版本管理数据库, 选用Drupal 6.26 版本搭建平台。
4.2 读者信息混搭, 多站点构建过程
目前基于同一个Drupal核心在虚拟主机上搭建了三个站点 (见表1) , 各个站点运行良好, 功能完备。采用XAMPP管理数据库, 第一次搭建Drupal主站点1时安装到站点根目录下, 之后依照此路径在站点根目录下的site 文件夹里依次安装子站点, 这里需要说明的是在配置子站点数据库时需要添加前缀。全部安装完成后, 数据库中分别有了所有站点的数据表。通过修改子站点的配置文件来实现子站点2和子站点3 共享主站点1的用户数据和登录信息。具体实现时, 需在配置文件中找到:
﹩db_url = ′pgsql://username:password@localhost/databasename′;
其中, databasename表示访问的数据库名称, username、password分别表示可以访问该数据库的用户名称和密码, 以子站点3为例, 按照上面的格式在对应的位置修改该语句, 同时, 找到﹩db_prefix = ′manage_′;把其改成:
﹩db_prefix = array (
′default′⇒′manage_′,
′users′⇒′drupal.′,
′sessions′⇒′drupal.′,
′role′⇒′drupal.′,
′authmap′⇒′drupal.′,
′profile_fields′⇒′drupal.′,
′profile_values′⇒′drupal.′,
) ;
上面配置了子站点3数据库中独有的数据表、其与主站点共享的数据表。其中 ‘default’ 的值表示子站3中独自使用的数据表前缀, 之后的变量值表示子站点3中有关用户的信息共享主站点1数据库Drupal中的信息。
4.3 资源混搭应用现状
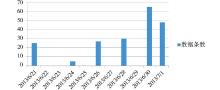
三个子平台针对不同读者群体, 实现具有不同主题特征和功能的平台。馆员根据学科特点实时发布最新资源并与读者充分互动, 其中网络与信息资源服务平台截止2013年7月1日导入测试数据7 000余条, 通过Aggregator模块定时自动收集来自西安交通大学图书馆馆内资源RSS数据1 300多条, 相比2012年9月14日数量增加了两倍多, 通过Bibliography模块导入西安交通大学图书馆馆藏USMARC记录5 000余条, 通过Millennium Integration模块批量收割馆藏图书记录1 100多条, 相比2012年9月14日数量增加了10倍多, 以及其他如抓取来自康涅狄格州立大学图书馆系统 (CONSULS) 中的书目数据若干条。随机抽取一个时间段如2013年6月21日到2013年7月1日, MS Drupal-Mashup每日导入西安交通大学图书馆馆藏资源的对比统计情况如图4所示:
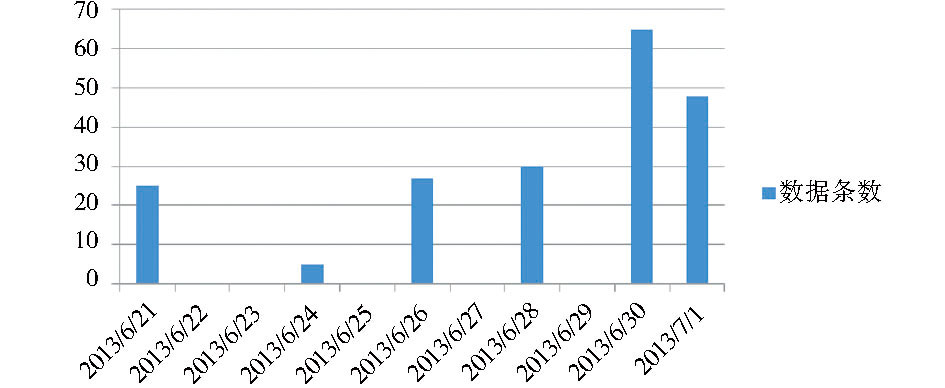 | 图4 MS Drupal-Mashup导入馆藏资源统计 |
图4中每天导入馆藏资源的数据数量参差不齐, 没有固定规律, 这一方面与图书馆局域网网络环境有关, 另一方面与读者访问MS Drupal-Mashup次数、激发Cron模块自动运行次数有关, 最重要的还是与西安交通大学图书馆Millennium中书目号、USMARC和CNMARC数据格式有关。
考虑到平台的效能和安全性, 通过Cron模块定时自动更新缓存, 检查各模块, 检测网站运行状态, 收割RSS数据等。从日志报告可以看出, 各个服务平台正常工作, 日志模块 (Blog Module) 监测网站, 捕捉系统事件如使用数据、性能数据、错误、警告和操作信息等。
5 结 语
混搭从简单到复杂, 类型丰富给予开发者广阔的创造空间, 西安交通大学图书馆作为开源数据的提供者, 亦可作为混搭的受益者。Drupal作为图书馆界公认的内容管理系统, 通过对 Drupal的实践, 搭建MS Drupal-Mashup, 探索图书馆在引进资源整合方面的技术难点以及如何更好地处理共享、整合、同步动态信息等问题。目前搭建的MS Drupal-Mashup利用混搭按需收集信息, 定制检索, 实时向读者传递新的服务;实现单点注册, 站点之间用户信息共享, 每个站点在控制权方面相对独立, 界面设计灵活丰富, 基本实现了馆藏MARC数据导入导出、书封显示、平台和馆藏流通信息数据同步、读者留言管理等交互功能。同时, 馆藏数据抓取不全, 导致中文图书信息不完善, 需要进一步对Millennium Integration模块开发;谷歌定制搜索数据源有限, 有待进一步扩大。Drupal 与其他系统的信息融合、混搭问题, 挖掘混搭和Web 服务技术架构的潜能, 引入语义网 (Semantic Web) 数据关联技术[ 14]也需要进一步探讨。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|